
句法分析 (syntactic parsing) 在 NLP 领域的应用是怎样的?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2016-06-06 16:22:282041검색
问个NLP领域问题。问题原话是这样的,"To what extent would syntactic parsing be useful in an opinion extraction system and an information retrieval system?"
题干里的opinion extraction system,information retrieval system是如何通过syntactic parsing实现的?求NLP大神讲解各自的细节和领域。
这个问题要怎么回答合适?
回复内容:
谢邀。这里面有两个问题:1. 在opinion extraction/IR中如何使用句法分析;2. 句法分析在多大程度上对这两个任务有帮助(原题)。由于我自己主要还是做句法分析本身,暂时很少做上层应用,所以简单谈谈我对应用的理解,抛砖引玉。
1. 在opinion extraction/IR中如何使用句法分析。
举几个例子吧。
比如在opinion extraction中我们常常要抽取评价对象(aspect):
例:“知乎的内容质量很好”
这里 “很好” 形容的是 “内容质量”。通过依存句法分析,就可以抽取出对应的搭配。如下图:
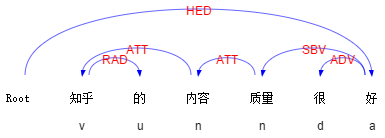
 (顺手插个广告,分析结果来自我们实验室的语言云:在线演示 | 语言云(语言技术平台云 LTP-Cloud))
(顺手插个广告,分析结果来自我们实验室的语言云:在线演示 | 语言云(语言技术平台云 LTP-Cloud))再说说IR,以百度框计算为例。对于以下两个query:
Query 1: 谢霆锋的儿子是谁?
Query 2: 谢霆锋是谁的儿子?
这两个Query的bag-of-words完全一致,如果不考虑其语法结构,很难直接给用户返回正确的结果。类似的例子还有很多。在这种情况下,通过句法分析,我们就能够知道用户询问的真正对象是什么。
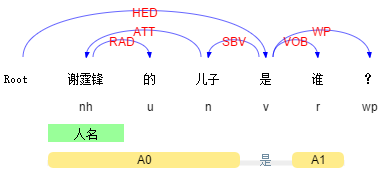
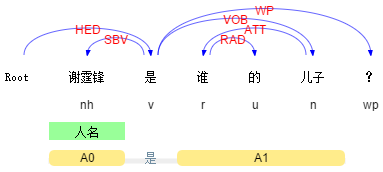
推而广之,对Query进行更general的需求分析大都离不开描述对象的提取,很多时候句法结构非常关键,更是下一步语义分析的前提。
2. 句法分析在多大程度上对这两个任务有帮助(原题)。
原问题很好,可以扩展出很多思考。在炼丹纪到来之前,也许我们可以给一个非常乐观的回答,比如60%。但是现如今,我们需要思虑再三。主要原因在于,RNN/LSTM等强大的时序模型(sequential modeling)能够在一定程度上刻画句子的隐含语法结构。尽管我们暂时无法提供一个清晰的解释,但是它在很多任务上的确表现出非常promising的性能。
推荐一下车万翔老师前段时间写的一个简单的survey:哈工大车万翔:自然语言处理中的深度学习模型是否依赖于树结构?
文中的一个性能对比能够说明问题:Tree-LSTM是基于句法结构之上的LSTM,Bi-LSTM则是简单的双向(leftright)LSTM。在很多任务上,Bi-LSTM都表现得比Tree-LSTM更好。
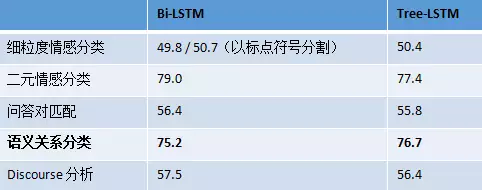
但是,这并不说明句法结构是没有用的,详细分析请参考上面提到的survey。
需要提及的是,句法分析目前的性能是防碍其实际应用的一个关键因素,尤其是在open-domain上。目前在英文WSJ上的parsing性能最高能够做到94%,但是一旦跨领域,性能甚至跌到80%以下,是达不到实际应用标准的。而中文上parsing性能则更低。
刚入手nlp不久,主要做的是文本情感分析方向,但并没有用句法分析做过研究,看到题主的问题,和所有答主的回答,并在近几日查阅了一些相关文献,针对题主所提问题做了整理,也对现有回答进行一些补充。
欢迎大家一起讨论^_^。
句法分析在opinion extraction(意见提取)中的应用:
1. What to do
首先对研究目标进行分析。
opinion extraction要解决的主要问题就是判断一句话或一段评论所蕴含的情感。如果仅以情感倾向性的判断作为唯一目标,那么就是一个分类问题,分类的结果可以为正向、负向、中性三类,或者加入强度,进行更细粒度的划分。当然,虽然情感倾向性的判断是一个值得研究的方向,但opinion extraction能挖掘出来的信息并不仅限于此。
上述的挖掘内容的差异,实际上引出了opinion extraction研究方向的两个大类。一个是sentiment classification,就是以情感倾向性判断的高正确率为目标的研究;另一个是sentiment related information extraction,更多地关注于对情感文本的组成元素进行分析。什么是组成元素?就是一段评论中,评论者,评论的主体,能体现评论者情感的情感词等等元素。
举个例子(取自[1])
I highly recommend the Canon SD500 to anybody looking for a compact camera that can take good pictures.
粗体字表示评论主体,斜体字划线字表示情感词
对于sentiment classification问题,对于上述数据,能够判断出它蕴含的情感是正向的,就够了。
而对于sentiment related information extraction问题,对于上述数据,要能够判断出Canon SD500的性能不错,如果有性能的分类,还应该将其分类到如“拍照性能”的类别中。
2.How to do and why is Syntactic Parsing important
说完要解决的问题,接下来说解决问题的方法,并分析句法分析在其中的关键作用
上面对opinion extraction的研究方向进行了一个分类。下面要说的是,句法分析在其中的应用。
句法分析对第一类问题的意义不大,这也是答主没有看到过用句法分析所做研究的原因。因为对于第一类问题,用统计的方法更为高效,效果也比较好。只需要对测试文本进行分词(英文的话根据空格分词就可以了),由文本中出现的所有词的情感倾向,对该文本的情感倾向进行预测就可以了。当然这是大致思路,若要提升准确率,还可以对文本的领域进行判断等等。
而在第二类问题中,句法分析的作用就大大的了。因为第一类问题可以将所有词平等看待,只需要根据标定数据,判断一个词在正向和负向评论中出现的概率。而要想知道一句话中哪个是评论的主题,哪个是修饰它的词,则必须要对语言规则有足够的设定,名词和形容词是存在本质差别的。另一方面,因为一句话中可能存在从句,所以可能形容词和其修饰的名词主体相距甚远,如果没有对句法规则有足够的判断,结果可能一塌糊涂。
关于句法分析,已有答主给出了很清晰的例子,在这里就不在赘述。在这里给出一个由规则进行情感词提取的例子(取自[2])
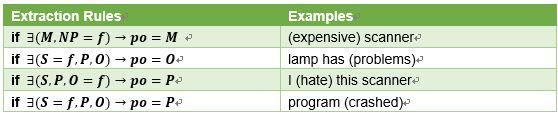
标志注释:
M: modifier,修饰词
NP: noun phrase,名词短语
S: subject,主语
P: predicate,谓语
O: object 宾语
f: feature 被评价的主体
这还不是全部的规则,由此也可以看出由句法结构来进行opinion extraction是麻烦而且准确率难以达到很高水准的,因为很难对所有的情况指定精确的规则。因此如何进行句法分析,在opinion extraction中也是一项研究内容。
句法分析在information retrieval中的应用:
1.what to do
答主之前没有接触过information retrieval,通过这段时间的调研,认为其解决的主要问题即为通过给定的查询输入,在一定范围内检索到相关的信息。一个重要的应用就是问答系统(question answering systems)。
2.How to do and why is Syntactic Parsing important
因为要通过对输入查询的分析,找到某一数据集(比如互联网)中与查询相关内容的信息,比如与查询语句相关的一段话,或针对所提问题直接给出一个简短的回答。
文献[6]将问答系统的任务大致分为三步,个人认为有参考意义:
(1)locating the relevant documents 定位相关文档
(2)retrieving passages that may contain the answer 在文档中找到可能包含答案的段落
(3)pinpointing the exact answer from candidate passages 在备选段落中精确定位,找到答案
由上可以看出,在进行information retrieval时,并非一步得到答案,而是不断缩小范围的。这就需要每一步都没有太大偏差,比如第(2)步,连可能包含答案的段落都找错了,那肯定不会找到正确的答案了。
因为查询实际上可以看为匹配操作,所以对输入语句的匹配和分析就会对查询结果起到决定性影响。下面用一个例子来进行说明(取自[7])
Q: What did George Washington call his house?
传统的方法,会在数据库(搜索范围)中对包含关键词的文档/段落进行匹配,毫无疑问,这个问题中的关键词是标绿的George Washington 和 house。于是找到了以下关键词:
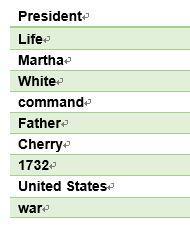
确实找到了一些相关的词语,但一个很大的问题就是,这样直接对关键词进行匹配,而不分析关键词之间的关系,就无法找到同时包含多个关键词的答案。也就是说,匹配出的词语仅与一个或少量关键词有关。但在问题中问的是George Washington的house,所以只匹配George Washington或之匹配house都是很难得到精确答案的。
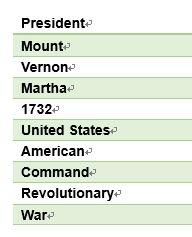
这是用句法分析,分析关键词之间的相关关系后,得到的相关结果。虽然有多个词语上面的结果相近,但后者会将与两个关键词都相关的结果排名提前,如”George’s Washington’s house, Mount Vernon.”这一搜索结果,其出现次数很少,在传统方法中,会被排到比较靠后的位置,但明显其与两个关键词同时相关,因此在句法分析的方法中,它会被排到很靠前的位置。
在文献[7]中还有更详细的举例说明,即如何通过句法分析建立parsing tree,对查询语句和搜索结果进行语法序列(因为每句话的词语之间存在相关关系,所以其可以看成是一个语法序列)的匹配,选择匹配得分高的结果作为答案。具体说明细节较多,就不在这里赘述了。
总结
上面说了句法分析如何解决opinion extraction和information retrieval的问题,有些琐碎。个人认为,总体来说,因为自然语言的词语词之间存在相关性,因此通过句法分析能够比仅用统计的方法挖掘出更多的信息量,当然统计的方法也可以在某些维度挖掘出句法分析所得不到的信息,所以这么说更准确一些:句法分析能够更直接地通过语法结构的规则约束筛选出对我们有用的结果,以这种方法来提升方法得准确性。
因为是看到题主的问题后于近期做了一些调研,回答可能有不完善之处,但答案中所举例子、所述理论均有文献依据,欢迎大家一起探讨^_^。
参考文献及pdf链接
Opinion extraction部分
[1] Wu Y, Zhang Q, Huang X, et al. Phrase dependency parsing for opinion mining[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1533-1541.
链接:http://www.aclweb.org/anthology/D/D09/D09-1159.pdf
[2] Popescu A M, Etzioni O. Extracting product features and opinions from reviews[M]//Natural language processing and text mining. Springer London, 2007: 9-28.
链接: http://www.aclweb.org/old_anthology/H/H05/H05-1.pdf#page=375
[3] Poria S, Cambria E, Ku L W, et al. A rule-based approach to aspect extraction from product reviews[C]//Proceedings of the Second Workshop on Natural Language Processing for Social Media (SocialNLP). 2014: 28-37.
链接:http://www.anthology.aclweb.org/W/W14/W14-59.pdf#page=38
[4] Choi Y, Breck E, Cardie C. Joint extraction of entities and relations for opinion recognition[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2006: 431-439.
链接:http://www.aclweb.org/anthology/W/W06/W06-16.pdf#page=453
[5] Dave K, Lawrence S, Pennock D M. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews[C]//Proceedings of the 12th international conference on World Wide Web. ACM, 2003: 519-528.
链接:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.13.2424&rep=rep1&type=pdf
Information extraction部分
[6] Cui H, Sun R, Li K, et al. Question answering passage retrieval using dependency relations[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2005: 400-407.
链接:http://www.comp.nus.edu.sg/~kanmy/papers/f66-cui.pdf
[7] Sun R, Ong C H, Chua T S. Mining dependency relations for query expansion in passage retrieval[C]//Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2006: 382-389.
链接:http://lms.comp.nus.edu.sg/sites/default/files/publication-attachments/sigir06-sunrenxu.pdf
[8] Carpineto C, Romano G. A survey of automatic query expansion in information retrieval[J]. ACM Computing Surveys (CSUR), 2012, 44(1): 1.
链接:
https://www.researchgate.net/profile/Claudio_Carpineto/publication/220566113_A_Survey_of_Automatic_Query_Expansion_in_Information_Retrieval/links/00b7d515aa3ac40767000000.pdf
【非常高兴看到大家喜欢并赞同我们的回答。应许多知友的建议,最近我们开通了同名公众号:PhDer,也会定期更新我们的文章,如果您不想错过我们的每篇回答,欢迎扫码关注~ 】
 我也来答一下好了,虽然没人邀_(:3」∠)
我也来答一下好了,虽然没人邀_(:3」∠)Jiwei Li 在今年ACL上发了一篇“When Are Tree Structures Necessary for Deep Learning of Representations?”,大概就是tree structure vs. sequence (recursive vs. recurrent)。
他用四个任务说明这个问题:
- sentiment classification at the sentence level and phrase level
- matching questions to answer-phrases
- discourse parsing
- semantic relation classification
具体结论有以下几点:
- 较长文本用tree比较好(如果语料充分)
- bi-LSTM可以弥补sequence和tree之间的gap
- 可以把长文本分成短文本(用标点),再分层的使用sequence model
 我是相信树的有效性的,或许只是我们没有提出更好的模型罢了
我本人是做文本情感分析的,经常用到句法依存分析,算是对这些有些了解,暂且发表一下个人的观点,不对之处希望指出,大家共同学习,共同进步。
我是相信树的有效性的,或许只是我们没有提出更好的模型罢了
我本人是做文本情感分析的,经常用到句法依存分析,算是对这些有些了解,暂且发表一下个人的观点,不对之处希望指出,大家共同学习,共同进步。1.句法依存的介绍
依存分析主要是为了分析句子中各成分之间的相互关系。大致目标:识别句法成分(主谓宾等)、确定句法关系(SBV、VOB、ATT、ADV等)。
依存分析的实现主要包括基于图的方法和基于状态转移的方法。基于图的方法利用全句的依存关系训练,使用最大生成树算法解析,具有全局性,但他有个致命缺点--不到搜索结束,不会产生中间解析结果,因此无法把中间结果用于后续解析。基于状态转移的方法利用每一步的转移训练,逐步搜索局部最优解析直至解析完毕,这种方法有点贪心算法的意思(个人感觉)和局部性,这个算法的好处是可以利用中间结果对后续进行解析。这两种方法可以说是对立又互补的关系,也有不少人把他们融合,据说产生了比任何一个单独方法都要好的效果。
2.句法依存的意义
2.1 文本理解
“谢霆锋的儿子是谁?”和“谢霆锋是谁的儿子?”这俩问题完全不一样,但是如果用传统的搜索肯定导致搜索结果几乎一致(因为基本就是关键字匹配),但是如果加入句法依存分析的话结果就会完全不一样。
2.2语义消歧(这个用处就很多了,最常见的可以用与query改写)
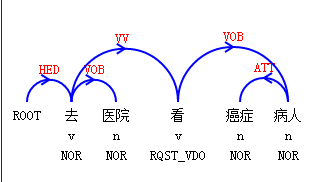
比如“去医院看癌症病人”,“看”在这里可以是“治疗”的意思也可以是“看望”的意思,所以容易歧义。如果你引入句法依存完全就会确定为“看望”了,因为看的宾语是“病人”。
2.3主干抽取
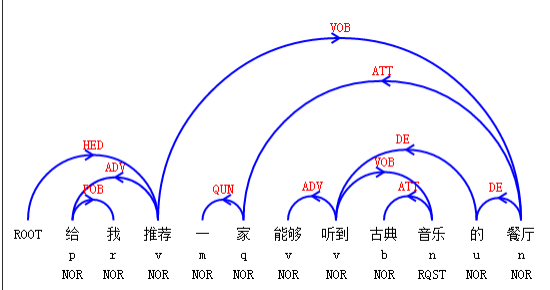
“给我推荐一家能够听到古典音乐的餐厅”这句通过句法分析就可以轻而易举获取主干。
2.4摘要抽取
具体类似,不再多说。
2.5情感分析
一般因为领域问题(我家音响声音很大VS我家洗衣机声音很大)和反讽问题(你牛逼你上啊),目前情感分析大多基于规则而不是基于统计,基于规则的一般用句法分析确定和验证一些情感词、主观词的句法结构,然后判定句子的情感倾向、抽取情感tag等。
2.6机器翻译
最简单的一种方法:通过句法分析把句子结构确定下来,然后逐个词翻译,再根据句法结构整理和修改翻译结果。
2.7唯一答案搜索(问答系统)
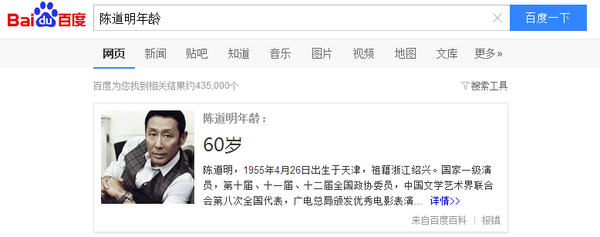
比如用户搜“陈道明身高”、“陈道明年龄”,如果加入句法依存分析就会直接给出搜索结果。
 类似的应用还有,不再一一列举。除此之外句法依存分析还是语义角色标注的基础。
类似的应用还有,不再一一列举。除此之外句法依存分析还是语义角色标注的基础。3.什么时候需要句法依存分析
a.对于复杂问题但训练数据比较少
b.语义依赖的距离比较远(那帮傻乎乎的女性小粉丝在网络上抨击我)
具体参考车老师的这个文章:哈工大车万翔:自然语言处理中的深度学习模型是否依赖于树结构?
4.句法分析怎么用
简单介绍一个在主观句抽取中的应用吧,基本处理(分词、词性标注等)-->match aspect-->match aspect-verb-->match 情感词-->match 泛情感词-->粒度解析(合并结果、重新词性标注等,比如(给v 力n -->给力a)-->句法依存分析-->验证主观词句法结构(比如情感动词必须得有主语和宾语等)-->句式匹配(多种句式,不同句式位置和命中规则不一样)-->句式过滤(多种句式,不同句式过滤的位置和过滤规则不一样)-->整句句法分析-->整句过滤-->输出主观句。 基于规则才会用到句法 opinion extraction system这说法很学术,我不知道中文怎么表达。
information retrieval system指的就搜索引擎。
首先,基于文本相关性来搜索,在NLP场景下,核心关键词的得分容易被一些废话稀释。虽然可以用stopwords来解决,但句法分析提取本体的做法会精准得多。
然后,更重要的是,咱们搞搜索上层应用的,除了文本相关性之外,很多时候会做一些基于特定规则的特殊处理。这一块很大程度是基于自身的业务,所以国内LTP也好、ICTCLAS也好,并没有给出做句法分析的通解。
例如一个视频搜索,发现query里有“new”或者“hot”,可能就要在搜索时加上时间相关的特殊规则。这些规则的制定,就是对业务的理解结合句法分析完成的。
视频搜索这例子不太好,因为设个关键词也能解决,不需要用到句法分析这种牛刀。如果搜“我要订个明天从广州飞北京的机票”,就一定要用句法分析了。首先要判定这个是买机票业务,然后抽取出句中的时间地点,然后填入对应的业务接口当中,最后呈现给用户。
其难点在于如何抽象化和运行效率问题,还有业务和工程方面无数你想到的想不到的坑。
关于“To what extent would syntactic parsing be useful”,
这个应该对题主有帮助:
https://open.weixin.qq.com/zh_CN/htmledition/res/assets/smart_lang_protocol.pdf 基本上,停滞不前。