


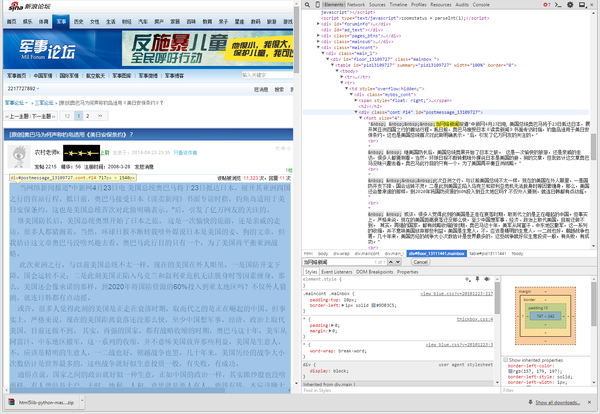
大数据分析就不会了,还请赐教。
<code class="language-python"><span class="kn">import</span> <span class="nn">requests</span>
<span class="kn">from</span> <span class="nn">bs4</span> <span class="kn">import</span> <span class="n">BeautifulSoup</span>
<span class="n">r</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="s">"http://club.mil.news.sina.com.cn/thread-666013-1-1.html"</span><span class="p">)</span>
<span class="n">r</span><span class="o">.</span><span class="n">encoding</span> <span class="o">=</span> <span class="n">r</span><span class="o">.</span><span class="n">apparent_encoding</span>
<span class="n">soup</span> <span class="o">=</span> <span class="n">BeautifulSoup</span><span class="p">(</span><span class="n">r</span><span class="o">.</span><span class="n">text</span><span class="p">)</span>
<span class="n">result</span> <span class="o">=</span> <span class="n">soup</span><span class="o">.</span><span class="n">find</span><span class="p">(</span><span class="n">attrs</span><span class="o">=</span><span class="p">{</span><span class="s">"class"</span><span class="p">:</span> <span class="s">"cont f14"</span><span class="p">})</span>
<span class="k">print</span> <span class="n">result</span><span class="o">.</span><span class="n">text</span>
</code>
用beautifulSoup吧,正则太多了看着都头疼.
先用了BeautifulSoup爬取数据<code class="language-python"><span class="c"># -*- coding:utf-8 -*-</span>
<span class="kn">import</span> <span class="nn">re</span><span class="o">,</span> <span class="nn">requests</span>
<span class="kn">from</span> <span class="nn">bs4</span> <span class="kn">import</span> <span class="n">BeautifulSoup</span>
<span class="kn">import</span> <span class="nn">sys</span>
<span class="nb">reload</span><span class="p">(</span><span class="n">sys</span><span class="p">)</span>
<span class="n">sys</span><span class="o">.</span><span class="n">setdefaultencoding</span><span class="p">(</span><span class="s">'utf-8'</span><span class="p">)</span>
<span class="n">url</span> <span class="o">=</span> <span class="s">"http://club.mil.news.sina.com.cn/viewthread.php?tid=666013&extra=page%3D1&page=1"</span>
<span class="n">req</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">url</span><span class="p">)</span>
<span class="n">req</span><span class="o">.</span><span class="n">encoding</span> <span class="o">=</span> <span class="n">req</span><span class="o">.</span><span class="n">apparent_encoding</span>
<span class="n">html</span> <span class="o">=</span> <span class="n">req</span><span class="o">.</span><span class="n">text</span>
<span class="n">soup</span> <span class="o">=</span> <span class="n">BeautifulSoup</span><span class="p">(</span><span class="n">html</span><span class="p">)</span>
<span class="nb">file</span> <span class="o">=</span> <span class="nb">open</span><span class="p">(</span><span class="s">'sina_club.txt'</span><span class="p">,</span> <span class="s">'w'</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="mi">1</span>
<span class="k">for</span> <span class="n">tag</span> <span class="ow">in</span> <span class="n">soup</span><span class="o">.</span><span class="n">find_all</span><span class="p">(</span><span class="s">'div'</span><span class="p">,</span> <span class="n">attrs</span> <span class="o">=</span> <span class="p">{</span><span class="s">'class'</span><span class="p">:</span> <span class="s">"cont f14"</span><span class="p">}):</span>
<span class="n">word</span> <span class="o">=</span> <span class="n">tag</span><span class="o">.</span><span class="n">get_text</span><span class="p">()</span>
<span class="n">line1</span> <span class="o">=</span> <span class="s">"---------------评论"</span> <span class="o">+</span> <span class="nb">str</span><span class="p">(</span><span class="n">x</span><span class="p">)</span> <span class="o">+</span> <span class="s">"---------------------"</span> <span class="o">+</span> <span class="s">"</span><span class="se">\n</span><span class="s">"</span>
<span class="n">line2</span> <span class="o">=</span> <span class="n">word</span> <span class="o">+</span> <span class="s">"</span><span class="se">\n</span><span class="s">"</span>
<span class="n">line</span> <span class="o">=</span> <span class="n">line1</span> <span class="o">+</span> <span class="n">line2</span>
<span class="n">x</span> <span class="o">+=</span> <span class="mi">1</span>
<span class="nb">file</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="n">line</span><span class="p">)</span>
<span class="nb">file</span><span class="o">.</span><span class="n">close</span><span class="p">()</span>
</code>
哎,扒就扒吧,发了paper能不能告诉我刊号页数让我看一下?我们自己都没做大数据分析……
建议用一下正则测试工具
你需要pyquery,可以使用jquery一样的语法。你值得拥有。https://pythonhosted.org/pyquery/