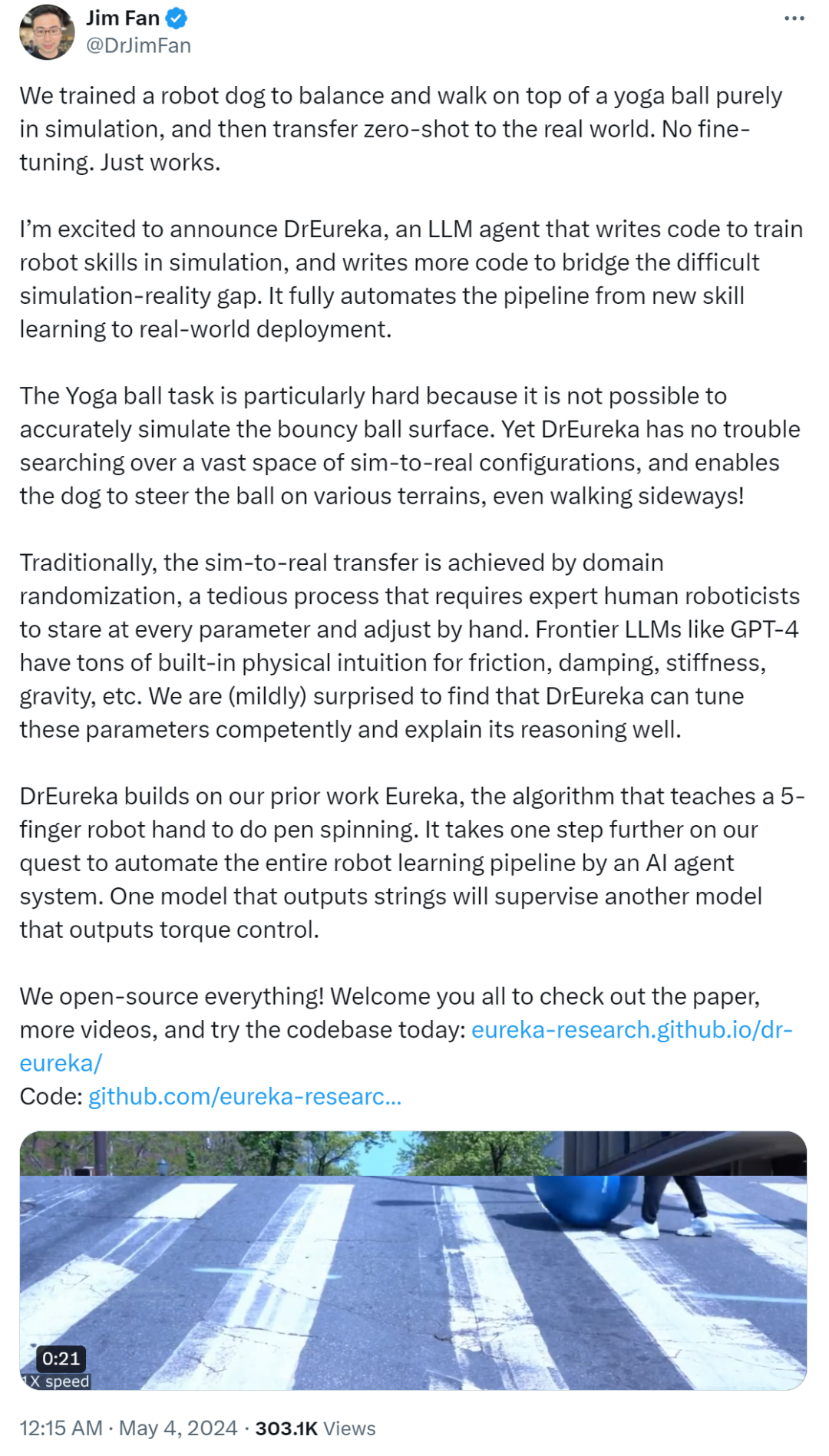
로봇 개는 요가 볼 위를 꾸준하게 걷고 균형이 꽤 좋습니다. 
평평한 보도든 까다로운 잔디밭이든 다양한 장면을 처리할 수 있습니다.
심지어 연구자들이 요가 공을 찼을 때 로봇 개는 넘어지지 않았습니다.
로봇 개는 풍선을 수축할 때 균형을 유지할 수도 있었습니다.
위 시연은 가속 처리 없이 모두 1배속입니다.
- 논문 주소: https://eureka-research.github.io/dr-eureka/assets/dreureka-paper.pdf
- 프로젝트 홈페이지: https://github.com/eureka- 연구/DrEureka
- 논문 제목: DrEureka: Language Model Guided Sim-To-Real Transfer
이 연구는 University of Pennsylvania, NVIDIA 및 University of Texas at Austin의 연구원들이 공동으로 작성했습니다. 이며 완전히 오픈 소스입니다. 그들은 LLM을 활용하여 보상 설계와 도메인 무작위 매개변수 구성을 구현하는 새로운 알고리즘인 DrEureka(Domain Randomized Eureka)를 제안했으며, 이는 시뮬레이션에서 현실로의 전환을 동시에 달성할 수 있습니다. 이 연구는 DrEureka 알고리즘이 반복적인 수동 설계 없이도 네 발 달린 로봇 균형 잡기, 요가 공 위 걷기 등 새로운 로봇 작업을 해결할 수 있는 능력을 보여줍니다. 논문의 추상 부분에서 연구자들은 시뮬레이션에서 학습한 전략을 현실 세계에 적용하는 것이 로봇 기술의 대규모 습득을 위한 유망한 전략이라고 밝혔습니다. 그러나 시뮬레이션에서 현실로의 접근 방식은 작업 보상 기능과 시뮬레이션 물리적 매개변수를 수동으로 설계하고 조정하는 경우가 많아 프로세스가 느리고 노동 집약적입니다. 이 문서에서는 시뮬레이션에서 현실적인 설계까지 자동화하고 가속화하기 위해 LLM(대형 언어 모델)을 사용하는 방법을 조사합니다. 논문 저자 중 한 명이자 NVIDIA의 수석 과학자인 Jim Fan도 이 연구에 참여했습니다. 이전에 엔비디아는 구체화된 지능을 전문으로 하는 짐 팬(Jim Fan)이 이끄는 AI 연구소를 설립했습니다. Jim Fan은 다음과 같이 말했습니다. "우리는 요가 공 위에서 균형을 잡고 걷기 위해 로봇 개를 훈련시켰습니다. 이것은 완전히 시뮬레이션으로 수행되었으며, 그런 다음 미세 조정 없이 샘플 없이 현실 세계로 전송되어 직접 달렸습니다. 요가 공을 걷는 작업은 탄력있는 공의 표면을 정확하게 시뮬레이션할 수 없기 때문에 로봇 강아지에게 특히 어렵습니다. 그러나 DrEureka는 시뮬레이션된 수많은 실제 구성을 쉽게 검색하여 로봇 강아지를 허용할 수 있습니다. 일반적으로 시뮬레이션에서 현실로의 전환은 도메인 무작위화를 통해 이루어집니다. 이는 로봇 전문가가 각 매개변수를 관찰하고 수동으로 수행해야 하는 지루한 과정입니다. 4 이러한 최첨단 LLM에는 마찰, 감쇠, 강성, 중력 등을 포함한 많은 물리적 직관이 내장되어 있습니다. GPT-4를 사용하면 DrEureka는 이러한 매개변수를 능숙하게 조정하고 추론을 잘 설명할 수 있습니다 》
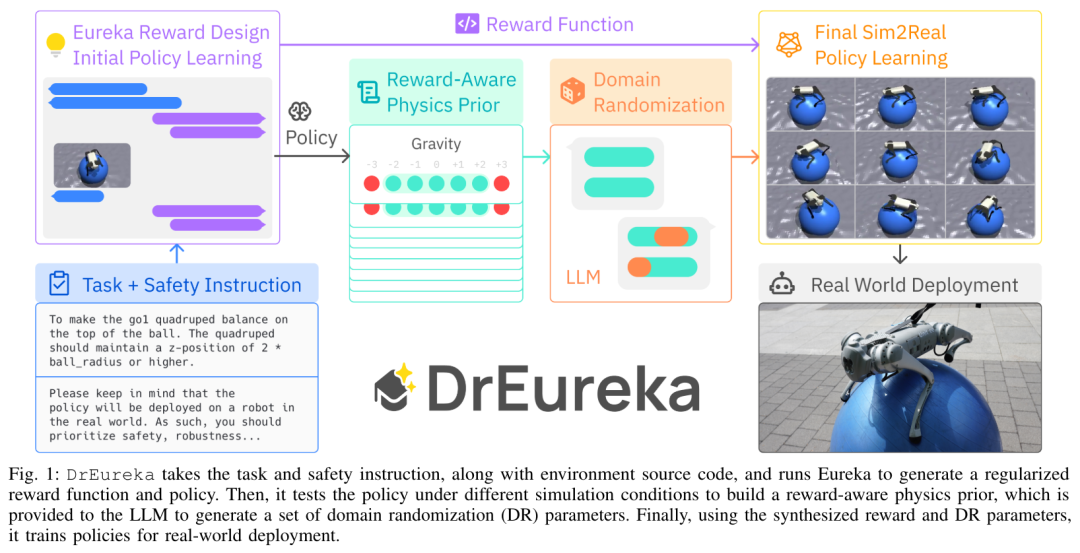
DrEureka 프로세스는 다음과 같습니다. 작업 및 안전 지침과 환경 소스 코드를 수용하고 Eureka를 실행하여 정규화된 보상 기능과 정책을 생성합니다. 그런 다음 다양한 시뮬레이션 조건에서 전략을 테스트하여 보상 인식 물리적 사전을 구성합니다. 이는 도메인 무작위화(DR) 매개변수 세트를 생성하기 위해 LLM에 공급됩니다. 마지막으로 실제 배포를 위해 합성된 보상과 DR 매개변수를 사용하여 정책을 학습합니다. 유레카 보상 디자인. 보상 디자인 구성 요소는 단순성과 표현성 때문에 Eureka를 기반으로 하지만, 본 논문에서는 시뮬레이션에서 실제 환경으로의 적용성을 높이기 위해 몇 가지 개선 사항을 소개합니다. 의사코드는 다음과 같습니다: Reward recognition 물리 사전(RAPP, 보상 인식 물리 사전). 보안 보상 기능은 환경 선택을 수정하기 위해 정책 행동을 규제할 수 있지만 그 자체로는 시뮬레이션에서 현실로의 전환을 달성하기에는 충분하지 않습니다. 따라서 본 논문에서는 LLM의 기본 범위를 제한하기 위해 간단한 RAPP 메커니즘을 소개합니다. LLM은 도메인 무작위화에 사용됩니다. 각 DR 매개변수에 대한 RAPP 범위가 주어지면 DrEureka의 마지막 단계에서는 LLM에 RAPP 범위 제한 내에서 도메인 무작위 구성을 생성하도록 지시합니다. 구체적인 프로세스는 그림 3을 참조하세요. 이 연구에서는 실험에 Unitree Go1을 사용합니다. Go1은 네 다리의 자유도가 12인 소형 4족 로봇입니다. 4족 보행 작업에서 이 논문은 또한 여러 실제 지형에서 DrEureka 정책의 성능을 체계적으로 평가하고 인간이 설계한 보상 및 DR 구성을 사용하여 훈련된 정책보다 강력하고 뛰어난 성능을 유지한다는 사실을 발견했습니다. 위 내용은 요가볼 위의 '개'를 산책시키세요! 엔비디아의 10대 프로젝트 중 하나로 선정된 유레카(Eureka)는 새로운 돌파구를 마련했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!