
단일 카드는 듀얼 카드보다 Llama를 70B 더 빠르게 실행합니다. Microsoft는 A100에 FP6을 넣었습니다 |

- PHPz앞으로
- 2024-04-29 16:55:121338검색
FP8 이하 부동 소수점 수량화 정밀도는 더 이상 H100의 "특허"가 아닙니다!
Lao Huang은 모든 사람이 INT8/INT4를 사용하기를 원했습니다. Microsoft DeepSpeed 팀은 NVIDIA의 공식 지원 없이 A100에서 FP6을 강제로 실행하기 시작했습니다.
테스트 결과에 따르면 A100에서 새로운 방법인 TC-FPx의 FP6 양자화 속도는 INT4에 가깝거나 때로는 INT4를 초과하며 후자보다 정확도가 더 높습니다.
이를 바탕으로 오픈 소스로 제공되고 DeepSpeed와 같은 딥 러닝 추론 프레임워크에 통합된 엔드 투 엔드 대규모 모델 지원도 있습니다.
이 결과는 대형 모델의 가속화에도 즉각적인 영향을 미칩니다. 이 프레임워크에서는 단일 카드를 사용하여 Llama를 실행하면 처리량이 듀얼 카드보다 2.65배 더 높습니다.
이 글을 읽은 후 한 머신러닝 연구원은 마이크로소프트의 연구가 미친 짓이라고 할 수 있다고 말했습니다.
이모티콘 팩도 즉시 온라인에 표시됩니다. 예:
NVIDIA: H100만 FP8을 지원합니다.
Microsoft: 좋습니다. 제가 직접 하겠습니다.

그럼 이 프레임워크는 어떤 효과를 낼 수 있고, 그 이면에는 어떤 기술이 사용되는 걸까요?
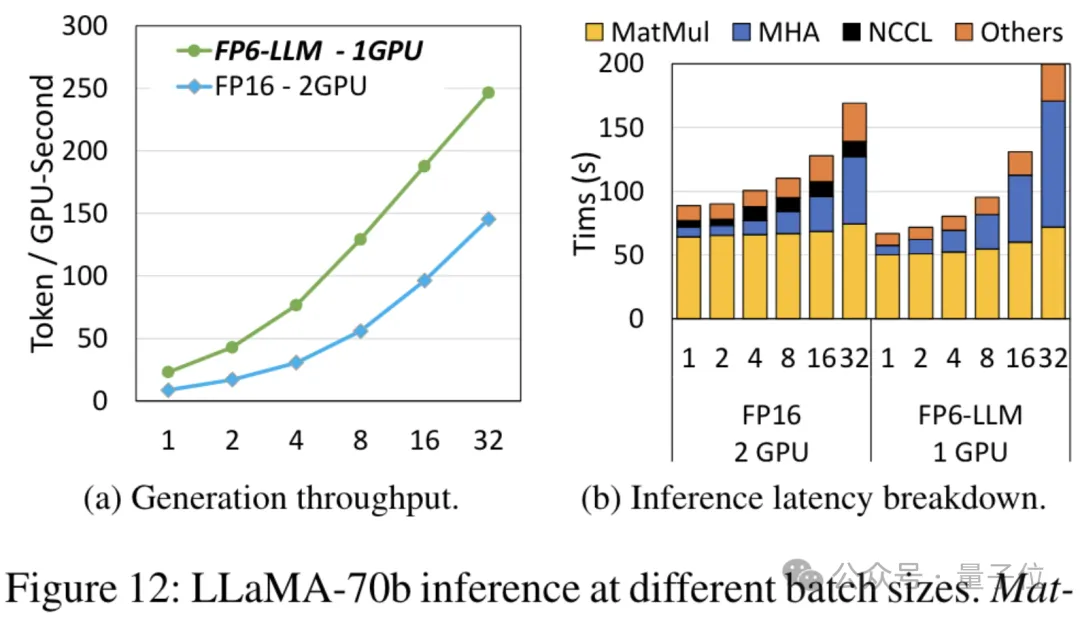
FP6을 사용하여 Llama를 실행하면 단일 카드가 듀얼 카드보다 빠릅니다.
A100에서 FP6 정확도를 사용하면 커널 수준 성능이 향상됩니다.
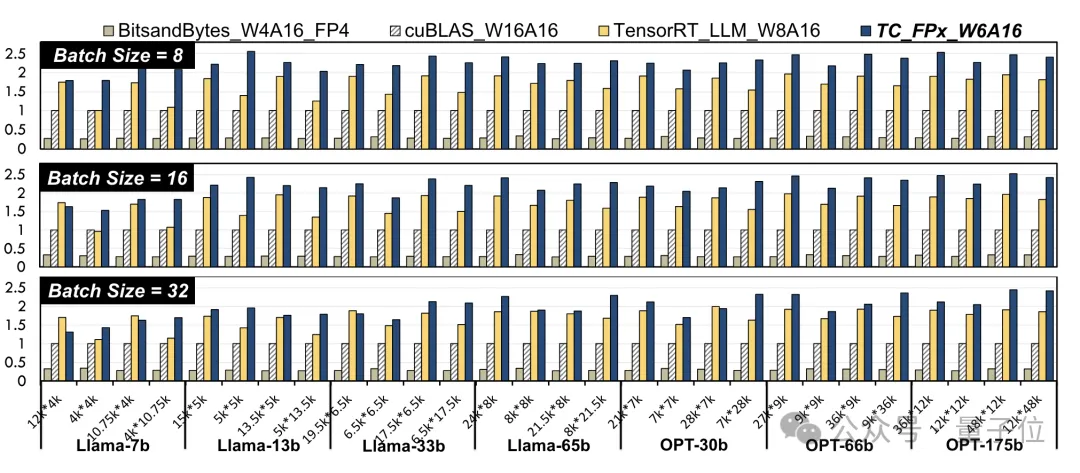
연구원들은 다양한 크기의 Llama 모델과 OPT 모델에서 선형 레이어를 선택하고 NVIDIA A100-40GB GPU 플랫폼에서 CUDA 11.8을 사용하여 테스트했습니다.
NVIDIA 공식 cuBLAS(W16A16) 및 TensorRT-LLM(W8A16)과 비교한 결과, TC-FPx(W6A16)의 최대 속도 향상은 각각 2.6배, 1.9배입니다. 4bit BitsandBytes
(W4A16)방식과 비교하여 TC-FPx의 최대 속도 향상은 8.9배입니다.
(W와 A는 각각 가중치 양자화 비트 폭과 활성화 양자화 비트 폭을 나타냄)
 Δ정규화된 데이터, cuBLAS 결과는 1
Δ정규화된 데이터, cuBLAS 결과는 1
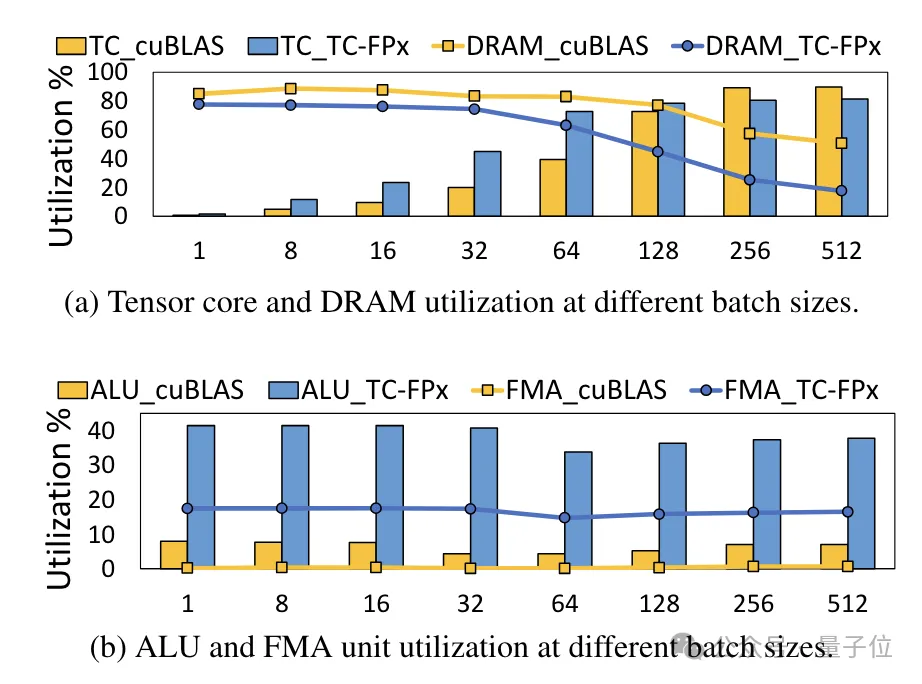
동시에 TC-FPx 코어도 감소합니다 DRAM 메모리 액세스의 필요성을 해결하고 DRAM 대역폭 활용도와 Tensor 코어 활용도는 물론 ALU 및 FMA 장치 활용도도 향상시킵니다.
 TC-FPx를 기반으로 설계된
TC-FPx를 기반으로 설계된
엔드 투 엔드 추론 프레임워크 FP6-LLM은 대형 모델의 성능도 크게 향상시킵니다. Llama-70B를 예로 들면, 단일 카드에서 FP6-LLM을 실행하는 처리량은 듀얼 카드의 FP16보다 2.65배 더 높으며, 16 미만 배치 크기의 지연 시간도 FP16보다 낮습니다.
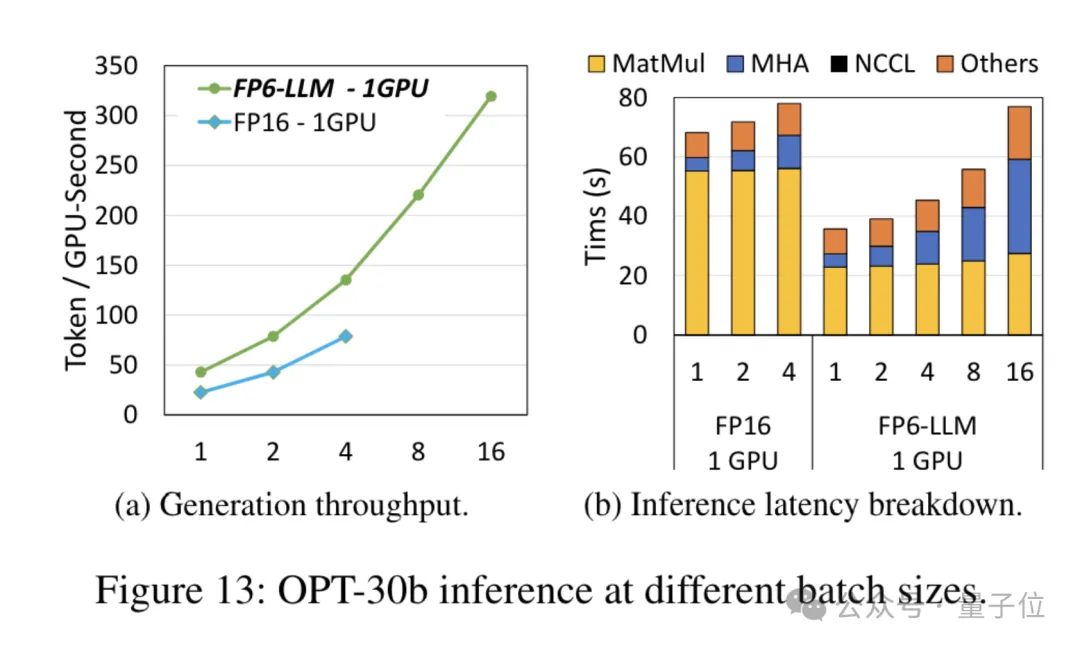
 매개변수 수가 더 적은 OPT-30B 모델(FP16도 단일 카드 사용)의 경우 FP6-LLM은 처리량을 크게 향상하고 대기 시간을 단축합니다.
매개변수 수가 더 적은 OPT-30B 모델(FP16도 단일 카드 사용)의 경우 FP6-LLM은 처리량을 크게 향상하고 대기 시간을 단축합니다.
이 조건에서 단일 카드 FP16이 지원하는 최대 배치 크기는 4개에 불과하지만 FP6-LLM은 배치 크기 16으로 정상적으로 작동할 수 있습니다.
 그렇다면 Microsoft 팀은 어떻게 A100에서 실행되는 FP16 양자화를 달성했을까요?
그렇다면 Microsoft 팀은 어떻게 A100에서 실행되는 FP16 양자화를 달성했을까요?
재설계된 커널 솔루션
6비트를 포함한 정밀도를 지원하기 위해 TC-FPx 팀은 다양한 비트 폭의 양자화 가중치를 지원할 수 있는 통합 커널 솔루션을 설계했습니다.
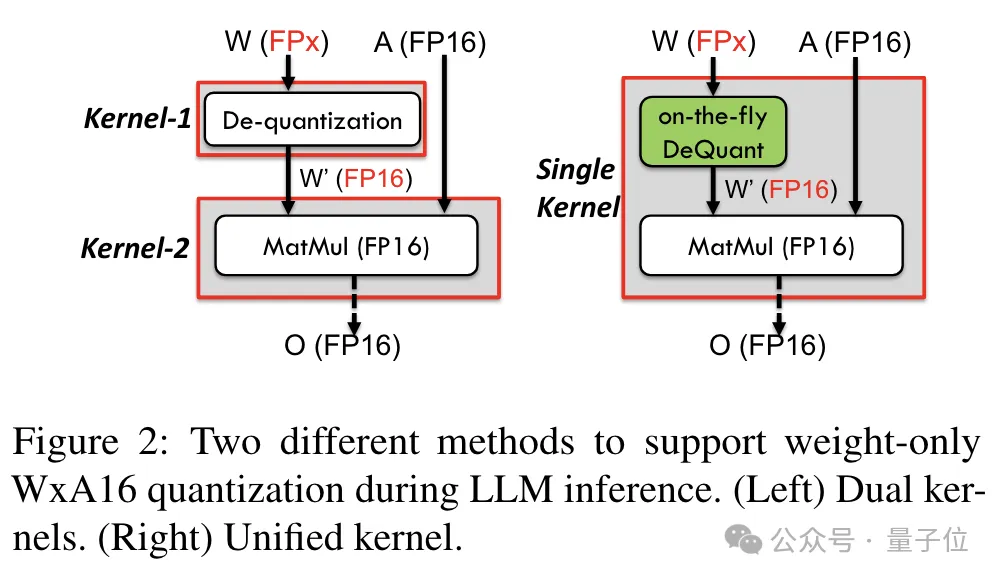
기존 듀얼 코어 방식과 비교하여 TC-FPx는 역양자화 및 행렬 곱셈을 단일 코어에 통합하여 메모리 액세스 횟수를 줄이고 성능을 향상시킵니다.
저정밀도 양자화를 달성하는 핵심 비결은 역양자화를 통해 FP6 정밀도 데이터를 FP16으로 '위장'한 다음 이를 GPU에 넘겨 FP16 형식으로 계산하는 것입니다.
동시에 팀은 비트 수준 사전 패키징 기술을 사용하여 GPU 메모리 시스템이 2의 거듭제곱이 아닌 비트 폭(예: 6 -조금).
구체적으로, 비트 수준 사전 패킹은 GPU 메모리 시스템 친화적인 방식으로 액세스할 수 있도록 6비트 양자화된 가중치를 재배열하는 것을 포함하여 모델 추론 이전에 가중치 데이터를 재구성하는 것입니다.
또한 GPU 메모리 시스템은 일반적으로 32비트 또는 64비트 블록으로 데이터에 액세스하므로 비트 수준 사전 패킹 기술도 6비트 가중치를 패킹하여 이러한 정렬된 형태로 저장 및 액세스할 수 있습니다. 블록.

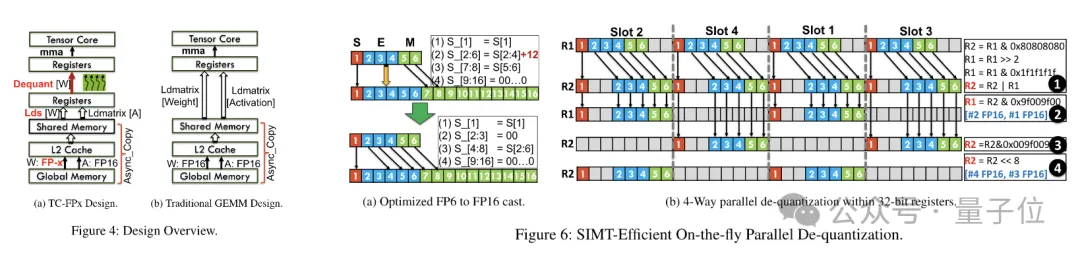
사전 패키징이 완료된 후 연구팀은 SIMT 코어의 병렬 처리 기능을 사용하여 레지스터의 FP6 가중치에 대해 병렬 역양자화를 수행하여 FP16 형식의 가중치를 생성합니다.
역양자화된 FP16 가중치는 레지스터에서 재구성된 후 Tensor Core로 전송됩니다. 재구성된 FP16 가중치는 선형 레이어 계산을 완료하기 위해 행렬 곱셈 작업을 수행하는 데 사용됩니다.
이 과정에서 팀은 SMIT 코어의 비트 수준 병렬성을 활용하여 전체 역양자화 과정의 효율성을 향상했습니다.
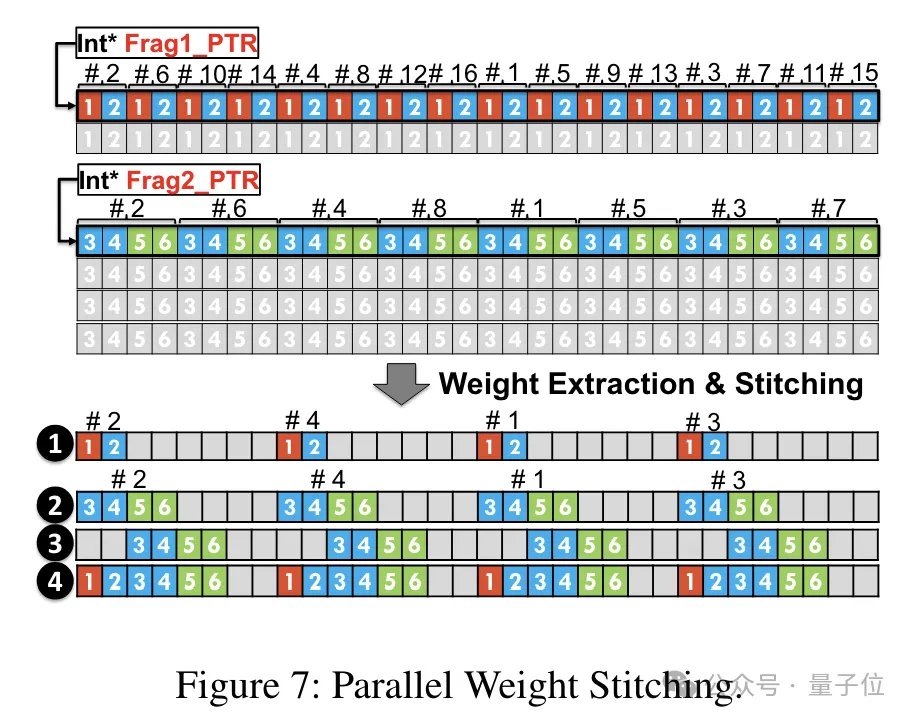
중량 재구성 작업을 병렬로 실행할 수 있도록 팀에서는 평행 중량 접합 기술도 사용했습니다.
구체적으로, 각 가중치는 여러 부분으로 나누어지고, 각 부분의 비트 폭은 2의 거듭제곱입니다(예: 6을 2+4 또는 4+2로 나누기).
역양자화하기 전에 가중치는 먼저 공유 메모리에서 레지스터로 로드됩니다. 각 가중치는 여러 부분으로 분할되므로 전체 가중치는 런타임 시 레지스터 수준에서 재구성되어야 합니다.
런타임 오버헤드를 줄이기 위해 TC-FPx에서는 가중치를 병렬 추출하고 접합하는 방법을 제안합니다. 이 접근 방식은 두 세트의 레지스터를 사용하여 32개의 FP6 가중치 세그먼트를 저장하고 이러한 가중치를 병렬로 재구성합니다.
동시에 가중치를 병렬로 추출하고 접합하려면 초기 데이터 레이아웃이 특정 순서 요구 사항을 충족하는지 확인해야 하므로 TC-FPx는 실행하기 전에 가중치 조각을 재정렬합니다.
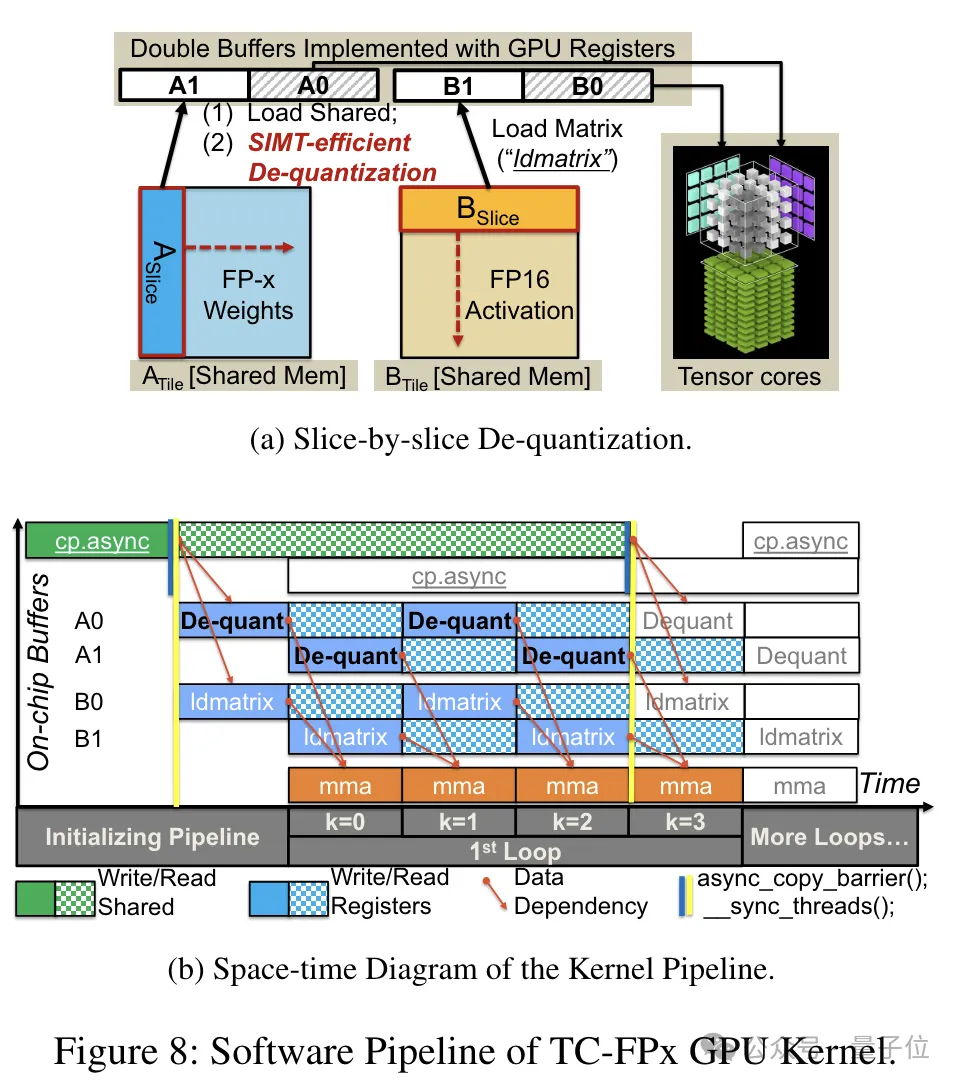
또한 TC-FPx는 소프트웨어 파이프라인도 설계했습니다. 이 파이프라인은 역양자화 단계와 Tensor Core의 행렬 곱셈 연산을 통합하여 명령어 수준 병렬성을 통해 전반적인 실행 효율성을 향상시킵니다.
논문 주소: https://arxiv.org/abs/2401.14112
위 내용은 단일 카드는 듀얼 카드보다 Llama를 70B 더 빠르게 실행합니다. Microsoft는 A100에 FP6을 넣었습니다 |의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!