
BEVFormer를 넘어! CR3DT: RV 융합은 새로운 SOTA(ETH)의 3D 감지 및 추적을 지원합니다.

- PHPz앞으로
- 2024-04-24 18:07:211153검색
앞서 작성 및 저자 개인적 이해
이 글에서는 3차원 표적 탐지 및 다중 표적 추적을 위한 카메라-밀리미터파 레이더 융합 방식(CR3DT)을 소개합니다. LiDAR 기반 방법은 이 분야에 대해 높은 표준을 설정했지만 높은 컴퓨팅 성능과 높은 비용으로 인해 자율 주행 분야에서 이 솔루션의 개발이 제한되었습니다. 비용 상대적으로 저렴하고 많은 학자들의 관심을 끌었지만 결과가 좋지 않았습니다. 따라서 카메라와 밀리미터파 레이더의 융합이 유망한 솔루션이 되고 있습니다. 저자는 기존 카메라 프레임워크인 BEVDet에서 밀리미터파 레이더의 공간 및 속도 정보를 융합하고 이를 CC-3DT++ 추적 헤드와 결합하여 3D 표적 탐지 및 추적의 정확도를 크게 향상시키고 성능과 비용 간의 모순을 무력화합니다.
주요 기여
센서 융합 아키텍처 제안된 CR3DT는 BEV 인코더 전후의 중간 융합 기술을 사용하여 밀리미터파 레이더 데이터를 통합하고 추적을 위해 준밀도 외관 임베딩 헤드를 사용합니다. 밀리미터파 레이더의 속도 추정을 사용한 상관 관계.
감지 성능 평가 CR3DT는 nuScenes 3D 감지 검증 세트에서 mAP 35.1%, NDS(nuScenes 감지 점수) 45.6%를 달성했습니다. 레이더 데이터에 포함된 풍부한 속도 정보를 활용하여 감지기의 평균 속도 오류(mAVE)는 SOTA 카메라 감지기에 비해 45.3% 감소합니다.
추적 성능 평가 CR3DT의 nuScenes 추적 검증 세트에 대한 추적 성능은 38.1% AMOTA로, 카메라 전용 SOTA 추적 모델에 비해 14.9% AMOTA 개선되었으며, 추적기에서 속도 정보를 명시적으로 사용하고 추가 개선이 이루어졌습니다. IDS 수가 약 43% 크게 감소했습니다.
모델 아키텍처
이 방법은 EV-Det 프레임워크를 기반으로 하며 RADAR의 공간 및 속도 정보를 융합하며 향상된 밀리미터파 레이더 탐지기를 명시적으로 사용하는 CC-3DT++ 추적 헤드와 결합됩니다. 데이터 연관을 통해 속도 추정을 통해 궁극적으로 3D 표적 탐지 및 추적이 가능해집니다.
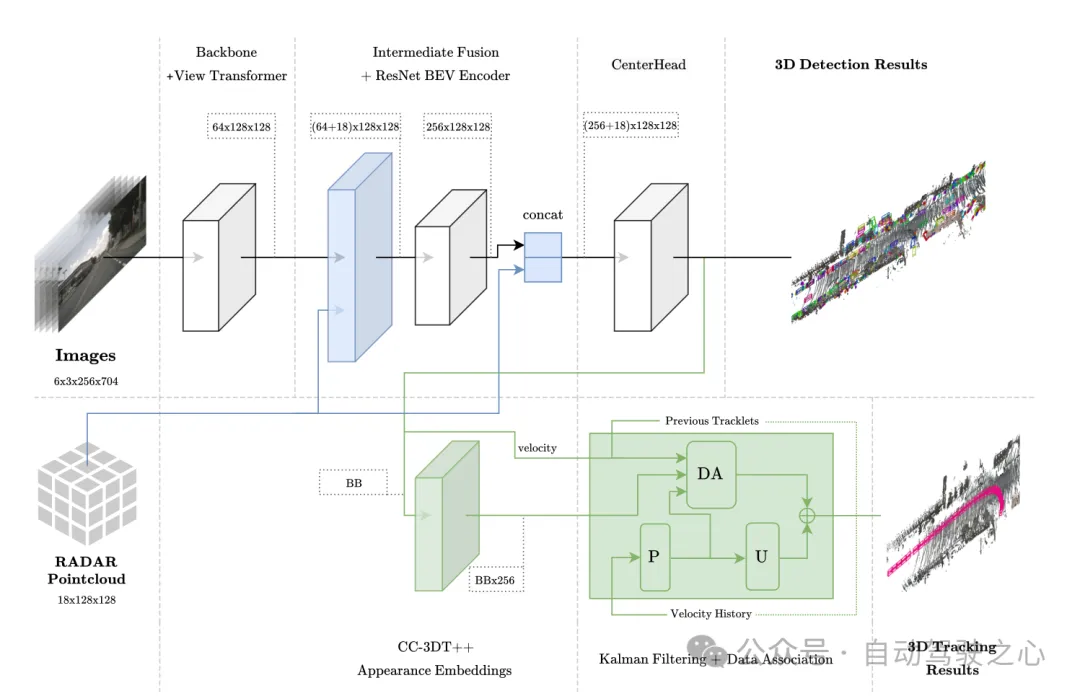 그림 1 전체 아키텍처. 감지 및 추적은 각각 연한 파란색과 녹색으로 강조 표시됩니다.
그림 1 전체 아키텍처. 감지 및 추적은 각각 연한 파란색과 녹색으로 강조 표시됩니다.
BEV 공간의 센서 융합
이 모듈은 내부 집계 및 연결을 포함하여 PointPillars와 유사한 융합 방법을 채택합니다. BEV 그리드는 해상도 0.8의 [-51.2, 51.2]로 설정되어 (128×128) 기능 그리드가 됩니다. 이미지 특징을 BEV 공간에 직접 투영합니다. 각 그리드 유닛의 채널 수는 64이고, 이미지 BEV 특징은 (64×128×128)입니다. 마찬가지로 Radar의 18차원 정보는 각 In에 집계됩니다. 그리드 단위에는 포인트의 x, y 및 z 좌표가 포함되며 레이더 데이터는 향상되지 않습니다. 저자는 레이더 포인트 클라우드가 이미 LiDAR 포인트 클라우드보다 더 많은 정보를 포함하고 있으므로 레이더 BEV 기능은 (18×128×128)임을 확인했습니다. 마지막으로 이미지 BEV 특징(64×128×128)과 Radar BEV 특징(18×128×128)은 BEV 특징 인코딩 계층의 입력으로 ((64+18)×128×128) 직접 연결됩니다. 후속 절제 실험에서는 차원이 (256×128×128)인 BEV 특징 인코딩 계층의 출력에 잔여 연결을 추가하는 것이 유익한 것으로 밝혀졌으며, 그 결과 CenterPoint 감지 헤드의 최종 입력 크기는 ( (256+18)×128×128).

그림 2 융합 작업을 위해 BEV 공간에 집계된 레이더 포인트 클라우드 시각화
추적 모듈 아키텍처
추적은 동작 상관 관계와 시각적 특징 유사성을 기반으로 서로 다른 두 프레임의 대상을 연결하는 것입니다. 훈련 과정에서 준밀도 다변량 양성 대비 학습을 통해 1차원 시각적 특징 임베딩 벡터를 얻은 후 CC-3DT의 추적 단계에서 탐지와 특징 임베딩을 동시에 사용합니다. 향상된 CR3DT 위치 감지 및 속도 추정을 활용하도록 데이터 연결 단계(그림 1의 DA 모듈)가 수정되었습니다. 자세한 내용은 다음과 같습니다.

실험 및 결과
는 nuScenes 데이터 세트를 기반으로 완료되었으며 모든 학습에서는 CBGS를 사용하지 않았습니다.
제한 모델
작가가 3090 그래픽 카드를 장착한 컴퓨터에서 전체 모델을 진행했기 때문에 제한 모델이라고 합니다. 모델의 타겟 검출 부분은 BEVDet을 검출 기준선으로 사용하고, 영상 인코딩 백본은 ResNet50이며, 영상 입력은 (3×256×704)로 설정되어 있으며, 모델에서는 과거 또는 미래 영상 정보를 사용하지 않는다. 배치 크기는 8로 설정됩니다. 레이더 데이터의 희소성을 완화하기 위해 5번의 스캔을 사용하여 데이터를 향상시킵니다. 융합 모델에는 추가적인 시간 정보가 사용되지 않습니다.
표적 탐지의 경우 mAP, NDS 및 mAVE 점수를 사용하여 추적하고 AMOTA, AMOTP 및 IDS를 사용하여 평가합니다.
객체 감지 결과
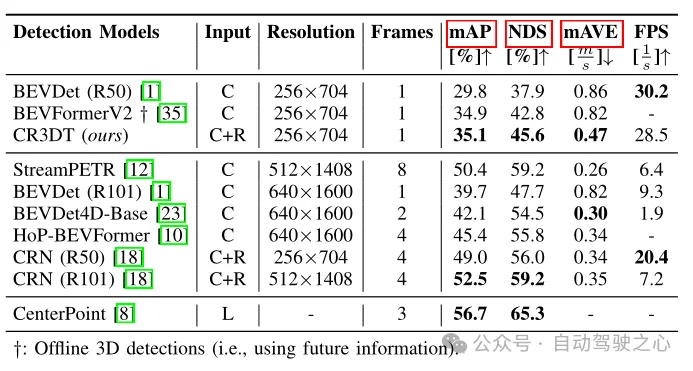
표 1 nuScenes 검증 세트의 감지 결과
표 1은 카메라만 사용하는 기본 BEVDet(R50) 아키텍처와 비교한 CR3DT의 감지 성능을 보여줍니다. 레이더를 추가하면 탐지 성능이 크게 향상되는 것은 분명합니다. 작은 해상도와 시간 프레임의 제약으로 CR3DT는 카메라 전용 BEVDet에 비해 mAP 5.3% 및 NDS 7.7% 향상을 성공적으로 달성했습니다. 그러나 컴퓨팅 파워의 한계로 인해 고해상도, 시간 정보 병합 등의 실험 결과를 얻지 못했습니다. 또한 추론 시간도 표 1의 마지막 열에 나와 있습니다.
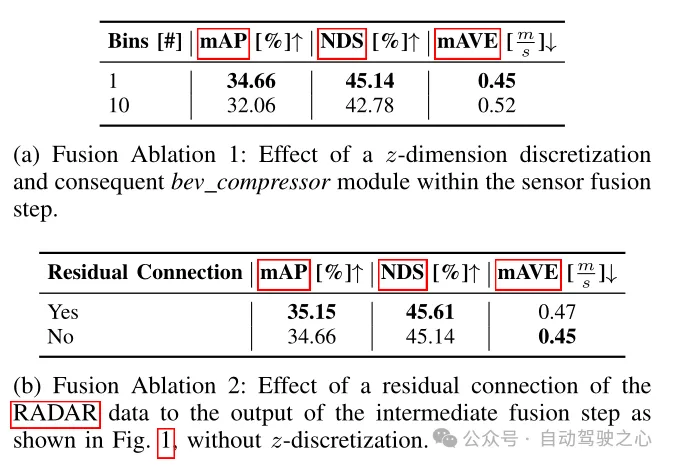
표 2 검출 프레임워크의 절제 실험
표 2에서는 다양한 융합 아키텍처가 검출 지표에 미치는 영향을 비교합니다. 여기서 융합 방법은 두 가지 유형으로 나뉩니다. 첫 번째는 논문에서 언급된 것으로, z차원 복셀화 및 후속 3D 컨볼루션을 포기하고 개선된 이미지 특징과 순수 RADAR 데이터를 열로 직접 집계하여 알려진 특징 크기를 얻습니다. 다른 하나는 개선된 이미지 특징과 순수 RADAR 데이터를 0.8 × 0.8 × 0.8m 크기의 큐브로 복셀화하여 대체 특징을 얻는 것입니다. 크기는 ((64+ 18) × 10 × 128 × 128)이므로 BEV 압축기 모듈은 3D 컨볼루션 형태로 사용해야 합니다. 표 2(a)에서 볼 수 있듯이 BEV 압축기의 수가 증가하면 성능이 저하되며 첫 번째 솔루션의 성능이 더 우수함을 알 수 있습니다. 또한 표 2(b)에서 레이더 데이터의 잔여 블록을 추가하면 성능이 향상될 수 있음을 알 수 있으며, 이는 이전 모델 아키텍처에서 언급한 BEV 기능 인코딩 계층의 출력에 잔여 연결을 추가하는 것이 이점임을 확인합니다. .
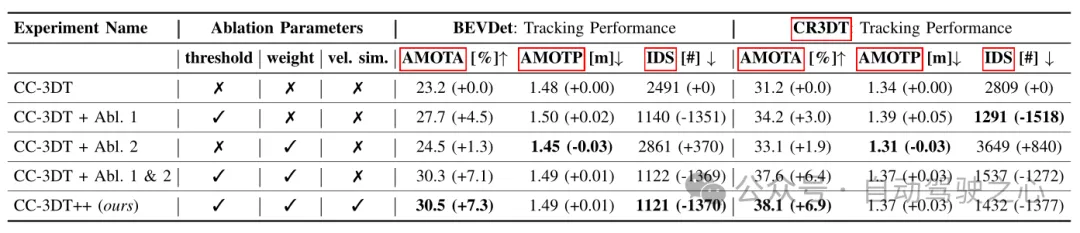 표 3 기본 BEVDet 및 CR3DT의 다양한 구성을 기반으로 한 nuScenes 검증 세트의 추적 결과
표 3 기본 BEVDet 및 CR3DT의 다양한 구성을 기반으로 한 nuScenes 검증 세트의 추적 결과
표 3은 nuScenes 검증 세트에서 개선된 CC3DT++ 추적 모델의 추적 결과를 보여줍니다. CR3DT 탐지 모델의 기준 및 성능. CR3DT 모델은 AMOTA의 성능을 기준 대비 14.9% 향상시키고 AMOTP에서는 0.11m 감소시킵니다. 또한 기준치 대비 IDS가 약 43% 감소한 것을 확인할 수 있다.
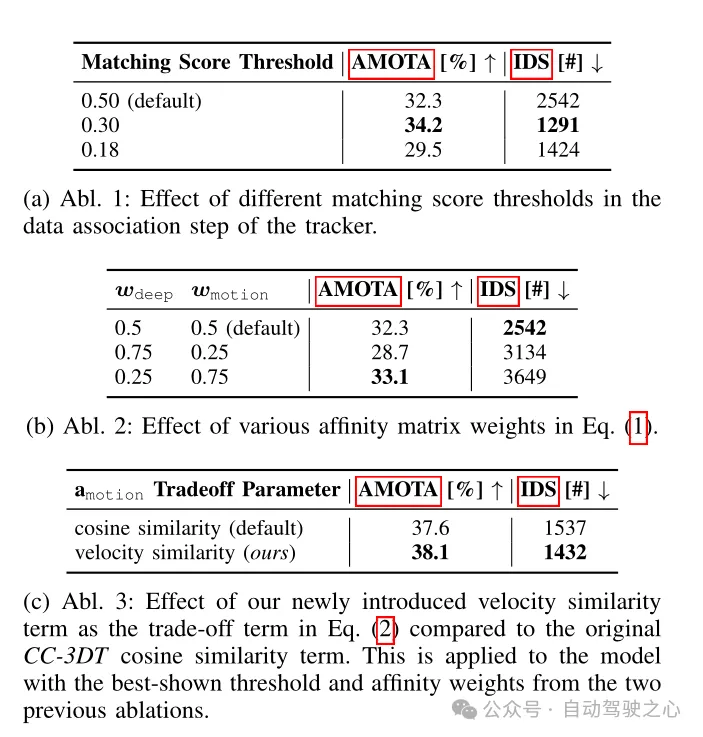
표 4 CR3DT 감지 백본에서 수행된 추적 아키텍처 절제 실험

결론
이 연구는 특히 3D 객체 감지 및 다중 객체 추적을 위한 효율적인 카메라-레이더 융합 모델인 CR3DT를 제안합니다. 레이더 데이터를 카메라 전용 BEVDet 아키텍처에 융합하고 CC-3DT++ 추적 아키텍처를 도입함으로써 CR3DT는 mAP와 AMOTA가 각각 5.35%와 14.9% 증가하여 3D 표적 탐지 및 추적 정확도를 크게 향상시켰습니다.
카메라와 밀리미터파 레이더를 통합하는 솔루션은 순수 LiDAR나 LiDAR와 카메라를 통합하는 솔루션에 비해 비용이 저렴하다는 장점이 있으며 현재의 자율주행차 개발에 가깝습니다. 또한 밀리미터파 레이더는 악천후에도 견고하다는 장점이 있으며 다양한 응용 시나리오에 직면할 수 있습니다. 현재 큰 문제는 밀리미터파 레이더 포인트 클라우드가 희박하고 높이 정보를 감지할 수 없다는 것입니다. 그러나 4D 밀리미터파 레이더의 지속적인 개발로 인해 향후 카메라와 밀리미터파 레이더 솔루션의 통합이 더 높은 수준에 도달하고 더 나은 결과를 얻을 것이라고 믿습니다!
위 내용은 BEVFormer를 넘어! CR3DT: RV 융합은 새로운 SOTA(ETH)의 3D 감지 및 추적을 지원합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
관련 기사
더보기- 기사에서는 LiDAR와 카메라 보정의 타임스탬프 동기화 문제에 대해 설명합니다.
- 새로운 Xpeng P5 스파이 사진 노출 : 외부 및 내부 리뉴얼, 레이더 구성 조정 가능
- Hesai Technology, FAW Group과 협력하여 최초의 글로벌 LiDAR 지능형 운전 솔루션 개발
- Hesai Technology는 업계 기록을 세웠습니다. 한 달에 50,000개의 차량 탑재 LiDAR를 제공하여 새로운 차원으로 발전했습니다.
- 레이더오토모티브(Radar Automotive)의 신형 4륜구동 픽업트럭 '레이더 호라이즌(Radar Horizon)' 출시를 앞두고 있다. 4초 만에 0~60초 가속이 가능하다.