
BEVFusion을 넘어! DifFUSER: 확산모델이 자율주행 멀티태스크 진입(BEV 세분화 + 감지 듀얼 SOTA)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-04-22 17:49:07825검색
앞서 작성 및 저자 개인의 이해
현재 자율주행 기술이 성숙해지고 자율주행 인식 작업에 대한 수요가 증가함에 따라 업계와 학계에서는 동시에 완성할 수 있는 이상적인 인식 알고리즘 모델에 대한 기대가 크다. BEV 공간 기반의 3차원 표적 탐지 및 의미론적 분할 작업. 자율 주행이 가능한 차량의 경우 일반적으로 서라운드 뷰 카메라 센서, 라이더 센서, 밀리미터파 레이더 센서가 장착되어 다양한 방식으로 데이터를 수집합니다. 이를 통해 서로 다른 모달 데이터 간의 보완적인 이점을 최대한 활용하여 서로 다른 양식 간의 데이터 보완적인 이점을 만들 수 있습니다. 예를 들어 3D 포인트 클라우드 데이터는 3D 타겟 감지 작업에 대한 정보를 제공할 수 있는 반면, 컬러 이미지 데이터는 의미론적 분할 작업에 대한 더 많은 정보를 제공할 수 있습니다. . 정확한 정보. 서로 다른 모달 데이터 간의 보완적인 이점을 고려하여 서로 다른 모달 데이터의 유효 정보를 동일한 좌표계로 변환함으로써 후속 공동 처리 및 의사 결정이 촉진됩니다. 예를 들어, 3D 포인트 클라우드 데이터는 BEV 공간을 기반으로 하는 포인트 클라우드 데이터로 변환될 수 있고, 서라운드 뷰 카메라의 이미지 데이터는 카메라의 내부 및 외부 매개변수 보정을 통해 3D 공간에 투영될 수 있습니다. 다른 모달 데이터. 다양한 모달 데이터를 활용하면 단일 모달 데이터보다 더 정확한 인식 결과를 얻을 수 있습니다. 이제 우리는 이미 다중 모드 인식 알고리즘 모델을 자동차에 배포하여 보다 강력하고 정확한 공간 인식 결과를 출력할 수 있게 되었습니다. 정확한 공간 인식 결과를 통해 자율 주행 기능 구현을 위해 보다 안정적이고 안전한 보장을 제공할 수 있습니다.
최근 Transformer 네트워크 프레임워크를 기반으로 하는 다중 감각 및 다중 모드 데이터 융합을 위한 많은 3D 인식 알고리즘이 학계 및 산업계에서 제안되었지만, 모두 Transformer의 교차 주의 메커니즘을 사용하여 다중 모드 데이터 통합을 달성합니다. 이상적인 3D 표적 탐지 결과를 얻기 위해 그들 사이의 융합. 그러나 이러한 유형의 다중 모드 기능 융합 방법은 BEV 공간 기반의 의미 분할 작업에 완전히 적합하지 않습니다. 또한 서로 다른 양식 간의 정보 융합을 완성하기 위해 교차 주의 메커니즘을 사용하는 것 외에도 많은 알고리즘이 LSA 기반 순방향 벡터 변환을 사용하여 융합된 특징을 구성하지만 다음과 같은 몇 가지 문제도 있습니다. 다음).
- 현재 제안된 다중 모드 융합 관련 3D 센싱 알고리즘으로 인해 서로 다른 모달 데이터 특성의 융합 방법이 충분히 설계되지 않아 인식 알고리즘 모델이 센서 데이터 간의 복잡한 연결 관계를 정확하게 포착할 수 없습니다. 따라서 모델의 최종 인지 성능에 영향을 미칩니다.
- 서로 다른 센서에서 데이터를 수집하는 과정에서 관련 없는 노이즈 정보가 필연적으로 도입됩니다. 서로 다른 양식 간의 이러한 고유 노이즈로 인해 서로 다른 모달 기능을 융합하는 과정에 노이즈가 혼합되어 다중 모드 기능 융합이 발생합니다. 부정확성은 후속 인식 작업에 영향을 미칩니다.
위에서 언급한 다중 모드 융합 프로세스에서 최종 모델의 인식 능력에 영향을 미칠 수 있는 많은 문제를 고려하고, 최근 생성 모델이 보여준 강력한 성능을 고려하여 생성 모델을 탐색했습니다. 여러 센서 간의 다중 모드 융합 및 잡음 제거 작업을 달성합니다. 이를 바탕으로 다중 모드 인식 작업을 구현하기 위해 조건부 확산 기반 생성 모델 인식 알고리즘 DifFUSER를 제안합니다. 아래 그림에서 볼 수 있듯이, 우리가 제안한 DifFUSER 다중 모드 데이터 융합 알고리즘은 보다 효과적인 다중 모드 융합 프로세스를 달성할 수 있습니다.  DifFUSER 다중 모드 데이터 융합 알고리즘은 보다 효과적인 다중 모드 융합 프로세스를 달성할 수 있습니다. 이 방법은 주로 두 단계를 포함합니다. 첫째, 생성 모델을 사용하여 입력 데이터의 노이즈를 제거하고 향상시켜 깨끗하고 풍부한 다중 모드 데이터를 생성합니다. 그런 다음 생성 모델에서 생성된 데이터는 더 나은 인식 효과를 얻기 위해 다중 모드 융합에 사용됩니다. DifFUSER 알고리즘의 실험 결과는 우리가 제안한 다중 모드 데이터 융합 알고리즘이 보다 효과적인 다중 모드 융합 프로세스를 달성할 수 있음을 보여줍니다. 다중 모드 인식 작업을 구현할 때 이 알고리즘은 보다 효과적인 다중 모드 융합 프로세스를 달성하고 모델의 인식 기능을 향상시킬 수 있습니다. 또한, 알고리즘의 다중 모드 데이터 융합 알고리즘은 보다 효율적인 다중 모드 융합 프로세스를 달성할 수 있습니다. 전체적으로
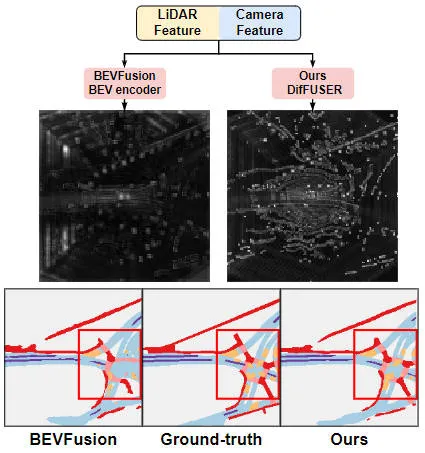
제안된 알고리즘 모델과 다른 알고리즘 모델의 결과를 시각적으로 비교한 차트
문서 링크: https://arxiv.org/pdf/2404.04629.pdf
전체 아키텍처 및 세부 정보 네트워크 모델
"DifFUSER 알고리즘의 모듈 세부 사항, 조건부 확산 모델 기반 다중 작업 인식 알고리즘"은 작업 인식 문제를 해결하는 데 사용되는 알고리즘입니다. 아래 그림은 제안한 DifFUSER 알고리즘의 전체 네트워크 구조를 보여준다. 본 모듈에서는 과제 인식 문제를 해결하기 위해 조건부 확산 모델을 기반으로 하는 다중 작업 인식 알고리즘을 제안한다. 이 알고리즘의 목표는 작업별 정보를 네트워크에 확산하고 집계하여 다중 작업 학습의 성능을 향상시키는 것입니다. DifFUSER 알고리즘 통합
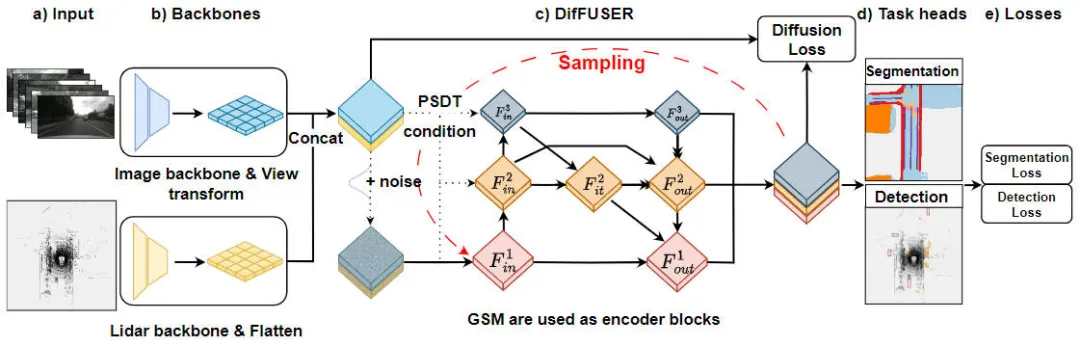 제안된 DifFUSER 인식 알고리즘 모델 네트워크 구조도
제안된 DifFUSER 인식 알고리즘 모델 네트워크 구조도
위 그림에서 볼 수 있듯이 우리가 제안한 DifFUSER 네트워크 구조는 크게 3개의 하위 네트워크, 즉 백본 네트워크 부분, DifFUSER의 멀티모달 데이터 융합 부분, 의미론적 분할 작업의 마지막 BEV 헤드 부분입니다. 3D 물체 감지 인식 작업의 머리 부분입니다. 백본 네트워크 부분에서는 ResNet이나 VGG와 같은 기존 딥러닝 네트워크 아키텍처를 사용하여 입력 데이터의 높은 수준의 특징을 추출합니다. DifFUSER의 다중 모드 데이터 융합 부분은 여러 병렬 분기를 사용하며, 각 분기는 다양한 센서 데이터 유형(예: 이미지, 라이더, 레이더 등)을 처리하는 데 사용됩니다. 각 지점에는 자체 백본 네트워크 부분이 있습니다
- : 이 부분은 주로 네트워크 모델에서 입력된 2D 이미지 데이터와 3D LiDAR 포인트 클라우드 데이터에 대한 특징 추출을 수행하여 해당 BEV 시맨틱 특징을 출력합니다. 영상 특징을 추출하는 백본 네트워크로는 주로 2차원 영상 백본 네트워크와 원근 변환 모듈이 포함된다. 3D LiDAR 포인트 클라우드 특징을 추출하는 백본 네트워크로는 주로 3D 포인트 클라우드 백본 네트워크와 Feature Flatten 모듈이 포함됩니다.
- DifFUSER 다중 모드 데이터 융합 부분: 우리가 제안한 DifFUSER 모듈은 계층적 양방향 기능 피라미드 네트워크 형태로 서로 연결됩니다. 이 구조를 cMini-BiFPN이라고 합니다. 이 구조는 잠재적인 확산을 위한 대체 구조를 제공하며 다양한 센서 데이터의 다중 스케일 및 너비-높이 세부 기능 정보를 더 잘 처리할 수 있습니다.
- BEV 의미 분할, 3D 타겟 탐지 인식 작업 헤드 부분: 우리의 알고리즘 모델은 BEV 공간에서 3차원 타겟 탐지 결과와 의미 분할 결과를 동시에 출력할 수 있으므로 3D 인식 작업 헤드에는 3D 탐지 헤드와 의미 분할 헤드가 포함됩니다. . 또한 우리가 제안한 알고리즘 모델에 포함된 손실에는 확산 손실, 감지 손실 및 의미 분할 손실이 포함되며, 모든 손실을 합산하여 역전파를 통해 네트워크 모델의 매개변수를 업데이트합니다.
다음으로 모델의 각 주요 하위 부분에 대한 구현 세부 사항을 주의 깊게 소개하겠습니다.
융합 아키텍처 설계(Conditional-Mini-BiFPN, cMini-BiFPN)
자율주행 시스템의 인식 작업에서는 알고리즘 모델이 현재 외부 환경을 실시간으로 인식할 수 있는 것이 중요하므로, 확산 모듈의 성능과 효율성을 보장하는 것은 매우 중요합니다. 따라서 우리는 양방향 기능 피라미드 네트워크에서 영감을 얻어 조건부-미니-BiFPN이라고 하는 유사한 조건의 BiFPN 확산 아키텍처를 도입했습니다. 구체적인 네트워크 구조는 위 그림에 나와 있습니다.


Progressive Sensor Dropout Training(PSDT)
자율주행차의 경우 자율주행 획득 센서의 성능이 매우 중요합니다. 카메라 센서나 라이더 센서가 막히거나 오작동하게 되어 최종 자율주행 시스템의 안전성과 작동 효율성에 영향을 미치게 됩니다. 이러한 고려 사항을 바탕으로 우리는 센서가 차단될 수 있는 상황에서 제안된 알고리즘 모델의 견고성과 적응성을 향상시키기 위한 점진적인 센서 드롭아웃 훈련 패러다임을 제안했습니다.
우리가 제안한 점진적인 센서 드롭아웃 훈련 패러다임을 통해 알고리즘 모델은 카메라 센서와 LiDAR 센서에서 수집한 두 가지 모달 데이터의 분포를 활용하여 누락된 특징을 재구성할 수 있으며 이를 통해 열악한 조건 성능과 견고성에서 탁월한 적응을 달성할 수 있습니다. 구체적으로 우리는 훈련 목표, 확산 모듈에 대한 노이즈 입력, 센서 손실 또는 오작동 조건 시뮬레이션 등 세 가지 방법으로 이미지 데이터와 LiDAR 포인트 클라우드 데이터의 특징을 활용합니다. 훈련 중에 카메라 센서 또는 LiDAR 센서 입력의 손실률을 0에서 미리 정의된 최대값 a = 25까지 점차적으로 늘립니다. 전체 과정은 다음 공식으로 표현할 수 있습니다.
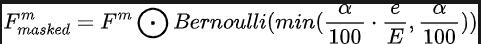
그 중 은 현재 모델이 속한 훈련 라운드 수를 나타내며, 각 특성이 삭제될 확률을 나타내기 위해 드롭아웃 확률을 정의합니다. 이러한 점진적인 훈련 프로세스를 통해 모델은 효과적으로 노이즈를 제거하고 더욱 표현력이 풍부한 기능을 생성하도록 훈련될 뿐만 아니라 단일 센서에 대한 의존도를 최소화하여 더 큰 복원력으로 불완전한 센서의 처리를 향상시킵니다.
Gated Self-Conditioned Modulation Diffusion Module(GSM 확산 모듈)

구체적으로 Gated Self-Conditioned Modulation Diffusion Module의 네트워크 구조는 아래 그림과 같습니다
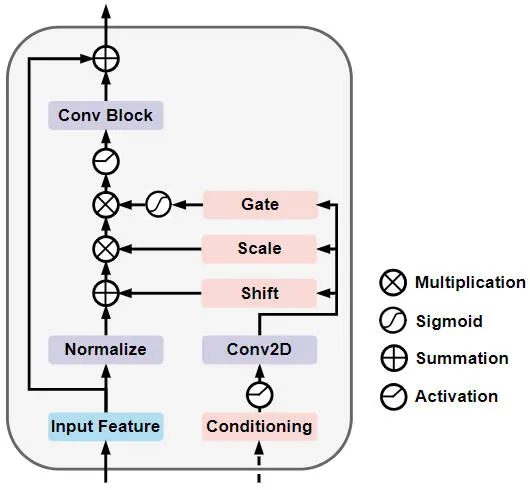
Gated Self-Conditioned Modulation Diffusion 모듈 네트워크 구조의 모식도

실험 결과 및 평가 지표
정량 분석 부분
제안한 알고리즘 모델 DifFUSER의 다중 작업에 대한 지각 결과를 검증하기 위해 주로 수행했습니다. nuScenes 데이터 세트에서 BEV 공간을 기반으로 한 3D 타겟 탐지 및 의미론적 분할 실험을 수행합니다.
먼저 의미론적 분할 작업에 대해 제안된 알고리즘 모델 DifFUSER의 성능을 다른 다중 모드 융합 알고리즘과 비교했습니다. 구체적인 실험 결과는 다음 표에 나와 있습니다.
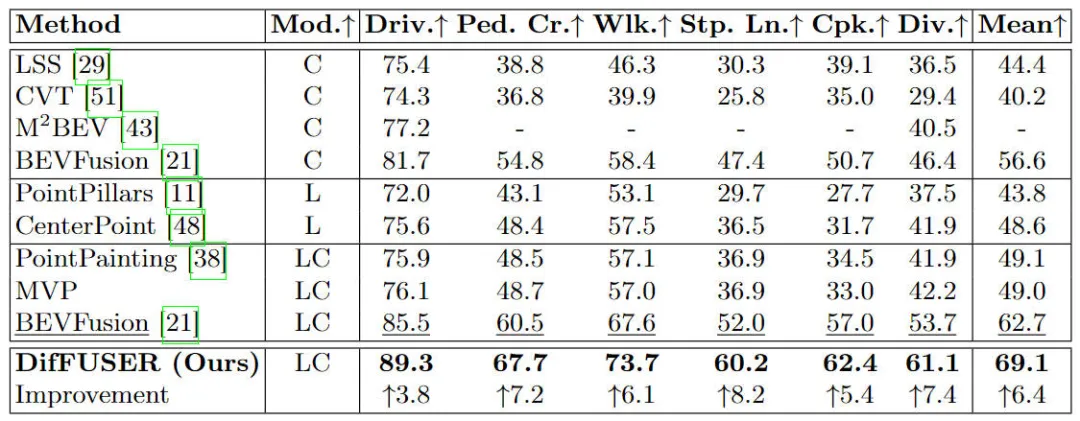 nuScenes 데이터 세트에 대한 다양한 알고리즘 모델 비교 BEV 공간 기반 의미 분할 작업의 실험 결과
nuScenes 데이터 세트에 대한 다양한 알고리즘 모델 비교 BEV 공간 기반 의미 분할 작업의 실험 결과
우리가 제안한 알고리즘 모델이 기본 모델에 비해 성능이 크게 향상되었음을 실험 결과에서 확인할 수 있습니다. 구체적으로 BEVFusion 모델의 mIoU 값은 62.7%에 불과한 반면, 우리가 제안한 알고리즘 모델은 69.1%에 도달하여 6.4% 포인트 개선되었으며, 이는 우리가 제안한 알고리즘이 다양한 범주에서 더 많은 장점을 가지고 있음을 보여줍니다. 또한, 아래 그림은 우리가 제안한 알고리즘 모델의 장점을 보다 직관적으로 보여줍니다. 특히, BEVFusion 알고리즘은 특히 센서 오정렬이 더 분명한 장거리 시나리오에서 불량한 분할 결과를 출력합니다. 이에 비해 우리의 알고리즘 모델은 더 명확한 세부 정보와 더 적은 노이즈로 더 정확한 분할 결과를 제공합니다.
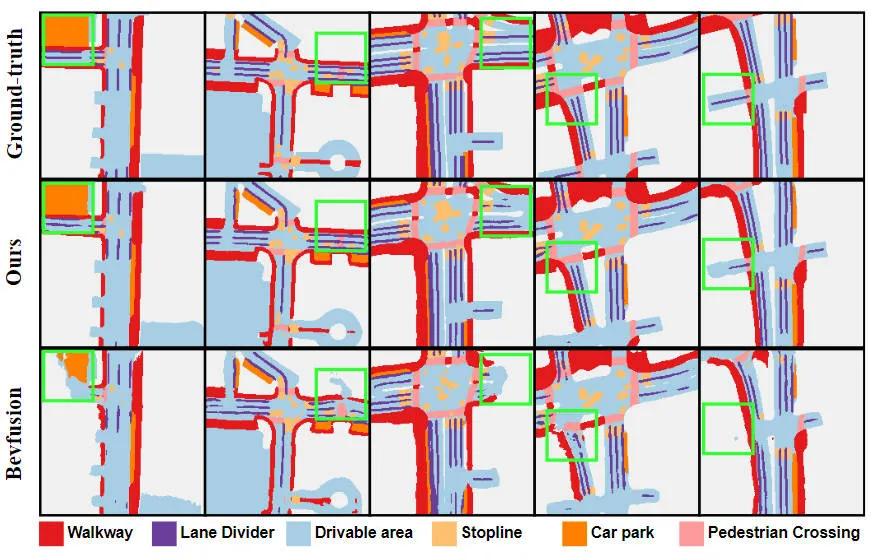
제안한 알고리즘 모델과 기준선 모델의 분할 시각화 결과 비교
또한 제안한 알고리즘 모델을 다른 3D 타겟 탐지 알고리즘 모델과도 비교했습니다. 구체적인 실험 결과는 아래 표와 같습니다.
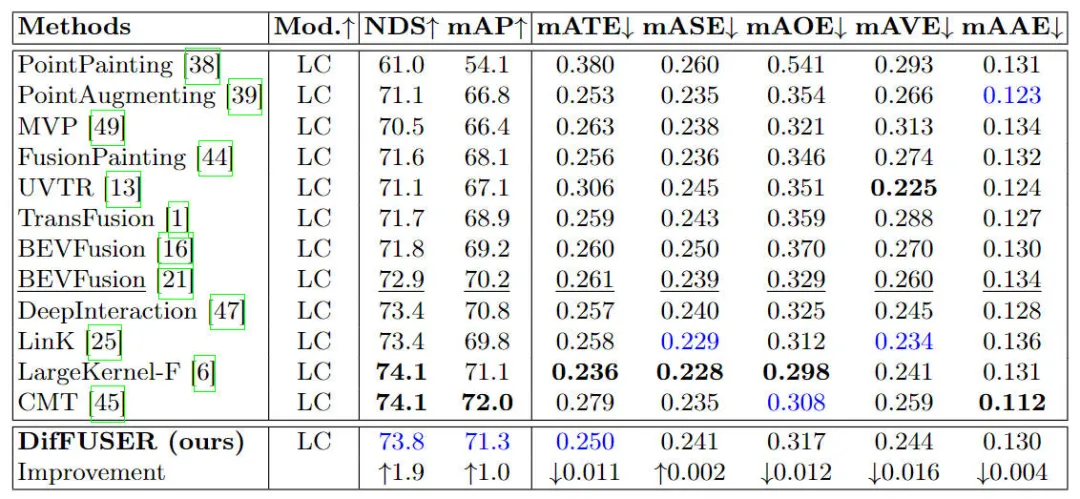
nuScenes 데이터세트의 3D 타겟 탐지 작업에 대한 다양한 알고리즘 모델의 실험 결과 비교
표에 나열된 결과에서 볼 수 있듯이 제안된 알고리즘 모델 DifFUSER는 NDS와 mAP 모두에서 더 나은 성능을 나타냅니다. 기준 모델 BEVFusion의 72.9% NDS 및 70.2% mAP와 비교하여 우리의 알고리즘 모델은 각각 1.8% 및 1.0% 더 높습니다. 관련 지표의 개선은 우리가 제안한 다중 모드 확산 융합 모듈이 기능 축소 및 기능 개선 프로세스에 효과적임을 보여줍니다.
또한 센서 장애 또는 폐색 시 제안된 알고리즘 모델의 지각적 견고성을 보여주기 위해 아래 그림과 같이 관련 분할 작업의 결과를 비교했습니다.
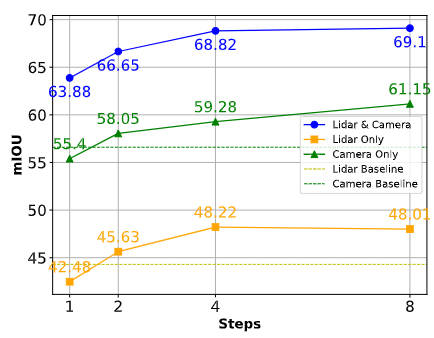
다양한 상황에서의 알고리즘 성능 비교
위 그림에서 알 수 있듯이 샘플링이 충분할 경우 우리가 제안한 알고리즘 모델은 누락된 특징을 효과적으로 보완하고 누락된 센서 수집의 기초로 사용될 수 있습니다. 정보. 대체 콘텐츠. 합성 기능을 생성하고 활용하는 제안된 DifFUSER 알고리즘 모델의 기능은 단일 센서 양식에 대한 의존성을 효과적으로 완화하고 모델이 다양하고 까다로운 환경에서 원활하게 실행될 수 있도록 보장합니다.
정성 분석 부분
다음 그림은 우리가 제안한 DifFUSER 알고리즘 모델의 3D 타겟 탐지 및 의미 분할 결과를 BEV 공간에서 시각화한 것입니다. 우리가 제안한 알고리즘 모델이 탐지가 좋은 것을 시각적 결과에서 확인할 수 있습니다. 및 분할 효과.

결론
이 기사에서는 네트워크 모델의 융합 아키텍처를 개선하고 잡음 제거 특성을 활용하여 네트워크 모델의 융합 품질을 향상시키는 확산 모델 기반의 다중 모드 인식 알고리즘 모델 DifFUSER를 제안합니다. 확산 모델의 Nuscenes 데이터 세트의 실험 결과는 우리가 제안한 알고리즘 모델이 BEV 공간의 의미 분할 작업에서 SOTA 분할 성능을 달성하고, 3D 타겟 탐지 작업에서 현재 SOTA 알고리즘 모델과 유사한 탐지 성능을 달성할 수 있음을 보여줍니다.
위 내용은 BEVFusion을 넘어! DifFUSER: 확산모델이 자율주행 멀티태스크 진입(BEV 세분화 + 감지 듀얼 SOTA)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!