
새로 출시된 Llama 3를 빠르게 체험할 수 있는 6가지 방법!

- 王林앞으로
- 2024-04-19 12:16:01863검색

어젯밤 Meta는 Llama 3 8B 및 70B 모델을 출시했습니다. Llama 3 명령 조정 모델은 대화/채팅 사용 사례에 맞게 미세 조정 및 최적화되어 일반 벤치마크에서 기존의 많은 오픈 소스 채팅 모델보다 성능이 뛰어납니다. 예를 들어 Gemma 7B 및 Mistral 7B입니다.
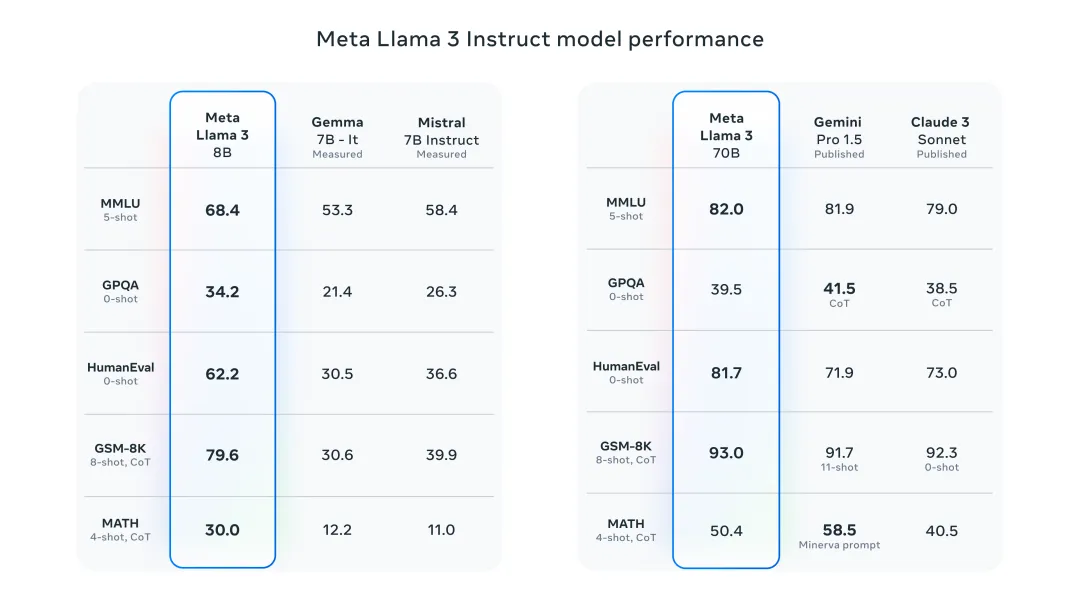
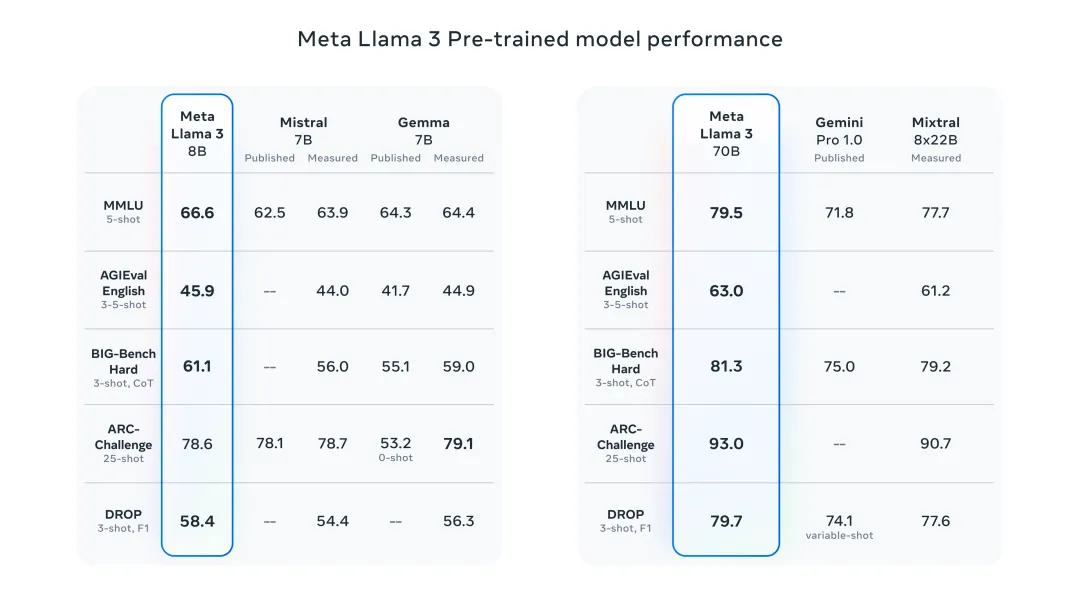
Llama+3 모델은 데이터와 규모가 향상되어 새로운 차원에 도달했습니다. Meta에서 최근 출시한 2개의 맞춤형 24K GPU 클러스터에서 15T 이상의 데이터 토큰에 대해 교육을 받았습니다. 이 훈련 데이터 세트는 Llama 2보다 7배 더 크고 4배 더 많은 코드를 포함합니다. 이를 통해 Llama 모델의 기능을 현재 최고 수준으로 끌어올려 Llama 2보다 두 배 긴 8K 이상의 텍스트 길이를 지원합니다.
새롭게 출시된 라마3를 빠르게 체험할 수 있는 6가지 방법을 아래에서 소개해드리겠습니다!
온라인으로 Llama 3를 경험해 보세요
HuggingChat
llama2.ai
https: //www.llama2.ai/
로컬에서 Llama 3를 경험해 보세요
LM Studio
https://lmstudio.ai/
CodeGPT
https //marketplace.visualstudio.com/items?itemName=DanielSanMedium.dscodegpt&ssr=false
CodeGPT를 사용하기 전에 Ollama를 사용하여 해당 모델을 가져오는 것을 잊지 마세요. 예를 들어 llama3:8b 모델을 가져오려면 ollama pull llama3:8b를 입력합니다. ollama를 로컬에 설치하지 않은 경우 "단 몇 분 만에 로컬 대형 언어 모델 배포!"를 읽어보세요.
Ollama
Run Llama 3 8B 모델:
ollama run llama3
Run Llama 3 70B 모델:
ollama run llama3:70b
WebUI 및 Ollama 열기

https://pinokio.computer/item ?uri=https://github.com/cocktailpeanutlabs/open-webui.
위 내용은 새로 출시된 Llama 3를 빠르게 체험할 수 있는 6가지 방법!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!