
Google은 대형 모델의 '기억상실'을 바로잡기 위해 조치를 취합니다! 피드백 주의 메커니즘은 컨텍스트를 '업데이트'하는 데 도움이 되며 대형 모델을 위한 무제한 메모리 시대가 다가오고 있습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-04-17 15:40:01570검색
편집자 | Yi Feng
제작자: 51CTO Technology Stack(WeChat ID: blog51cto)
Google이 마침내 조치를 취했습니다! 우리는 더 이상 대형 모델의 '기억상실증'에 시달리지 않을 것입니다.
대형 모델에 무제한 메모리를 제공하겠다고 약속하는 TransformerFAM이 탄생했습니다!
더 이상 고민하지 말고 TransformerFAM의 "효율성"을 살펴보겠습니다.
 사진
사진
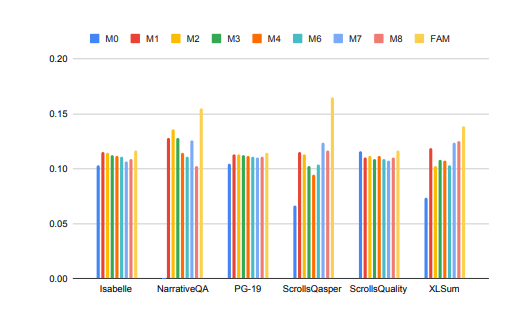
장기 컨텍스트 작업 처리에서 대형 모델의 성능이 크게 향상되었습니다!
위 그림에서 Isabelle 및 NarrativeQA와 같은 작업을 수행하려면 모델이 많은 양의 상황 정보를 이해하고 처리하며 특정 질문에 대한 정확한 답변이나 요약을 제공해야 합니다. 모든 작업에서 FAM으로 구성된 모델은 다른 모든 BSWA 구성보다 성능이 뛰어나며 특정 지점을 지나면 BSWA 메모리 세그먼트 수의 증가가 메모리 성능을 계속 향상시킬 수 없음을 알 수 있습니다.
긴 문자와 긴 대화로 가는 길에는 대형 모델인 FAM의 '잊을 수 없는' 존재가 있는 것 같습니다.
Google 연구원들은 새로운 Transformer 아키텍처인 Feedback Attention Memory인 FAM을 출시했습니다. 피드백 루프를 사용하여 네트워크가 자체 드리프트 성능에 주의를 기울일 수 있도록 하고 Transformer의 내부 작업 메모리 출현을 촉진하며 무한히 긴 시퀀스를 처리할 수 있도록 합니다.
간단히 말하면, 이 전략은 대형 모델의 "기억상실"을 인위적으로 퇴치하기 위한 전략과 약간 비슷합니다. 대형 모델과 대화할 때마다 프롬프트를 다시 입력하세요. 단지 FAM의 접근 방식이 더욱 발전했다는 점입니다. 모델이 새로운 데이터 블록을 처리할 때 이전에 처리된 정보(즉, FAM)를 동적으로 업데이트되는 컨텍스트로 사용하고 이를 현재 처리 프로세스에 다시 통합합니다.
이렇게 하면 '잊는 것' 문제를 잘 해결할 수 있습니다. 더 좋은 점은 장기 작업 기억을 유지하기 위한 피드백 메커니즘 도입에도 불구하고 FAM은 추가 가중치 없이 사전 훈련된 모델과의 호환성을 유지하도록 설계되었다는 것입니다. 따라서 이론적으로 대형 모델의 강력한 메모리는 모델을 둔하게 만들거나 더 많은 컴퓨팅 리소스를 소비하지 않습니다.
그럼 이렇게 멋진 TransformerFAM은 어떻게 발견됐나요? 관련 기술은 무엇입니까?
1. TransformerFAM이 왜 대형 모델을 "더 많이 기억"하도록 도울 수 있나요?
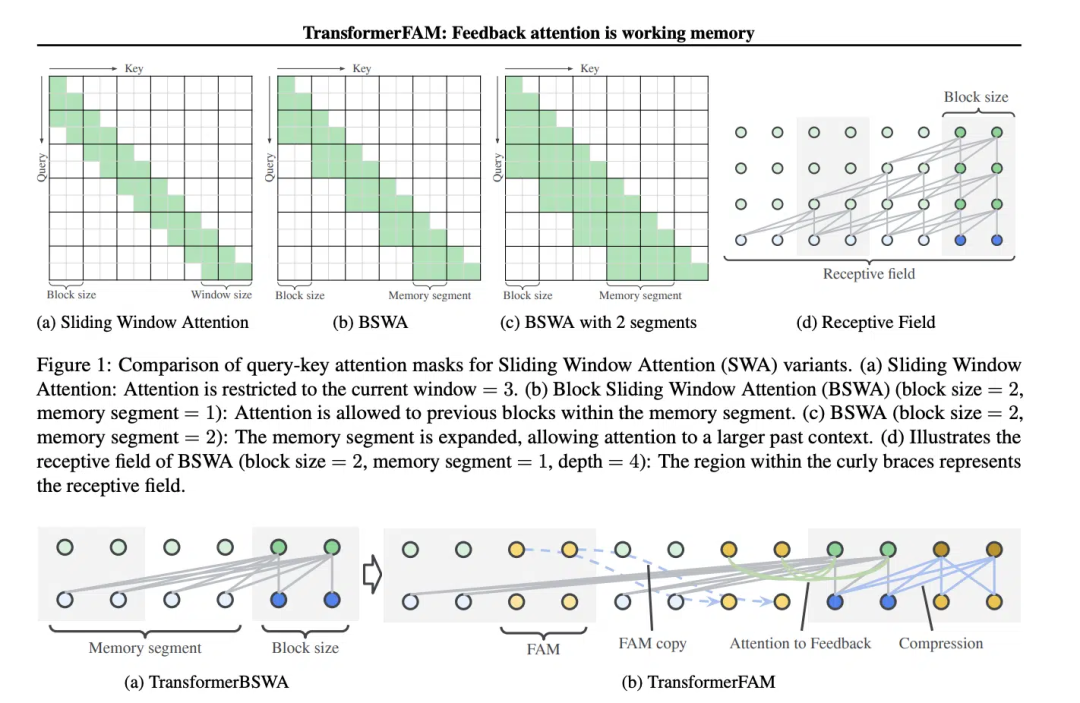
SWA(Sliding Window Attention) 개념은 TransformerFAM 설계에 매우 중요합니다.
기존 Transformer 모델에서는 시퀀스 길이가 증가함에 따라 self-attention의 복잡성이 2차적으로 증가하여 긴 시퀀스를 처리하는 모델의 능력이 제한됩니다.
“영화 메멘토(2000)의 주인공은 순행성 기억상실증을 앓고 있는데, 이는 지난 10분 동안 일어난 일을 기억하지 못하지만 장기기억은 온전해 중요한 정보를 몸에 문신으로 새겨야 한다는 뜻이다. 이를 기억하는 것은 LLM(대형 언어 모델)의 현재 상태와 유사합니다."라고 논문에서는 읽습니다.
 영화 "Memento"의 스크린샷, 인터넷에서 가져온 사진
영화 "Memento"의 스크린샷, 인터넷에서 가져온 사진
Sliding Window Attention(Sliding Window Attention)은 긴 시퀀스 데이터를 처리하기 위한 향상된 Attention 메커니즘입니다. 이는 컴퓨터 과학의 슬라이딩 윈도우 기술에서 영감을 받았습니다. 자연어 처리(NLP) 작업을 처리할 때 SWA를 사용하면 모델이 전체 시퀀스가 아닌 각 시간 단계에서 입력 시퀀스의 고정 크기 창에만 집중할 수 있습니다. 따라서 SWA의 장점은 계산 노력을 크게 줄일 수 있다는 것입니다.
 Pictures
Pictures
그러나 SWA에는 주의 범위가 창 크기에 의해 제한되어 모델이 창 밖의 중요한 정보를 고려할 수 없기 때문에 제한이 있습니다.
TransformerFAM은 슬라이딩 윈도우 어텐션의 각 블록에 컨텍스트 표현을 다시 입력하기 위해 피드백 활성화를 추가하여 통합 어텐션, 블록 수준 업데이트, 정보 압축 및 전역 컨텍스트 저장을 달성합니다.
TransformerFAM에서는 피드백 루프를 통해 개선이 이루어집니다. 특히, 현재 시퀀스 블록을 처리할 때 모델은 현재 창 내의 요소에 초점을 맞출 뿐만 아니라 이전에 처리된 상황별 정보(예: 이전 "피드백 활성화")를 추가 입력으로 어텐션 메커니즘에 다시 도입합니다. 이런 방식으로 모델의 주의 창이 시퀀스 위로 미끄러지더라도 이전 정보에 대한 기억과 이해를 유지할 수 있습니다.
따라서 이러한 개선 이후 TransformerFAM은 LLM에 무한 길이 시퀀스를 처리할 수 있는 잠재력을 제공합니다!
두 번째, 대규모 작업 메모리 모델을 통해 AGI로 계속 이동
TransformerFAM은 연구에서 긍정적인 전망을 보였으며, 이는 문서 처리 요약, 스토리 생성과 같은 긴 텍스트 작업을 이해하고 생성하는 데 있어 AI의 성능을 의심할 여지 없이 향상시킬 것입니다. , Q&A 및 기타 작업.
 Pictures
Pictures
동시에 지능적인 비서이든 감성적 동반자이든 무제한 메모리를 갖춘 AI가 더 매력적으로 들립니다.
흥미롭게도 TransformerFAM의 디자인은 생물학의 기억 메커니즘에서 영감을 얻었으며 이는 AGI가 추구하는 자연 지능 시뮬레이션과 일치합니다. 이 논문은 신경과학의 개념인 주의 기반 작업 기억을 딥러닝 분야에 통합하려는 시도입니다.
TransformerFAM은 피드백 루프를 통해 대규모 모델에 작업 메모리를 도입하여 모델이 단기 정보를 기억할 뿐만 아니라 장기 시퀀스에서 핵심 정보의 메모리를 유지할 수 있도록 합니다.
대담한 상상력을 통해 연구자들은 현실 세계와 추상적 개념 사이에 다리를 놓습니다. TransformerFAM과 같은 혁신적인 성과가 계속해서 등장함에 따라 기술적 병목 현상은 계속해서 극복될 것이며, 더욱 지능적이고 상호 연결된 미래가 서서히 우리를 향해 펼쳐지고 있습니다.
AIGC에 대해 자세히 알아보려면 다음을 방문하세요.
51CTO AI.x 커뮤니티
https://www.51cto.com/aigc/
위 내용은 Google은 대형 모델의 '기억상실'을 바로잡기 위해 조치를 취합니다! 피드백 주의 메커니즘은 컨텍스트를 '업데이트'하는 데 도움이 되며 대형 모델을 위한 무제한 메모리 시대가 다가오고 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!