
대형 모델은 시계열 예측에도 매우 강력합니다! 중국 팀은 LLM의 새로운 기능을 활성화하고 기존 모델을 뛰어넘는 SOTA를 달성합니다.

- PHPz앞으로
- 2024-04-11 09:43:20994검색
대규모 언어 모델의 잠재력이 자극됩니다. -
대규모 언어 모델을 훈련하지 않고도 모든 기존 시계열 모델을 능가하는 고정밀 시계열 예측을 달성할 수 있습니다.
Monash University, Ant 및 IBM Research는 여러 양식에 걸쳐 시퀀스 데이터를 처리하는 대규모 언어 모델의 기능을 성공적으로 촉진하는 일반 프레임워크를 공동으로 개발했습니다. 프레임워크는 중요한 기술 혁신이 되었습니다.

시계열 예측은 도시, 에너지, 교통, 원격 감지 등과 같은 일반적인 복잡한 시스템의 의사 결정에 유용합니다.
이후 대형 모델은 시계열/시공간 데이터 마이닝 방법에 혁명을 일으킬 것으로 예상됩니다.
일반 대형 언어 모델 재프로그래밍 프레임워크
연구팀은 별도의 훈련 없이 일반 시계열 예측을 위해 대형 언어 모델을 쉽게 사용할 수 있는 일반 프레임워크를 제안했습니다.
주로 두 가지 핵심 기술을 제안합니다: 타이밍 입력 재프로그래밍; 프롬프트 접두사.
Time-LLM은 먼저 텍스트 프로토타입(Text Prototypes)을 사용하여 입력 시간 데이터를 다시 프로그래밍하고 자연어 표현을 사용하여 시간 데이터의 의미 정보를 표현함으로써 서로 다른 두 가지 데이터 양식을 정렬하므로 대규모 언어 모델이 필요하지 않습니다. 다른 데이터 형식 뒤에 있는 정보를 이해하기 위한 수정. 동시에, 대규모 언어 모델에는 다양한 데이터 형식 뒤에 있는 정보를 이해하기 위해 특정 교육 데이터 세트가 필요하지 않습니다. 이 방법은 모델의 정확도를 향상시킬 뿐만 아니라 데이터 전처리 과정을 단순화합니다.
입력된 시계열 데이터를 더 잘 처리하고 해당 작업을 분석하기 위해 저자는 PaP(Prompt-as-Prefix) 패러다임을 제안했습니다. 이 패러다임은 시간 데이터를 표현하기 전에 추가 상황 정보와 작업 지침을 추가하여 시간 작업에 대한 LLM의 처리 기능을 완전히 활성화합니다. 이 방법은 타이밍 작업에 대한 보다 정교한 분석을 달성할 수 있으며, 타이밍 데이터 테이블 앞에 추가적인 상황 정보와 작업 지침을 추가하여 타이밍 작업에 대한 LLM의 처리 기능을 완전히 활성화할 수 있습니다.
주요 기여 사항은 다음과 같습니다.
- 백본 언어 모델을 수정하지 않고 타이밍 분석을 위해 대규모 언어 모델을 다시 프로그래밍하는 새로운 개념을 제안했습니다.
- 입력 시간 데이터를 보다 자연스러운 텍스트 프로토타입 표현으로 재프로그래밍하고 도메인 전문 지식 및 작업 설명과 같은 선언적 단서로 입력 컨텍스트를 향상시키는 것으로 구성된 일반 언어 모델 재프로그래밍 프레임워크인 Time-LLM을 제안하여 LLM을 안내합니다. 효과적인 교차 도메인 추론을 위해.

- 주류 예측 작업의 성능은 특히 소수 샘플 및 제로 샘플 시나리오에서 기존 최고의 모델의 성능을 지속적으로 초과합니다. 또한 Time-LLM은 뛰어난 모델 재프로그래밍 효율성을 유지하면서 더 높은 성능을 달성할 수 있습니다. 시계열 및 기타 순차 데이터에 대해 LLM의 아직 활용되지 않은 잠재력을 크게 활용하세요.
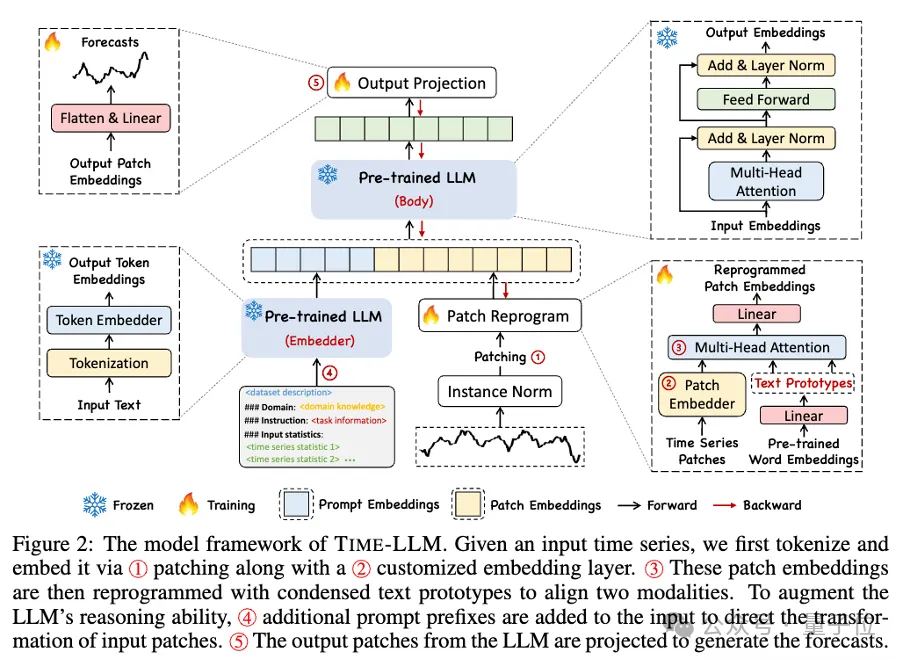
이 프레임워크를 구체적으로 살펴보면, 먼저 입력된 시계열 데이터를 RevIN으로 정규화한 후 여러 패치로 나누어 잠재 공간에 매핑합니다.
시계열 데이터와 텍스트 데이터는 표현 방식에 상당한 차이가 있으며, 서로 다른 양상에 속합니다.
시계열은 직접 편집할 수도 없고 자연어로 손실 없이 설명할 수도 없습니다. 따라서 시간적 입력 특성을 자연어 텍스트 도메인에 맞춰 정렬해야 합니다.

서로 다른 양식을 정렬하는 일반적인 방법은 교차 주의(cross-attention)이지만 LLM의 고유 어휘는 매우 방대하므로 시간적 특징을 모든 단어에 효과적으로 직접 정렬하는 것이 불가능하며 모든 단어가 시간과 관련이 있는 것은 아닙니다. 시퀀스는 의미론적 관계를 정렬했습니다.
이 문제를 해결하기 위해 본 작업에서는 어휘의 선형 결합을 수행하여 텍스트 프로토타입을 얻습니다. 텍스트 프로토타입의 수는 원래 어휘보다 훨씬 적으며, 이 조합을 사용하여 시계열 데이터의 변화하는 특성을 나타낼 수 있습니다. .
특정 타이밍 작업에서 LLM의 기능을 완전히 활성화하기 위해 이 작업은 신속한 접두사 패러다임을 제안합니다.
간단히 말하면, 시계열 데이터 세트의 일부 사전 정보가 접두어 프롬프트로 자연어 형태로 LLM에 공급되고, 여기에 정렬된 시계열 특징이 접합되어 예측 효과를 향상시킬 수 있습니까? ?
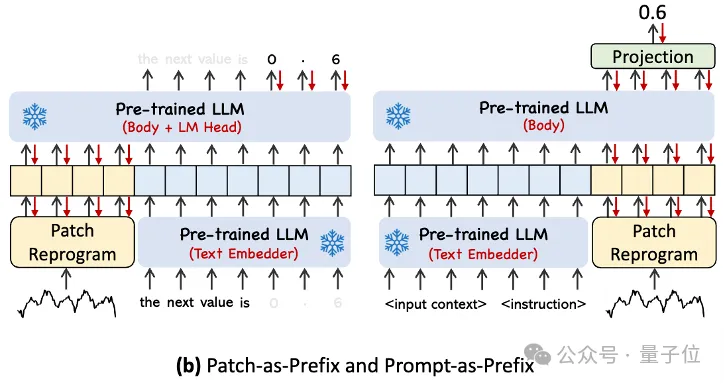
실제로 저자는 효과적인 프롬프트를 구축하기 위한 세 가지 주요 구성 요소를 확인했습니다.
데이터 세트 컨텍스트(2) LLM이 다양한 다운스트림 작업에 적응할 수 있도록 함, (3) 추세, 지연과 같은 통계 설명; 등을 통해 LLM은 시계열 데이터의 특성을 더 잘 이해할 수 있습니다.

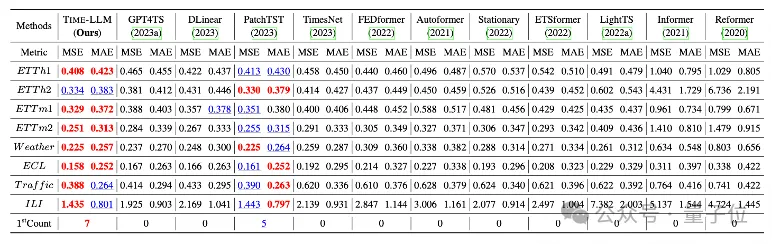
팀은 장기 예측 분야에서 8개의 기존 공개 데이터 세트에 대해 포괄적인 테스트를 수행했습니다.
결과적으로 Time-LLM은 벤치마크 비교에서 해당 분야의 이전 최고 결과를 크게 초과했습니다. 예를 들어 GPT-2를 직접 사용하는 GPT4TS와 비교하면 Time-LLM이 크게 개선되어 이 방법의 효율성을 나타냅니다. .
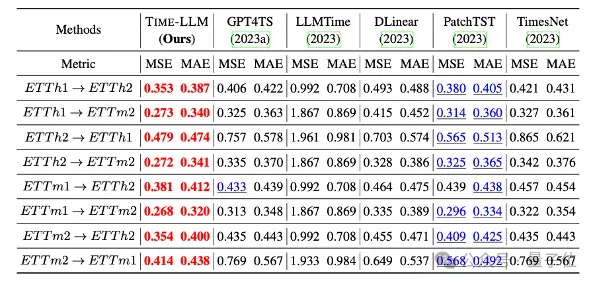
또한 제로샷 시나리오에서도 강력한 예측 능력을 보여줍니다.
본 프로젝트는 앤트그룹 지능형 엔진 사업부 AI 혁신 R&D 부서인 NextEvo의 지원을 받습니다.
관심 있는 친구들은 아래 링크를 클릭해 논문에 대해 자세히 알아보세요~
논문 링크https://arxiv.org/abs/2310.01728.
위 내용은 대형 모델은 시계열 예측에도 매우 강력합니다! 중국 팀은 LLM의 새로운 기능을 활성화하고 기존 모델을 뛰어넘는 SOTA를 달성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!