
36년 전의 저주를 풀어라! Meta, 대형 모델의 '역전 저주'를 제거하기 위한 역방향 학습 방법 출시

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-04-09 15:40:09807검색
대형 언어 모델의 "역전 저주"가 해결되었습니다!
이 저주는 작년 9월에 처음 발견되었으며, 이는 즉시 LeCun, Karpathy, Marcus 및 기타 빅맨들로부터 감탄사를 불러일으켰습니다.

비할 데 없이 오만한 대형 모델에는 실제로 "아킬레스건"이 있기 때문입니다. "A는 B입니다"로 훈련된 언어 모델은 "B는 A입니다"라고 정확하게 대답할 수 없습니다.
예를 들어 다음 예에서 LLM은 "Tom Cruise의 어머니가 Mary Lee Pfeiffer입니다"라는 것을 분명히 알고 있지만 "Mary Lee Pfeiffer의 자녀는 Tom Cruise"라고 대답할 수 없습니다.

——이것은 당시 가장 발전된 GPT-4였기 때문에 아이들도 정상적인 논리적 사고를 할 수 있었지만 LLM은 그렇지 못했습니다.
대량의 데이터를 바탕으로 거의 모든 인간을 능가하는 지식을 외우면서도 너무나 둔감하게 행동하는 그는 지혜의 불을 얻었지만 이 저주에 영원히 갇혀있습니다.

논문주소: https://arxiv.org/pdf/2309.12288v1.pdf
이 사건이 알려지자마자 인터넷 전체가 난리났습니다.
한편 네티즌들은 빅모델이 정말 멍청하다고 하더군요. 'A는 B'만 알고 'B는 A'를 모르고 마침내 인간으로서의 존엄성을 확보했습니다.
한편, 연구자들도 이에 대한 연구를 시작했으며 이 중대한 과제를 해결하기 위해 열심히 노력하고 있습니다.
최근 Meta FAIR의 연구원들은 LLM의 '역전 저주'를 단번에 해결하기 위해 역방향 학습 방법을 출시했습니다.
문서 주소: https://arxiv.org/pdf/2403.13799.pdf
연구원들은 처음에 LLM이 왼쪽에서 오른쪽으로 자동 회귀 방식으로 훈련된다는 사실을 관찰했습니다. 이것이 가능한 원인입니다. 저주의 역전.
그래서 LLM(역방향 학습)을 오른쪽에서 왼쪽 방향으로 훈련하면 모델이 반대 방향으로 사실을 보는 것이 가능합니다.
역방향 텍스트는 멀티태스킹 또는 언어 간 사전 학습을 통해 다양한 소스를 활용하여 제2언어로 처리될 수 있습니다.
연구원들은 토큰 반전, 단어 반전, 엔터티 보존 반전, 무작위 세그먼트 반전이라는 4가지 유형의 반전을 고려했습니다.
토큰 및 단어 역전. 시퀀스를 각각 토큰 또는 단어로 분할하고 순서를 뒤집어 새로운 시퀀스를 형성합니다.
엔터티 보존 역방향은 시퀀스에서 엔터티 이름을 찾고 단어 역전을 수행하는 동안 그 안에서 왼쪽에서 오른쪽으로 단어 순서를 유지합니다.
랜덤 세그먼트 반전은 토큰화된 시퀀스를 임의 길이의 블록으로 분할한 다음 각 블록 내에서 왼쪽에서 오른쪽 순서를 유지합니다.
연구원들은 1.4B 및 7B의 매개변수 규모에서 이러한 반전 유형의 효율성을 테스트한 결과 엔터티 보존 및 무작위 조각별 반전 훈련이 반전 저주를 완화할 수 있으며 어떤 경우에는 완전히 제거할 수 있음을 보여주었습니다.
또한 연구원들은 훈련 전 반전이 표준 왼쪽에서 오른쪽 훈련에 비해 모델 성능이 향상된다는 사실도 발견했습니다. 따라서 역방향 훈련을 일반적인 훈련 방법으로 사용할 수 있습니다.
역방향 학습 방법
역방향 학습에는 N개의 샘플로 구성된 학습 데이터 세트를 얻고 역방향 샘플 세트 REVERSE(x)를 구성하는 것이 포함됩니다.
REVERSE 함수는 다음과 같이 주어진 문자열을 반전시키는 역할을 합니다.
단어 반전: 각 예는 먼저 단어로 분할된 다음, 함께 연결된 공백을 사용하여 문자열을 단어 수준에서 반전합니다.
엔티티 보존 반전: 주어진 훈련 샘플에 대해 엔터티 감지기를 실행하고 엔터티가 아닌 항목도 단어로 분할합니다. 그런 다음 엔터티가 아닌 단어는 반전되고 엔터티를 나타내는 단어는 원래 단어 순서를 유지합니다.
Random Segment Reversal: 개체 탐지기를 사용하는 대신 균일 샘플링을 사용하여 시퀀스를 1에서 k 토큰 사이의 크기를 가진 세그먼트로 무작위로 분할한 다음 이러한 세그먼트를 반전시키려고 합니다. 단, 각 단어 순서는 그 후 세그먼트는 특수 토큰 [REV]를 사용하여 연결됩니다.
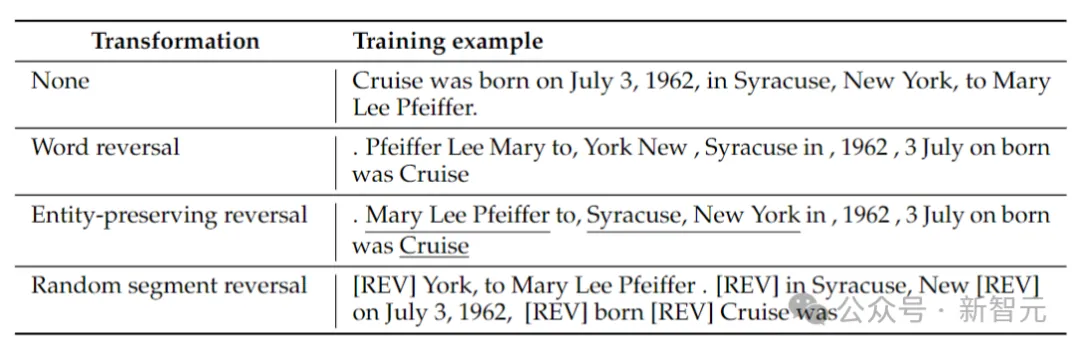
위 표에는 특정 문자열에 대한 다양한 반전 유형의 예가 나와 있습니다.
현재 언어 모델은 여전히 왼쪽에서 오른쪽으로 학습됩니다. 단어 반전의 경우 오른쪽에서 왼쪽으로 문장을 예측하는 것과 같습니다.
역 훈련에는 표준 및 역방향 예제에 대한 훈련이 포함되므로 훈련 토큰의 수가 두 배로 늘어나고 정방향 훈련 샘플과 역방향 훈련 샘플이 혼합됩니다.
역변환은 모델이 학습해야 하는 제2 언어로 볼 수 있습니다. 반전 중에 사실 간의 관계는 변경되지 않고 모델은 문법을 통해 정방향인지 역방향인지 판단할 수 있습니다. 언어 예측 모델.
역 훈련의 또 다른 관점은 정보 이론으로 설명할 수 있습니다. 언어 모델링의 목표는 자연어의 확률 분포를 배우는 것입니다.
역 작업 훈련 및 테스트
엔티티 쌍 매핑
통제된 환경에서 반전 저주를 연구하기 위해 간단한 기호 기반 데이터 세트를 만드는 것부터 시작하세요.
엔터티 a와 b를 일대일 방식으로 무작위로 쌍으로 만듭니다. 훈련 데이터에는 모든 (a→b) 매핑 쌍이 포함되어 있지만 (b→a) 매핑 중 절반만 역할을 합니다. 테스트 데이터.
모델은 훈련 데이터에서 a→b ⇔ b→a 규칙을 추론한 다음 이를 테스트 데이터의 쌍으로 일반화해야 합니다.
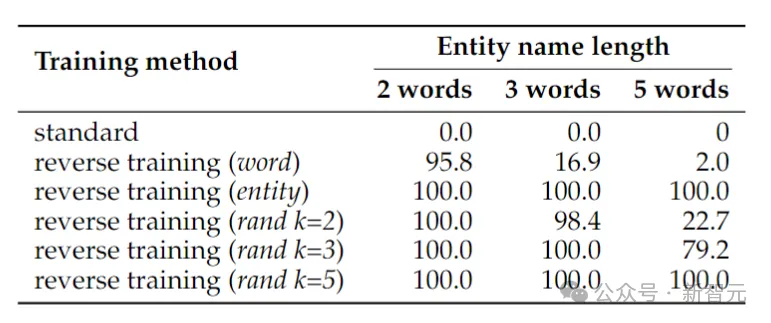
위 표는 부호 반전 작업의 테스트 정확도(%)를 보여줍니다. 작업의 단순성에도 불구하고 표준 언어 모델 교육은 완전히 실패하므로 확장만으로는 문제를 해결할 수 없을 것 같습니다.
반대로 역방향 훈련은 두 단어 엔터티의 문제를 거의 해결할 수 있지만 엔터티가 길어질수록 성능이 빠르게 떨어집니다.
단어 반전은 짧은 엔터티에는 잘 작동하지만 단어가 더 많은 엔터티에는 엔터티 보존 반전이 필요합니다. 무작위 세그먼트 반전은 최대 세그먼트 길이 k가 적어도 엔터티만큼 길 때 잘 수행됩니다.
사람 이름 복구
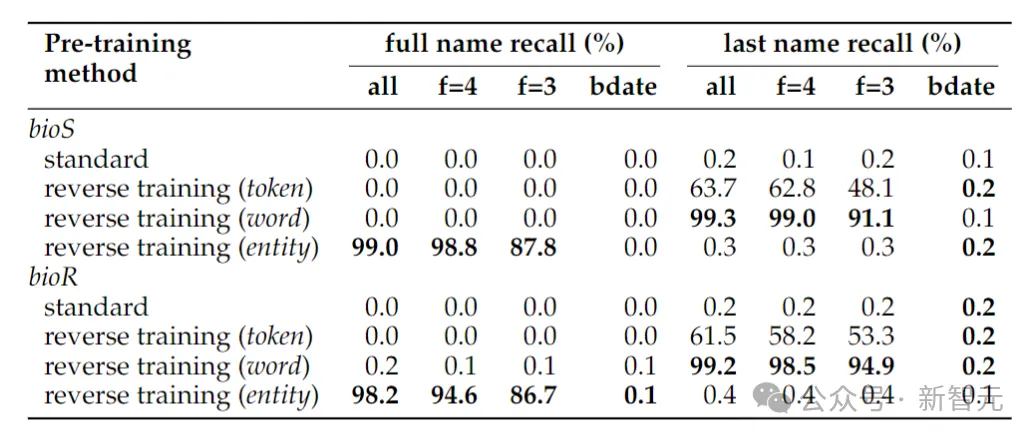
위 표는 사람의 이름을 결정하기 위해 생년월일만 부여하는 경우의 역전 작업의 정확성을 보여줍니다. 전체 이름은 여전히 0에 가깝습니다. 이는 이 문서에서 채택한 엔터티 검색 방법에서 날짜가 세 개의 엔터티로 처리되어 역순으로 유지되지 않기 때문입니다.
역위 작업이 단순히 사람의 성을 결정하는 것으로 축소되면 단어 수준 역산이면 충분합니다.
놀라울 수 있는 또 다른 현상은 엔터티 보존 방법에 따라 사람의 전체 이름은 확인할 수 있지만 성은 확인할 수 없다는 것입니다.
이것은 알려진 현상입니다. 언어 모델은 지식 조각(예: 성)의 최신 토큰을 완전히 검색하지 못할 수 있습니다.
Real World Facts
여기에서 저자는 Llama-2 14억 개의 매개변수 모델을 훈련하여 왼쪽에서 오른쪽 방향으로 2조 토큰의 기본 모델을 훈련했습니다.
반대로 역 훈련은 1조 개의 토큰만 사용하지만 동일한 데이터 하위 집합을 사용하여 왼쪽에서 오른쪽, 오른쪽에서 왼쪽의 두 방향으로 훈련합니다. 두 방향을 합친 것은 2조 토큰이므로 공정성과 정의가 보장됩니다. 컴퓨팅 자원의.
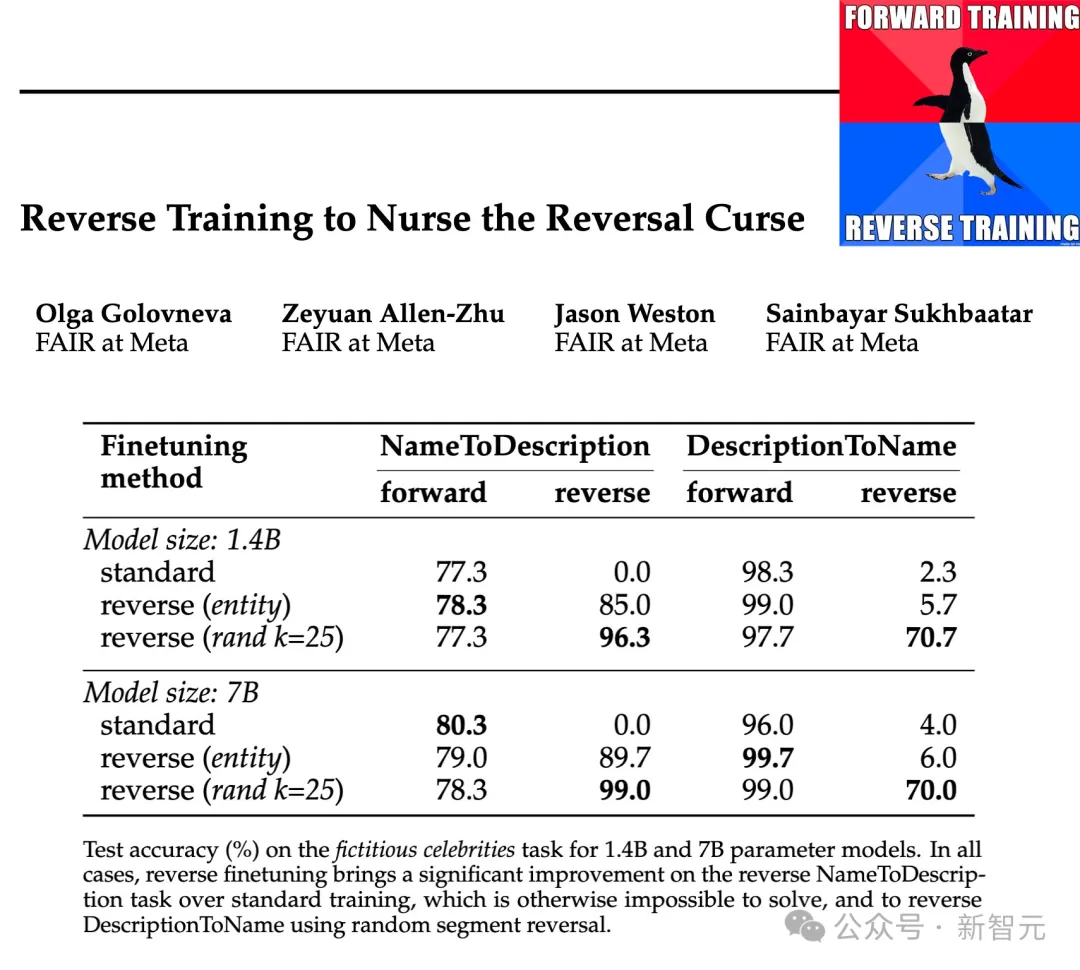
실제 사실의 반전을 테스트하기 위해 연구원들은 "유명인의 어머니는 누구입니까?"와 같은 질문과 "특정 사람의 자녀는 누구입니까?"와 같은 질문이 포함된 유명인 과제를 사용했습니다. 연예인 부모님?"
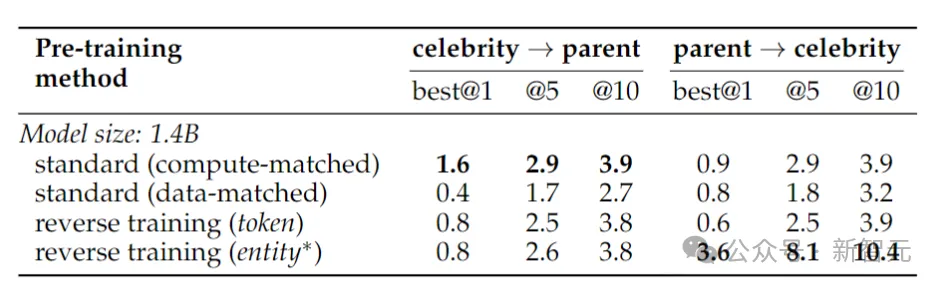
결과는 위 표와 같습니다. 연구자들은 각 질문에 대해 모델을 여러 번 샘플링하고 그 중 하나에 정답이 포함되어 있으면 성공으로 간주했습니다.
일반적으로 모델의 매개변수 수가 작고 사전 훈련이 제한적이며 미세 조정이 부족하기 때문에 일반적으로 정확도가 상대적으로 낮습니다. 그러나 역방향 훈련은 훨씬 더 나은 성능을 보였습니다.
36년 전 예언
1988년 Fodor와 Pylyshyn은 "Cognition" 저널에 사고의 체계적 성격에 관한 기사를 게재했습니다.

이 세상을 정말로 이해한다면 A와 B의 관계, B와 A의 관계를 이해할 수 있어야합니다.
비언어적 인지 생물도 이것을 할 수 있어야 합니다.
위 내용은 36년 전의 저주를 풀어라! Meta, 대형 모델의 '역전 저주'를 제거하기 위한 역방향 학습 방법 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!