
대형 모델에서 일반적으로 사용되는 Attention 메커니즘인 GQA와 Pytorch 코드 구현에 대한 자세한 설명

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-04-03 17:40:091246검색
Grouped Query Attention은 대규모 언어 모델의 다중 쿼리 Attention 방법으로 MQA의 속도를 유지하면서 MHA의 품질을 달성하는 것이 목표입니다. Grouped Query Attention은 각 그룹 내의 쿼리가 동일한 Attention 가중치를 공유하도록 쿼리를 그룹화하므로 계산 복잡성을 줄이고 추론 속도를 높이는 데 도움이 됩니다.
이 글에서는 GQA의 개념과 이를 코드로 변환하는 방법에 대해 설명하겠습니다.
GQA는 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints 논문에서 제안되었습니다. 이는 매우 간단하고 깔끔한 아이디어이며 Multi-head Attention을 기반으로 합니다.
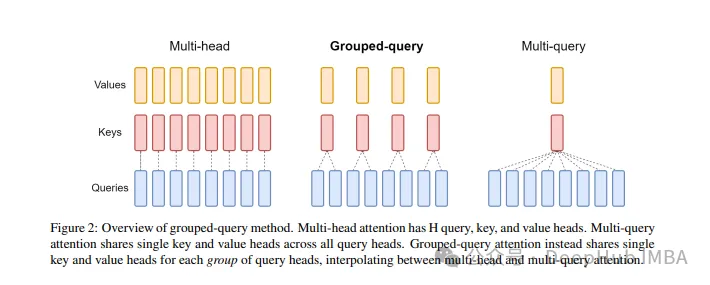
GQA
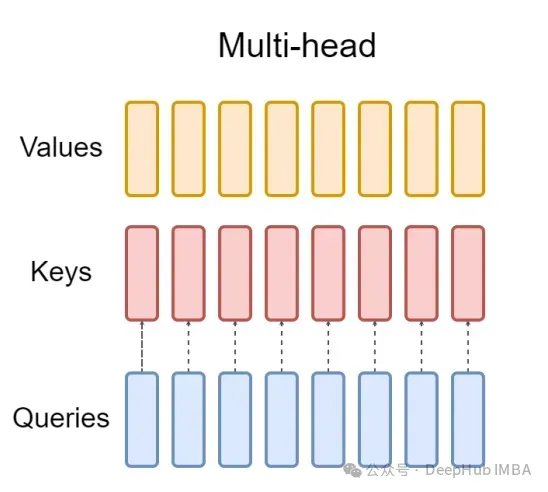
표준 다중 헤드 주의 계층(MHA)은 H 쿼리 헤더, 키 헤더 및 값 헤더로 구성됩니다. 각 헤드에는 D 치수가 있습니다. Pytorch 코드는 다음과 같습니다.
from torch.nn.functional import scaled_dot_product_attention # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 8, 64) value = torch.randn(1, 256, 8, 64) output = scaled_dot_product_attention(query, key, value) print(output.shape) # torch.Size([1, 256, 8, 64])
각 쿼리 헤더마다 해당 키가 있습니다. 이 프로세스는 아래 그림에 나와 있습니다.
그리고 GQA는 쿼리 헤더를 G 그룹으로 나누고 각 그룹은 키와 값을 공유합니다.
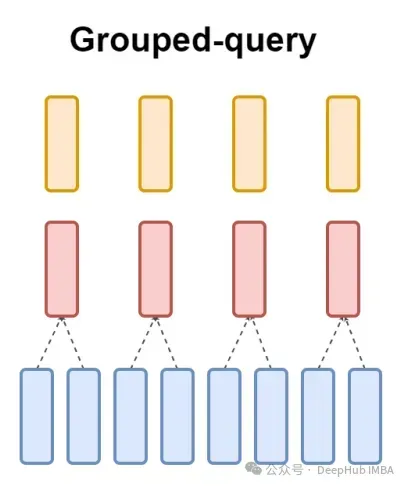
위에서 말한 것처럼 시각적 표현을 사용하면 GQA의 작동 원리를 명확하게 이해할 수 있습니다. GQA는 상당히 간단하고 깔끔한 아이디어입니다.
Pytorch 코드 구현
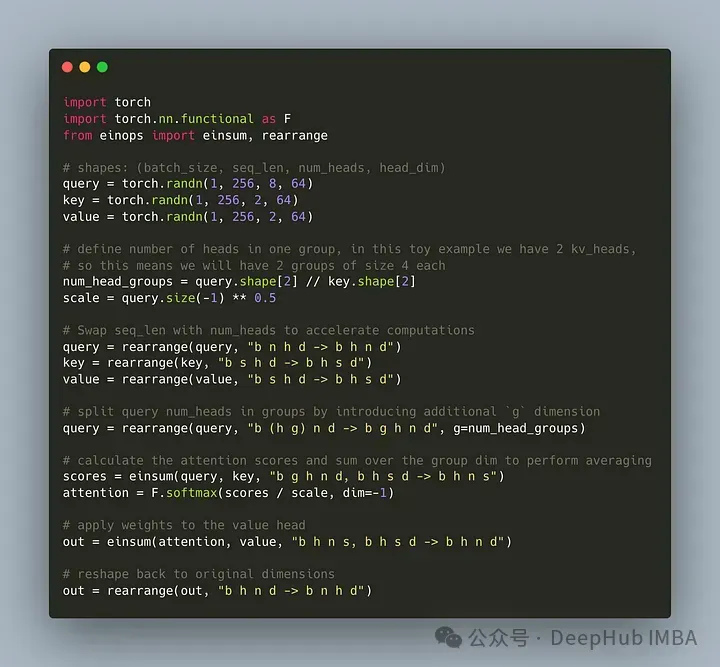
쿼리 헤더를 G 그룹으로 나누는 코드를 작성해 보겠습니다. 각 그룹은 키와 값을 공유합니다. einops 라이브러리를 사용하여 텐서에 대한 복잡한 작업을 효율적으로 수행할 수 있습니다.
먼저 쿼리, 키, 값을 정의합니다. 그런 다음 주의 헤드 수를 설정합니다. 숫자는 임의적이지만 num_heads_for_query % num_heads_for_key = 0이어야 합니다. 이는 나눌 수 있어야 함을 의미합니다. 우리의 정의는 다음과 같습니다:
import torch # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 2, 64) value = torch.randn(1, 256, 2, 64) num_head_groups = query.shape[2] // key.shape[2] print(num_head_groups) # each group is of size 4 since there are 2 kv_heads
효율성을 향상시키기 위해 seq_len 및 num_heads 차원을 교환하면 einops는 다음과 같이 간단하게 완성될 수 있습니다.
from einops import rearrange query = rearrange(query, "b n h d -> b h n d") key = rearrange(key, "b s h d -> b h s d") value = rearrange(value, "b s h d -> b h s d")
그런 다음 "그룹화"를 도입해야 합니다. 쿼리 매트릭스 개념.
from einops import rearrange query = rearrange(query, "b (h g) n d -> b g h n d", g=num_head_groups) print(query.shape) # torch.Size([1, 4, 2, 256, 64])
위의 코드를 사용하여 2D를 2D로 재구성합니다. 우리가 정의한 텐서의 경우 원래 차원 8(쿼리의 헤드 수)이 이제 두 그룹으로 분할됩니다(키의 헤드와 일치) 값은 숫자), 각 그룹 크기는 4입니다.
마지막이자 가장 어려운 부분은 관심 점수를 계산하는 것입니다. 그러나 실제로는 insum 연산을 통해 한 줄로 수행할 수 있습니다.
from einops import einsum, rearrange # g stands for the number of groups # h stands for the hidden dim # n and s are equal and stands for sequence length scores = einsum(query, key, "b g h n d, b h s d -> b h n s") print(scores.shape) # torch.Size([1, 2, 256, 256])
scores 텐서는 위의 값 텐서와 동일한 모양을 갖습니다. 어떻게 작동하는지 살펴보겠습니다
einsum은 두 가지 작업을 수행합니다.
1. 쿼리와 키의 행렬 곱셈입니다. 우리의 경우 이러한 텐서의 모양은 (1,4,2,256,64)와 (1,2,256,64)이므로 마지막 두 차원에 대한 행렬 곱셈은 (1,4,2,256,256)을 제공합니다.
2. 두 번째 차원(차원 g)의 요소를 합산합니다. 지정된 출력 모양에서 차원이 생략되면 einsum이 자동으로 이 작업을 완료하고 이러한 합산을 사용하여 키와 헤드 수를 일치시킵니다. 가치.
마지막으로 분수와 값의 표준 곱셈에 유의하세요.
import torch.nn.functional as F scale = query.size(-1) ** 0.5 attention = F.softmax(similarity / scale, dim=-1) # here we do just a standard matrix multiplication out = einsum(attention, value, "b h n s, b h s d -> b h n d") # finally, just reshape back to the (batch_size, seq_len, num_kv_heads, hidden_dim) out = rearrange(out, "b h n d -> b n h d") print(out.shape) # torch.Size([1, 256, 2, 64])
가장 간단한 GQA 구현이 이제 완료되어 16줄 미만의 Python 코드가 필요합니다.
마지막으로 MQA에 대해 간략하게 언급합니다. MQA(Multi-Query Attention)는 MHA를 단순화하는 또 다른 인기 있는 방법입니다. 모든 쿼리는 동일한 키와 값을 공유합니다. 회로도는 다음과 같습니다.
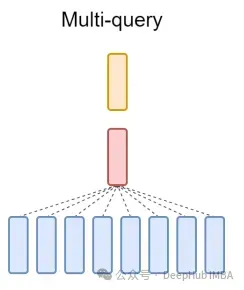
보시다시피 MQA와 MHA는 모두 GQA에서 파생될 수 있습니다. 단일 키와 값을 갖는 GQA는 MQA와 동일하고, 헤더 수와 동일한 그룹을 갖는 GQA는 MHA와 동일합니다.
GQA의 장점은 무엇인가요?
GQA는 최고의 성능(MQA)과 최고의 모델 품질(MHA) 사이의 절충안입니다.
아래 그림은 GQA를 사용하면 MHA와 거의 동일한 모델 품질을 얻을 수 있으며 처리 시간은 3배 증가하여 MQA 성능에 도달한다는 것을 보여줍니다. 이는 고부하 시스템에 필수적일 수 있습니다.
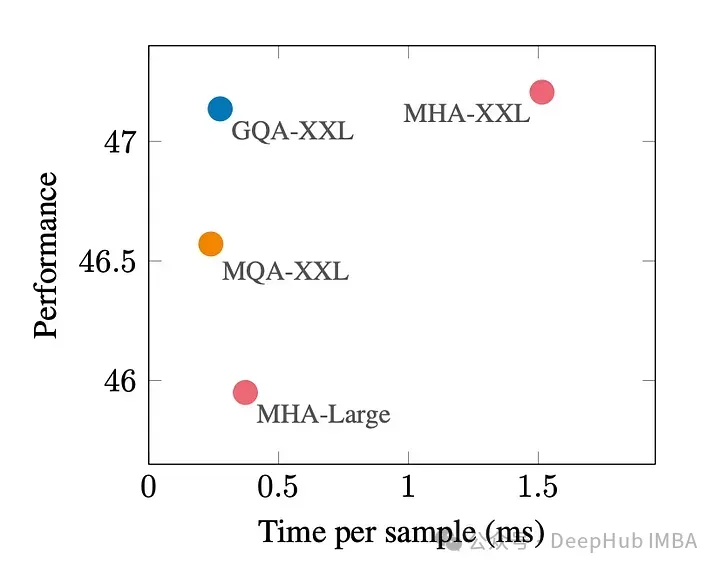
pytorch에는 GQA의 공식적인 구현이 없습니다. 그래서 더 나은 비공식 구현을 찾았습니다. 관심이 있다면 시도해 볼 수 있습니다.
https://www.php.cn/link/5b52e27a9d5bf294f5b593c4c071500e
GQA 문서:
위 내용은 대형 모델에서 일반적으로 사용되는 Attention 메커니즘인 GQA와 Pytorch 코드 구현에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!