
Yuanxiang의 첫 번째 MoE 대형 모델은 오픈 소스입니다: 4.2B 활성화 매개변수, 효과는 13B 모델과 비슷합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-04-02 13:25:081324검색
Yuanxiang은 업계 최고의 Mixture of Experts 모델 아키텍처(Mixture of Experts)를 채택하고 매개변수 4.2B를 활성화하며 효과는 13B 모델과 비슷한 XVERSE-MoE-A4.2B 대형 모델을 출시했습니다. 이 모델은 완전 오픈 소스이며 상업용으로 무조건 무료로, 많은 중소기업, 연구원 및 개발자가 Yuanxiang의 고성능 "패밀리 버킷"에서 온디맨드로 사용할 수 있도록 하여 저비용 배포를 촉진합니다. .

GPT3, Llama 및 XVERSE와 같은 주류 대형 모델의 개발은 스케일링 법칙을 따릅니다. 모델 훈련 및 추론 과정에서 단일 정방향 및 역방향 계산 중에 모든 매개변수가 활성화됩니다. 이를 dense라고 합니다. 활성화 (조밀하게 활성화됨). 모델 규모가 커지면 컴퓨팅 파워 비용이 급격히 증가합니다.
점점 더 많은 연구자들이 드물게 활성화된 MoE 모델이 모델 크기를 늘릴 때 훈련 및 추론의 계산 비용을 크게 늘리지 않고도 더 효과적인 방법이 될 수 있다고 믿고 있습니다. 기술이 비교적 새로운 것이기 때문에 중국의 대부분의 오픈 소스 모델이나 학술 연구는 아직 대중적이지 않습니다.
요소 자체 연구에서 동일한 코퍼스를 사용하여 2.7조 개의 토큰을 훈련하는 경우 XVERSE-MoE-A4.2B는 실제 활성화 매개변수 양이 4.2B이고 성능은 XVERSE-13B-2를 "점프"합니다. 계산량이 훈련 시간의 50%만큼 감소됩니다. 여러 오픈 소스 벤치마크인 Llama와 비교하면 이 모델은 Llama2-13B를 훨씬 능가하며 Llama1-65B(아래)에 가깝습니다.
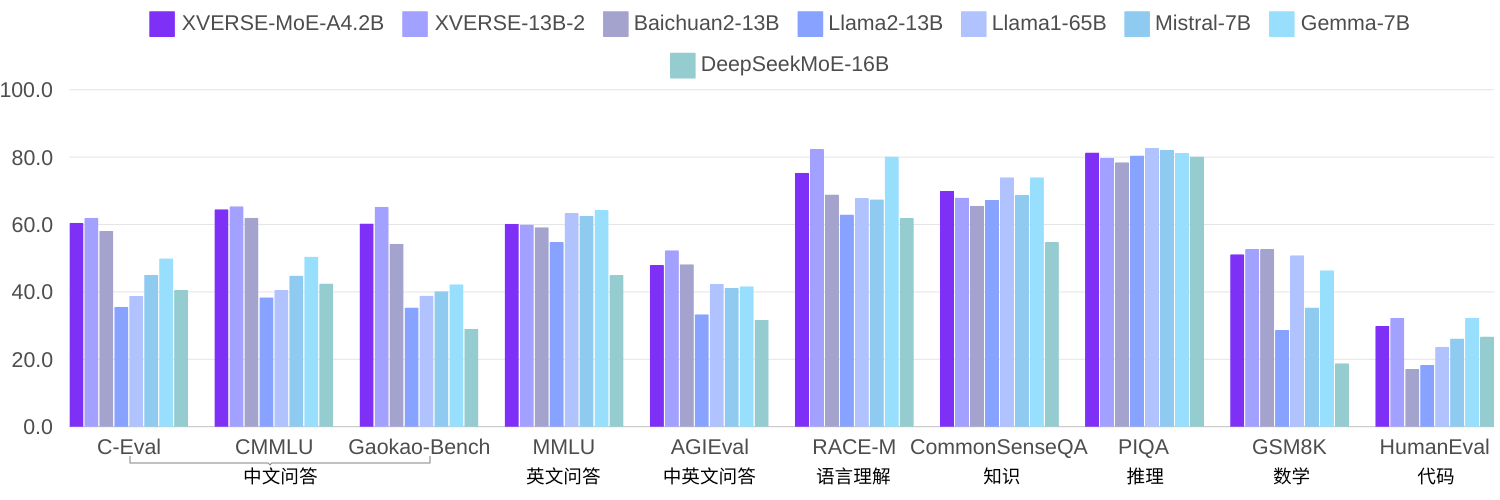
여러 권위 있는 리뷰 보기
오픈소스 측면에서 요소대형 모델 '패밀리 버킷'이 계속해서 반복되며 국내 오픈소스를 세계 최고 수준으로 끌어올리고 있습니다. 적용 측면에서 Element는 AI+3D 기술의 고유한 장점을 활용하고 대형 모델 3D 공간 및 AIGC 도구와 같은 원스톱 솔루션을 출시하여 엔터테인먼트, 관광, 금융 등 다양한 산업에 힘을 실어주고 지능적인 고객 서비스, 창의적 서비스를 제공합니다. 다양한 시나리오에서 최고의 사용자 경험을 창출하세요.
MoE기술적 자체 연구 및 혁신
교육부(MoE)는 현재 업계에서 가장 최첨단 모델 프레임워크로 인해 최신 기술로 인해 국내 오픈 소스 모델이나 학술 연구에서는 그렇지 않습니다. 그래도 인기를 얻습니다. MetaObject는 MoE의 효율적인 훈련 및 추론 프레임워크를 독립적으로 개발하고 세 가지 방향으로 혁신했습니다.
성능 측면에서 MoE 아키텍처의 고유한 전문가 라우팅 및 가중치 계산 논리를 기반으로 효율적인 융합 연산자 세트가 개발되어 컴퓨팅이 크게 향상되었습니다. 효율성; MoE 모델의 높은 메모리 사용량과 대규모 통신량 문제를 해결하기 위해 컴퓨팅, 통신 및 메모리 오프로딩의 중복 작업이 전체 처리량을 효과적으로 향상시키도록 설계되었습니다.
아키텍처 측면에서 각 전문가의 크기를 표준 FFN과 동일시하는 기존 MoE(예: Mixtral 8x7B)와 달리 Yuanxiang은 보다 세분화된 전문가 디자인을 채택하고 각 전문가의 크기는 1/4에 불과합니다. 모델 유연성과 성능을 향상시키는 표준 FFN, 전문가도 공유 전문가와 비공유 전문가의 두 가지 범주로 나뉩니다. 공유 전문가는 계산 중에 활성 상태로 유지되는 반면, 비공유 전문가는 필요에 따라 선택적으로 활성화됩니다. 이 설계는 일반 지식을 공유 전문가 매개변수로 압축하고 공유되지 않은 전문가 매개변수 간의 지식 중복을 줄이는 데 도움이 됩니다.
Switch Transformers, ST-MoE 및 DeepSeekMoE에서 영감을 받은 훈련 측면에서 Yuanxiang은 전문가 간의 로드 균형을 더 잘 맞추기 위해 로드 밸런싱 손실 항을 도입합니다. 라우터 z-손실 항은 효율적이고 안정적인 훈련을 보장하는 데 사용됩니다.
일련의 비교 실험을 통해 아키텍처 선택을 얻었습니다(아래 그림). 실험 3과 실험 2에서는 전체 매개변수 양과 활성화 매개변수 양은 동일했지만 전자의 세밀한 전문가 설계로 인해 더 높은 성능을 가져왔습니다. . 이를 바탕으로 실험 4에서는 전문가를 공유형과 비공유형의 두 가지 유형으로 더욱 세분화하여 효과를 크게 향상시켰습니다. 실험 5에서는 전문가 규모가 표준 FFN과 같을 때 공유 전문가를 도입하는 방법을 탐색하지만 효과가 이상적이지 않습니다.
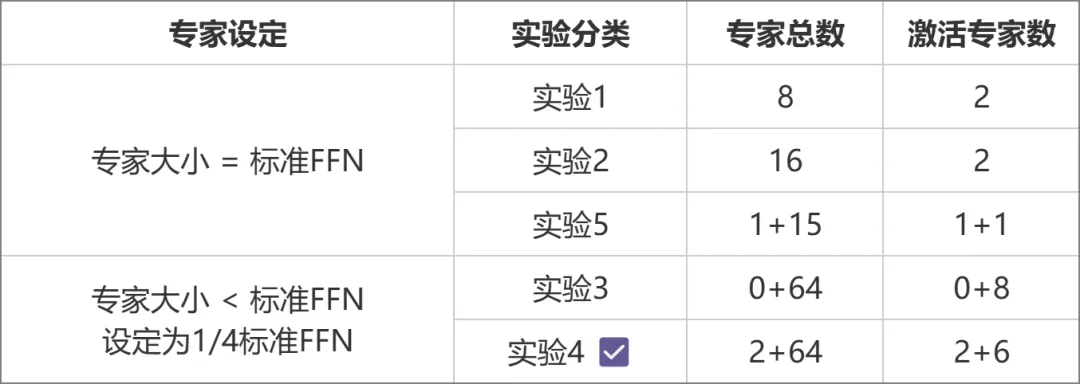
실험 설계 계획 비교
종합 테스트 결과(아래 그림) Yuanxiang은 마침내 실험 4에 해당하는 아키텍처 설정을 채택했습니다. 미래를 내다보면 Google Gemma와 같은 새로운 오픈소스 프로젝트가
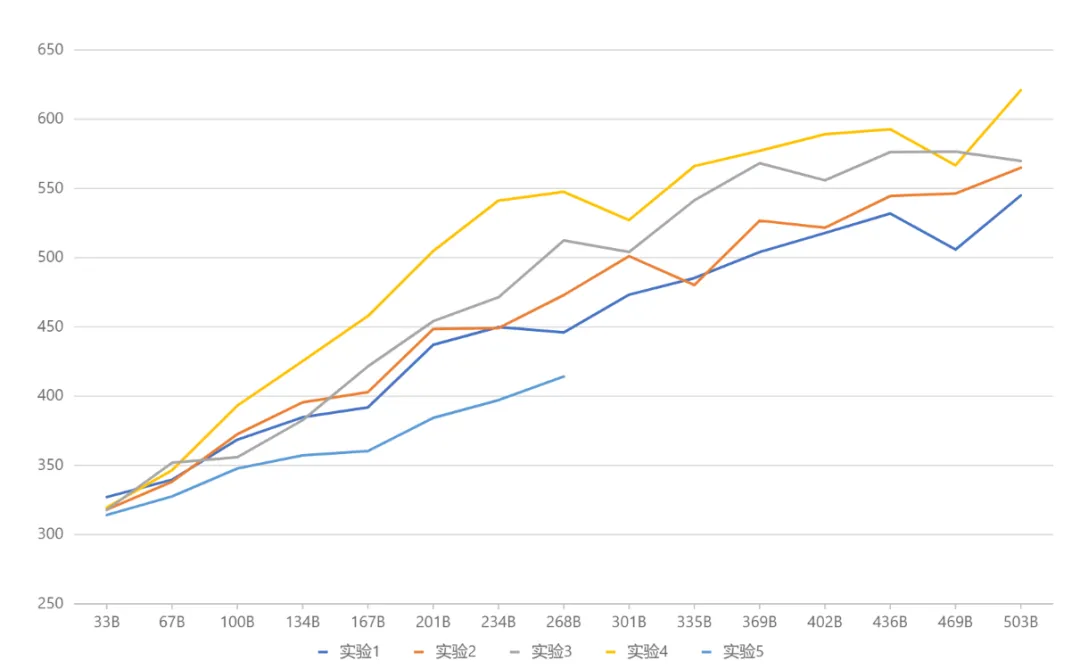
실험 결과 비교
대형 모델 무료 다운로드
- Hugging Face: https://huggingface.co/xverse/XVERSE-MoE-A4.2B
- ModelScope: https://modelscope.cn / models/xverse/XVERSE-MoE-A4.2B
- Github: https://github.com/xverse-ai/XVERSE-MoE-A4.2B
- 문의사항은 opensource@xverse.cn
위 내용은 Yuanxiang의 첫 번째 MoE 대형 모델은 오픈 소스입니다: 4.2B 활성화 매개변수, 효과는 13B 모델과 비슷합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!