
주의가 필요한 전부는 아닙니다! Mamba 하이브리드 대형 모델 오픈 소스: Transformer 처리량 3배

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-03-30 09:41:16947검색
맘바 시간이 왔나요?
트랜스포머 아키텍처는 2017년 획기적인 연구 논문 "Attention is All You Need"가 출판된 이후 생성 인공 지능 분야를 지배해 왔습니다.
그러나 Transformer 아키텍처에는 실제로 두 가지 중요한 단점이 있습니다.
Transformer의 메모리 공간은 컨텍스트 길이에 따라 다릅니다. 이로 인해 상당한 하드웨어 리소스 없이 긴 컨텍스트 창이나 대규모 병렬 처리를 실행하는 것이 어려워져 광범위한 실험과 배포가 제한됩니다. Transformer 모델의 메모리 공간은 컨텍스트 길이에 따라 확장되므로 상당한 하드웨어 리소스 없이는 긴 컨텍스트 창이나 과도한 병렬 처리를 실행하기 어렵기 때문에 광범위한 실험 및 배포가 제한됩니다.
Transformer 모델의 어텐션 메커니즘은 컨텍스트 길이의 증가에 따라 속도를 조정합니다. 이 메커니즘은 시퀀스 길이를 무작위로 확장하고 계산 비용을 줄입니다. 각 토큰은 이전 시퀀스에 의존하기 때문입니다. 효율적인 생산 범위를 벗어나 적용됩니다.
Transformer가 인공지능 생산을 위한 유일한 길은 아닙니다. 최근 AI21 Labs는 여러 벤치마크에서 Transformer를 능가하는 "Jamba"라는 새로운 방법을 출시하고 오픈소스화했습니다.

Hugging Face 주소: https://huggingface.co/ai21labs/Jamba-v0.1
Mamba의 SSM 아키텍처는 변환기의 메모리 리소스 및 컨텍스트 문제를 잘 해결할 수 있습니다. 그러나 Mamba 접근 방식은 변환기 모델과 동일한 수준의 출력을 제공하는 데 어려움을 겪습니다.
Jamba는 SSM(Structured State Space Model)을 기반으로 한 Mamba 모델과 Transformer 아키텍처를 결합하여 SSM과 Transformer의 최고의 특성을 결합하는 것을 목표로 합니다.

Jamba는 NVIDIA API 카탈로그에서 NVIDIA NIM 추론 마이크로서비스로도 액세스할 수 있으며, 엔터프라이즈 애플리케이션 개발자는 NVIDIA AI Enterprise 소프트웨어 플랫폼을 사용하여 배포할 수 있습니다.
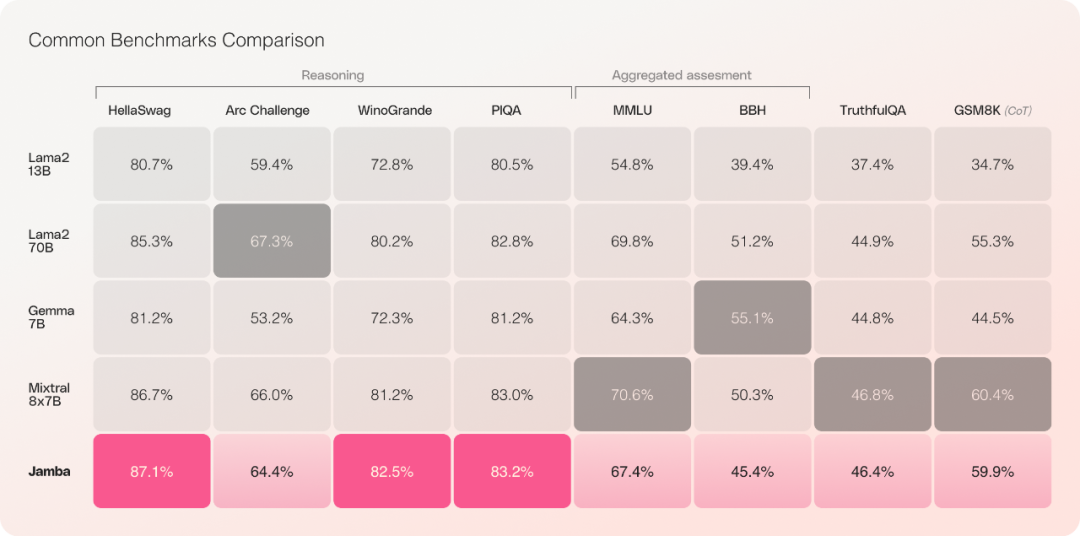
일반적으로 Jamba 모델은 다음과 같은 특징을 가지고 있습니다:
새로운 SSM-Transformer 하이브리드 아키텍처를 사용하는 Mamba 기반 최초의 생산 수준 모델
Mixtral 8x7B와 비교 시, 긴 컨텍스트 처리량은 다음과 같습니다. 3배 증가
256K 컨텍스트 창에 대한 액세스 제공
모델 가중치 노출
단일 GPU에서 최대 140K 컨텍스트를 수용할 수 있는 유일한 모델입니다.
모델 아키텍처
아래 그림에 표시된 것처럼 Jamba의 아키텍처는 블록 및 레이어 접근 방식을 채택하므로 Jamba가 두 아키텍처를 통합할 수 있습니다. 각 Jamba 블록은 Attention 레이어 또는 Mamba 레이어와 MLP(다층 퍼셉트론)로 구성되어 변환기 레이어를 형성합니다.
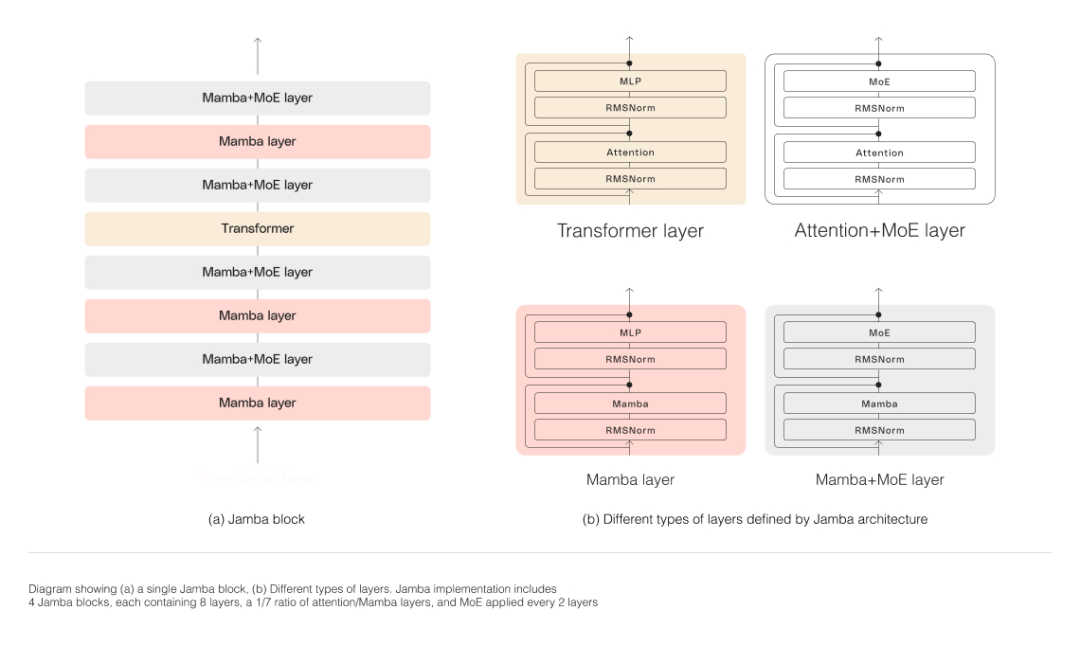
Jamba는 MoE를 활용하여 모델 매개변수의 총 수를 늘리는 동시에 추론에 사용되는 활성 매개변수의 수를 단순화하여 계산 요구 사항을 늘리지 않고도 모델 용량을 높일 수 있습니다. 단일 80GB GPU에서 모델 품질과 처리량을 극대화하기 위해 연구팀은 사용되는 MoE 레이어와 전문가 수를 최적화하여 일반적인 추론 워크로드에 충분한 메모리를 확보했습니다.
Jamba의 MoE 레이어를 사용하면 추론 시 사용 가능한 52B 매개변수 중 12B만 활용할 수 있으며, 하이브리드 아키텍처는 이러한 12B 활성 매개변수를 동일한 크기의 순수 변압기 모델보다 더 효율적으로 만듭니다.
이전에는 Mamba를 3B 매개변수 이상으로 확장한 사람이 없습니다. Jamba는 생산 규모에 도달한 최초의 하이브리드 아키텍처입니다.
처리량 및 효율성
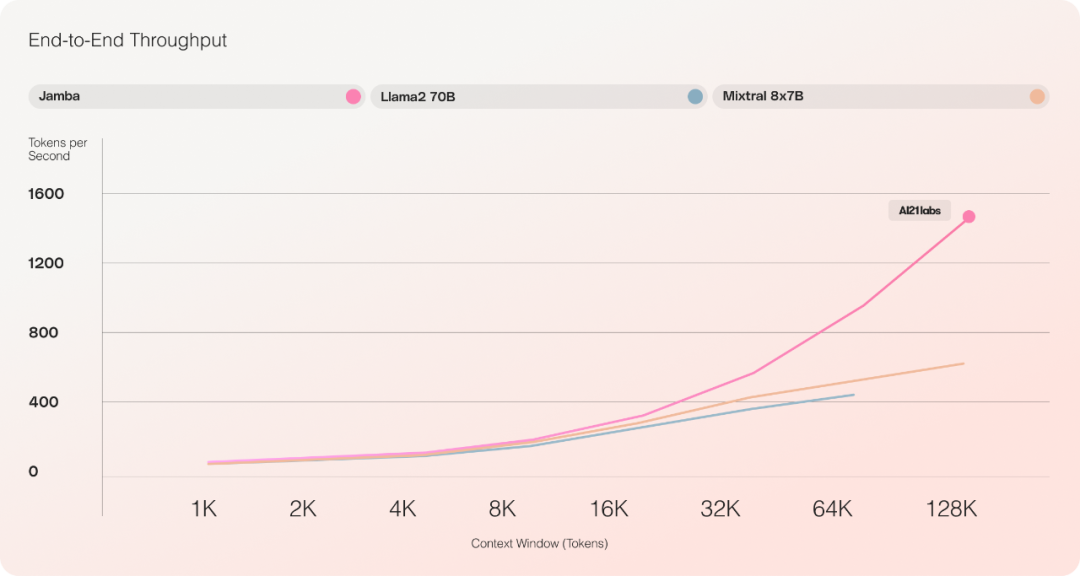
사전 평가 실험에 따르면 Jamba는 처리량 및 효율성과 같은 주요 지표에서 우수한 성능을 발휘하는 것으로 나타났습니다.
효율성 측면에서 Jamba는 긴 컨텍스트에서 Mixtral 8x7B 처리량의 3배를 달성합니다. Jamba는 Mixtral 8x7B와 같은 비슷한 크기의 Transformer 기반 모델보다 더 효율적입니다.
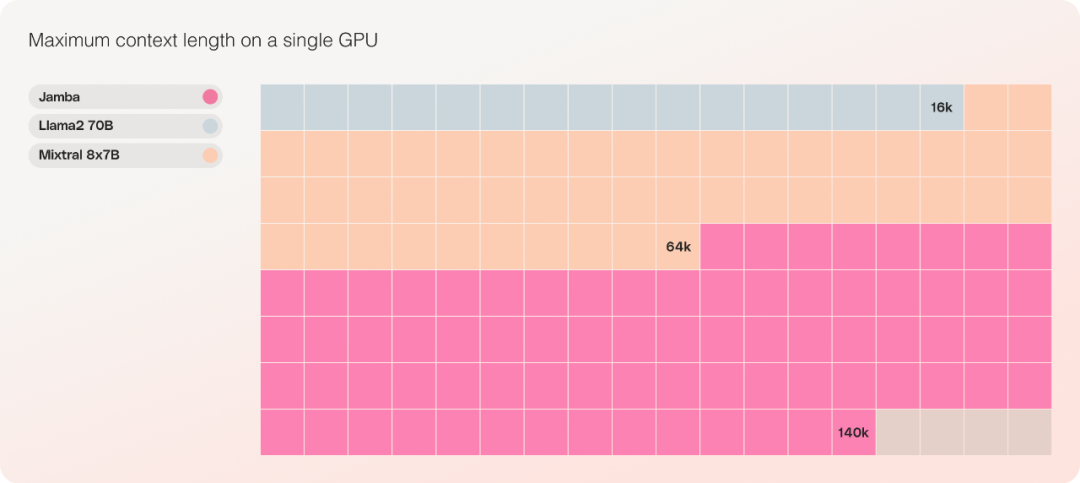
비용 측면에서 Jamba는 단일 GPU에서 140K 컨텍스트를 수용할 수 있습니다. Jamba는 비슷한 규모의 다른 현재 오픈 소스 모델보다 더 많은 배포 및 실험 기회를 제공합니다.
Jamba는 현재 현재 Transformer 기반 LLM(대형 언어 모델)을 대체할 가능성이 낮지만 일부 영역에서는 보완 모델이 될 수 있다는 점에 유의해야 합니다.
참조링크:
https://www.ai21.com/blog/announce-jamba
https://venturebeat.com/ai/ai21-labs-juices-up- gen-ai-transformers-with-jamba/
위 내용은 주의가 필요한 전부는 아닙니다! Mamba 하이브리드 대형 모델 오픈 소스: Transformer 처리량 3배의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!