
OccFusion: Occ를 위한 간단하고 효과적인 다중 센서 융합 프레임워크(Performance SOTA)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-03-08 11:50:03857검색
자율 주행에서는 3D 장면에 대한 포괄적인 이해가 중요하며, 최근 3D 의미론적 점유 예측 모델은 다양한 모양과 범주로 실제 객체를 설명하는 과제를 성공적으로 해결했습니다. 그러나 기존의 3D 점유 예측 방법은 파노라마 카메라 영상에 크게 의존하기 때문에 조명 및 기상 조건 변화에 취약합니다. LiDAR 및 서라운드 뷰 레이더와 같은 추가 센서의 기능을 통합함으로써 우리의 프레임워크는 점유 예측의 정확성과 견고성을 향상시켜 nuScenes 벤치마크에서 최고의 성능을 발휘합니다. 또한 까다로운 야간 및 비오는 장면을 포함하여 nuScene 데이터 세트에 대한 광범위한 실험을 통해 다양한 감지 범위에 걸쳐 센서 융합 전략의 탁월한 성능이 확인되었습니다.
논문 링크: https://arxiv.org/pdf/2403.01644.pdf
논문 이름: OccFusion: 3D 점유 예측을 위한 간단하고 효과적인 다중 센서 융합 프레임워크
이 기사의 주요 기여는 다음과 같이 요약됩니다. :
- 카메라, 라이더, 레이더 정보를 통합하여 3D 의미론적 점유 예측 작업을 수행하는 다중 센서 융합 프레임워크를 제안합니다.
- 3D 의미론적 점유 예측 작업에서 우리의 방법은 다중 센서 융합의 장점을 보여주기 위해 다른 최첨단(SOTA) 알고리즘과 비교됩니다.
- 밤, 비 등 까다로운 조명 및 기상 조건에서 다양한 센서 조합으로 달성한 성능 향상을 평가하기 위해 철저한 절제 연구가 수행되었습니다.
- 다양한 센서 조합과 까다로운 시나리오를 고려하여 3D 의미론적 점유 예측 작업에서 지각 범위 요인이 우리 프레임워크의 성능에 미치는 영향을 분석하기 위해 포괄적인 연구가 수행되었습니다!
네트워크 구조 개요
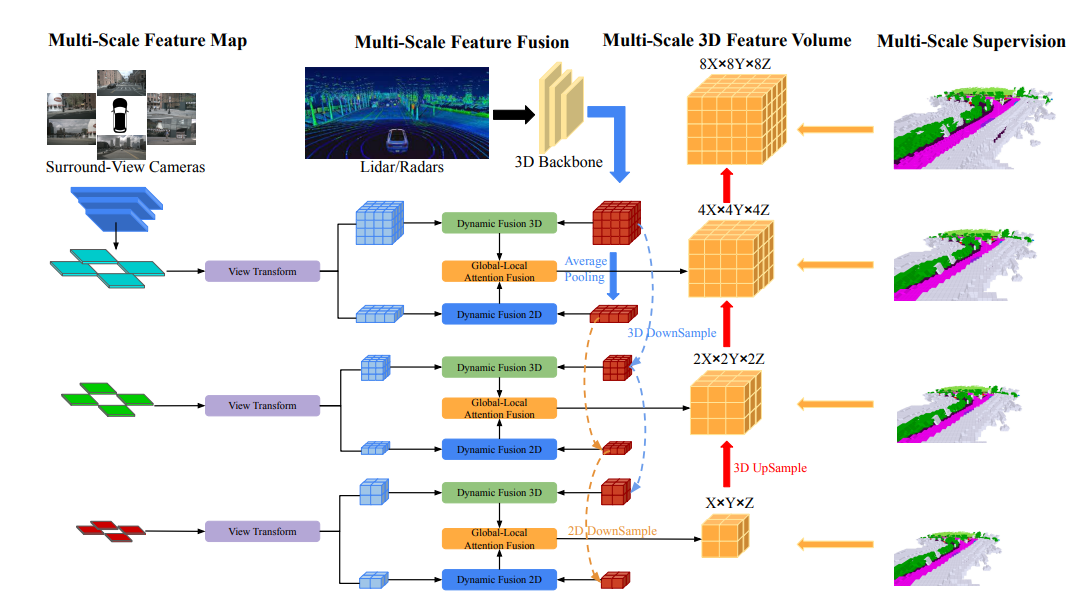
OccFusion의 전체적인 아키텍처는 다음과 같습니다. 먼저 서라운드 뷰 이미지를 2D 백본에 입력하여 멀티스케일 특징을 추출합니다. 이어서, 각 축척에서 뷰 변환을 수행하여 각 수준에서 전역 BEV 특징과 로컬 3D 특징 볼륨을 얻습니다. LiDAR 및 서라운드 레이더에 의해 생성된 3D 포인트 클라우드는 3D 백본에도 입력되어 다중 스케일 로컬 3D 기능 수량 및 글로벌 BEV 기능을 생성합니다. 각 레벨의 동적 융합 3D/2D 모듈은 카메라와 라이더/레이더의 기능을 결합합니다. 그 후, 병합된 글로벌 BEV 기능과 각 레벨의 로컬 3D 기능 볼륨이 글로벌-로컬 어텐션 융합에 공급되어 각 스케일에서 최종 3D 볼륨을 생성합니다. 마지막으로, 각 레벨의 3D 볼륨은 다중 스케일 감독 메커니즘을 통해 업샘플링되고 건너뛰어 연결됩니다.
실험적 비교 분석
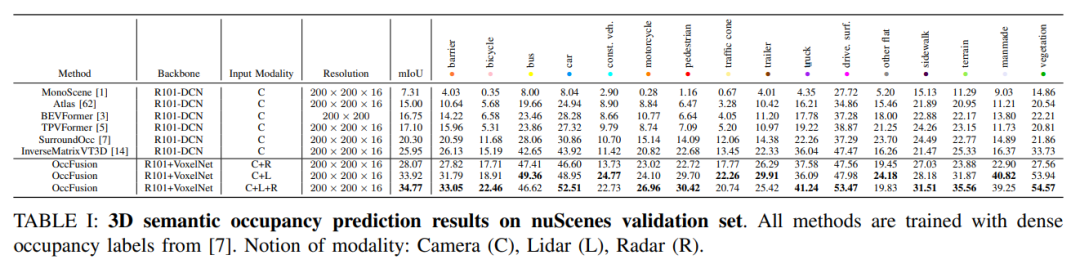
nuScenes 검증 세트에서는 3차원 의미론적 점유 예측에서 밀집 점유 라벨 훈련을 기반으로 한 다양한 방법의 결과를 보여줍니다. 이러한 방법에는 카메라(C), LiDAR(L) 및 레이더(R)를 포함한 다양한 모달 개념이 포함됩니다.
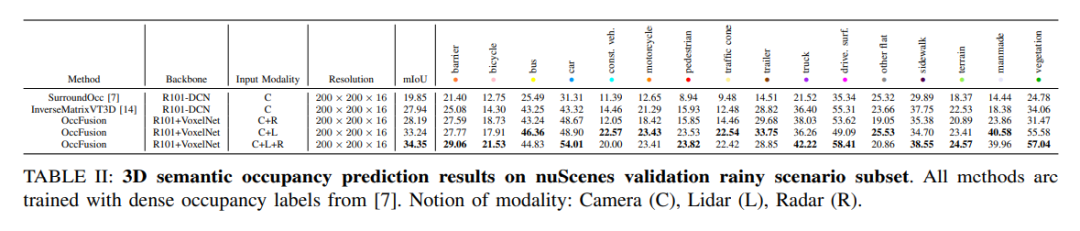
nuScenes 데이터세트의 비오는 장면 하위 집합에서 우리는 3D 의미론적 점유를 예측하고 훈련을 위해 조밀한 점유 라벨을 사용합니다. 이번 실험에서는 카메라(C), 라이더(L), 레이더(R) 등 다양한 양식의 데이터를 고려했습니다. 이러한 모드의 융합은 우천 장면을 더 잘 이해하고 예측하는 데 도움이 되며 자율 주행 시스템 개발에 중요한 참고 자료를 제공합니다.
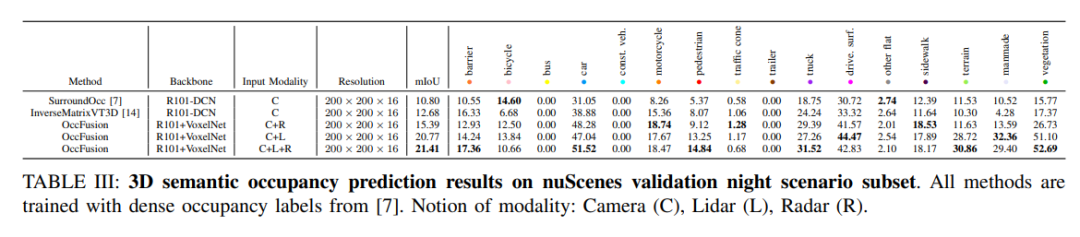
nuScenes는 야간 장면의 하위 집합에 대한 3D 의미론적 점유 예측 결과를 검증합니다. 모든 방법은 밀집된 점유 라벨을 사용하여 학습됩니다. 모달 개념: 카메라(C), 라이더(L), 레이더(R).
성능 변화 추세. (a) 전체 nuScenes 검증 세트의 성능 변화 추세, (b) nuScenes 검증 야간 장면 하위 집합, (c) 비오는 장면 하위 집합의 nuScene 검증 성능 변화 추세.
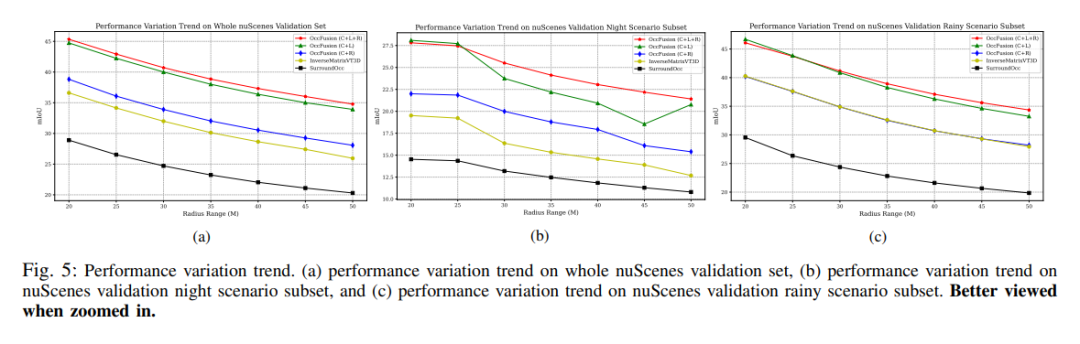
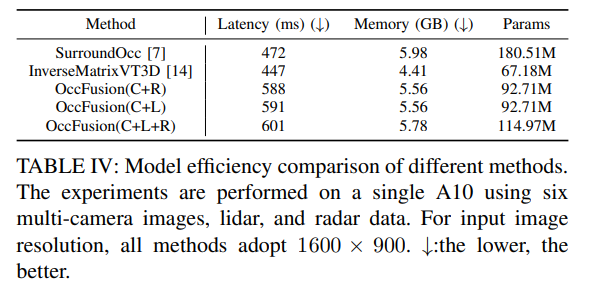
표 4: 다양한 방법의 모델 효율성 비교. 6개의 다중 카메라 이미지, LiDAR 및 레이더 데이터를 사용하여 A10에서 실험을 수행했습니다. 입력 영상 해상도는 모든 방법에서 1600×900을 사용한다. ↓:낮을수록 좋습니다.
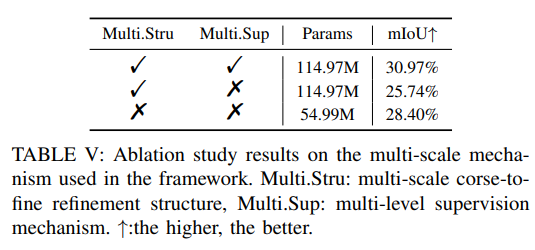
더 많은 절제 실험:


위 내용은 OccFusion: Occ를 위한 간단하고 효과적인 다중 센서 융합 프레임워크(Performance SOTA)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!