
ICLR 2024 스포트라이트 | 대형 언어 모델 가중치, 활성화, 전반적인 낮은 비트 미세화가 상용 APP에 통합되었습니다.

- PHPz앞으로
- 2024-03-07 16:16:16844검색
모델 양자화는 모델 압축 및 가속의 핵심 기술로, 모델 가중치와 활성화 값을 낮은 비트로 양자화하여 모델이 메모리 오버헤드를 덜 차지하고 추론 속도를 높일 수 있습니다. 대규모 매개변수가 있는 대규모 언어 모델의 경우 모델 수량화가 더욱 중요합니다. 예를 들어, GPT-3 모델의 175B 매개변수는 FP16 형식을 사용하여 로드할 때 350GB의 메모리를 소비하므로 최소 5개의 80GB A100 GPU가 필요합니다.
하지만 GPT-3 모델의 무게를 3bit로 압축할 수 있다면 A100-80GB 하나에 모든 모델의 무게를 담을 수 있습니다.
현재 대규모 언어 모델에 대한 기존의 학습 후 양자화 알고리즘에는 양자화 매개변수의 수동 설정에 의존하고 해당 최적화 프로세스가 부족하다는 명백한 문제가 있습니다. 이로 인해 기존 방법에서는 낮은 비트 양자화를 수행할 때 종종 성능 저하가 발생합니다. 양자화 인식 훈련은 최적의 양자화 구성을 결정하는 데 효과적이지만 추가적인 훈련 비용과 데이터 지원이 필요합니다. 특히 대규모 언어 모델의 경우 계산량 자체가 이미 크기 때문에 대규모 언어 모델의 양자화에 양자화 인식 훈련을 적용하기가 더욱 어려워집니다.
이것은 다음과 같은 질문을 던집니다. 훈련 후 양자화의 시간과 데이터 효율성을 유지하면서 양자화 인식 훈련의 성능을 달성할 수 있습니까?
대형 언어 모델의 사후 훈련 중 양자화 매개변수 최적화 문제를 해결하기 위해 상하이 인공 지능 연구소, 홍콩 대학교, 홍콩 중문 대학교 연구진이 "OmniQuant: Omni Directionly"를 제안했습니다. 대규모 언어 모델을 위한 보정된 양자화". 이 알고리즘은 대규모 언어 모델에서 가중치의 양자화 및 활성화를 지원할 뿐만 아니라 다양한 양자화 비트 설정에 적응할 수도 있습니다.

arXiv 논문 주소: https://arxiv.org/abs/2308.13137
OpenReview 논문 주소: https://openreview.net/forum?id=8Wuvhh0LYW
코드 주소: https://github. com/OpenGVLab/OmniQuant
Framework Method

위 그림과 같이 OmniQuant는 LLM(대형 언어 모델)을 위한 미분 양자화 기술로 가중치 전용 양자화와 가중치 활성화 값 동시 양자화를 모두 지원합니다. 또한, 훈련 시간 효율성과 훈련 후 정량화의 데이터 효율성을 유지하면서 고성능 양자화 모델을 달성합니다. 예를 들어 OmniQuant는 단일 카드 A100-40GB에서 LLaMA-7B ~ LLaMA70B 모델의 양자화 매개변수를 1~16시간 내에 업데이트할 수 있습니다.
이 목표를 달성하기 위해 OmniQuant는 블록별 양자화 오류 최소화 프레임워크를 채택합니다. 동시에 OmniQuant는 가중치 양자화의 어려움을 완화하기 위한 학습 가능한 가중치 클리핑(LWC)과 학습 가능한 등가 변환(LET)을 포함하여 학습 가능한 양자화 매개변수를 늘리기 위한 두 가지 새로운 전략을 설계하여 양자화 과제를 더욱 전환합니다. 활성화 값에서 가중치까지.
또한 OmniQuant에서 도입한 모든 학습 가능한 매개변수는 양자화가 완료된 후 융합 및 제거가 가능하며, 양자화 모델은 GPU, Android, IOS 등 기존 도구를 기반으로 하는 여러 플랫폼에 배포할 수 있습니다.
블록별 양자화 오류 최소화
OmniQuant는 블록별 양자화 오류 최소화를 사용하고 추가 양자화 매개변수를 미분 가능한 방식으로 최적화하는 새로운 최적화 프로세스를 제안합니다. 그중 최적화 목표는 다음과 같이 공식화됩니다.
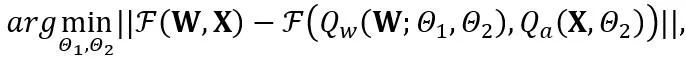
여기서 F는 LLM, W에서 변환기 블록의 매핑 함수를 나타내고 각각 학습 가능한 가중치 클리핑(LWC) 및 학습 가능한 등가 변환(LET)의 양자화 매개변수입니다. . OmniQuant는 블록 방식 양자화를 설치하여 다음 변환기 블록으로 이동하기 전에 하나의 변환기 블록의 매개변수를 순차적으로 양자화합니다. 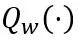
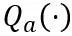
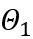 학습 가능한 체중 클리핑(LWC)
학습 가능한 체중 클리핑(LWC)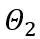
등가 변환은 모델 가중치와 활성화 값 사이의 크기 전달을 수행합니다. OmniQuant가 채택한 학습 가능한 등가 변환은 매개변수 최적화 프로세스 중 훈련을 통해 모델 가중치 분포가 지속적으로 변경되도록 합니다. 가중치 클리핑 임계값을 직접 학습하는 이전 방법[1,2]은 가중치 분포가 크게 변하지 않는 경우에만 적합하며 그렇지 않으면 수렴하기 어렵습니다. 이 문제를 기반으로 가중치 클리핑 임계값을 직접 학습하는 이전 방법과 달리 LWC는 다음과 같은 방식으로 클리핑 강도를 최적화합니다.
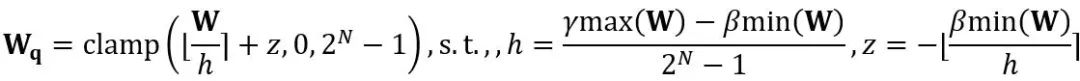
여기서 ⌊⋅⌉는 반올림 연산을 나타냅니다. N은 목표 자릿수입니다. 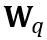 및 W는 각각 양자화된 가중치와 완전 정밀도 가중치를 나타냅니다. h는 가중치의 정규화 인자이고 z는 영점 값입니다. 클램프 연산은 양자화된 값을 N비트 정수 범위, 즉
및 W는 각각 양자화된 가중치와 완전 정밀도 가중치를 나타냅니다. h는 가중치의 정규화 인자이고 z는 영점 값입니다. 클램프 연산은 양자화된 값을 N비트 정수 범위, 즉 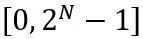 로 제한합니다. 위 공식에서
로 제한합니다. 위 공식에서 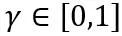 및
및 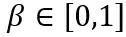 는 각각 가중치의 상한 및 하한에 대한 학습 가능한 클리핑 강도입니다. 따라서 최적화 목적 함수
는 각각 가중치의 상한 및 하한에 대한 학습 가능한 클리핑 강도입니다. 따라서 최적화 목적 함수 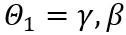 에서.
에서.
Learnable Equivalent Transformation(LET)
양자화에 더 적합한 가중치로 LWC를 달성하기 위해 클리핑 임계값을 최적화하는 것 외에도 OmniQuant는 LET를 통해 활성화 값을 양자화하는 어려움을 더욱 줄여줍니다. LLM 활성화 값의 이상치가 특정 채널에 존재한다는 점을 고려하여 SmoothQuant[3], Outlier Supression+[4]와 같은 이전 방법에서는 양자화의 어려움을 수학적으로 등가적인 변환을 통해 활성화 값에서 가중치로 전달합니다.
그러나 수동 선택이나 욕심 많은 검색으로 얻은 등가 변환 매개변수는 양자화 모델의 성능을 제한합니다. 블록별 양자화 오류 최소화 기능을 도입한 덕분에 OmniQuant의 LET는 미분 가능한 방식으로 최적의 등가 변환 매개변수를 결정할 수 있습니다. Outlier Suppression+~citep {outlier-plus}에서 영감을 받은 채널 수준 스케일링 및 채널 수준 이동은 활성화 분포를 조작하는 데 사용되어 활성화 값의 이상값 문제에 대한 효과적인 솔루션을 제공합니다. 특히 OmniQuant는 선형 레이어와 어텐션 작업에서 동등한 변환을 탐색합니다.
선형 레이어의 등가 변환: 선형 레이어는 토큰의 입력 시퀀스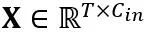 를 허용합니다. 여기서 T는 토큰 길이이고 가중치 행렬
를 허용합니다. 여기서 T는 토큰 길이이고 가중치 행렬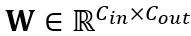 과 편향 벡터
과 편향 벡터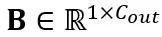 의 곱입니다. 수학적으로 동등한 선형 레이어 표현은 다음과 같습니다:
의 곱입니다. 수학적으로 동등한 선형 레이어 표현은 다음과 같습니다:
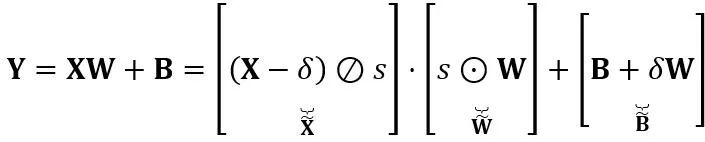
여기서 Y는 출력을 나타내고, 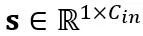 및
및 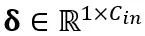 는 각각 채널 수준 스케일링 및 이동 매개변수이고,
는 각각 채널 수준 스케일링 및 이동 매개변수이고, 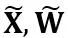 및
및 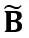 는 각각 등가 활성화, 가중치 및 편향, ⊘ 및 ⊙ 요소 수준 분할 및 곱셈을 나타냅니다. 위 식의 등가변환을 통해 활성화값은 가중치를 정량화하기 어려운 대신에 정량화하기 쉬운 형태로 변환된다. 이러한 의미에서 LWC는 가중치를 더 쉽게 정량화할 수 있기 때문에 LET로 달성한 모델 양자화 성능을 향상시킬 수 있습니다. 마지막으로 OmniQuant는 다음과 같이 변환된 활성화 및 가중치를 양자화합니다.
는 각각 등가 활성화, 가중치 및 편향, ⊘ 및 ⊙ 요소 수준 분할 및 곱셈을 나타냅니다. 위 식의 등가변환을 통해 활성화값은 가중치를 정량화하기 어려운 대신에 정량화하기 쉬운 형태로 변환된다. 이러한 의미에서 LWC는 가중치를 더 쉽게 정량화할 수 있기 때문에 LET로 달성한 모델 양자화 성능을 향상시킬 수 있습니다. 마지막으로 OmniQuant는 다음과 같이 변환된 활성화 및 가중치를 양자화합니다.

여기서 Q_a는 일반적인 MinMax 양자화기이고 Q_w는 학습 가능한 가중치 클리핑(즉, 제안된 LWC)이 있는 MinMax 양자화기입니다.
주의 작업의 등가 변환: 선형 레이어 외에도 주의 작업도 LLM 계산의 대부분을 차지합니다. 또한 LLM의 자동 회귀 추론 모드에서는 각 토큰에 대해 키-값(KV) 캐시를 저장해야 하므로 긴 시퀀스에 대해 엄청난 메모리 요구 사항이 발생합니다. 따라서 OmniQuant는 자율 힘 계산에서 Q/K/V 행렬을 낮은 비트로 양자화하는 것도 고려합니다. 구체적으로 self-attention 행렬의 학습 가능한 등가 변환은 다음과 같이 작성할 수 있습니다.

여기서 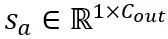 스케일링 인자. Self Attention 계산의 정량적 계산은
스케일링 인자. Self Attention 계산의 정량적 계산은 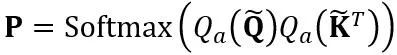 로 표현됩니다. 여기서 OmniQuant는
로 표현됩니다. 여기서 OmniQuant는 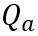 행렬을 양자화하기 위해 MinMax 양자화 방식을
행렬을 양자화하기 위해 MinMax 양자화 방식을 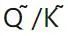 로 사용합니다. 따라서 목적 함수의
로 사용합니다. 따라서 목적 함수의  가 궁극적으로 최적화됩니다.
가 궁극적으로 최적화됩니다.
의사 코드

OmniQuant의 의사 알고리즘은 위 그림과 같습니다. LWC 및 LET에 의해 도입된 추가 매개변수는 모델이 양자화된 후에 제거될 수 있습니다. 즉, OmniQuant는 양자화된 모델에 추가 오버헤드를 도입하지 않으므로 기존 양자화 배포 도구에 직접 적용할 수 있습니다.
실험 성능
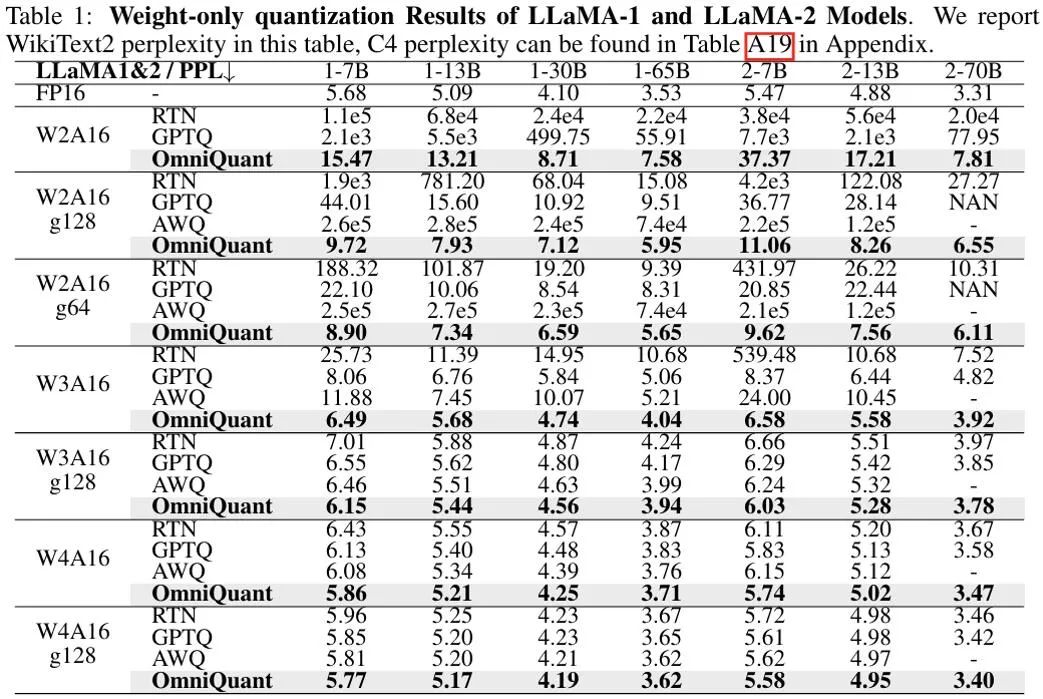
위 그림은 LLaMA 모델에 대한 OmniQuant의 가중치 전용 정량화 결과의 실험 결과를 보여줍니다. 더 많은 OPT 모델 결과는 원문을 참조하세요. 볼 수 있듯이 OmniQuant는 다양한 LLM 모델(OPT, LLaMA-1, LLaMA-2) 및 다양한 양자화 구성(W2A16, W2A16g128, W2A16g64, W3A16, W3A16g128, W4A16 및 W4A16g128 포함)에서 이전 모델보다 지속적으로 성능이 뛰어납니다. LLM은 중량 정량화입니다. 방법만. 동시에, 이러한 실험은 OmniQuant의 다양성과 다양한 정량화 구성에 적응할 수 있는 능력을 보여줍니다. 예를 들어, AWQ[5]는 그룹 양자화에 특히 효과적인 반면, OmniQuant는 채널 수준 및 그룹 수준 양자화 모두에서 우수한 성능을 보여줍니다. 또한 양자화 비트 수가 감소함에 따라 OmniQuant의 성능 이점은 더욱 분명해집니다.
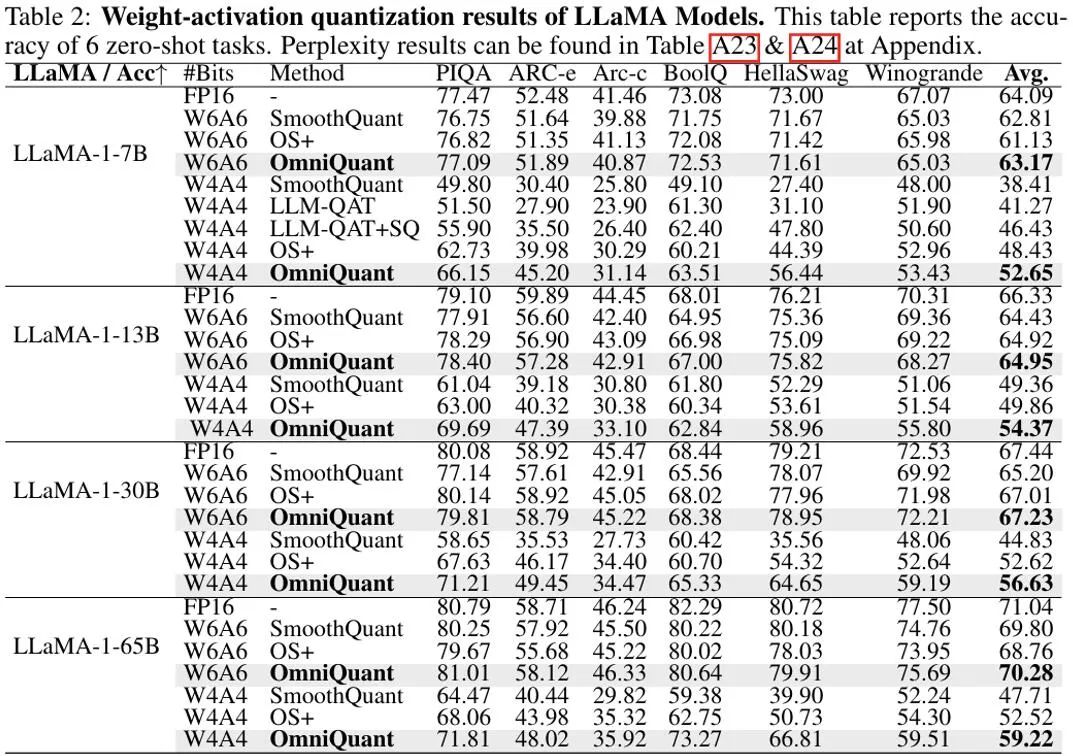
가중치와 활성화가 모두 양자화되는 설정에서 실험의 주요 초점은 W6A6 및 W4A4 양자화입니다. 이전 SmoothQuant는 전체 정밀도 모델에 비해 거의 무손실 W8A8 모델 양자화를 달성했기 때문에 W8A8 양자화는 실험 설정에서 제외되었습니다. 위 그림은 LLaMA 모델에 대한 OmniQuant의 가중치 활성화 값을 정량화한 실험 결과를 보여줍니다. 특히 OmniQuant는 W4A4 정량화의 다양한 모델 전반에 걸쳐 평균 정확도를 +4.99%에서 +11.80%까지 크게 향상시켰습니다. 특히 LLaMA-7B 모델에서 OmniQuant는 최신 양자화 인식 훈련 방법인 LLM-QAT[6]보다 +6.22%의 상당한 격차를 보입니다. 이러한 개선은 학습 가능한 추가 매개변수 도입의 효율성을 보여 주며, 이는 양자화 인식 훈련에 사용되는 전역 가중치 조정보다 더 유익합니다.

동시에 OmniQuant를 사용하여 양자화된 모델을 MLC-LLM[7]에 원활하게 배포할 수 있습니다. 위 그림은 NVIDIA A100-80G에서 LLaMA 시리즈 양자화 모델의 메모리 요구 사항과 추론 속도를 보여줍니다.
Weights Memory(WM)는 양자화된 가중치 저장을 나타내고, Running Memory(RM)는 추론 중 메모리를 나타내며, 후자는 특정 활성화 값이 유지되기 때문에 더 높습니다. 추론 속도는 512개의 토큰을 생성하여 측정됩니다. 양자화된 모델이 16비트 완전 정밀도 모델에 비해 메모리 사용량을 크게 줄이는 것은 분명합니다. 또한 W4A16g128 및 W2A16g128 양자화는 추론 속도를 거의 두 배로 늘립니다.
MLC-LLM[7]이 Android 휴대폰 및 IOS 휴대폰을 포함한 다른 플랫폼에서도 OmniQuant 정량화 모델 배포를 지원한다는 점은 주목할 가치가 있습니다. 위 그림에 표시된 것처럼 최근 애플리케이션 Private LLM은 OmniQuant 알고리즘을 사용하여 iPhone, iPad, macOS 등과 같은 여러 플랫폼에서 LLM의 메모리 효율적인 배포를 완료합니다.
요약
OmniQuant는 양자화를 낮은 비트 형식으로 발전시키는 고급 대형 언어 모델 양자화 알고리즘입니다. OmniQuant의 핵심 원리는 학습 가능한 양자화 매개변수를 추가하면서 원래의 완전 정밀도 가중치를 유지하는 것입니다. 학습 가능한 가중치 연결과 등가 변환을 활용하여 가중치와 활성화 값의 양자화 호환성을 최적화합니다. OmniQuant는 그래디언트 업데이트를 통합하면서도 기존 PTQ 방법과 유사한 훈련 시간 효율성과 데이터 효율성을 유지합니다. 또한 OmniQuant는 추가된 훈련 가능한 매개변수를 추가 오버헤드 없이 원래 모델에 통합할 수 있으므로 하드웨어 호환성을 보장합니다.
Reference
[1] Pact: 양자화된 신경망을 위한 매개변수화된 클리핑 활성화.
[2] LSQ: 학습된 단계 크기 양자화.
[3] SmoothQuant: 정확하고 효율적인 게시물 -대규모 언어 모델을 위한 양자화 훈련.
[4] 이상값 억제+: 등가 및 최적 이동 및 스케일링을 통해 대규모 언어 모델의 정확한 양자화.
[5] Awq: llm 압축 및
[6] Llm-qat: 대규모 언어 모델을 위한 데이터 없는 양자화 인식 교육.
[7] MLC-LLM: https://github.com/mlc-ai/mlc-llm
위 내용은 ICLR 2024 스포트라이트 | 대형 언어 모델 가중치, 활성화, 전반적인 낮은 비트 미세화가 상용 APP에 통합되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!