
Stable Diffusion 3 기술 보고서 공개: Sora의 동일한 아키텍처에 대한 세부 정보 공개

- 王林앞으로
- 2024-03-07 12:01:11958검색
곧, “빈첸시안 그래픽의 새로운 왕”인 Stable Diffusion 3의 기술 보고서가 나왔습니다.
원문은 총 28페이지로 정성이 가득 담겨있습니다.

"기존 규칙", 홍보 포스터(⬇️)는 모델과 함께 직접 생성되고 텍스트 렌더링 기능을 과시합니다.
그래서 SD3는 DALL·E 3 및 Midjourney v6보다 더 강력한 텍스트와 명령을 가지고 있습니다. 다음 스킬은 어떻게 발동되나요?
기술 보고서에 따르면:
모두 다중 모드 확산 변압기 아키텍처 MMDiT에 의존합니다.
이미지와 텍스트 표현에 서로 다른 가중치 세트를 적용하여 이전 버전보다 더 큰 성능 개선을 달성하는 것이 성공의 열쇠입니다.
특정 형상에 대해서는 보고서를 열어 살펴보겠습니다.
텍스트 렌더링 기능을 향상시키기 위해 미세 조정된 DiT
SD3 출시 초기에 관계자는 해당 아키텍처가 Sora와 동일한 기원을 가지며 확산 Transformer-DiT라고 밝혔습니다.
이제 답이 공개됩니다.
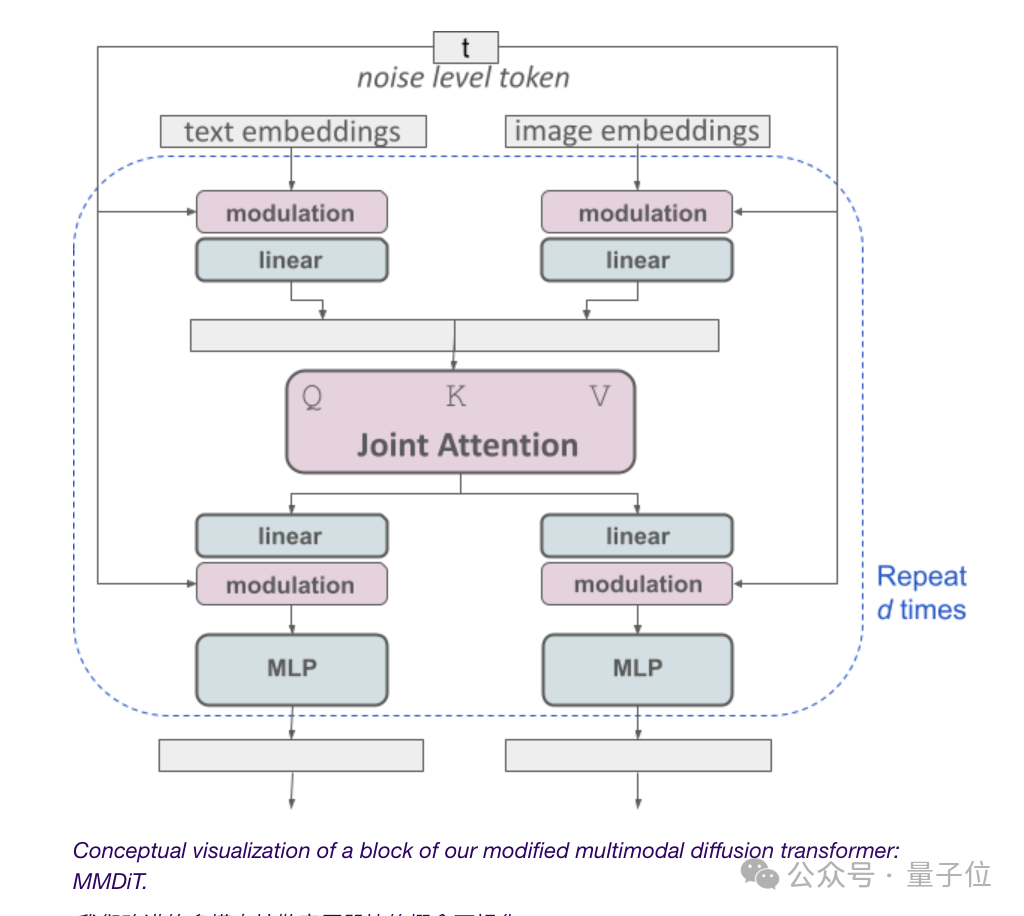
Vincent 다이어그램 모델은 텍스트 모드와 이미지 모드를 모두 고려해야 하기 때문에 Stability AI는 DiT에서 한 단계 더 나아가 새로운 아키텍처 MMDiT를 제안합니다.
여기서 "MM"은 "멀티모달"을 의미합니다.
Stable Diffusion의 이전 버전과 마찬가지로 공식에서는 사전 훈련된 두 가지 모델을 사용하여 적절한 텍스트 및 이미지 표현을 얻습니다.
텍스트 표현의 인코딩은 두 개의 CLIP 모델과 하나의 T5 모델을 포함하여 세 가지 다른 텍스트 임베더(임베더)를 사용하여 수행됩니다.
향상된 자동 인코더 모델을 사용하여 이미지 토큰의 인코딩이 완료되었습니다.
텍스트 임베딩과 이미지 임베딩은 개념적으로 동일하지 않기 때문에 SD3는 이 두 모드에 대해 두 세트의 독립 가중치를 사용합니다.
(일부 네티즌 불만: 이 건축도가 '인간 완성 프로젝트'를 시작하는 것 같다, 네, 누군가 '신세기 에반게리온' 정보를 보고 이 보고서를 클릭했습니다')
얻기 다시 주제로 돌아가서, 위 그림에 표시된 것처럼 이는 각 양식에 대해 두 개의 독립 변환기를 갖는 것과 동일하지만 해당 시퀀스는 주의 작업을 위해 연결됩니다.
이렇게 하면 두 표현 모두 다른 표현을 고려하면서 자체 공간에서 작동할 수 있습니다.
궁극적으로 이 방법을 통해 이미지와 텍스트 토큰 간에 정보가 "흐를" 수 있어 출력 시 모델의 전반적인 이해와 텍스트 렌더링 기능이 향상됩니다.
그리고 이전 효과에서 볼 수 있듯이 이 아키텍처는 비디오와 같은 여러 모드로 쉽게 확장될 수도 있습니다.

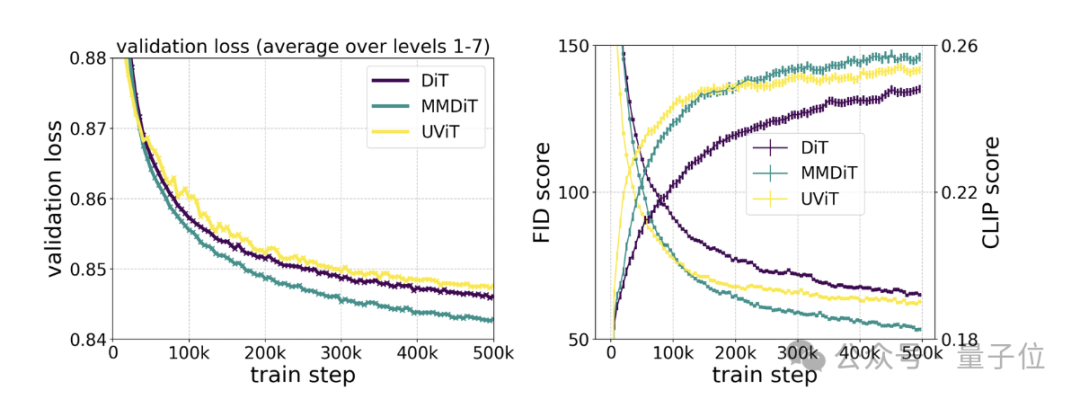
특정 테스트에 따르면 MMDiT는 DiT를 기반으로 하지만 DiT보다 우수합니다.
교육 과정 중 시각적 충실도와 텍스트 정렬이 UViT 및 DiT와 같은 기존 텍스트-이미지 백본보다 우수합니다.
지속적인 성능 향상을 위해 재가중된 흐름 기술
출시 초반에는 확산 트랜스포머 아키텍처 외에도 SD3에 흐름 매칭이 포함되어 있다고 공식적으로 밝혔습니다.
“흐름”이란 무엇입니까?
오늘 발표된 논문 제목에서도 밝혔듯이 SD3는 "Rectified Flow"(RF)를 사용합니다.

ICLR2023에서 채택된 "매우 단순화된 1단계 생성" 새로운 확산 모델 생성 방법입니다.
훈련 중에 모델의 데이터와 노이즈를 선형 궤적으로 연결할 수 있으므로 샘플링에 더 적은 단계를 사용할 수 있는 보다 "직선적인" 추론 경로가 생성됩니다.
RF를 기반으로 하는 SD3는 훈련 과정에서 새로운 궤적 샘플링을 도입합니다.
궤도의 중간 부분에 더 많은 가중치를 두는 데 중점을 둡니다. 왜냐하면 저자는 이러한 부분이 더 어려운 예측 작업을 완료할 것이라고 가정하기 때문입니다.
여러 데이터세트, 측정항목 및 샘플러 구성에 걸쳐 60가지 다른 확산 궤적 방법(예: LDM, EDM 및 ADM)에 대해 이 생성 방법을 테스트한 결과 다음과 같은 사실이 발견되었습니다.
이전 RF 방법은 몇 단계 샘플링 체계에서 좋은 성능을 보였지만, 그러나 단계 수가 증가함에 따라 상대적인 성능은 감소합니다.
반대로 SD3 재가중 RF 변형은 지속적으로 성능을 향상시킵니다.
모델 성능을 더욱 향상시킬 수 있습니다
공식에서는 재가중 RF 방법과 MMDiT 아키텍처를 사용하여 텍스트-이미지 생성에 대한 스케일링 연구를 수행했습니다.
학습된 모델의 범위는 4억 5천만 개의 매개변수가 있는 15개 모듈부터 80억 개의 매개변수가 있는 38개 모듈까지 다양합니다.
이로부터 그들은 관찰했습니다. 모델 크기와 훈련 단계가 증가함에 따라 검증 손실은 완만한 하향 추세를 나타냅니다. 즉, 모델은 지속적인 학습을 통해 더 복잡한 데이터에 적응합니다.
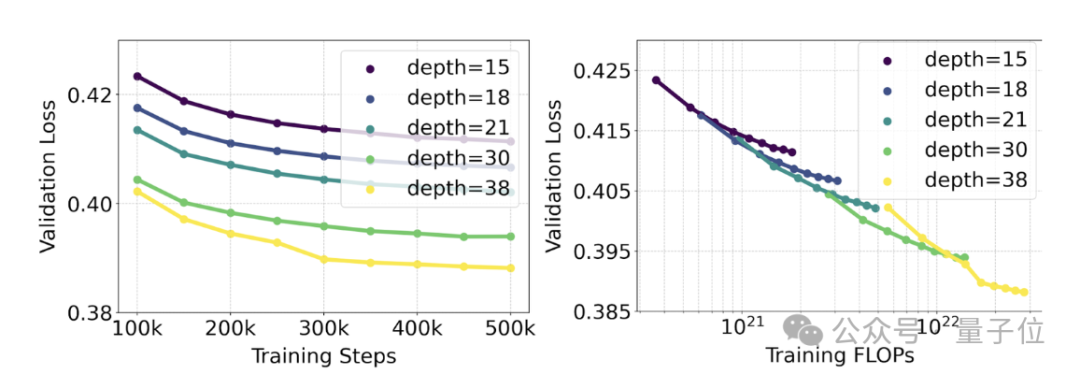
이것이 모델 출력의 보다 의미 있는 개선으로 해석되는지 테스트하기 위해 자동 이미지 정렬 측정항목 (GenEval) 과 인간 선호도 점수 (ELO) 도 평가했습니다.
결과는 다음과 같습니다.
둘 사이에는 강한 상관관계가 있습니다. 즉, 검증 손실은 전체 모델 성능을 예측하는 데 매우 강력한 지표로 사용될 수 있습니다.
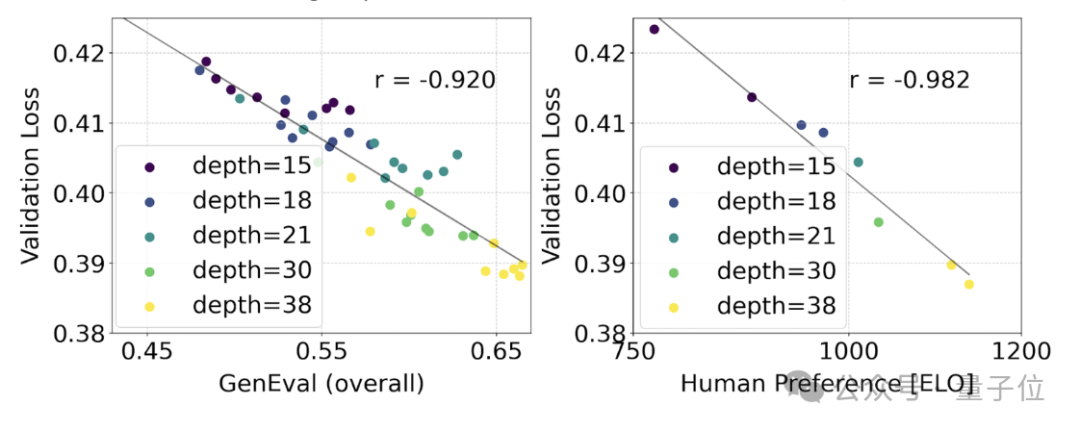
또한 여기의 확장 추세는 포화 조짐을 보이지 않기 때문에(즉, 모델 크기가 커짐에 따라 성능이 여전히 향상되고 있으며 한계에 도달하지 않았습니다) 공식은 매우 낙관적입니다.
The 앞으로도 SD3의 성능은 계속해서 향상될 수 있습니다.
마지막으로 기술 보고서에서는 텍스트 인코더 문제도 언급합니다.
추론에 사용되는 메모리 집약적인 T5 텍스트 인코더인 47억 개의 매개변수를 제거함으로써 SD3의 메모리 요구 사항을 크게 줄일 수 있지만 동시에 성능 손실이 적습니다(승률이 50%에서 46%로 감소).
그러나 텍스트 렌더링 기능을 위해 공식적인 권장 사항은 T5를 제거하지 않는 것입니다. T5가 없으면 텍스트 표현의 승률이 38%로 떨어지기 때문입니다.

요컨대, SD3의 세 가지 텍스트 인코더 중 T5는 텍스트가 포함된 이미지(및 매우 상세한 장면 설명 이미지)를 생성할 때 가장 큰 기여를 합니다.
네티즌: 오픈소스 약속이 예정대로 이행되었습니다. 감사합니다
SD3 보고서가 나오자마자 많은 네티즌들은 다음과 같이 말했습니다.
안정성 AI는 오픈소스 약속이 예정대로 이행된 것을 매우 기쁘게 생각합니다. 그리고 앞으로도 오랫동안 유지관리하고 운영할 수 있었으면 좋겠습니다.

어떤 사람들은 OpenAI라는 이름을 주장하기에는 부족합니다:

더욱 기쁜 것은 누군가 댓글 영역에서 언급했다는 것입니다:
SD3 모델의 모든 무게를 다운로드할 수 있으며, 현재 계획은 8억 개의 매개변수, 20억 개의 매개변수, 80억 개의 매개변수입니다.


속도는 어떤가요?
에헴, 기술 보고서에는 다음과 같이 언급되어 있습니다.
80억 SD3는 24GB RTX 4090에서 1024*1024 이미지를 생성하는 데 34초가 걸립니다 (50 샘플링 단계) - 하지만 이는 최적화되지 않은 초기의 예비 추론 테스트 결과일 뿐입니다.
보고서 전문: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf.
참조 링크:
[1]https://stability.ai/news/stable-diffusion-3-research-paper.
[2]https://news.ycombinator.com/item?id=39599958.
위 내용은 Stable Diffusion 3 기술 보고서 공개: Sora의 동일한 아키텍처에 대한 세부 정보 공개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!