
Pure js는 무제한 space_javascript 기술로 로컬 스토리지를 구현합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2016-05-16 15:54:141550검색
오랜만에 블로그를 작성하다 보니 2년 전에 소스코드를 공개하겠다고 약속했는데 드디어 순수 JS를 이용하여 공간이 무제한인 로컬 스토리지 기능을 오픈소스화하게 됐습니다. .
프로젝트 주소https://github.com/xueduany/localstore,
데모 보기http://xueduany.github.io/localstore/,
일반적인 원칙에 대해 간략하게 소개하겠습니다. 구체적인 내용과 예외 처리에 대해서는 나중에 기회가 되면 따로 다루겠습니다
먼저 localStorage 돌파 원리에 대해 이야기해 보겠습니다. 공식 단어는 다음과 같습니다 http://www.w3.org/TR/2013/PR-webstorage-20130409/

아시다시피 여러 하위 도메인의 localStorage가 서로 의존하지 않는다는 점을 활용하여 여러 하위 도메인의 localStorage를 통해 storePool을 설계하고 구현하여 상한선을 뛰어넘을 수 있습니다
그러면 실제 API가 저장될 때 localStorage에는 저장되지 않습니다
관리자 모드와 조금 비슷합니다. 즉, 저장하고 싶은 것을 창고관리자에게 말하면, 창고관리자가 열쇠를 주고, 그 열쇠를 해당 창고로 가져가서 물건을 보관하는 방식입니다. 그러면 관리자가 당신에게 토큰 인증서를 줍니다. 앞으로는 이 인증서만 가지고 있으면 저장된 물건을 꺼낼 수 있습니다.
localStorage와 유사한 API를 구현하기만 하면 최종 사용자는 내 데이터가 어디에 저장되어 있는지 신경 쓸 필요가 없습니다
그런 다음 창고 관리자 역할을 할 js 개체를 설계합니다. 이 관리자는 몇 개의 토큰을 지원해야 합니까? 그러면 해당 저장된 항목은 어디에 저장되어야 합니까? 우리는 이러한 데이터 구조 세트를 설계하고 구현해야 합니다
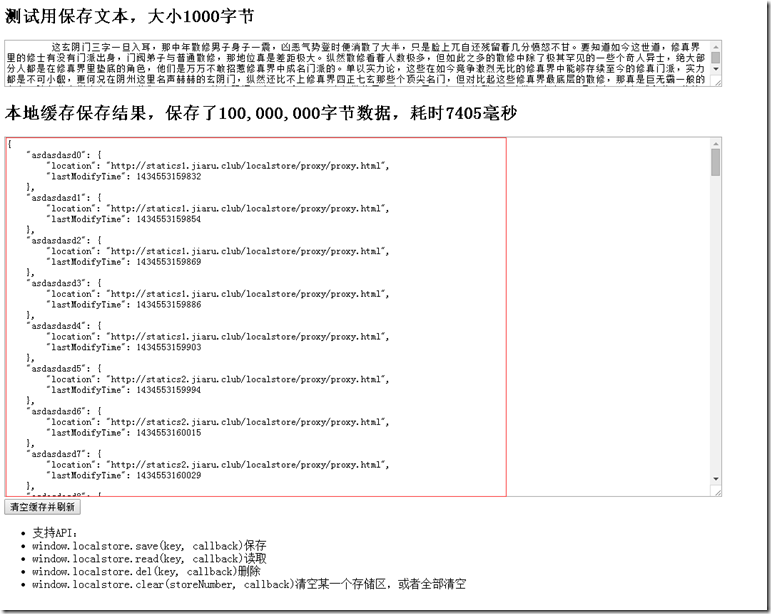
해당 키 아래에는 해당 데이터가 존재하는 창고의 주소와 보관 시간이 표시됩니다. 보관 기간의 개념은 데이터의 신선도, 즉 만료 여부를 계산하는 데 사용됩니다.
따라서 먼저 여러 도메인 이름으로 프록시 파일을 로드하고 HTML5 API postMessage 또는 기존 페이지 교차 도메인 방법을 통해 서로 상호 작용하고 이 프록시의 프록시를 통해 데이터를 저장하기 위해 여러 iframe을 만들어야 합니다.
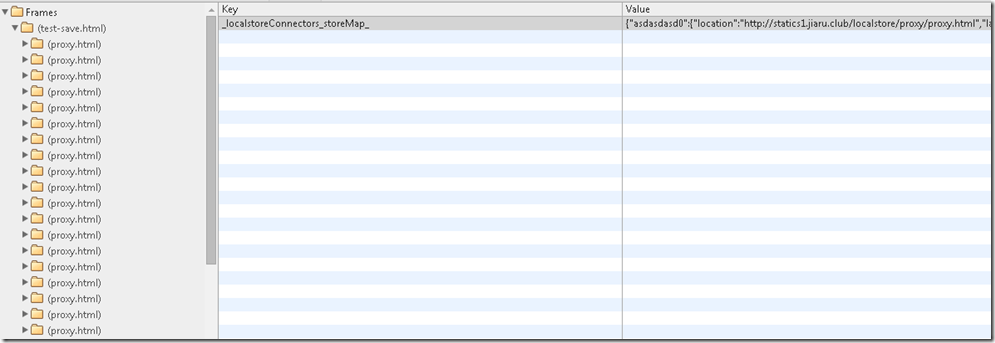
데이터 키의 스텁을 현재 기본 도메인 이름에 저장한 후 실제 데이터를 각 하위 도메인 이름에 저장합니다
자, 이제 저장 용량이 초과되었으므로 웹페이지를 저장하려면 웹페이지와 관련된 모든 정적 리소스를 끌어내리는 것을 고려해야 합니다. js, css를 포함한 웹페이지 관련 리소스는 모두 다음과 같습니다. ajax 요청이 이루어지면 콘텐츠를 얻을 수 있습니다. 고려해야 할 유일한 것은 도메인 간 문제로 인해 js가 응답 데이터를 얻을 수 없다는 것입니다. CDN 노드 서버의
에 대한 응답 헤더입니다.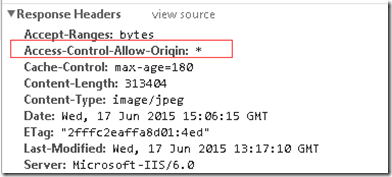
이제 모든 도메인에 걸쳐 콘텐츠를 얻을 수 있습니다
js, 즉 는 <script>원격으로 얻은 콘텐츠</script>, css, 이것을 으로 변경하세요.
여기서는 원본 HTML과 일치할 수 있는 코드 블록만 고려하면 됩니다. 즉, js의 정규식은 기본적으로 탐욕 모드이므로 정규식은 최소 일치를 달성해야 합니다.

그럼 사진의 내용은 어떻게 알 수 있나요? 우리는 그림이 원시 데이터, 바이너리라는 것을 알고 있습니다. 먼저 그림의 바이너리 스트림을 얻는 문제를 해결해야 합니다
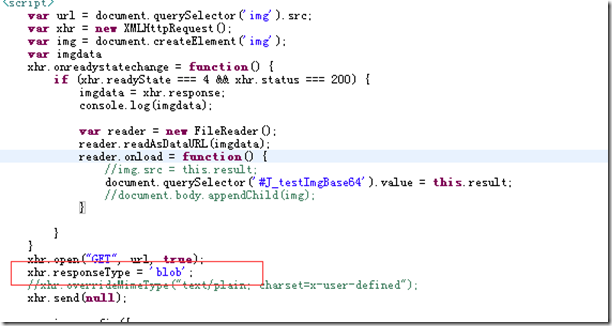
그런 다음 전체 웹페이지 HTML의 해당 리소스를 특수 태그로 교체합니다.
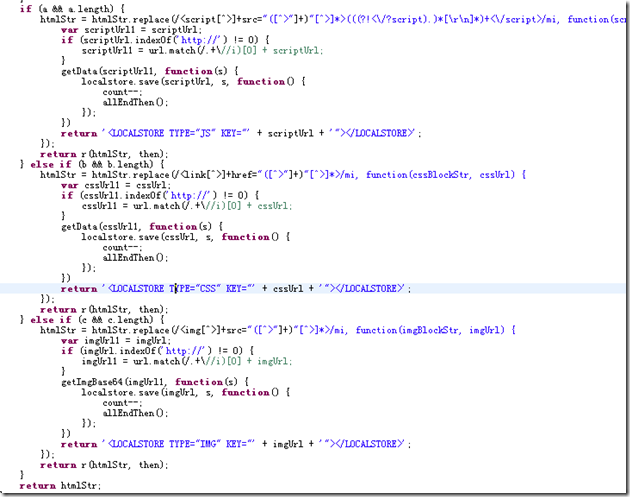
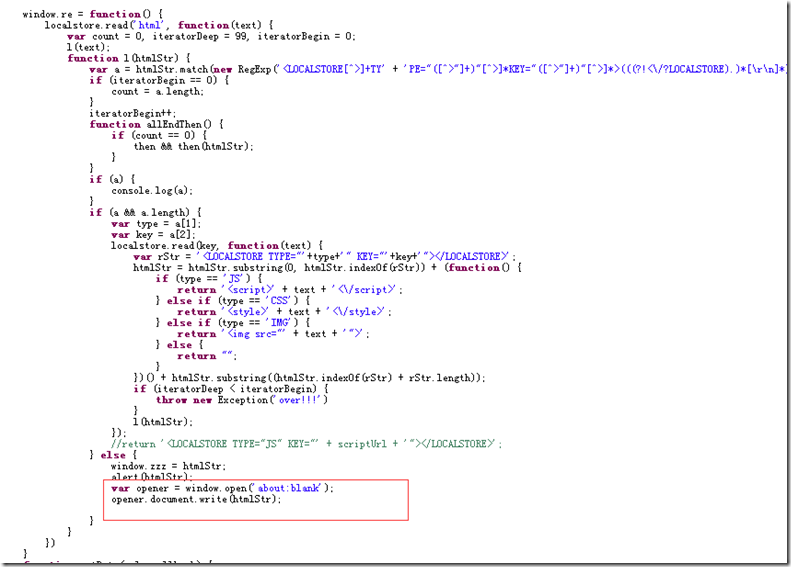
이 원칙을 통해 웹사이트를 오프라인으로 전환하고 현지화한 다음 단일 페이지 기술을 사용하여 요청을 보내지 않고도 검색할 수 있습니다. 물론 처리해야 할 몇 가지 기술적 세부 사항이 있습니다. 젠장, 다음번에 분해해 보자! ! !
위 내용은 이 글의 전체 내용입니다. 모두 마음에 드셨으면 좋겠습니다.