
Stable Diffusion 3 기술 보고서가 유출되었습니다. Sora 아키텍처가 다시 큰 성과를 거두었습니다! 오픈 소스 커뮤니티가 Midjourney와 DALL·E 3를 맹렬히 이기고 있습니까?

- PHPz앞으로
- 2024-03-06 16:22:20696검색
Stability AI는 Stable Diffusion 3 출시에 이어 오늘 자세한 기술 보고서를 공개했습니다.
이 논문은 DiT 기반 Vincentian 그래프의 개선된 버전과 DiT 기반의 새로운 아키텍처인 Stable Diffusion 3의 핵심 기술에 대한 심층 분석을 제공합니다!

신고 주소 :
https://www.php.cn/link/e5fb88b398b042f6cccce46bf3fa53e8
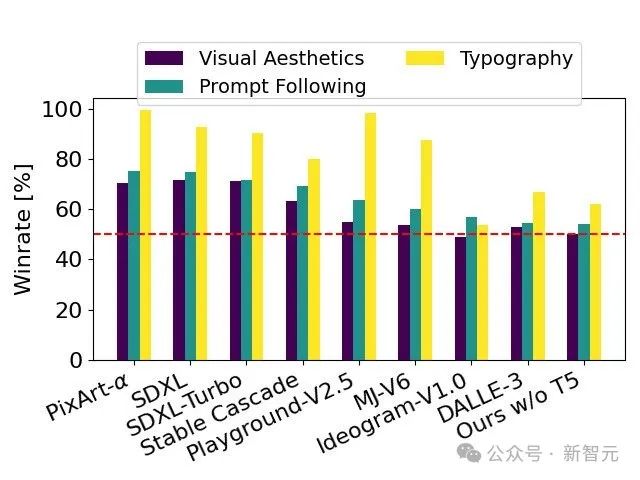
인체 평가 테스트 통과, 안정적 확산 3. 글꼴 디자인과 프롬프트에 대한 정확한 반응 성능면에서는 DALL·E 3, Midjourney v6, Ideogram v1을 능가합니다.
Stability AI의 새로 개발된 MMDiT(Multi-modal Diffusion Transformer) 아키텍처는 이미지 및 언어 표현을 위해 특별히 독립적인 가중치 세트를 사용합니다. 이전 버전의 SD 3에 비해 MMDiT는 텍스트 이해 및 철자법이 크게 향상되었습니다.

성능 평가
기술 보고서는 SD 3를 수많은 오픈 소스 모델인 SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 및 Pixart-α와 비교합니다. 비공개 소스 모델인 DALL·E 3, Midjourney v6 및 Ideogram v1을 자세히 평가했습니다.
평가자는 지정된 프롬프트의 일관성, 텍스트의 명확성 및 이미지의 전반적인 미학을 기반으로 각 모델에 가장 적합한 출력을 선택합니다.

테스트 결과에 따르면 Stable Diffusion 3은 프롬프트 따르기의 정확성, 텍스트의 명확한 표현 또는 이미지의 시각적 아름다움 측면에서 현재 Vincentian 다이어그램 생성 기술의 최고 수준에 도달하거나 초과했습니다.
완전히 하드웨어에 최적화되지 않은 SD 3 모델은 8B 매개변수를 가지고 있으며 24GB의 비디오 메모리를 갖춘 RTX 4090 소비자 GPU에서 실행될 수 있으며 50개의 샘플링 단계를 사용하여 1024x1024 해상도를 생성합니다. 이미지는 34초가 걸립니다. .
또한 Stable Diffusion 3은 출시되면 8억에서 80억까지의 매개변수를 갖춘 여러 버전을 제공하므로 사용을 위한 하드웨어 임계값을 더욱 낮출 수 있습니다.

건축 세부정보 노출
빈센트 다이어그램을 생성하는 과정에서 모델은 두 가지 유형의 정보, 텍스트와 이미지를 동시에 처리해야 합니다. 그래서 저자는 이 새로운 프레임워크를 MMDiT라고 부릅니다.
텍스트를 이미지로 생성하는 과정에서 모델은 텍스트와 이미지라는 두 가지 다른 정보 유형을 동시에 처리해야 합니다. 이것이 저자가 이 새로운 기술을 MMDiT(Multimodal Diffusion Transformer의 약어)라고 부르는 이유입니다.
이전 버전의 Stable Diffusion과 마찬가지로 SD 3도 사전 훈련된 모델을 사용하여 텍스트와 이미지의 적절한 표현을 추출합니다.
구체적으로, 두 개의 CLIP 모델과 T5라는 세 가지 텍스트 인코더를 사용하여 텍스트 정보를 처리하고, 더욱 발전된 자동 인코딩 모델을 사용하여 이미지 정보를 처리했습니다.
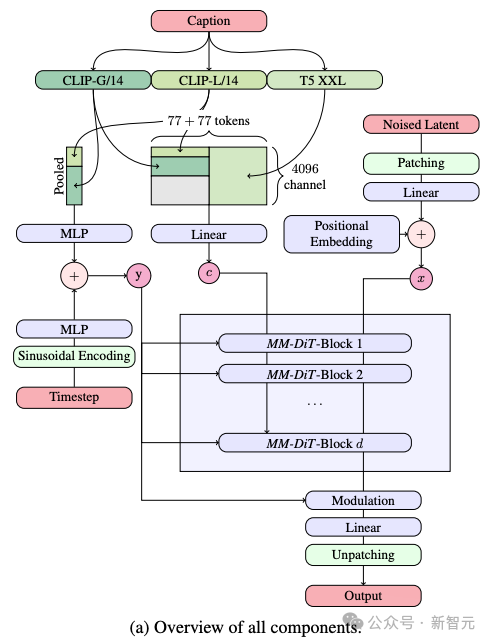
SD 3의 아키텍처는 DiT(확산 변압기)를 기반으로 구축되었습니다. 텍스트와 이미지 정보의 차이로 인해 SD 3는 이 두 가지 유형의 정보 각각에 대해 독립적인 가중치를 설정합니다.
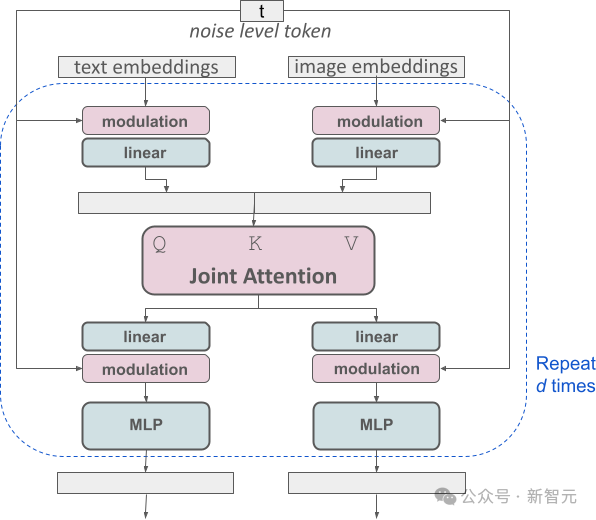
이 디자인은 각 정보 유형에 대해 두 개의 독립적인 변환기를 장착하는 것과 동일하지만 어텐션 메커니즘을 실행할 때 두 가지 유형의 정보의 데이터 시퀀스가 병합되어 해당 분야에서 독립적으로 작동할 수 있습니다. 상호 참조 및 통합.
이 독특한 아키텍처를 통해 이미지와 텍스트 정보가 서로 흐르고 상호 작용할 수 있으므로 콘텐츠에 대한 전반적인 이해와 생성된 결과의 시각적 표현이 향상됩니다.
또한 이 아키텍처는 향후 비디오를 포함한 다른 형식으로 쉽게 확장될 수 있습니다.

SD 3의 향상된 큐 추적 덕분에 이 모델은 이미지 스타일의 높은 수준의 유연성을 유지하면서 다양한 테마와 기능에 초점을 맞춘 이미지를 정확하게 생성할 수 있습니다.

재가중화 방법을 통해 개선된 정류 흐름
SD 3에서는 새로운 Diffusion Transformer 아키텍처 외에도 Diffusion 모델도 크게 개선되었습니다.
SD 3는 훈련 데이터와 노이즈를 직선 궤적을 따라 연결하는 RF(Rectified Flow) 전략을 채택합니다.
이 방법은 모델의 추론 경로를 더욱 직접적으로 만들어 샘플 생성을 더 적은 단계로 완료할 수 있습니다.
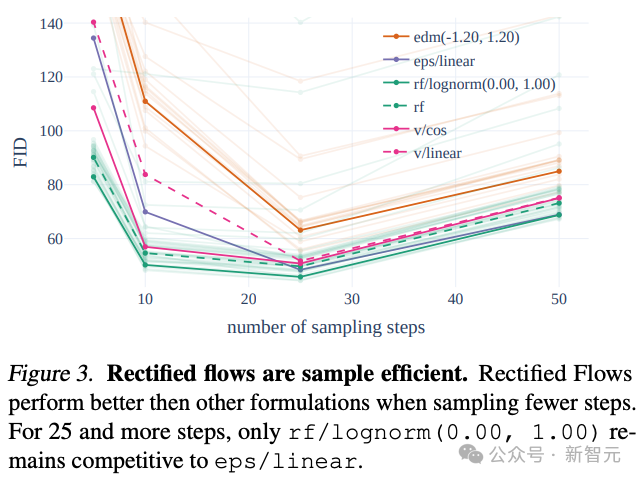
저자는 훈련 과정에서 혁신적인 궤적 샘플링 계획을 도입했는데, 특히 예측 작업이 더 어려운 궤적 중간 부분에 가중치를 늘렸습니다.
다른 60개의 확산 궤적(예: LDM, EDM 및 ADM)과 비교하여 저자는 이전 RF 방법이 몇 단계 샘플링에서 더 나은 성능을 보였지만 샘플링 단계 수가 증가함에 따라 성능이 천천히 감소한다는 것을 발견했습니다. .
이러한 상황을 피하기 위해 저자가 제안한 가중치 RF 방법은 모델 성능을 지속적으로 향상시킬 수 있습니다.
확장 RF 변압기 모델
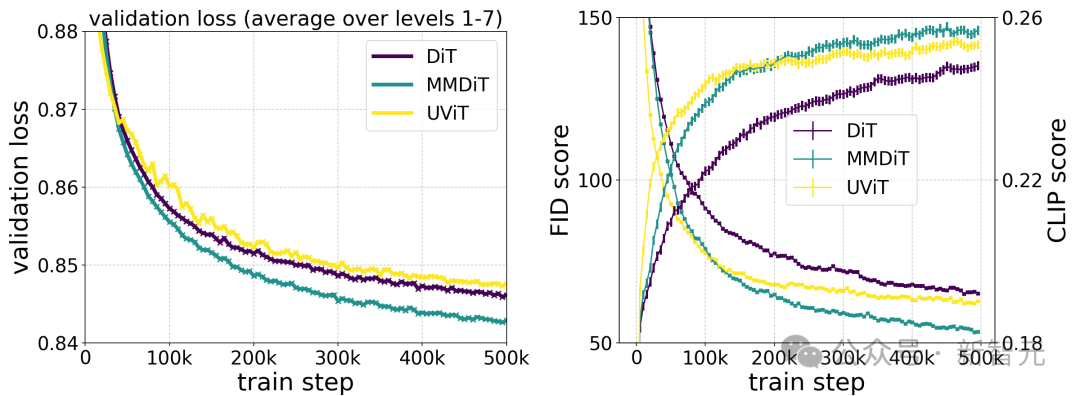
안정성 AI는 15개 모듈과 450M 매개변수부터 38개 모듈과 8B 매개변수까지 다양한 크기의 여러 모델을 훈련했으며, 모델 크기와 훈련 단계 모두 검증 손실을 원활하게 줄일 수 있음을 발견했습니다.
이것이 모델 출력의 실질적인 개선을 의미하는지 확인하기 위해 자동 이미지 정렬 측정항목과 인간 선호도 점수도 평가했습니다.
결과를 보면 이러한 평가지표는 검증손실과 강한 상관관계가 있음을 알 수 있으며, 이는 검증손실이 모델의 전반적인 성능을 측정하는 데 효과적인 지표임을 나타냅니다.
또한 이러한 확장 추세는 포화점에 도달하지 않았으므로 향후 모델 성능을 더욱 향상시킬 수 있다고 낙관합니다.
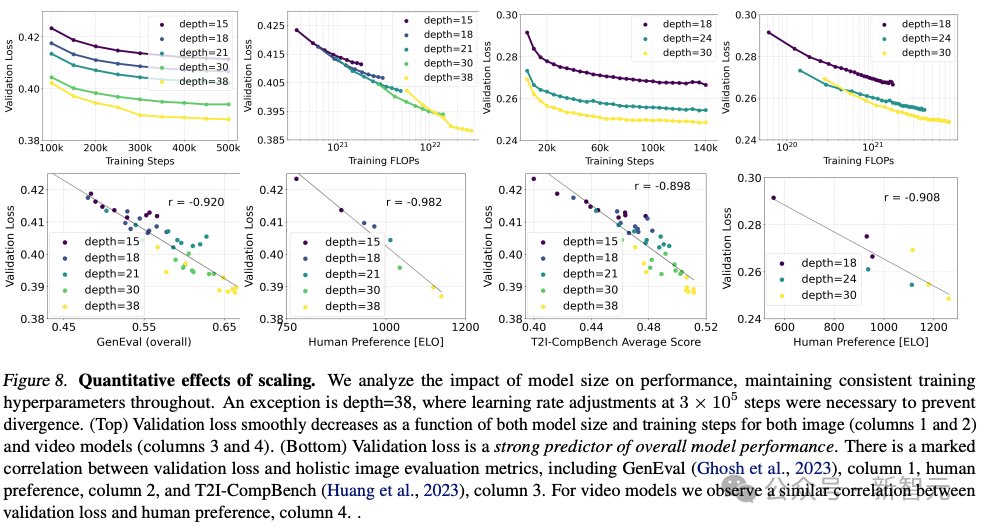
저자는 256 * 256 픽셀의 해상도와 4096의 배치 크기에서 다양한 매개변수 수를 사용하여 500,000단계에 대해 모델을 훈련했습니다.

위 그림은 더 큰 모델을 오랫동안 훈련하는 것이 샘플 품질에 미치는 영향을 보여줍니다.
위의 표는 GenEval의 결과를 보여줍니다. 저자가 제안한 훈련 방법을 사용하고 훈련 이미지의 해상도를 높이면 가장 큰 모델이 대부분의 범주에서 좋은 성능을 발휘하여 전체 점수에서 DALL·E를 3점 앞섰습니다.
저자의 다양한 아키텍처 모델 테스트 비교에 따르면 MMDiT는 DiT, Cross DiT, UViT 및 MM-DiT를 능가하여 매우 효과적입니다.
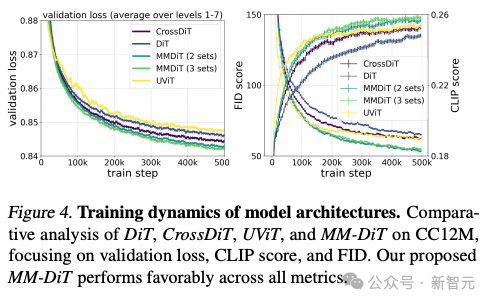
유연한 텍스트 인코더
추론 단계에서 메모리 집약적인 4.7B 매개변수 T5 텍스트 인코더를 제거함으로써 SD 3의 메모리 요구 사항은 성능 손실을 최소화하면서 크게 줄어듭니다.
이 텍스트 인코더를 제거해도 이미지의 시각적 아름다움에는 영향을 미치지 않지만(T5를 사용하지 않을 경우 승률 50%) 텍스트를 정확하게 따라가는 능력은 약간만 감소합니다(승률 46%).
그러나 SD 3의 텍스트 생성 기능을 최대한 활용하기 위해 저자는 여전히 T5 인코더를 사용할 것을 권장합니다.
저자는 이것이 없으면 생성된 텍스트를 조판하는 성능이 더 크게 떨어질 것이라는 것을 발견했습니다(승률 38%).

네티즌들 사이에서 뜨거운 논의
네티즌들은 Stability AI가 계속해서 사용자를 놀리지만 사용을 거부하는 것에 조금 조급해하며 가능한 한 빨리 온라인에 게시할 것을 촉구하고 있습니다.
네티즌들은 기술 애플리케이션을 읽은 후 이제 사진계가 오픈 소스가 폐쇄 소스를 무너뜨리는 첫 번째 트랙이 될 것 같다고 말했습니다!
위 내용은 Stable Diffusion 3 기술 보고서가 유출되었습니다. Sora 아키텍처가 다시 큰 성과를 거두었습니다! 오픈 소스 커뮤니티가 Midjourney와 DALL·E 3를 맹렬히 이기고 있습니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!