
GPT-4 시대는 끝났는가? 전 세계 네티즌들이 클로드3를 테스트하고 충격에 빠졌다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-03-06 13:00:18555검색
대형 모델의 일반 텍스트 방향이 끝까지 굴러갔나요?
어젯밤 OpenAI의 최대 경쟁자인 Anthropic은 차세대 AI 대형 모델 시리즈인 Claude 3를 출시했습니다.
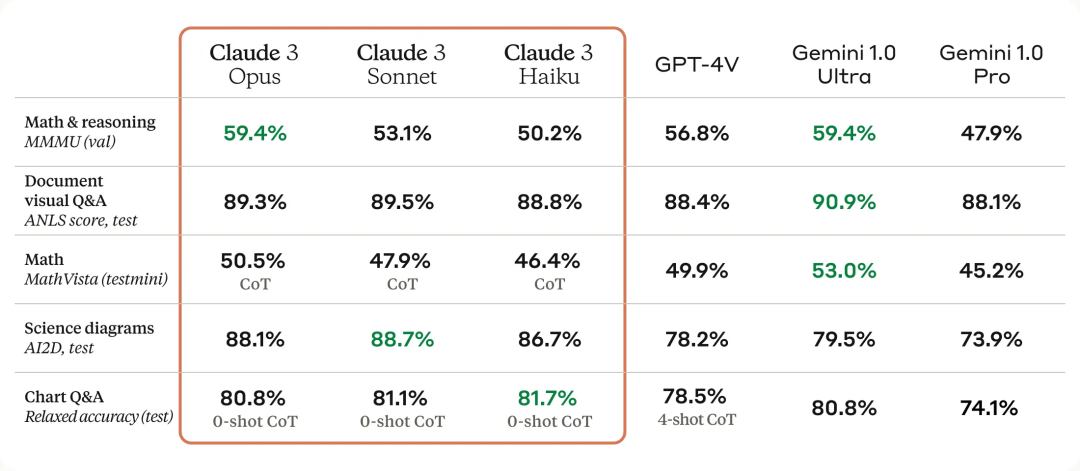
이 시리즈에는 가장 약한 것부터 가장 강한 것까지 순위가 매겨진 세 가지 모델, 즉 Claude 3 Haiku, Claude 3 Sonnet 및 Claude 3 Opus가 포함되어 있습니다. 그 중 가장 유능한 Opus는 여러 벤치마크 테스트에서 GPT-4 및 Gemini 1.0 Ultra보다 높은 점수를 획득하여 수학, 프로그래밍, 다국어 이해 및 비전과 같은 다차원에서 새로운 업계 벤치마크를 설정했습니다.
Anthropic은 Claude 3 Opus가 인간 학부 수준의 지식을 보유하고 있다고 말합니다.
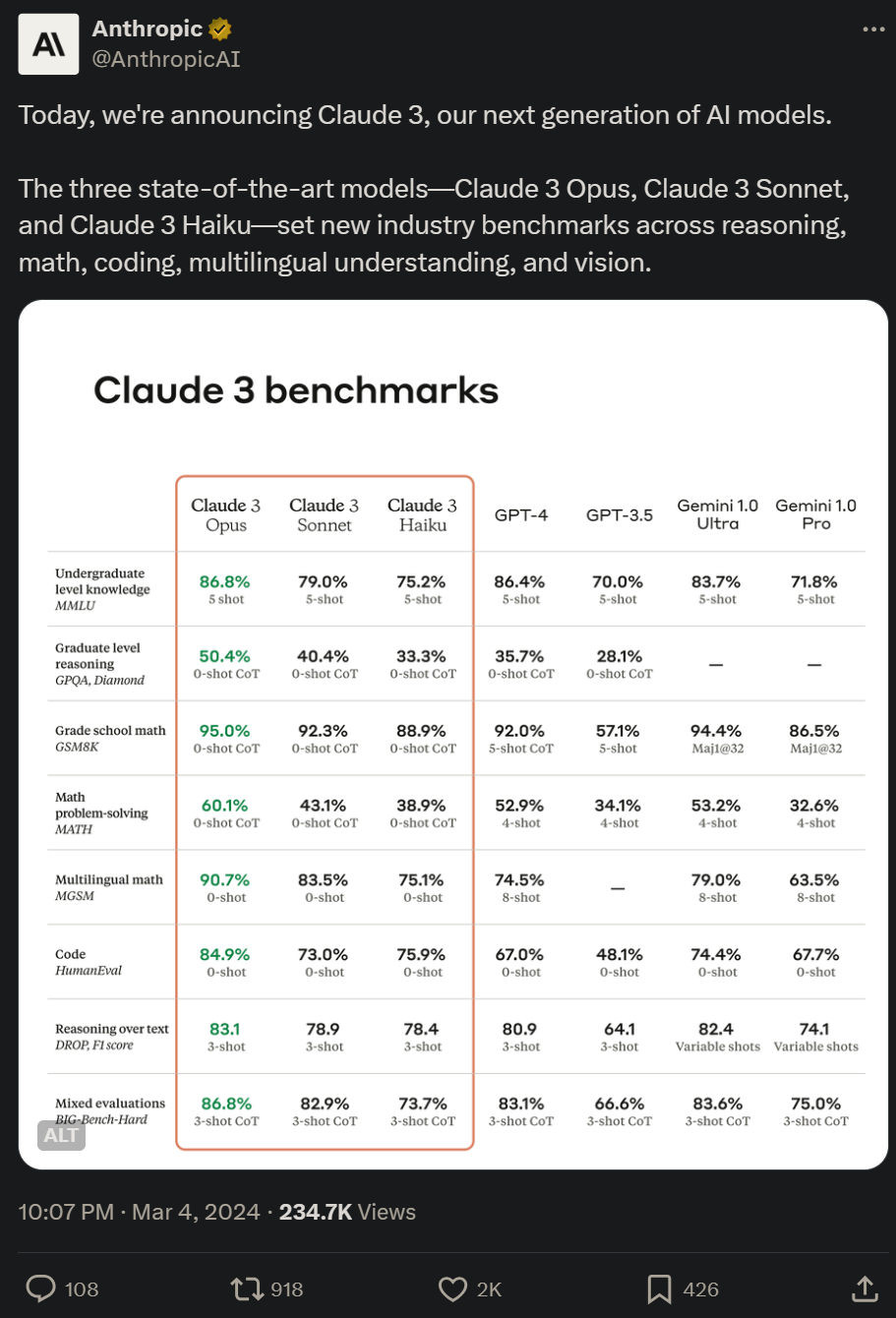
Claude는 새 모델 출시 후 처음으로 다중 모드 기능을 지원합니다(Opus 버전의 MMMU 점수는 59.4%로 GPT-4V를 초과하고 Gemini 1.0 Ultra와 동등합니다). 이제 사용자는 AI가 분석하고 답변할 수 있도록 사진, 차트, 문서 및 기타 유형의 비정형 데이터를 업로드할 수 있습니다.
또한 이 세 가지 모델은 Claude 시리즈 모델의 일관된 장점, 즉 긴 컨텍스트 창을 유지합니다. 처음에는 200K 토큰의 컨텍스트 창이 지원되지만 Anthropic은 세 가지 모델 모두 Moby Dick 또는 Harry Potter and the Deathly Hallows의 영어 버전 길이에 해당하는 100만 개의 토큰(특정 고객의 경우)의 컨텍스트 입력을 지원할 것이라고 말합니다.
그러나 가격 측면에서 가장 강력한 Claude 3는 GPT-4 Turbo보다 훨씬 비쌉니다. GPT-4 Turbo는 백만 개의 토큰 입력/출력당 10/30 USD를 청구하는 반면 Claude 3 Opus는 $15/입니다. 75.
Opus 및 Sonnet 모델은 이제 claude.ai 및 Claude API에서 사용할 수 있으며, Haiku 모델도 곧 제공될 예정입니다. Amazon Cloud Technologies는 이제 Amazon Bedrock에서 새로운 모델을 사용할 수 있다고 발표했습니다. Anthropic은 공식 데모를 발표했으며 자세한 내용은 다음과 같습니다.
Anthropic의 공식 발표 이후, 이를 시험해 볼 기회를 얻은 많은 연구자들도 자신의 경험을 공유했습니다. 어떤 사람들은 Claude 3 Sonnet이 이전에는 GPT-4만이 풀 수 있었던 퍼즐을 풀었다고 말합니다.
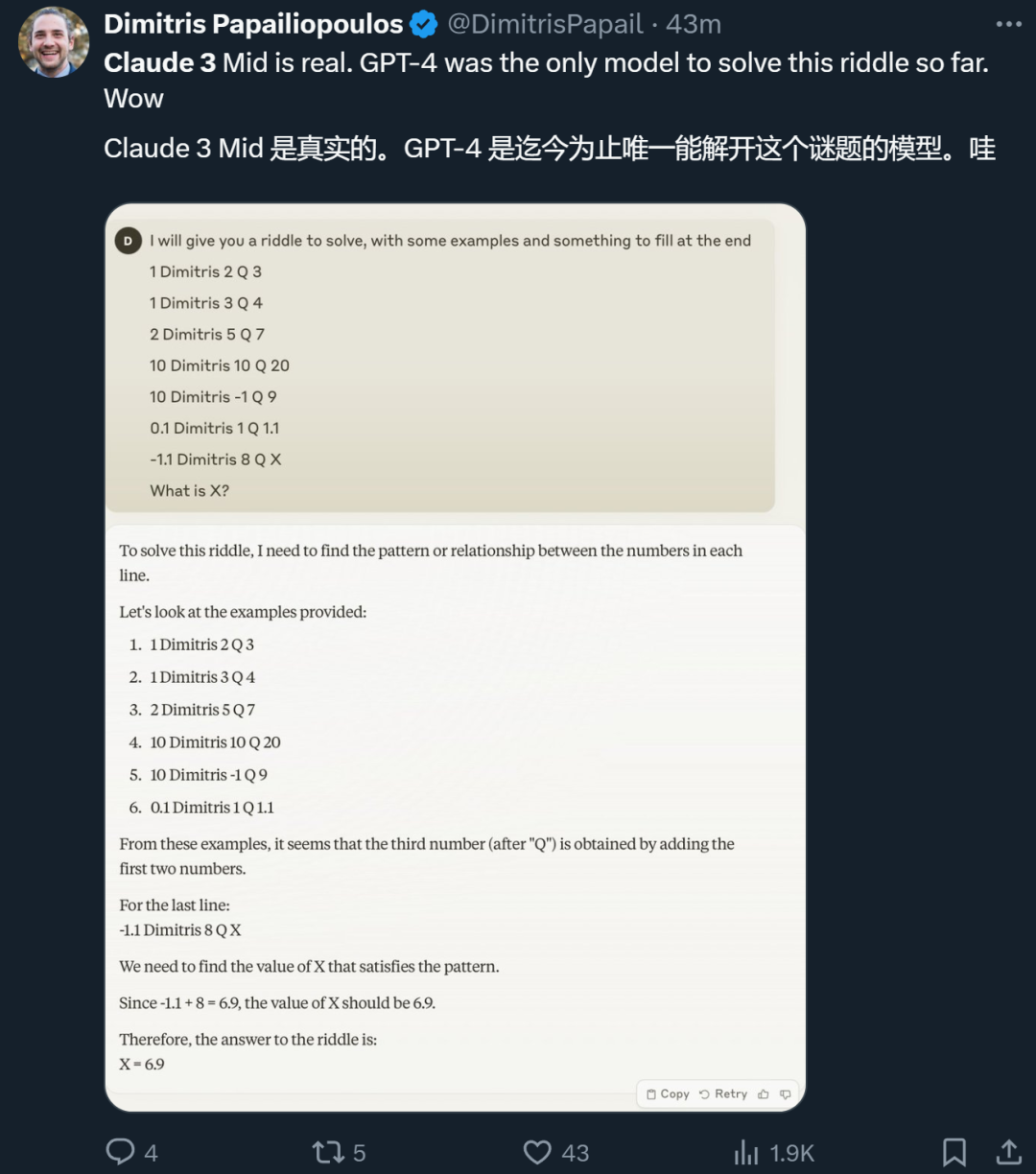
그러나 일부 사람들은 실제 경험으로 볼 때 클로드 3가 GPT-4를 완전히 이기지 못했다고 말했습니다.
클로드 3의 직접 실제 테스트
주소: https://claude.ai/
클로드 3는 정말 공식적으로 주장된 대로 GPT를 능가하는 성능을 발휘하나요? -4? 현재 대부분의 사람들은 그것이 어떤 의미를 갖고 있다고 생각합니다.
다음은 실제 테스트 결과 중 일부입니다.
먼저, 어느 달에 28일이 있는지 알아볼까요? 실제 정답은 매달 입니다. 클로드 3은 아직 이런 질문을 잘 못하는 것 같습니다.
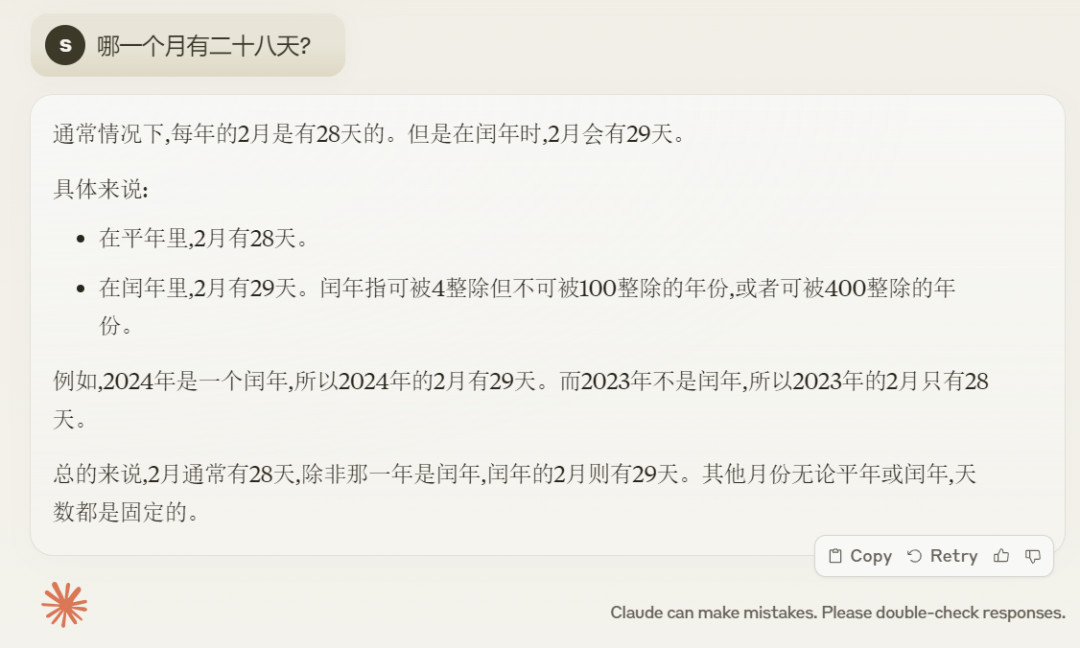
그럼 클로드 3가 잘하는 분야를 테스트해봤습니다. 공식 소개를 보면 이미지에서 텍스트를 추출하고, UI를 전면으로 변환하는 등 "이미지를 이해하고 처리하는 것"에 능숙하다는 걸 알 수 있어요. 최종 코드, 복잡한 방정식 이해, 손으로 쓴 메모 복사 등이 있습니다.
큰 모델의 경우 프라이드치킨과 테디를 구별하기 어려운 경우가 많습니다. 테디와 프라이드치킨이 포함된 사진을 입력하면 클로드3가 "이 사진은 강아지와 치킨이 포함된 콜라주 세트입니다."라고 답했습니다. 개 자체와 매우 유사한 너겟 또는 너겟...” 이 질문은 통과되었습니다.
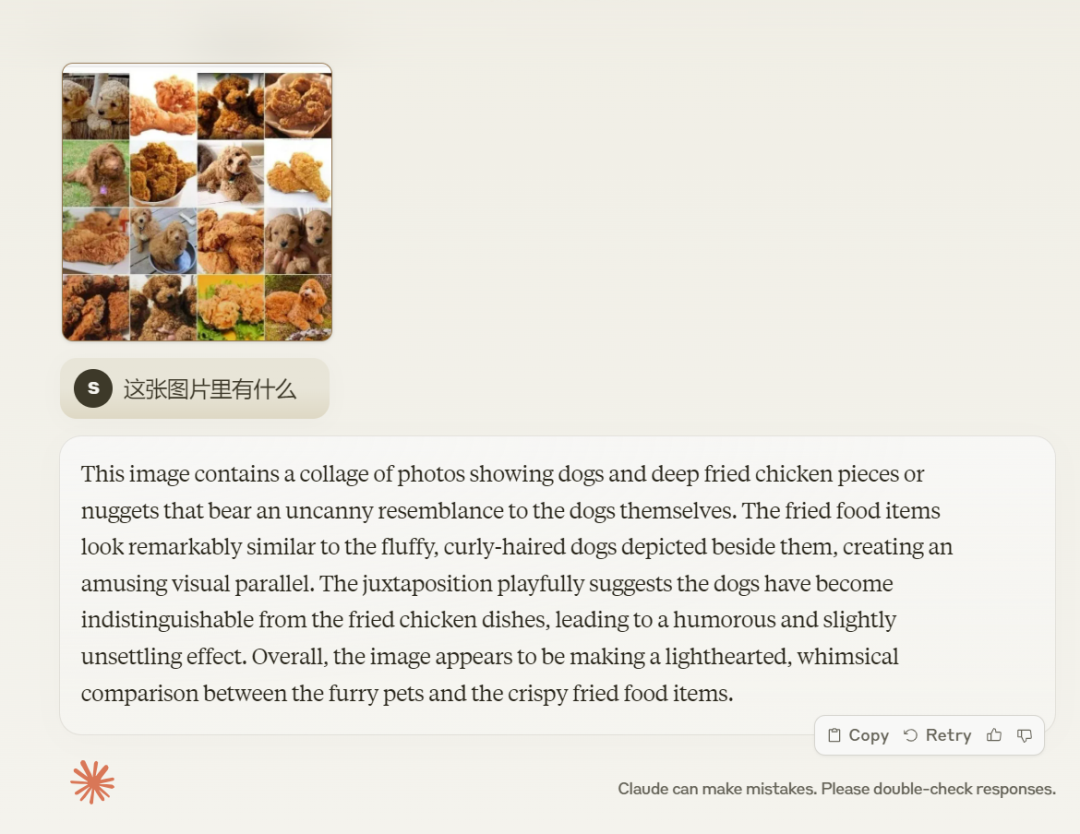
그리고 거기에 몇 명이 있었는지 묻자 클로드 3도 "이 애니메이션은 7명의 작은 만화 캐릭터를 묘사하고 있습니다."라고 정확하게 대답했습니다.
Claude 3는 사진에서 텍스트를 추출할 수 있으며 중국어와 일본어의 세로 순서도 정확하게 인식할 수 있습니다.

인터넷에서 밈을 사용하면 어떻게 처리되나요? 시각적 오류 사진에 대해 GPT-4와 Claude3는 서로 반대 추측을 했습니다.
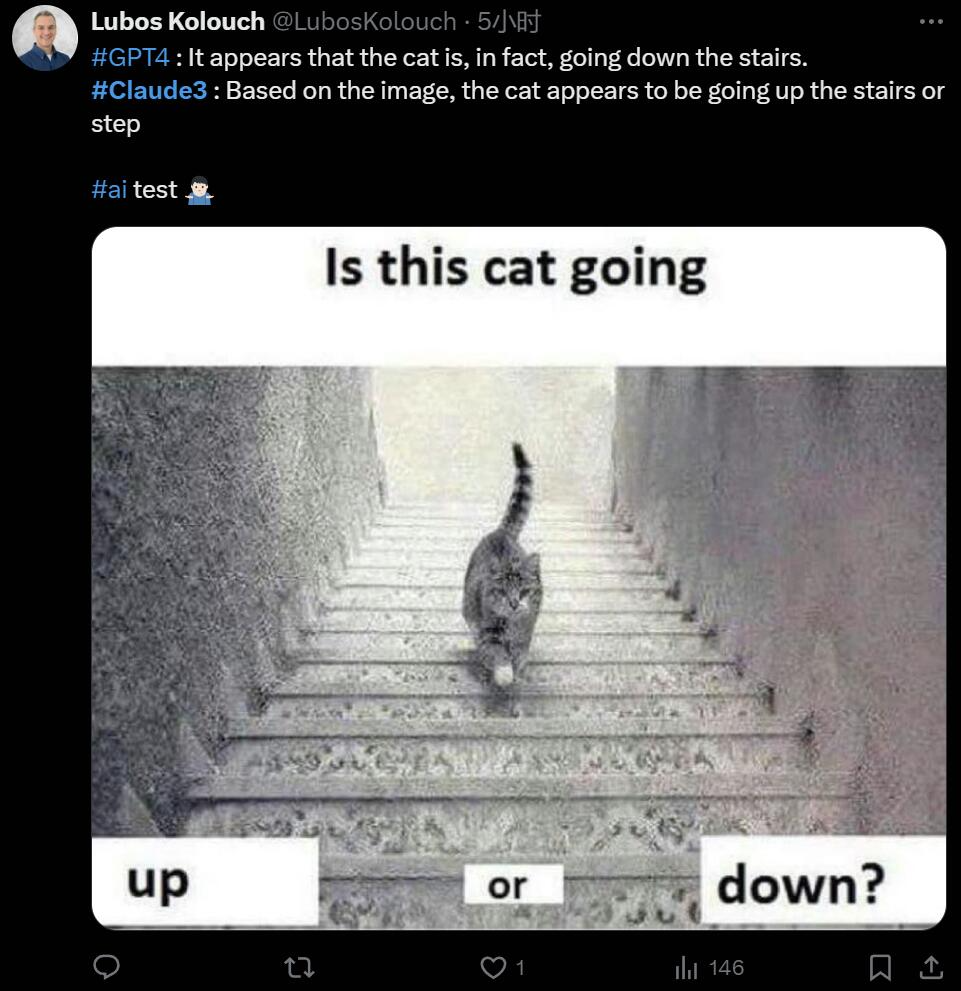
어느 것이 맞나요?
Claude는 이미지 이해 외에도 긴 텍스트 처리도 가능합니다. 이번에 출시된 전체 대형 모델 시리즈는 200k 컨텍스트 창을 제공하고 100만 개 이상의 토큰 입력을 수용할 수 있습니다.
효과는 어때요? 마이크로소프트와 국립과학기술대학교가 최근 발표한 논문 "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits"를 주고, 기사의 요점을 다음과 같은 형식으로 요약해 달라고 요청했습니다. 1, 2, 3의 1번을 기록했습니다. 시간, 전체 답을 출력하는 데 걸리는 시간은 약 15초입니다.
이것은 Claude 3 Sonnet의 출력효과일 뿐입니다. Claude Pro 버전을 사용하시면 속도는 더 빨라지지만 월 20달러의 비용이 듭니다.
Claude는 이제 업로드된 기사의 크기가 10MB를 초과하지 않도록 요구한다는 점에 주목할 가치가 있습니다.

Claude 3의 블로그 Anthropic 새 모델의 코딩 기능이 대폭 향상되었다고 제안했는데, 누군가 Claude에게 직접 기본 ASCII 코드를 던졌더니 부담감이 없다는 것을 알게 되었습니다.
Claude 3의 코딩 기능이 더 강력하다는 것을 확인할 수 있어야 합니다. GPT-4보다.
얼마 전 OpenAI에서 퇴사한 Karpathy가 '워드 세그먼터' 챌린지를 제안했습니다. 구체적으로 그는 2시간 13분짜리 튜토리얼 비디오를 LLM에 넣고 토크나이저에 관한 책 장이나 블로그 게시물 형식으로 번역했습니다.
이 작업에 직면하여 Claude 3가 이를 수행했습니다. 다음은 AnthropicAI 연구 엔지니어 Emmanuel Ameisen이 게시한 결과입니다. 카르파티 비교적 완전하고 객관적인 평가를 주셨습니다:
 스타일 측면에서 보면 정말 괜찮은 것 같아요! 자세히 살펴보면 몇 가지 미묘한 문제/환상을 발견할 수 있습니다. 그럼에도 불구하고 거의 즉시 작동하는 시스템을 보유하고 있다는 것은 인상적입니다. 클로드 3로 더 많은 플레이를 기대하고 있는데, 강력한 모델인 것 같습니다.
스타일 측면에서 보면 정말 괜찮은 것 같아요! 자세히 살펴보면 몇 가지 미묘한 문제/환상을 발견할 수 있습니다. 그럼에도 불구하고 거의 즉시 작동하는 시스템을 보유하고 있다는 것은 인상적입니다. 클로드 3로 더 많은 플레이를 기대하고 있는데, 강력한 모델인 것 같습니다.
관련이 있는 것이 있다면 사람들은 평가 비교를 할 때 매우 조심해야 한다는 것입니다. 평가 결과 자체가 생각보다 나쁠 뿐만 아니라 많은 평가 결과가 과적합되기 때문입니다. 정의되지 않은 방식이며 비교가 오해의 소지가 있을 수 있기 때문입니다. GPT-4의 인코딩 비율(HumanEval)은 67%가 아닙니다. 코딩 성능 대신 이 비교가 사용되는 것을 볼 때마다 눈꼬리가 꿈틀거리기 시작합니다. 
위의 다양한 까다로운 테스트 결과를 바탕으로 이미 "인류가 돌아왔다"라고 외치는 분들도 계십니다.
마지막으로 Anthropopic은 여러 방향의 프롬프트 콘텐츠를 포함하는 프롬프트 라이브러리도 출시했습니다. Claude 3의 새로운 기능에 대해 더 자세히 알아보고 싶다면 한번 사용해 보세요.
링크: https://docs.anthropic.com/claude/prompt-library
Claude 3 시리즈 모델
Claude 3 시리즈 모델의 세 가지 버전은 Claude 3 Opus, Claude 3 Sonnet 및 Claude입니다. 3 하이쿠.
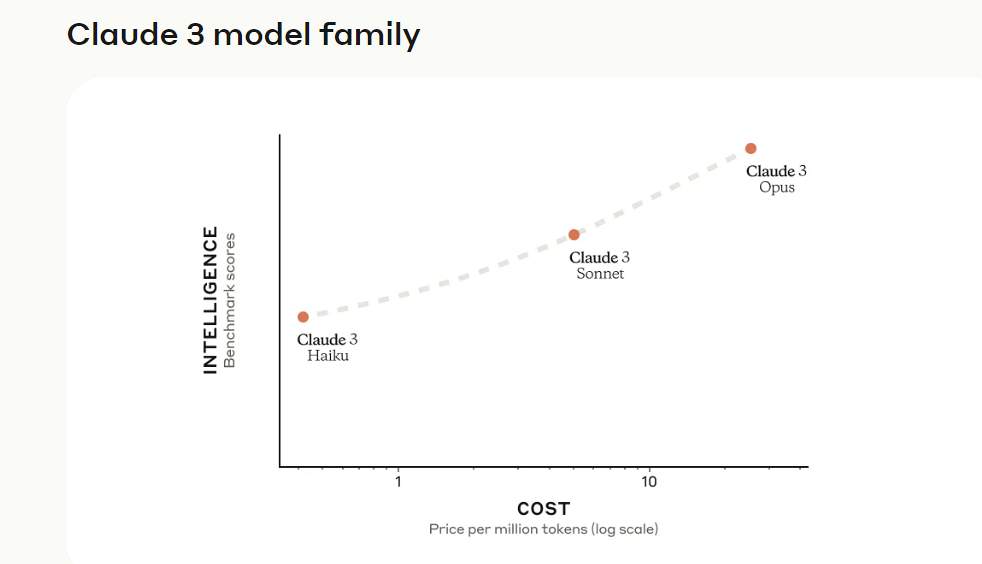
그 중에서 Claude 3 Opus는 200,000개의 토큰 컨텍스트 창을 지원하고 매우 복잡한 작업에서 현재 SOTA 성능을 달성하는 가장 지능적인 모델입니다. 이 모델은 탁월한 유창함과 인간 수준의 이해를 바탕으로 개방형 프롬프트와 보이지 않는 장면을 처리합니다. Claude 3 Opus는 생성 AI로 가능한 것의 한계를 보여줍니다.

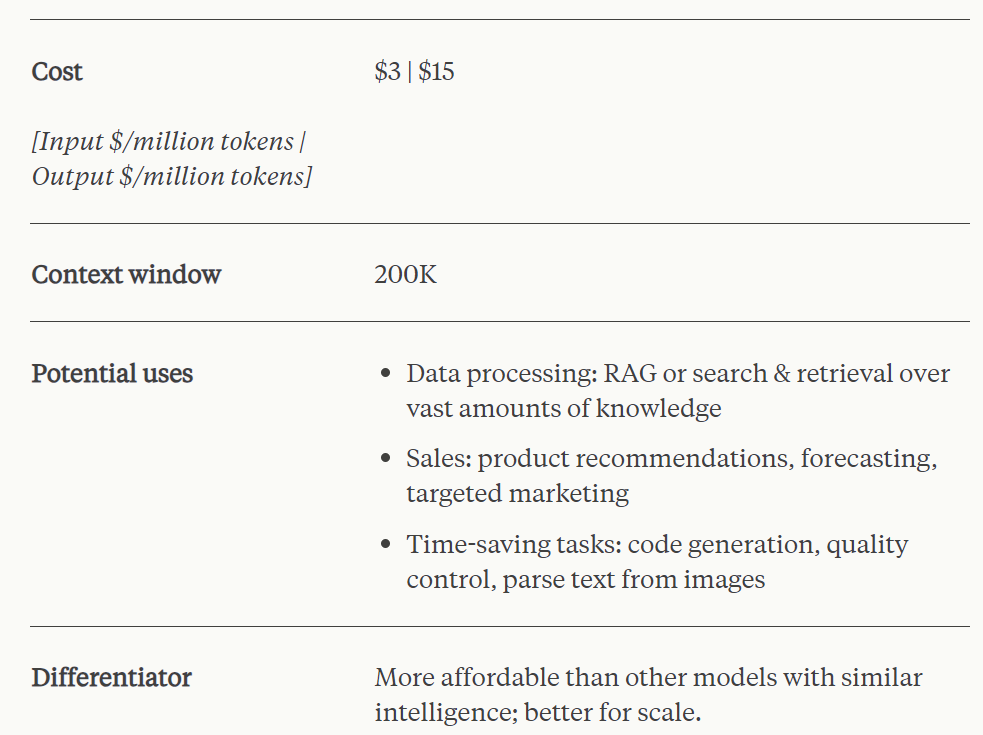
Claude 3 Sonnet은 특히 기업 작업 부하에 지능과 속도 사이의 이상적인 균형을 제공합니다. 유사한 모델보다 저렴한 비용으로 강력한 성능을 제공하며 대규모 AI 배포에서 높은 내구성을 제공하도록 설계되었습니다. Claude 3 Sonnet은 200,000개 토큰의 컨텍스트 창을 지원합니다.
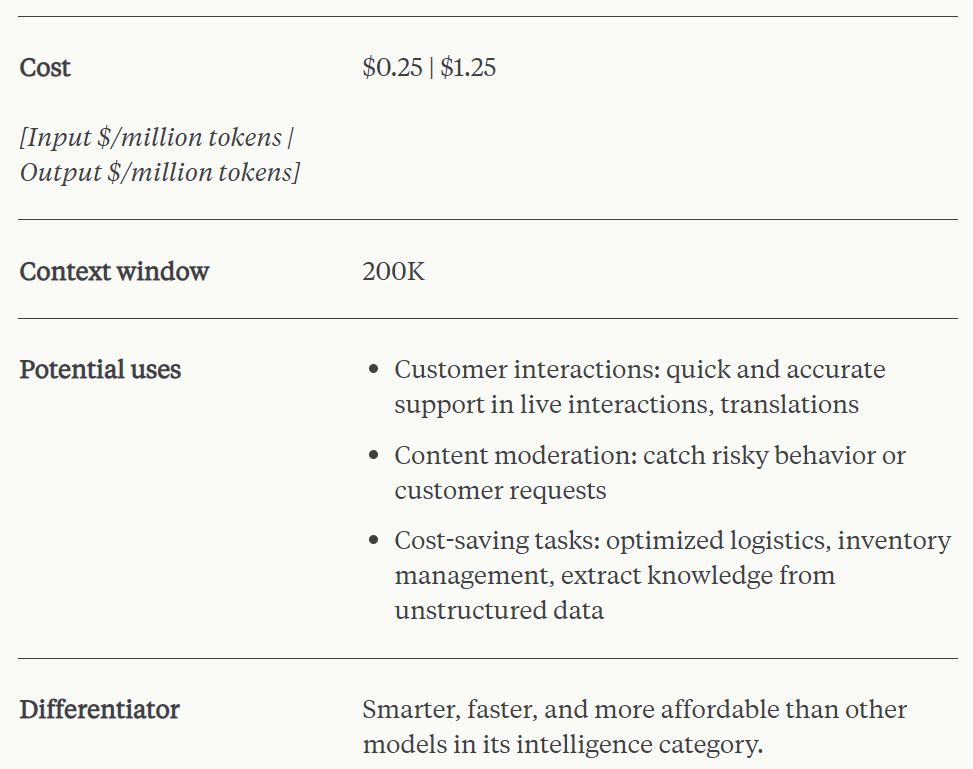
Claude 3 Haiku는 실시간에 가까운 반응성을 갖춘 가장 빠르고 컴팩트한 모델입니다. 흥미롭게도 지원하는 컨텍스트 창도 200k입니다. 이 모델은 비교할 수 없는 속도로 간단한 쿼리와 요청에 응답할 수 있으므로 사용자는 인간 상호 작용을 모방하는 원활한 AI 경험을 구축할 수 있습니다.
다음으로 클로드 3 시리즈 모델의 특징과 성능을 자세히 살펴보겠습니다.
GPT-4를 완전히 능가하고 새로운 SOTA 수준의 지능 달성
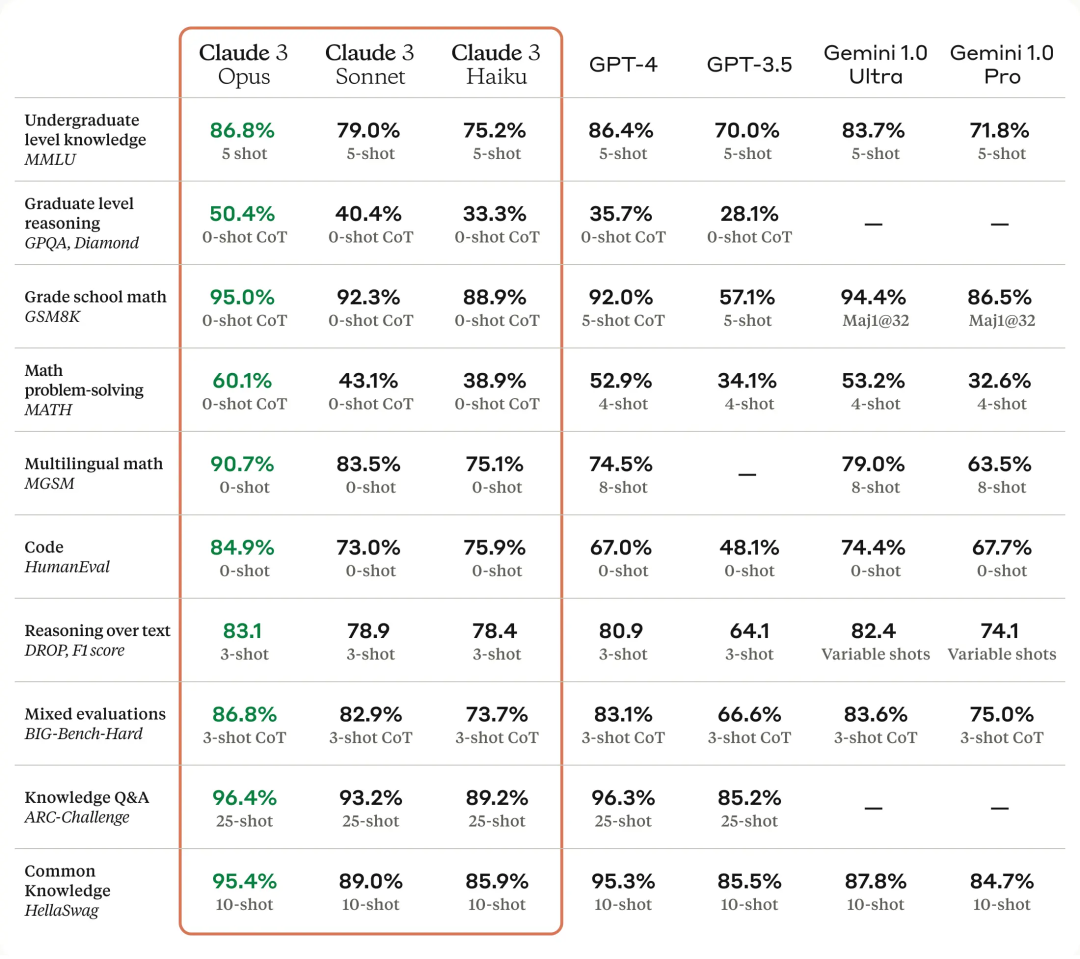
Claude 3 시리즈 중 가장 지능적인 모델인 Opus는 학부 수준 전문가를 포함한 대부분의 AI 시스템 평가 벤치마크에서 경쟁 제품보다 우수한 성능을 발휘합니다. (MMLU), 대학원 수준 전문가 추론(GPQA), 기초 수학(GSM8K) 및 기타 벤치마크. 또한 Opus는 복잡한 작업에 대해 인간 수준에 가까운 이해력과 유창함을 보여 일반 지능의 선두를 달리고 있습니다.
또한 Opus를 포함한 모든 Claude 3 시리즈 모델은 분석 및 예측, 세분화된 콘텐츠 생성, 코드 생성, 스페인어, 일본어, 프랑스어와 같은 영어 이외의 언어로 대화하는 기능이 향상되었습니다.
아래 그림은 여러 성능 벤치마크에서 Claude 3 모델과 경쟁 모델을 비교한 것입니다. OpenAI의 GPT-4보다 가장 강력한 Opus가 더 낫다는 것을 알 수 있습니다.
거의 실시간 응답
Claude 3 모델은 응답이 즉각적이고 실시간이어야 하는 실시간 고객 채팅, 자동 보충 및 데이터 추출과 같은 작업을 지원할 수 있습니다.
Haiku는 스마트 카테고리 시장에서 가장 빠르고 비용 효율적인 모델입니다. 조밀한 다이어그램과 그래픽 정보가 포함된 arXiv 플랫폼 문서(~10,000개 토큰)를 3초 이내에 읽을 수 있습니다.
대부분의 작업에서 Sonnet은 Claude 2 및 Claude 2.1보다 2배 더 빠르고 지능적입니다. 지식 검색이나 영업 자동화 등 빠른 응답이 필요한 작업에 탁월합니다. Opus는 Claude 2 및 2.1과 속도가 비슷하지만 지능 수준이 더 높습니다.
강력한 시각적 기능
Claude 3는 다른 헤드 모델과 비교할 수 없을 정도로 정교한 시각적 기능을 갖추고 있습니다. 사진, 차트, 그래프, 기술 다이어그램을 비롯한 다양한 시각적 형식의 데이터를 처리할 수 있습니다.
Anthropic에 따르면 일부 고객은 지식 기반의 50% 이상이 PDF, 순서도, 프레젠테이션 슬라이드 등 다양한 데이터 형식으로 프로그래밍되어 있다고 합니다. 따라서 새 모델의 강력한 시각적 기능은 매우 유용합니다.
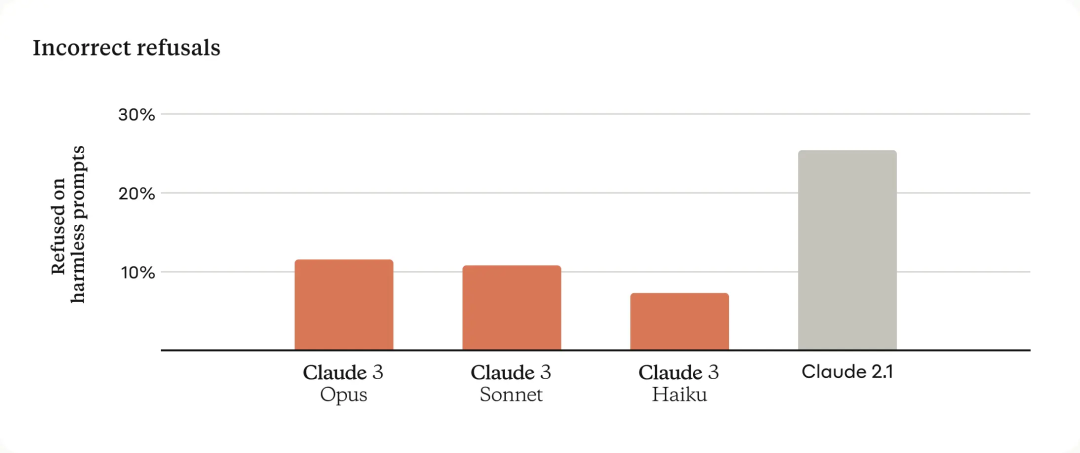
거부 답변 감소
이전 클로드 모델은 불필요한 거부를 하는 경우가 많아 모델의 맥락적 이해가 부족함을 나타냅니다. Anthropic은 이 분야에서 의미 있는 진전을 이루었습니다. Opus, Sonnet 및 Haiku는 사용자 프롬프트가 시스템의 수익에 가까운 경우에도 이전 세대 모델보다 답변을 거부할 가능성이 훨씬 적습니다. 아래에 표시된 것처럼 Claude 3 모델은 요청에 대한 보다 미묘한 이해를 보여주고, 실제로 유해한 프롬프트를 식별할 수 있으며, 무해한 프롬프트에 대한 응답을 훨씬 덜 자주 거부합니다.
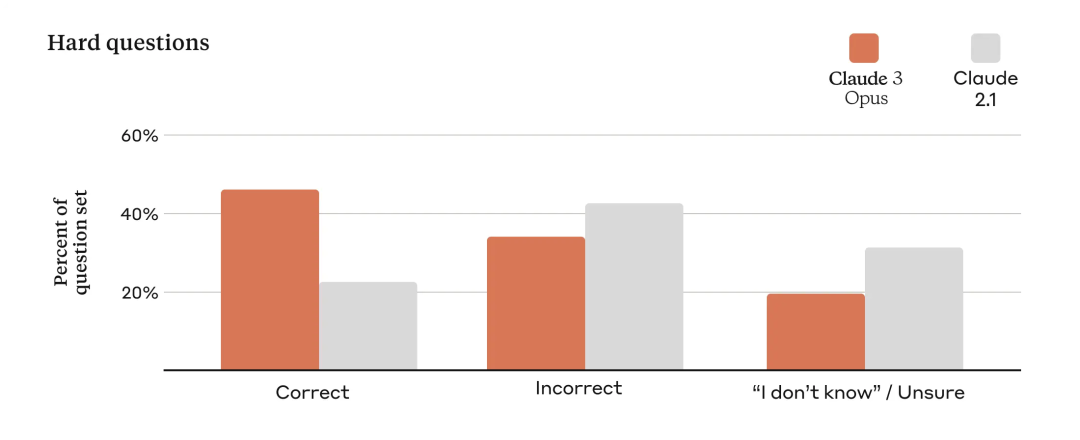
정확도 향상
모델 정확성을 평가하기 위해 Anthropic은 여러 가지 복잡한 사실 기반 질문을 사용하여 현재 모델의 알려진 약점을 해결했습니다. Anthropic은 정답, 오답(또는 환각), 불확실한 답변으로 분류하는데, 여기서 모델은 잘못된 정보를 제공하는 것이 아니라 답을 알 수 있습니다. Claude 2.1과 비교하여 Opus는 이러한 도전적인 개방형 질문에 대한 정확도(또는 정답)를 두 배로 높이는 동시에 오답을 줄였습니다.
더 신뢰할 수 있는 응답을 생성하는 것 외에도 Anthropic은 Claude 3 모델에서 인용을 활성화하여 모델이 참조 자료의 정확한 문장을 가리켜 응답을 입증할 수 있도록 합니다.
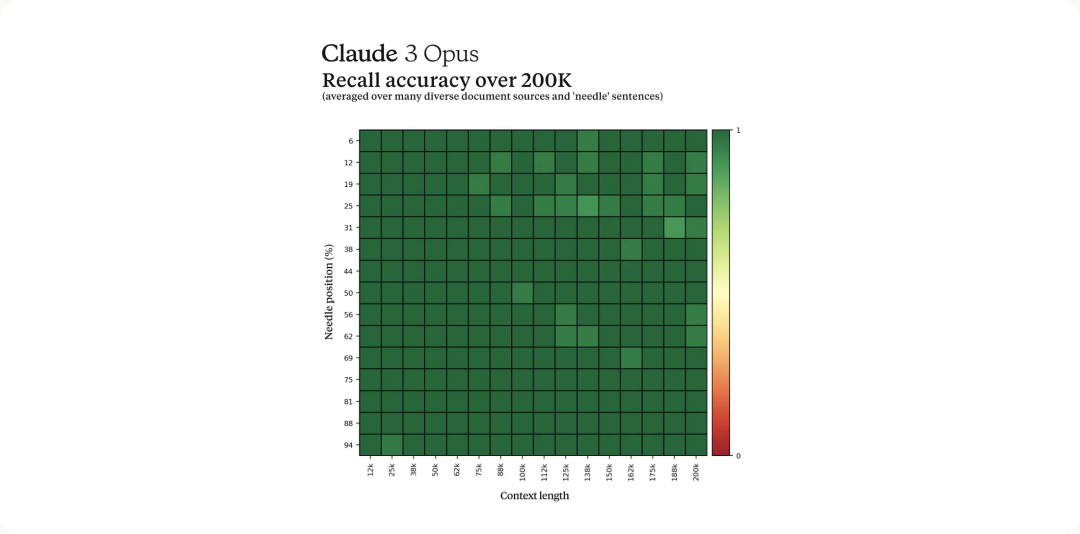
긴 컨텍스트 및 거의 완벽한 재현율
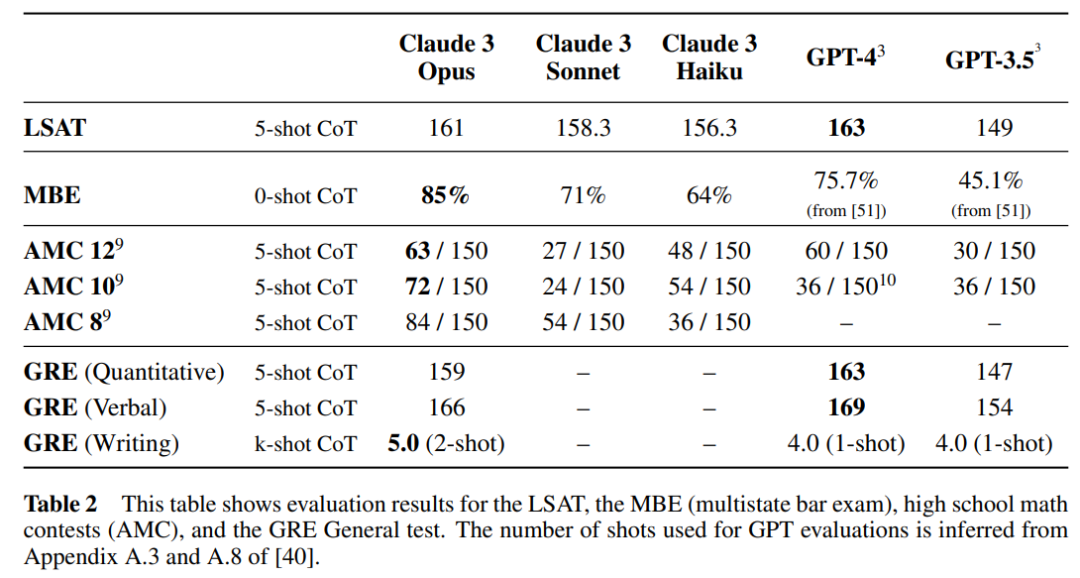
Claude 3 시리즈 모델은 출시 시 처음에 200K 컨텍스트 창을 제공합니다. 그러나 관계자들은 세 가지 모델 모두 100만 개 이상의 토큰을 입력받을 수 있으며, 이 기능은 향상된 처리 기능이 필요한 특정 사용자에게 제공될 것이라고 밝혔습니다.
긴 상황별 단서를 효과적으로 처리하려면 모델에 강력한 회상 기능이 필요합니다. NIAH(Needle In A Haystack) 평가는 대량의 데이터에서 정보를 정확하게 기억하는 모델의 능력을 측정합니다. Anthropic은 각 프롬프트에서 30개의 무작위 바늘/질문 쌍을 사용하여 다양한 크라우드소싱 문서 기반에서 테스트함으로써 이 벤치마크의 견고성을 강화했습니다. Claude 3 Opus는 거의 완벽에 가까운 재현율을 달성했을 뿐만 아니라 99% 이상의 정확도를 달성했습니다. 그리고 어떤 경우에는 '바늘' 문장이 원문에 인위적으로 삽입된 것처럼 보이는 등 평가 자체의 한계까지 확인했다.
안전하고 사용하기 쉬움
Anthropic은 보안 위험을 추적하고 줄이기 위해 전담 팀을 구성했다고 밝혔습니다. 또한 회사는 모델 보안과 투명성을 개선하고 새로운 모델에서 발생할 수 있는 개인 정보 보호 문제를 완화하기 위해 Constitutional AI와 같은 방법을 개발하고 있습니다.
Claude 3 모델 시리즈는 생물학적 지식, 네트워크 관련 지식, 자율성 등 주요 지표에서 이전 모델에 비해 진전을 보인 반면, 연구에 따르면 신형 모델은 AI 안전 레벨 2(ASL-2)에 해당합니다. .
사용자 경험 측면에서 Claude 3는 이전 모델보다 복잡한 다단계 지침을 더 잘 따르고, 브랜드 및 반응 지침을 더 잘 준수할 수 있어 신뢰할 수 있는 애플리케이션을 더 잘 개발할 수 있습니다. 또한 Anthropic은 Claude 3 모델이 이제 JSON과 같은 형식으로 널리 사용되는 구조화된 출력을 생성하는 데 더 뛰어나므로 자연어 분류 및 감정 분석과 같은 사용 사례에 대해 Claude를 더 쉽게 안내할 수 있다고 말합니다.
기술 보고서에 적힌 내용
현재 Anthropic은 42페이지 분량의 기술 보고서 "The Claude 3 Model Family: Opus, Sonnet, Haiku"를 발표했습니다.

신고 주소: https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
Claude 3 시리즈 모델 트레이닝 데이터를 보았는데, 평가 기준 및 보다 자세한 실험 결과 .
훈련 데이터 측면에서 Claude 3 시리즈 모델은 2023년 8월 현재 인터넷에 공개된 독점적인 데이터 조합과 제3자의 비공개 데이터, 데이터 라벨링 서비스 제공업체가 제공하는 데이터를 사용하여 훈련되었습니다. 및 유료 계약자, Claude의 내부 데이터.
Claude 3 시리즈 모델은 다음을 포함한 다양한 지표를 통해 광범위하게 평가되었습니다.
语추론 능력 言 다국어 능력- 긴 맥락
- 신뢰성/사실의 빈도
- 다중 모드 능력
- 우선 추론, 프로그래밍, 질의응답에 있어서 과제 평가 결과, Claude 3 시리즈 모델은 추론, 독해, 수학, 과학, 프로그래밍 분야의 일련의 업계 표준 벤치마크에서 경쟁 모델과 비교되었습니다. 그 결과, 이전 모델을 능가했을 뿐만 아니라, 그러나 대부분의 경우 New SOTA를 달성했습니다. ... 결과는 하기 표 2와 같다.
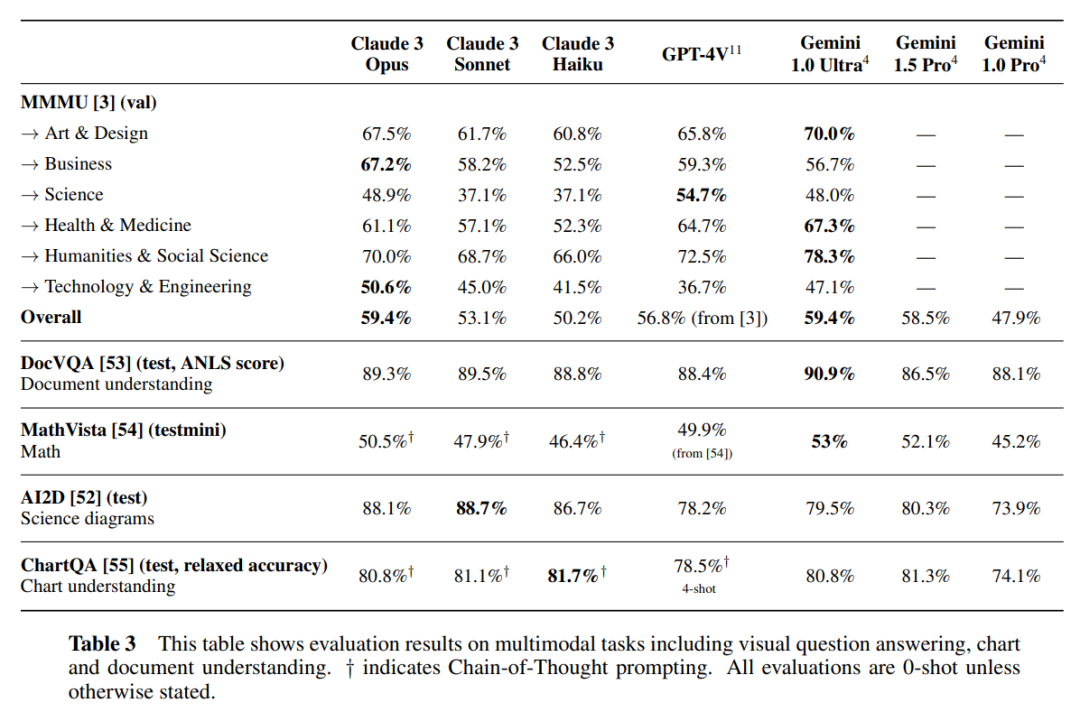
Claude 3 시리즈 모델은 다중 모드(이미지 및 비디오 프레임 입력)가 가능하며 단순한 텍스트 이해를 넘어 복잡한 다중 모드 추론 문제를 해결하는 데 상당한 진전을 이루었습니다.
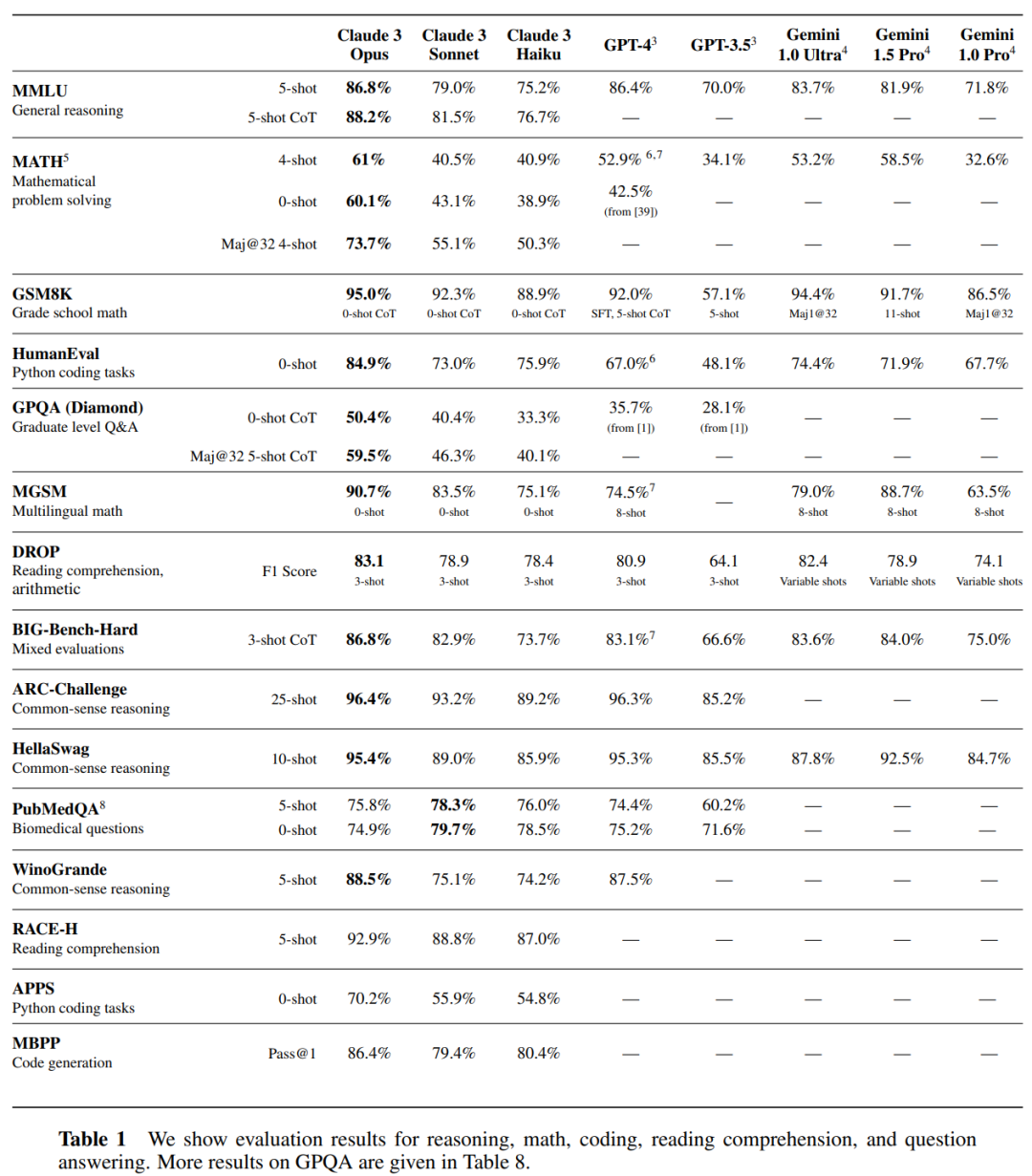 차트 구문 분석 및 객관식 형식의 해당 질문에 대한 답변을 포함하는 시각적 질문 답변 평가인 AI2D Scientific Charts 벤치마크에서 Claude 3 모델의 성능이 좋은 사례입니다.
차트 구문 분석 및 객관식 형식의 해당 질문에 대한 답변을 포함하는 시각적 질문 답변 평가인 AI2D Scientific Charts 벤치마크에서 Claude 3 모델의 성능이 좋은 사례입니다.
Claude 3 Sonnet은 0샷 설정에서 89.2%로 SOTA 수준에 도달했으며, Claude 3 Opus(88.3%), Claude 3 Haiku(80.6%)가 그 뒤를 이었습니다. 구체적인 결과는 아래 표 3에 나와 있습니다.
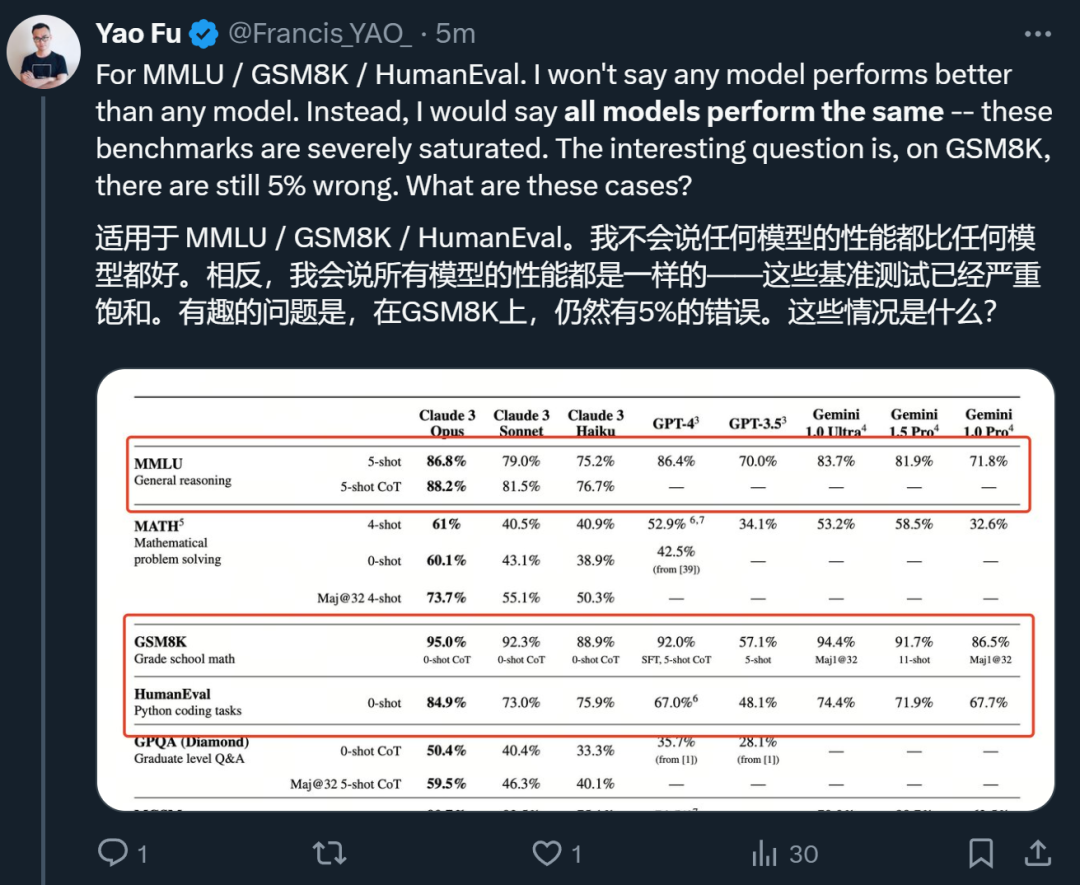
이 기술 보고서에 대해 에든버러 대학의 박사 과정 학생인 Fu Yao가 즉시 자신의 분석을 내놓았습니다.
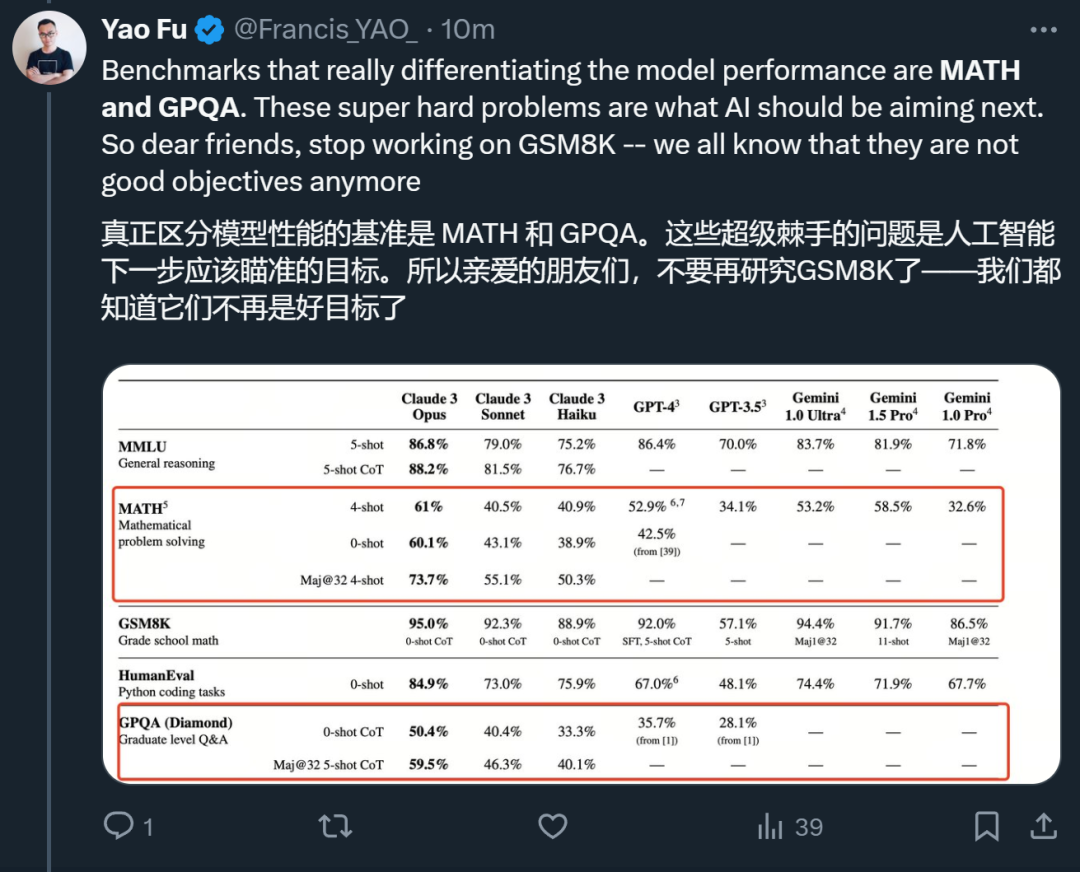
우선, 평가된 여러 모델은 기본적으로 MMLU / GSM8K / HumanEval과 같은 여러 지표에서 구별이 없다고 생각합니다. 실제로 걱정해야 할 것은 최고의 모델이 여전히 GSM8K 오류에 5%를 가지고 있다는 것입니다. .
 그는 모델을 실제로 구별할 수 있는 것은 MATH와 GPQA라고 믿습니다. 이러한 매우 까다로운 문제는 AI 모델이 다음으로 목표로 삼아야 할 목표입니다.
그는 모델을 실제로 구별할 수 있는 것은 MATH와 GPQA라고 믿습니다. 이러한 매우 까다로운 문제는 AI 모델이 다음으로 목표로 삼아야 할 목표입니다.
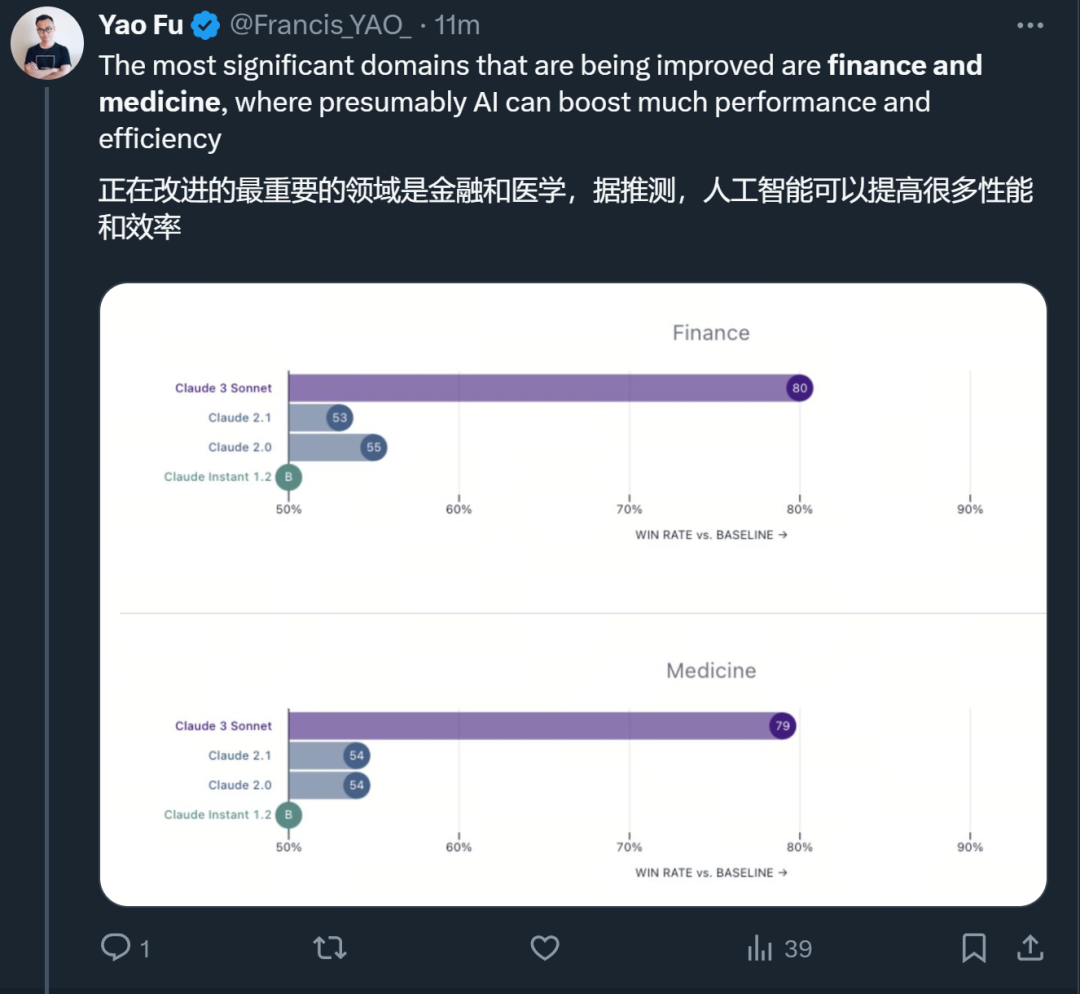
클로드의 이전 모델과 비교하여 더 크게 개선된 분야는 금융과 의료입니다.
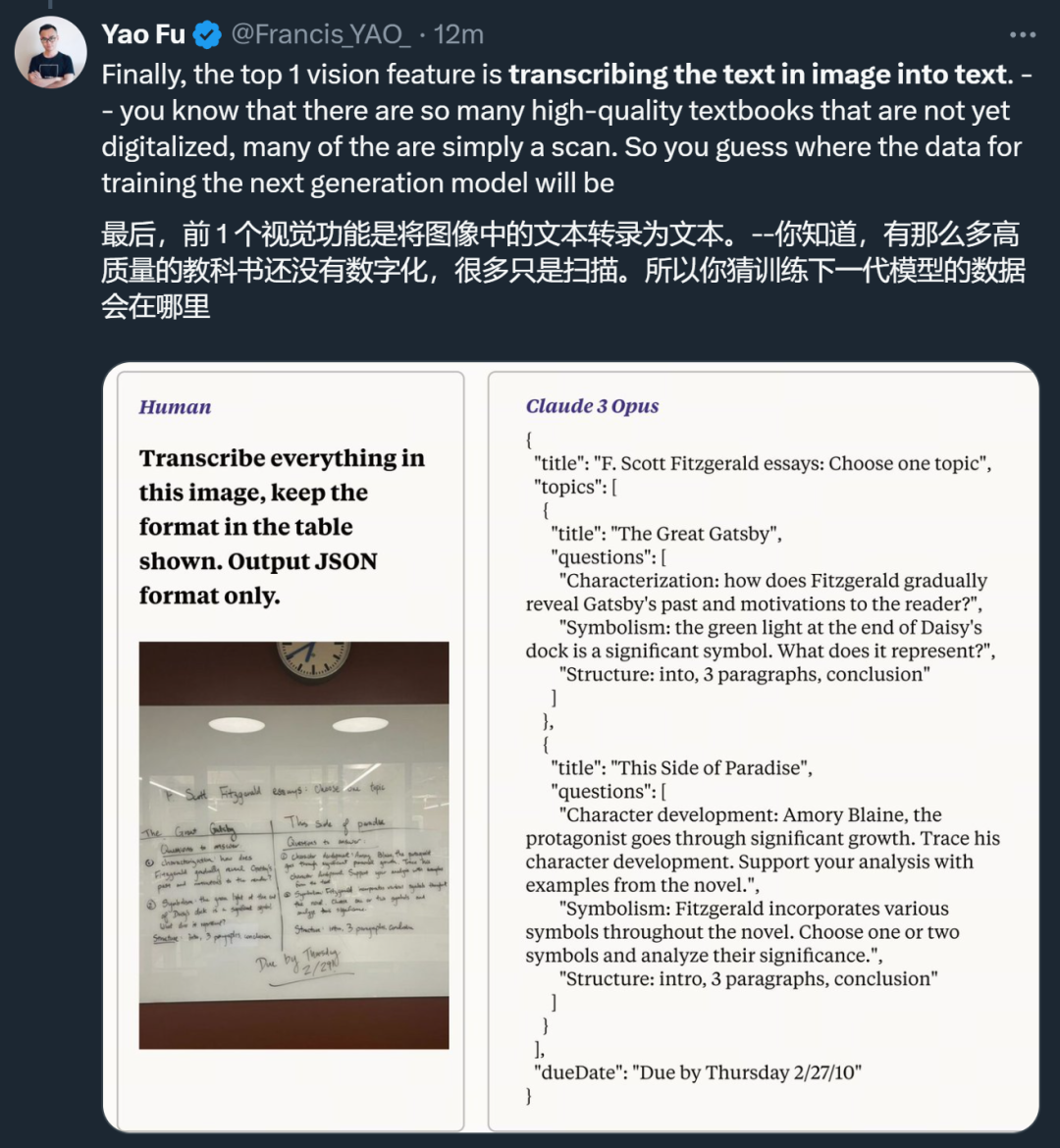
시력 측면에서 Claude 3의 시각적 OCR 기능은 사람들에게 데이터 수집의 엄청난 잠재력을 보여줍니다.
그는 또한 다음과 같은 몇 가지 다른 트렌드도 발견했습니다.
현재 평가 벤치마크와 경험에 따르면 Claude 3는 스마트하고 다양한 모드를 지원합니다. 성능과 속도 모두에서 만들어졌습니다. 새로운 모델 시리즈를 더욱 최적화하고 적용하면 더욱 다양한 대형 모델 생태계를 볼 수 있습니다.
블로그 주소: https://www.anthropic.com/news/claude-3-family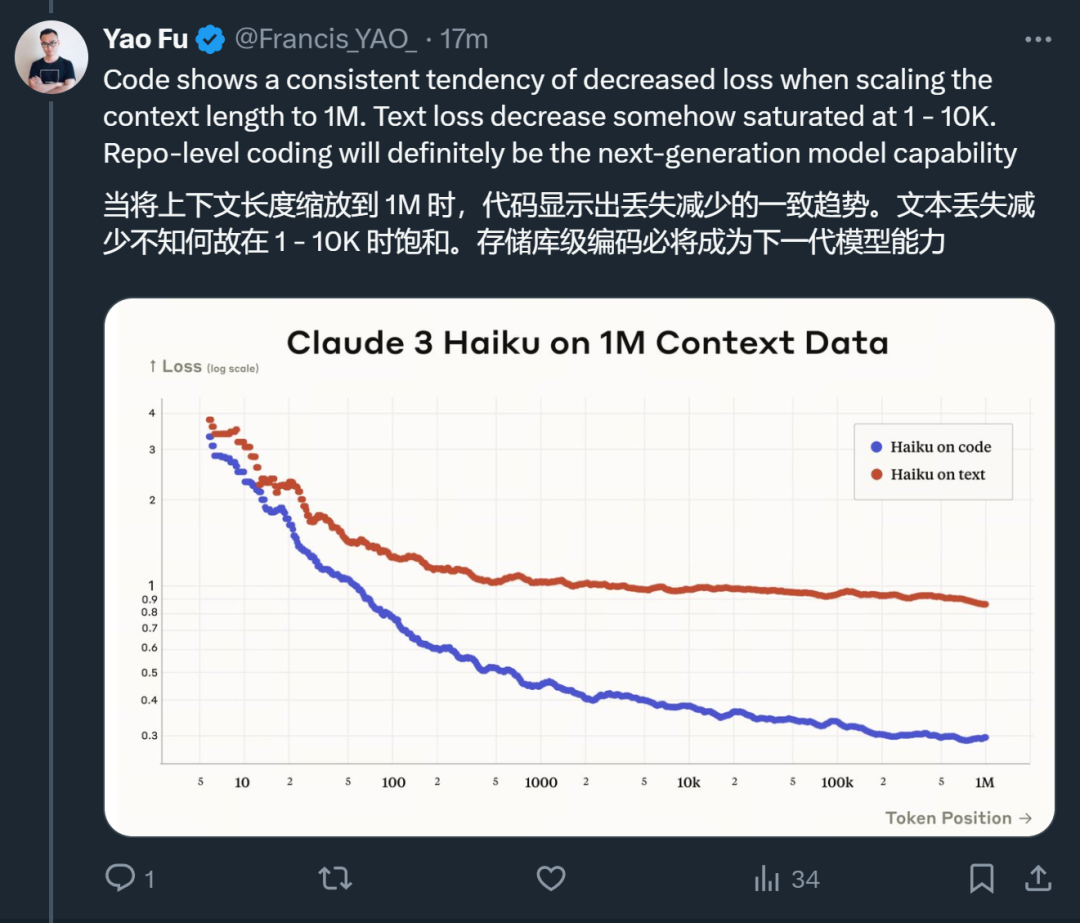
위 내용은 GPT-4 시대는 끝났는가? 전 세계 네티즌들이 클로드3를 테스트하고 충격에 빠졌다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!