모나리자가 하품을 하고, 닭이 다리미 드는 법을 배우고... Google VideoPoet의 대형 모델의 성능이 매우 뛰어납니다.
2023년 말, 기술 회사들은 생성 AI의 마지막 단계인 비디오 생성에 영향을 미치고 있습니다. 화요일, 구글이 제안한 대형 동영상 생성 모델이 출시되자마자 사람들의 관심을 끌었습니다. VideoPoet이라고 불리는 이 대규모 언어 모델은 혁신적인 제로샷 비디오 생성 도구로 간주됩니다. VideoPoet은 텍스트와 이미지로 비디오를 생성할 수 있을 뿐만 아니라 스타일을 전송하고 비디오를 음성으로 변환할 수도 있습니다. 실제로 다양하고 부드러운 움직임을 구축할 수 있습니다. 
소식이 나오자마자 많은 분들이 환영해 주셨어요. 현재 몇 안 되는 완성품이 좋은 결과를 내고 있는 걸 보면, 대형 모델 기술의 발전 속도가 너무 빠르거든요.
누군가 이 대형 모델이 생성한 영상의 길이에 놀라움을 표시했습니다.
또한 어떤 사람들은 이것이 혁명적인 대규모 언어 모델이라고 말합니다.
어떤 사람들은 Google에 가능한 한 빨리 VideoPoet 소스를 오픈하라고 요청했습니다.
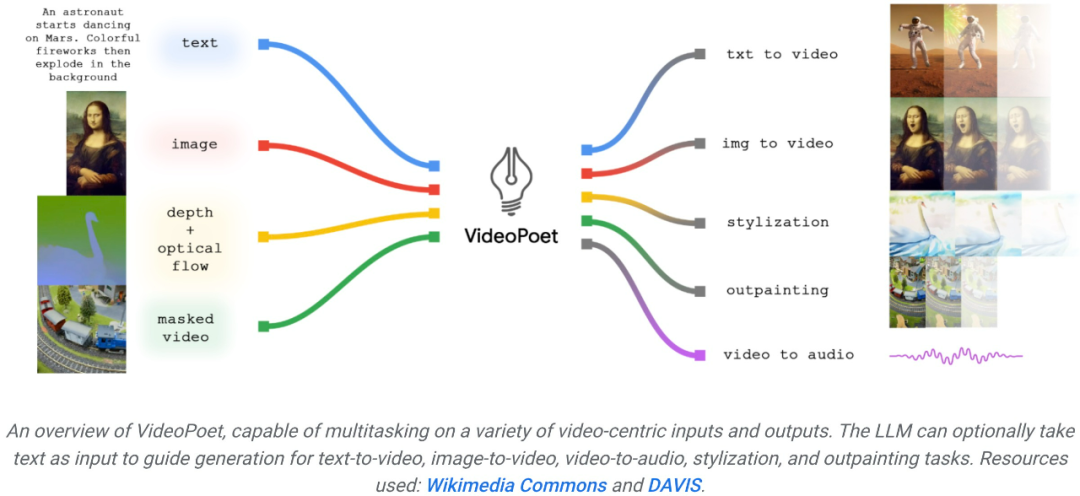
생성 AI의 발전과 함께 최근 놀라운 화질을 보여주는 새로운 비디오 세대 모델이 속속 등장하고 있습니다. 현재 비디오 생성의 병목 현상 중 하나는 일관된 대규모 움직임을 생성하는 것입니다. 그러나 대부분의 경우 선두 모델이라도 더 작은 모션만 생성할 수 있거나 더 큰 모션을 생성할 때 눈에 띄는 아티팩트가 나타날 수 있습니다. 비디오 생성에서 언어 모델의 적용을 탐색하기 위해 Google 연구원은 텍스트 대 비디오, 이미지 대 비디오, 비디오 스타일화 등 다양한 비디오 생성 작업을 수행할 수 있는 LLM(대형 언어 모델) VideoPoet을 도입했습니다. , 비디오 복구 및 확장, 비디오를 오디오로 변환.
VideoPoet 효과 표시
텍스트 생성 비디오
팁: 개는 헤드폰, 풍부한 디테일, 8k로 음악을 듣고 있습니다. 팁(왼쪽에서 오른쪽으로): 비오는 날 5번가에서 손을 잡고 걸어가는 곰 인형, 입에서 레이저 빔을 쏘는 상어, 다리미를 들어올리는 닭.
팁(왼쪽에서 오른쪽으로): 노란 민들레 꽃잎으로 만든 포효하는 사자, 반 고흐의 별이 빛나는 밤을 질주하는 말, 거위를 타고 있는 다람쥐; 셀카.
비디오 생성을 위한 이미지
이미지를 비디오로 변환하기 위해 VideoPoet은 입력 이미지를 가져와 프롬프트로 애니메이션화할 수 있습니다.
모나리자의 하품을 시작하려면 사진과 프롬프트를 입력하세요. 여자가 하품합니다. 다음과 같은 효과를 얻게 됩니다. 팁(왼쪽에서 오른쪽으로): 천둥과 번개가 치는 거친 바다를 항해하는 배, 반짝이는 별들이 많은 성운 위로 날아가는 배, 바람이 부는 날 절벽에 서서 바다를 바라보는 방랑자 그 아래에 떠 있는 운해.
VideoPoet은 텍스트 프롬프트를 기반으로 입력 비디오의 스타일을 지정할 수도 있습니다. 팁(왼쪽에서 오른쪽으로): 테디베어는 깨끗한 얼음 호수에서 스케이트를 타고, 금속 사자는 화로의 불빛 속에서 포효합니다.
VideoPoet은 오디오도 생성할 수 있습니다. 먼저 모델이 2초 길이의 클립을 생성하도록 한 다음 텍스트 안내 없이 장면의 오디오를 예측해 보세요. 이러한 방식으로 VideoPoet은 단일 모델에서 비디오와 오디오를 생성할 수 있습니다. VideoPoet은 긴 비디오도 생성할 수 있으며 기본값은 2초입니다. 이 과정을 무한히 반복하면 영상의 마지막 1초를 조정하고 다음 1초를 예측하여 원하는 길이의 영상을 생성할 수 있습니다. 다음은 텍스트 입력에서 긴 비디오를 생성하는 VideoPoet의 데모 예시입니다. 팁: FPV 영상은 밝고 푸른 강, 폭포, 크고 가파른 수직 절벽이 있는 정글 속의 매우 선명한 Elfstone 도시를 보여줍니다.
사용자는 프롬프트를 변경하여 비디오를 확장할 수 있습니다. 소나무로 둘러싸인 산길을 오토바이를 타고 달리는 너구리 두 마리의 원본 영상, 8k. 확대된 영상에는 너구리 두 마리가 오토바이를 타고 있는 모습이 담겨 있는데, 너구리 뒤로 유성이 떨어지고, 유성이 지구에 부딪혀 폭발하는 모습이 담겨 있다.
제공된 입력 비디오(왼쪽 끝)의 경우 사용자는 개체의 움직임을 변경하여 다양한 작업을 수행할 수 있습니다. 아래에 표시된 것처럼 가운데 3개에는 텍스트 프롬프트가 없으며 마지막 텍스트 프롬프트는 연기 배경으로 시작합니다.
VideoPoet은 영상에서 가려진 부분에 세부 정보를 추가하거나 텍스트 안내를 통해 수리하도록 선택할 수 있습니다.
VideoPoet의 기능을 보여주기 위해 Google은 VideoPoet에서 생성된 여러 개의 짧은 동영상으로 구성된 단편 영화도 제작했습니다. Bard가 작성한 대본은 여행하는 너구리에 대한 짧은 이야기로, 장면별 분석과 그에 따른 프롬프트 목록이 포함되어 있습니다. 그런 다음 Google은 각 프롬프트에 대한 비디오 클립을 생성하고 생성된 모든 클립을 함께 연결하여 아래의 최종 비디오를 제작했습니다. 아래 그림과 같이 VideoPoet에서는 입력 이미지에 애니메이션을 적용하여 영상을 생성할 수 있으며, 영상을 편집하거나 영상을 확장할 수 있습니다.
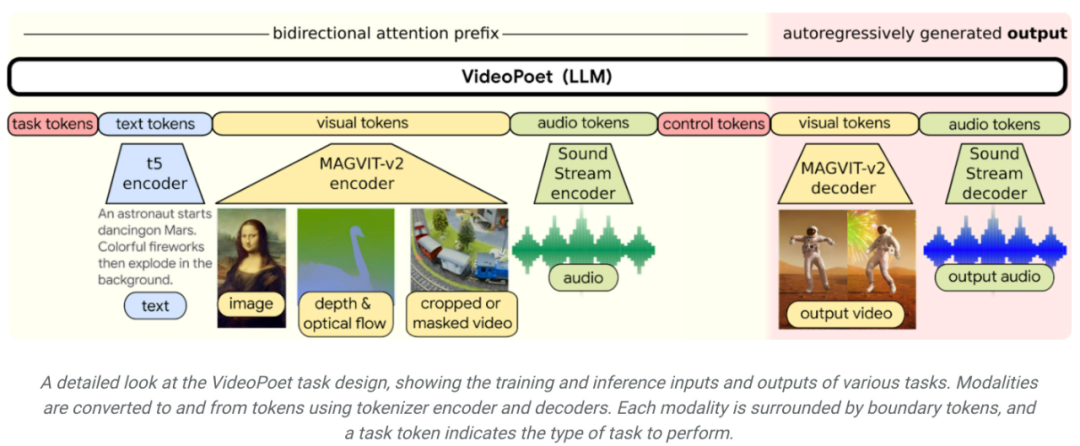
스타일화 측면에서 모델은 깊이와 시각적 흐름을 특성화하는 비디오를 수신하여 텍스트 안내 스타일로 콘텐츠를 그립니다. 교육에 LLM을 사용하는 주요 이점은 기존 LLM 교육 인프라에 도입된 확장 가능한 효율성 개선 사항 중 상당수를 재사용할 수 있다는 것입니다. 그러나 LLM은 개별 토큰으로 작동하므로 비디오 생성이 까다롭습니다. 비디오 및 오디오 토크나이저는 비디오 및 오디오 클립을 개별 토큰 시퀀스로 인코딩하는 데 사용할 수 있으며 원래 표현 형식으로 다시 변환할 수도 있습니다. VideoPoet은 여러 토크나이저(비디오 및 이미지용 MAGVIT V2, 오디오용 SoundStream)를 사용하여 자동 회귀 언어 모델을 교육하여 비디오, 이미지, 오디오 및 텍스트 전반에 걸쳐 다양한 양식을 학습합니다. 모델이 일부 컨텍스트에 따라 토큰을 생성하면 토크나이저 디코더를 사용하여 이를 다시 시각적 표현으로 변환할 수 있습니다.
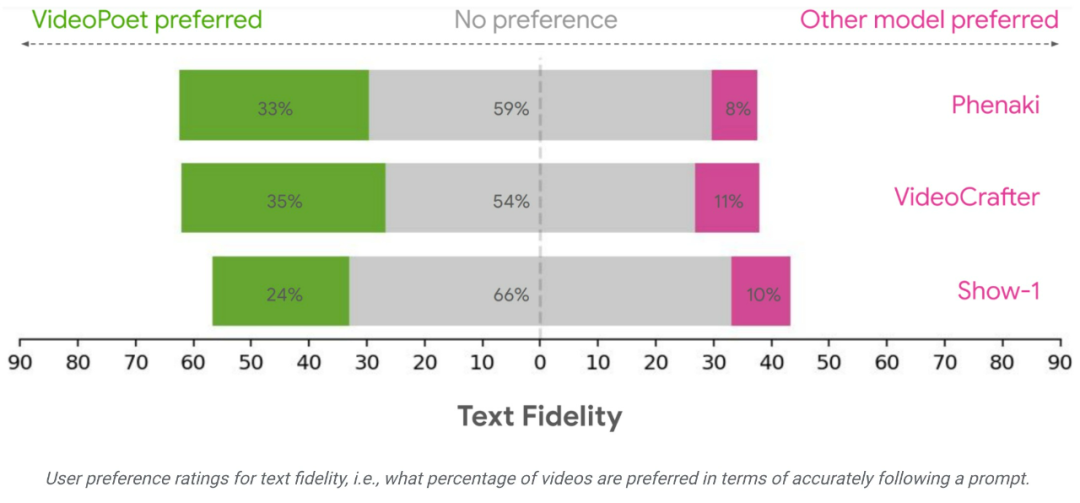
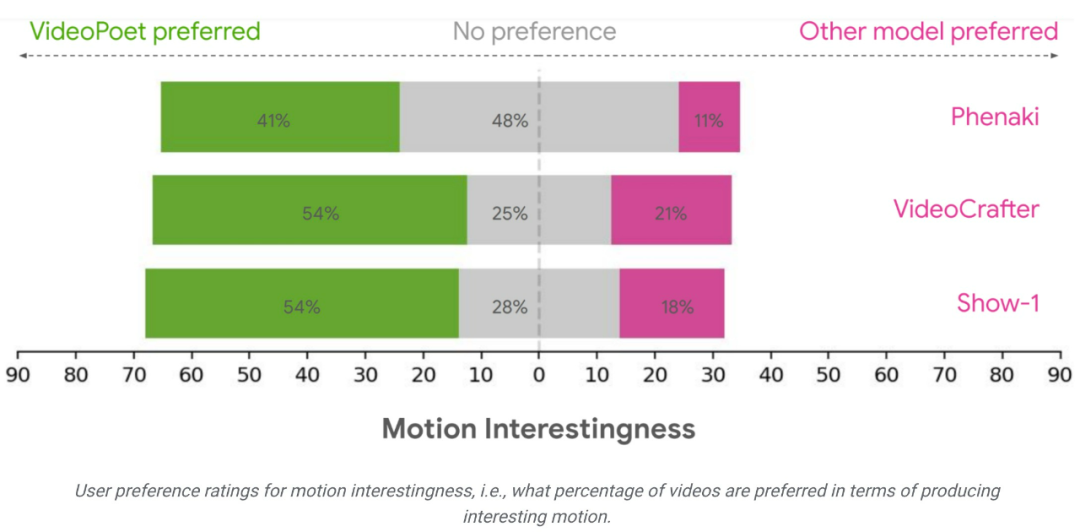
연구팀은 다른 방법과 결과를 비교하기 위해 다양한 벤치마크를 사용하여 VideoPoet의 텍스트-비디오 생성 성능을 평가했습니다. 중립적인 평가를 보장하기 위해 연구에서는 예시를 선택하지 않고 다양한 프롬프트에서 모든 모델을 실행했으며 인간 평가자에게 선호도 등급을 제공하도록 요청했습니다.
평균적으로 VideoPoet의 예시 중 24~35%가 다음 프롬프트에서 경쟁 모델보다 더 좋은 평가를 받은 반면, 경쟁 모델의 경우 8~11%가 더 좋은 평가를 받았습니다. 평가자는 또한 다른 모델의 11~21%에 비해 비디오를 생성한 작업이 더 흥미로웠기 때문에 VideoPoet의 사례 중 41~54%를 선호했습니다. https://blog.research.google/2023/12/videopoet-large-언어-model-for-zero.htmlhttps ://sites.research.google/videopoet/stylization/위 내용은 비디오 생성이 무한정 길어질 수 있나요? Google VideoPoet 대형 모델이 온라인에 등장, 네티즌: 혁명적인 기술의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


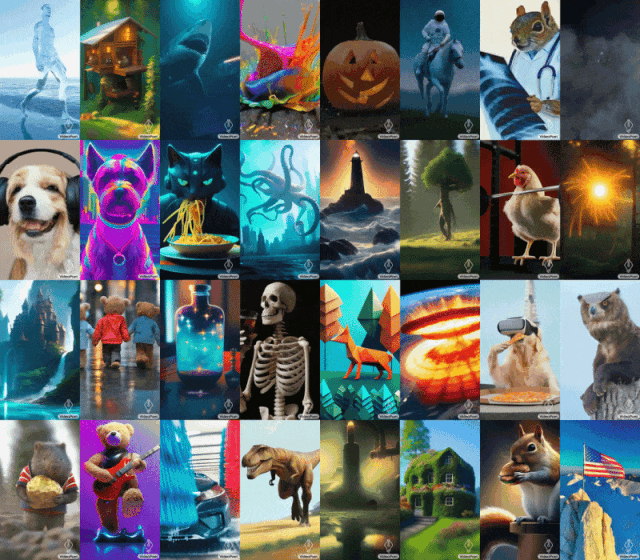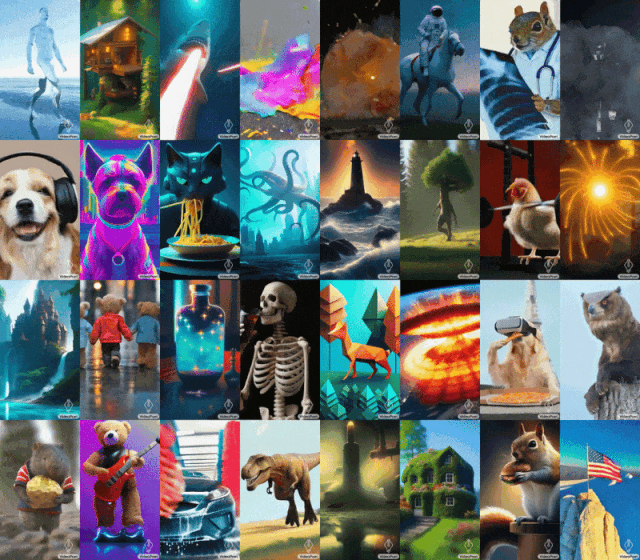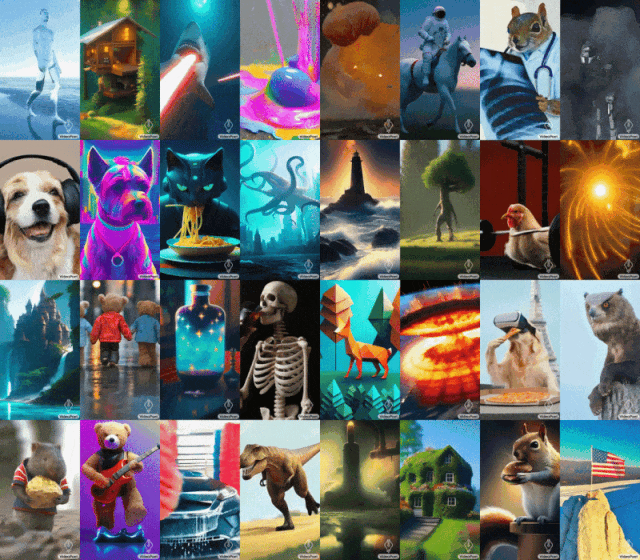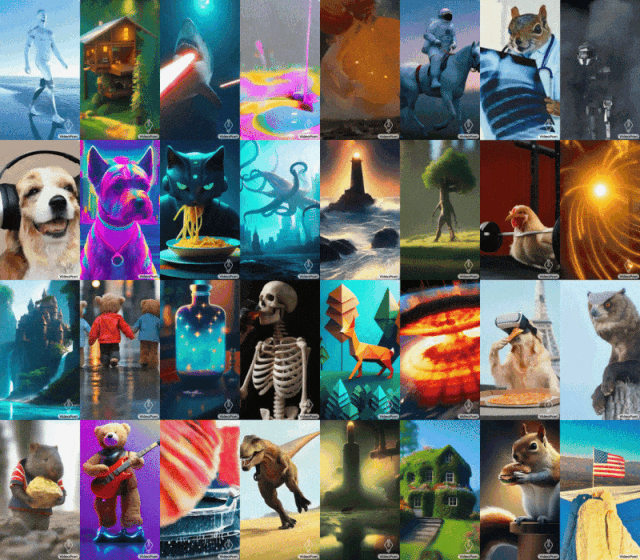

 비디오 생성에서 언어 모델의 적용을 탐색하기 위해 Google 연구원은 텍스트 대 비디오, 이미지 대 비디오, 비디오 스타일화 등 다양한 비디오 생성 작업을 수행할 수 있는 LLM(대형 언어 모델) VideoPoet을 도입했습니다. , 비디오 복구 및 확장, 비디오를 오디오로 변환.
비디오 생성에서 언어 모델의 적용을 탐색하기 위해 Google 연구원은 텍스트 대 비디오, 이미지 대 비디오, 비디오 스타일화 등 다양한 비디오 생성 작업을 수행할 수 있는 LLM(대형 언어 모델) VideoPoet을 도입했습니다. , 비디오 복구 및 확장, 비디오를 오디오로 변환.