
Sora Tokyo 소녀가 노래하게 하고 Gao Qiqiang이 그의 목소리를 Luo Xiang으로 바꾸면 Alibaba 캐릭터 립싱크 비디오가 완벽하게 생성됩니다.

- 王林앞으로
- 2024-03-01 11:34:021000검색
Alibaba의 EMO를 사용하면 AI가 생성한 이미지 또는 실제 이미지로 "움직이고 말하고 노래하는" 것이 더 쉬워졌습니다.
최근 OpenAI 소라로 대표되는 빈센트 영상 모델이 다시 인기를 끌고 있습니다.
텍스트로 생성된 영상 외에도 인간 중심의 영상 합성이 항상 많은 주목을 받아왔습니다. 예를 들어, 사용자가 제공한 오디오 클립을 기반으로 얼굴 표정을 생성하는 것이 목표인 "스피커 헤드" 비디오 생성에 중점을 둡니다.
기술적인 수준에서 표현을 생성하려면 말하는 사람의 미묘하고 다양한 얼굴 움직임을 정확하게 캡처해야 하는데, 이는 유사한 비디오 합성 작업에 있어서 큰 과제입니다.
기존 방법은 일반적으로 비디오 생성 작업을 단순화하기 위해 몇 가지 제한 사항을 적용합니다. 예를 들어, 일부 방법은 3D 모델을 활용하여 얼굴 주요 지점을 제한하는 반면, 다른 방법은 원시 비디오에서 머리 동작 시퀀스를 추출하여 전체 동작을 안내합니다. 이러한 제한으로 인해 비디오 생성의 복잡성이 줄어들지만 최종 얼굴 표정의 풍부함과 자연스러움도 제한됩니다.
알리 지능형 컴퓨팅 연구소(Ali Intelligent Computing Research Institute)가 최근 발표한 논문에서 연구원들은 화자의 머리 영상의 진정성, 자연성, 표현력을 향상시키기 위해 오디오 신호와 얼굴 움직임 사이의 미묘한 연결을 탐구하는 데 중점을 두었습니다.
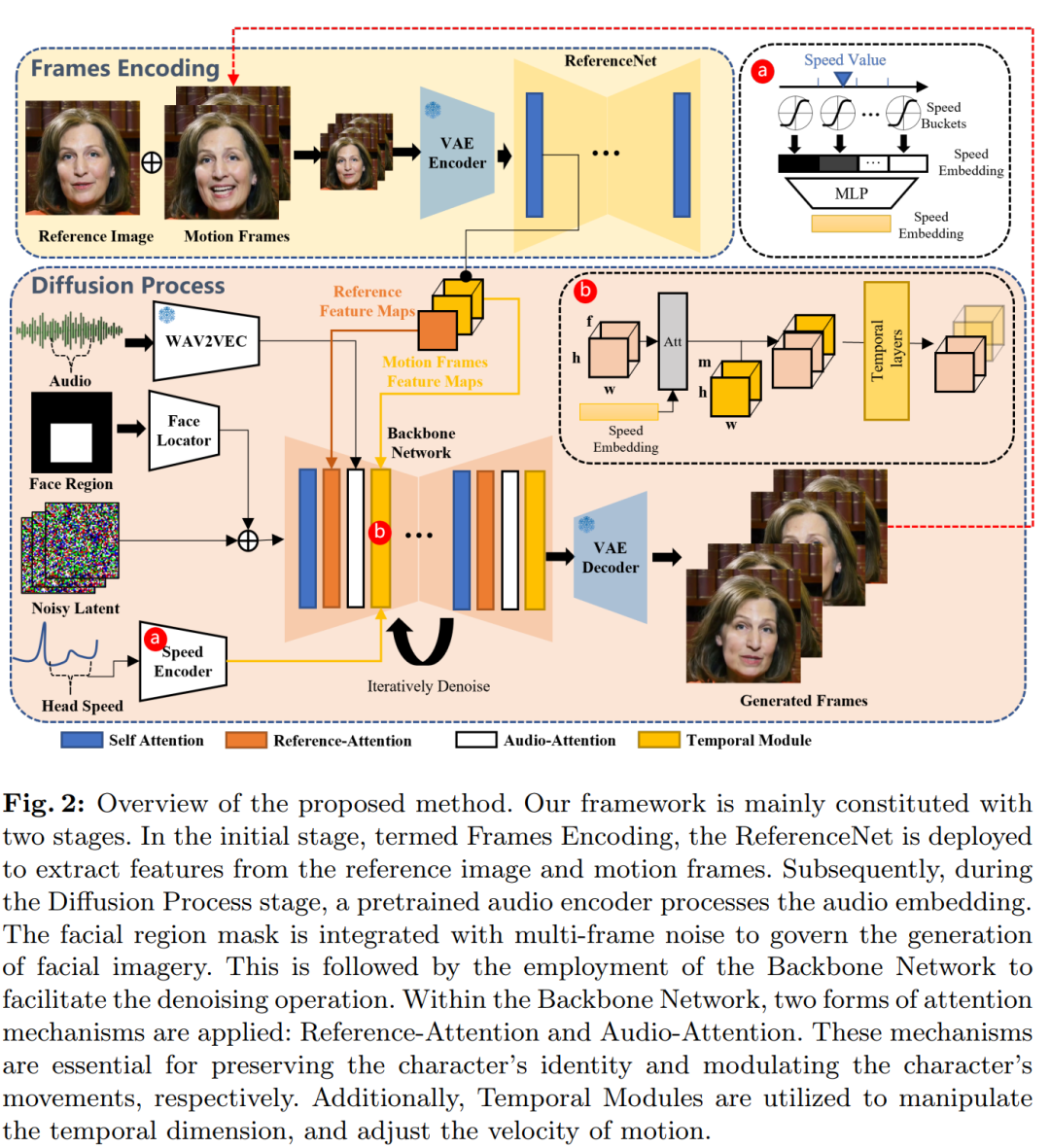
연구원들은 전통적인 방법으로 다양한 화자의 얼굴 표정과 독특한 스타일을 적절하게 포착하지 못하는 경우가 많다는 사실을 발견했습니다. 이에 중간 3D 모델이나 얼굴 랜드마크를 사용하지 않고 오디오-비디오 합성 방식을 통해 얼굴 표정을 직접 렌더링하는 EMO(Emote Portrait Alive) 프레임워크를 제안했다. ㅋㅋㅋ
프로젝트 홈페이지 : https://humanaigc.github.io/emote-portrait-alive/
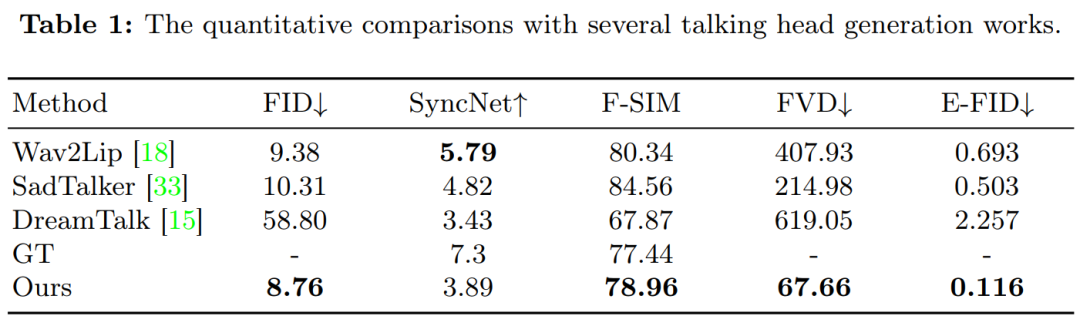
- 효과적인 측면에서 알리의 방식은 영상 전반에 걸쳐 원활한 프레임 전환을 보장하고 일관된 아이덴티티를 유지함으로써 퍼포먼스를 더욱 강렬하게 만들어 낼 수 있습니다. 현실감 넘치는 캐릭터 아바타 영상은 표현력과 사실성 측면에서 현재의 SOTA 방식보다 훨씬 뛰어납니다.
예를 들어 EMO에서는 소라가 생성한 도쿄 소녀 캐릭터를 노래하게 만들 수 있습니다. 노래는 영국/알바니아 이중 국적 여성 가수 Dua Lipa가 부른 "Don't Start Now"입니다.
- EMO는 영어와 중국어를 포함한 다양한 언어로 된 노래를 지원하며 오디오의 음색 변화를 직관적으로 식별하고 역동적이고 표현력이 풍부한 AI 캐릭터 아바타를 생성할 수 있습니다. 예를 들어 AI 페인팅 모델 ChilloutMix가 생성한 젊은 여성이 Tao Zhe의 "Melody"를 부르게 해보세요.
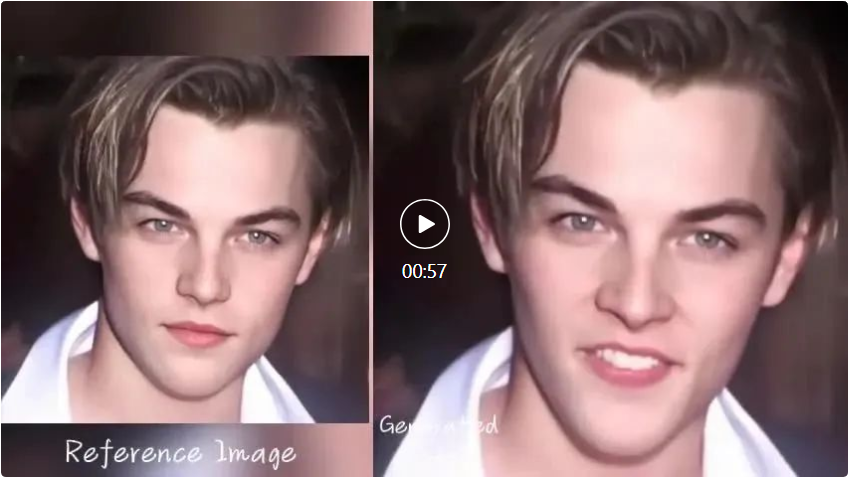
EMO는 또한 Leonardo DiCaprio에게 미국 래퍼 Eminem의 "Godzilla" 섹션을 연주하도록 요청하는 등 아바타가 빠르게 진행되는 랩 노래를 따라갈 수 있도록 할 수 있습니다.
 마지막으로 EMO는 "Cyclone"에서 Gao Qiqiang이 Luo Xiang 선생님과 연결되는 것처럼 다양한 캐릭터 간의 연결을 달성할 수도 있습니다.
마지막으로 EMO는 "Cyclone"에서 Gao Qiqiang이 Luo Xiang 선생님과 연결되는 것처럼 다양한 캐릭터 간의 연결을 달성할 수도 있습니다. 



위 내용은 Sora Tokyo 소녀가 노래하게 하고 Gao Qiqiang이 그의 목소리를 Luo Xiang으로 바꾸면 Alibaba 캐릭터 립싱크 비디오가 완벽하게 생성됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!