
Sora와 같은 모델을 훈련시키고 싶나요? You Yang 팀 OpenDiT, 80% 가속 달성

- WBOY앞으로
- 2024-02-29 16:34:381013검색
2024년 초 소라의 놀라운 성과는 새로운 벤치마크가 되었으며, Wensheng 동영상을 연구하는 모든 사람들이 따라잡기 위해 달려가고 있습니다. 모든 연구자는 Sora의 결과를 복제하기를 열망하며 시간을 두고 연구합니다.
OpenAI가 공개한 기술 보고서에 따르면, 소라의 중요한 혁신 포인트는 시각적 데이터를 패치의 통일된 표현으로 변환하고, Transformer와 확산 모델의 결합을 통해 뛰어난 확장성을 입증하는 것입니다. 이번 보고서 발표와 함께 소라의 핵심 개발자인 윌리엄 피블스(William Peebles)와 뉴욕대학교 컴퓨터공학과 조교수 시에 사이닝(Xie Saining)이 공동 집필한 논문 'Scalable Diffusion Models with Transformers'가 연구자들로부터 많은 주목을 받았다. 연구 커뮤니티는 논문에서 제안된 DiT 아키텍처를 통해 Sora를 재현할 수 있는 실행 가능한 방법을 모색하기를 희망합니다.
최근 싱가포르 국립대학교 You Yang 팀이 오픈소스로 제공하는 OpenDiT라는 프로젝트가 DiT 모델 교육 및 배포에 대한 새로운 아이디어를 열었습니다.
OpenDiT는 DiT 애플리케이션의 훈련 및 추론 효율성을 향상시키기 위해 설계된 시스템입니다. 작동이 쉬울 뿐만 아니라 빠르고 메모리 효율성도 뛰어납니다. 이 시스템은 사용자에게 효율적이고 편리한 경험을 제공하는 것을 목표로 텍스트-비디오 생성 및 텍스트-이미지 생성과 같은 기능을 다룹니다.
프로젝트 주소: https://github.com/NUS-HPC-AI-Lab/OpenDiT
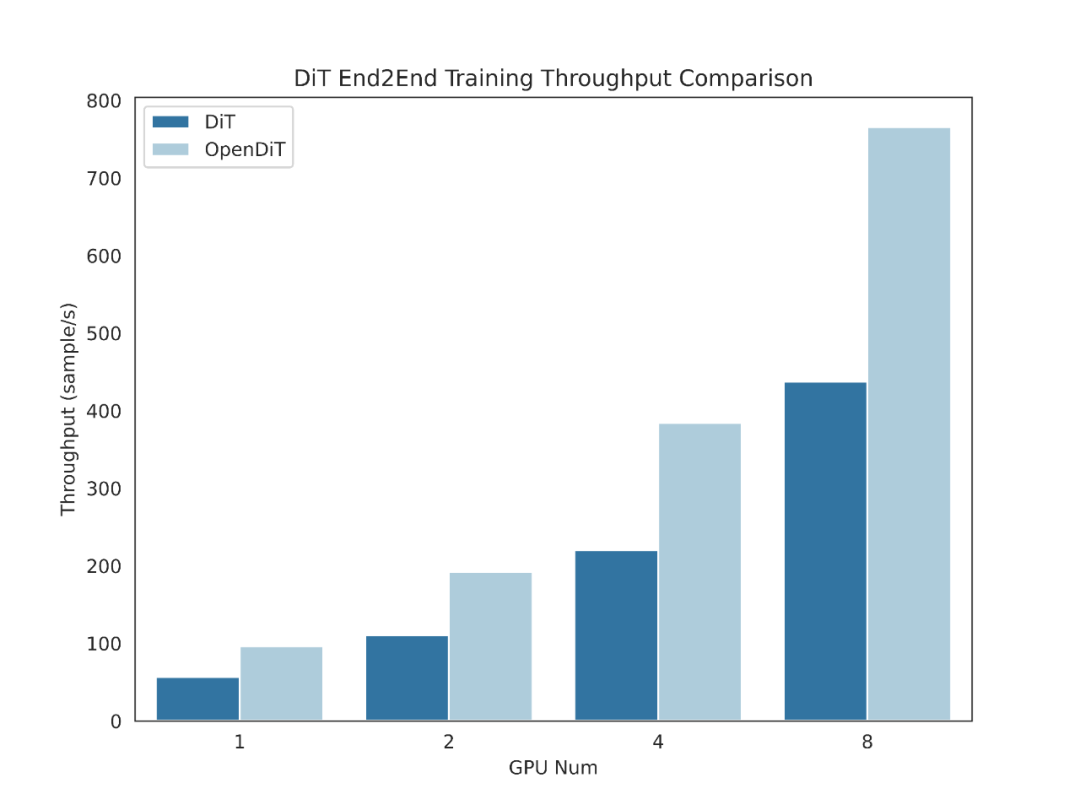
OpenDiT 방법 소개
OpenDiT는 Colossal-AI A에서 지원하는 Diffusion을 제공합니다. Transformer(DiT)의 고성능 구현. 훈련 중에 비디오 및 상태 정보는 각각 DiT 모델에 대한 입력으로 해당 인코더에 입력됩니다. 이후 확산 방식을 통해 학습 및 매개변수 업데이트를 수행하고, 마지막으로 업데이트된 매개변수를 EMA(Exponential Moving Average) 모델에 동기화합니다. 추론 단계에서는 EMA 모델을 직접 사용하여 조건 정보를 입력으로 사용하여 해당 결과를 생성합니다.
이미지 출처: https://www.zhihu.com/people/berkeley-you-yang
OpenDiT는 ZeRO 병렬 전략을 사용하여 DiT 모델 매개변수를 여러 시스템에 배포합니다. 압력. 성능과 정확성 사이의 더 나은 균형을 달성하기 위해 OpenDiT는 혼합 정밀도 교육 전략도 채택합니다. 특히 모델 매개변수와 최적화 프로그램은 정확한 업데이트를 보장하기 위해 float32를 사용하여 저장됩니다. 모델 계산 과정에서 연구팀은 모델 정확도를 유지하면서 계산 속도를 높이기 위해 DiT 모델에 대해 float16과 float32의 혼합 정밀도 방법을 설계했습니다.
DiT 모델에 사용되는 EMA 방법은 모델 매개변수 업데이트를 원활하게 하기 위한 전략으로, 모델의 안정성과 일반화 능력을 효과적으로 향상시킬 수 있습니다. 그러나 매개변수의 추가 복사본이 생성되므로 비디오 메모리에 대한 부담이 늘어납니다. 비디오 메모리의 이 부분을 더욱 줄이기 위해 연구팀은 EMA 모델을 조각화하여 다른 GPU에 저장했습니다. 훈련 과정에서 각 GPU는 EMA 모델 매개변수의 자체 부분만 계산하고 저장하면 되며 동기 업데이트를 위해 각 단계 후에 ZeRO가 업데이트를 완료할 때까지 기다려야 합니다.
FastSeq
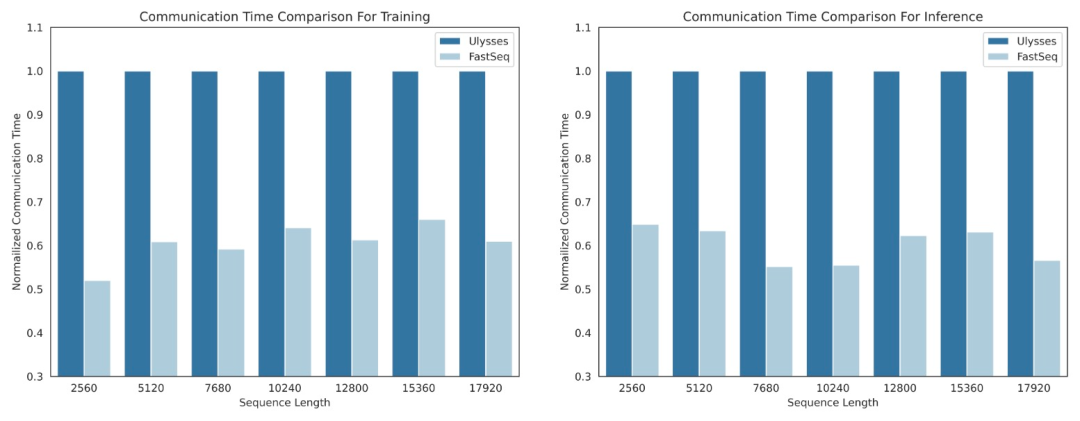
DiT와 같은 시각적 생성 모델 분야에서 시퀀스 병렬화는 효율적인 긴 시퀀스 훈련과 짧은 지연 시간 추론을 위해 필수적입니다.
그러나 DeepSpeed-Ulysses, Megatron-LM Sequence Parallelism 등과 같은 기존 방법은 이러한 작업에 적용할 때 한계에 직면합니다. 즉, 너무 많은 시퀀스 통신을 도입하거나 소규모 시퀀스 병렬 처리 효율성을 처리할 때 부족합니다.
이를 위해 연구팀은 대규모 시퀀스와 소규모 병렬 처리에 적합한 새로운 유형의 시퀀스 병렬 처리인 FastSeq을 제안했습니다. FastSeq는 변환기 레이어당 두 개의 통신 연산자만 사용하여 시퀀스 통신을 최소화하고, AllGather를 활용하여 통신 효율성을 향상시키며, 전략적으로 비동기 링을 사용하여 AllGather 통신과 qkv 계산을 겹쳐 성능을 더욱 최적화합니다.
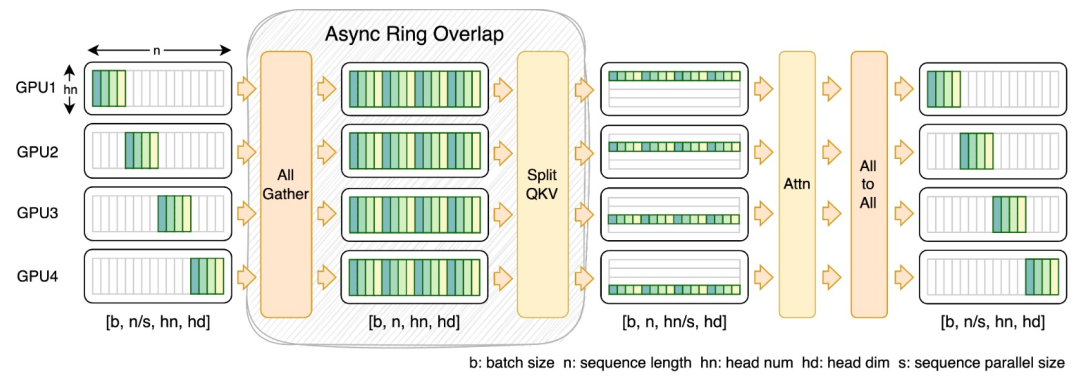
운영자 최적화
adaLN 모듈은 조건부 정보를 시각적 콘텐츠에 통합하기 위해 DiT 모델에 도입되었습니다. 이 작업은 모델 성능을 향상시키는 데 중요하지만 많은 요소별 작업을 수행하며 자주 호출됩니다. 전체 계산 효율성을 감소시키는 모델입니다. 연구팀은 이러한 문제를 해결하기 위해 여러 작업을 하나로 병합하여 컴퓨팅 효율성을 높이고 시각적 정보의 I/O 소비를 줄이는 효율적인 Fused adaLN 커널을 제안했습니다.
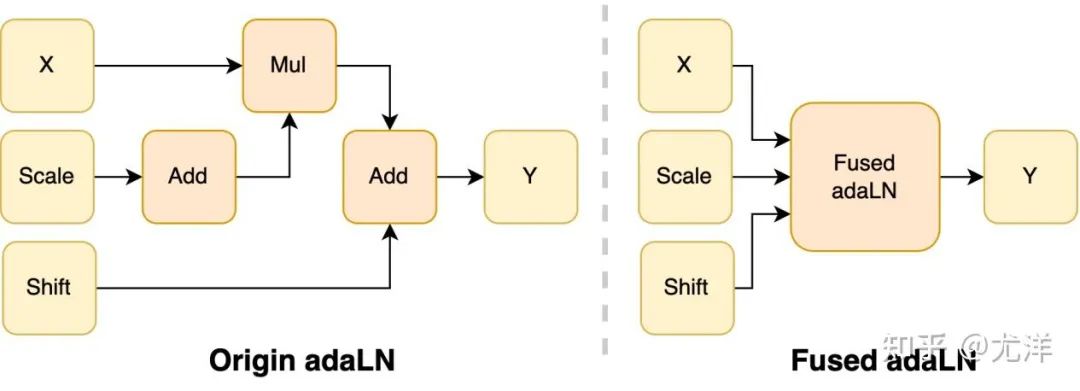
이미지 출처: https://www.zhihu.com/people/berkeley-you-yang
간단히 말하면 OpenDiT는 다음과 같은 성능 이점을 가지고 있습니다.
1. GPU 최대 80% 가속, 50% 메모리 절약
- DiT용으로 설계된 Fused AdaLN은 물론 FlashAttention, Fused Layernorm 및 HybridAdam을 포함한 효율적인 연산자를 설계했습니다.
- ZeRO, Gemini 및 DDP를 포함한 하이브리드 병렬 접근 방식을 사용합니다. ema 모델을 샤딩하면 메모리 비용도 더욱 절감됩니다.
2. FastSeq: 새로운 시퀀스 병렬 접근 방식
- 은 일반적으로 시퀀스가 길지만 매개변수가 LLM보다 작은 DiT와 유사한 워크로드를 위해 설계되었습니다.
- 노드 내 시퀀스 병렬화는 통신량을 최대 48%까지 절약할 수 있습니다.
- 단일 GPU의 메모리 한계를 극복하고 전반적인 훈련 및 추론 시간을 줄입니다.
3. 사용하기 쉽습니다.
- 단 몇 줄의 코드 수정만으로 엄청난 성능 향상을 얻을 수 있습니다.
- 사용자는 분산 교육이 어떻게 구현되는지 이해할 필요가 없습니다.
4. 텍스트-이미지 및 텍스트-비디오 생성 완료 파이프라인
- 연구원과 엔지니어는 병렬 부분을 수정하지 않고도 OpenDiT 파이프라인을 쉽게 사용하고 실제 애플리케이션에 적용할 수 있습니다.
- 연구팀은 ImageNet에서 텍스트-이미지 훈련을 진행하여 OpenDiT의 정확성을 검증하고 체크포인트를 공개했습니다.
설치 및 사용
OpenDiT를 사용하려면 먼저 필수 구성 요소를 설치해야 합니다:
- Python >= 3.10
- PyTorch >= 1.13 ( >2를 사용하는 것이 좋습니다. 0 version)
conda create -n opendit pythnotallow=3.10 -yconda activate openditOpenDiT 설치:
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .(선택 사항이지만 권장됨) 학습 및 추론 속도를 높이기 위해 라이브러리 설치:
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
훈련할 수 있습니다 다음 명령을 실행하여 DiT 모델을 생성합니다.
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"모든 가속 방법은 기본적으로 비활성화되어 있습니다. 훈련 과정의 일부 주요 요소에 대한 세부 정보는 다음과 같습니다.
플러그인: ColossalAI, zero2 및 ddp에서 사용하는 부스터 플러그인을 지원합니다. 기본값은 zero2이며 zero2를 활성화하는 것이 좋습니다.
- mixed_precision: 혼합 정밀도 훈련의 데이터 유형, 기본값은 fp16입니다.
- grad_checkpoint: 그래디언트 체크포인트 활성화 여부. 이렇게 하면 훈련 과정의 메모리 비용이 절약됩니다. 기본값은 거짓입니다. 메모리가 충분하다면 비활성화하는 것이 좋습니다.
- enable_modulate_kernel: 훈련 프로세스 속도를 높이기 위해 변조 커널 최적화를 활성화할지 여부입니다. 기본값은 False이며 GPU
- enable_layernorm_kernel: 학습 프로세스 속도를 높이기 위해 layernorm 커널 최적화를 활성화할지 여부입니다. 기본값은 False이며 활성화하는 것이 좋습니다.
- enable_flashattn: 교육 프로세스 속도를 높이기 위해 FlashAttention을 활성화할지 여부입니다. 기본값은 False이며 활성화하는 것이 좋습니다.
- sequence_parallel_size: 시퀀스 병렬 처리 크기. 값을 1보다 크게 설정하면 시퀀스 병렬성이 활성화됩니다. 기본값은 1이며, 메모리가 충분하면 비활성화하는 것이 좋습니다.
- 추론에 DiT 모델을 사용하려면 다음 코드를 실행해야 합니다. 체크포인트 경로를 자체 학습된 모델로 바꿔야 합니다.
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果
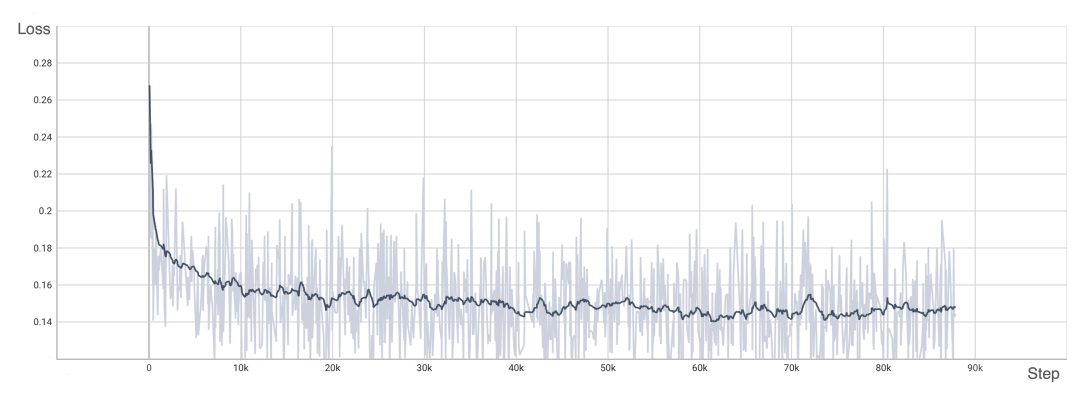
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
위 내용은 Sora와 같은 모델을 훈련시키고 싶나요? You Yang 팀 OpenDiT, 80% 가속 달성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!