이제 로봇은 정밀한 공장 제어 작업을 학습했습니다.
 최근 몇 년 동안 네 발 걷기, 잡기, 손재주 조작 등 로봇 강화학습 기술 분야에서 상당한 진전이 있었지만 대부분은 실험실 시연에 국한되어 있습니다. 단계. 로봇 강화 학습 기술을 실제 생산 환경에 광범위하게 적용하는 것은 여전히 많은 과제에 직면해 있으며, 이로 인해 실제 시나리오에서 적용 범위가 어느 정도 제한됩니다. 강화학습 기술을 실제 적용하는 과정에서는 보상 메커니즘 설정, 환경 재설정, 표본 효율성 향상, 행동 안전성 보장 등 여러 가지 복잡한 문제를 극복해야 합니다. 업계 전문가들은 강화학습 기술의 실제 구현에 있어서 많은 문제를 해결하는 것이 알고리즘 자체의 지속적인 혁신만큼 중요하다고 강조한다. 이러한 과제에 직면하여 캘리포니아 대학, 버클리 대학, 스탠포드 대학, 워싱턴 대학, Google의 학자들은 공동으로 SERL(Efficient Robot Reinforcement Learning Suite)이라는 오픈 소스 소프트웨어 프레임워크를 개발했습니다. 강화 학습 기술 실제 로봇 응용 분야에 널리 사용됩니다.
최근 몇 년 동안 네 발 걷기, 잡기, 손재주 조작 등 로봇 강화학습 기술 분야에서 상당한 진전이 있었지만 대부분은 실험실 시연에 국한되어 있습니다. 단계. 로봇 강화 학습 기술을 실제 생산 환경에 광범위하게 적용하는 것은 여전히 많은 과제에 직면해 있으며, 이로 인해 실제 시나리오에서 적용 범위가 어느 정도 제한됩니다. 강화학습 기술을 실제 적용하는 과정에서는 보상 메커니즘 설정, 환경 재설정, 표본 효율성 향상, 행동 안전성 보장 등 여러 가지 복잡한 문제를 극복해야 합니다. 업계 전문가들은 강화학습 기술의 실제 구현에 있어서 많은 문제를 해결하는 것이 알고리즘 자체의 지속적인 혁신만큼 중요하다고 강조한다. 이러한 과제에 직면하여 캘리포니아 대학, 버클리 대학, 스탠포드 대학, 워싱턴 대학, Google의 학자들은 공동으로 SERL(Efficient Robot Reinforcement Learning Suite)이라는 오픈 소스 소프트웨어 프레임워크를 개발했습니다. 강화 학습 기술 실제 로봇 응용 분야에 널리 사용됩니다. 
- 프로젝트 홈페이지: https://serl-robot.github.io/
- 오픈 소스 코드: https://github.com/rail-berkeley/serl
- 논문 제목: SERL: A Software 효율적인 샘플 강화 학습을 위한 제품군
SERL 프레임워크에는 주로 다음 구성 요소가 포함됩니다.강화 학습 분야에서는 지능형 에이전트(예: 로봇) 작업 수행 방법을 배우기 위해 환경과 상호작용을 통과합니다. 다양한 행동을 시도하고, 행동 결과에 따른 보상 신호를 획득하여 누적 보상을 극대화하도록 고안된 일련의 전략을 학습합니다. SERL은 RLPD 알고리즘을 사용하여 로봇이 실시간 상호 작용과 이전에 수집한 오프라인 데이터를 동시에 학습할 수 있도록 지원하여 로봇이 새로운 기술을 익히는 데 필요한 교육 시간을 크게 단축합니다. SERL은 개발자가 특정 작업의 필요에 따라 보상 구조를 맞춤 설정할 수 있도록 다양한 보상 제공 방법을 제공합니다. 예를 들어, 고정 위치 설치 작업은 로봇의 위치에 맞춰 보상을 받을 수 있으며, 보다 복잡한 작업은 분류기 또는 VICE를 사용하여 정확한 보상 메커니즘을 학습할 수 있습니다. 이러한 유연성은 로봇이 특정 작업에 가장 효과적인 전략을 학습하도록 정확하게 안내하는 데 도움이 됩니다. 기존의 로봇 학습 알고리즘은 다음 단계의 대화형 학습을 위해 정기적으로 환경을 재설정해야 합니다. 많은 작업에서 이 작업은 자동으로 수행될 수 없습니다. SERL이 제공하는 비강화 학습 기능은 두 가지 정방향 정책을 동시에 교육하여 서로에 대한 환경 재설정을 제공합니다. SERL은 Franka 매니퓰레이터 작업을 위한 일련의 Gym 환경 인터페이스를 표준 예로 제공하므로 사용자는 SERL을 다른 로봇 팔로 쉽게 확장할 수 있습니다. 로봇이 복잡한 물리적 환경에서 안전하고 정확하게 탐색하고 작동할 수 있도록 SERL은 정확성을 보장하면서 Franka 로봇 팔을 위한 특수 임피던스 컨트롤러를 제공합니다. 동시에 외부 물체와 접촉한 후 과도한 토크가 발생하지 않는지 확인하십시오. 이러한 기술과 방법의 결합을 통해 SERL은 높은 성공률과 견고성을 유지하면서 훈련 시간을 크게 단축하여 로봇이 짧은 시간에 복잡한 작업을 완료하는 방법을 학습하고 현실 세계에 효과적으로 적용할 수 있도록 합니다. 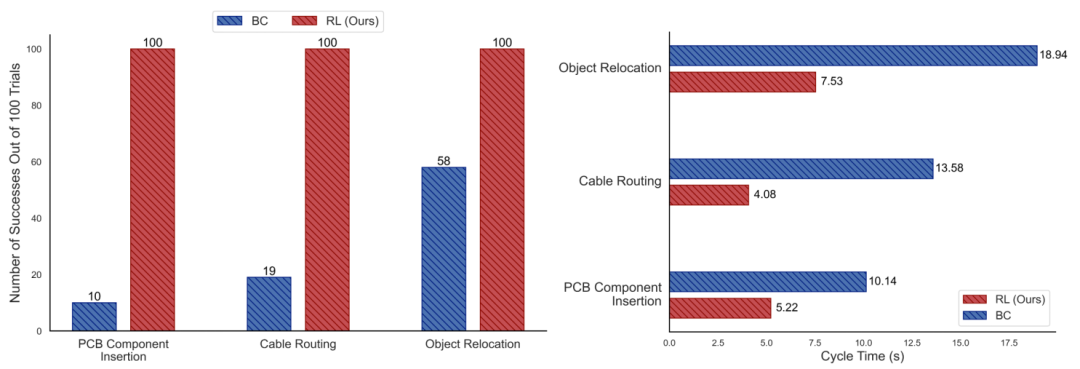 그림 1, 2: 다양한 작업에서 SERL과 행동 복제 방법 간의 성공률과 비트 수 비교. 비슷한 양의 데이터로 SERL의 성공률은 클론보다 몇 배(최대 10배) 높으며, 비트율도 최소 2배 이상 빠릅니다.
그림 1, 2: 다양한 작업에서 SERL과 행동 복제 방법 간의 성공률과 비트 수 비교. 비슷한 양의 데이터로 SERL의 성공률은 클론보다 몇 배(최대 10배) 높으며, 비트율도 최소 2배 이상 빠릅니다.
PCB 보드에 천공 부품을 조립하는 것은 흔하지만 어려운 로봇 작업입니다. 전자 부품의 핀은 구부러지기 매우 쉽고 구멍 위치와 핀 사이의 공차가 매우 작기 때문에 조립 시 로봇이 정밀하고 부드러워야 합니다. 단 21분의 자율 학습으로 SERL은 로봇이 100% 작업 완료율을 달성할 수 있도록 했습니다. 회로 기판의 위치가 움직이거나 시선이 부분적으로 차단되는 등 알 수 없는 간섭이 발생하는 경우에도 로봇은 안정적으로 조립 작업을 완료할 수 있습니다. 


: 그림 3, 4, 5: 회로 기판 구성 요소의 임무를 수행할 때 로봇은 훈련 단계에서 발생하지 않은 다양한 간섭을 처리하고 작업을 원활하게 완료할 수 있습니다.
많은 기계 및 전자 장비의 조립 공정에서는 특정 경로를 따라 케이블을 정확한 위치에 설치해야 합니다. 이 작업에는 정확성과 적응성이 필요합니다. 만들어졌다. 유연한 케이블은 배선 과정에서 변형되기 쉽기 때문에 케이블이 우발적으로 움직이거나 홀더 위치가 변경되는 등 배선 과정이 다양한 방해를 받을 수 있으므로 기존의 비-접속 케이블로는 처리하기가 어렵습니다. 학습 방법. SERL은 단 30분 만에 100% 성공률을 달성할 수 있습니다. 그리퍼 위치가 훈련 중 위치와 다른 경우에도 로봇은 학습한 기술을 일반화하고 새로운 배선 문제에 적응하여 배선 작업을 올바르게 실행할 수 있습니다. : 그림 6, 7, 8: 로봇공학은 별도의 훈련 없이 훈련 중 훈련과 다른 클립을 통해 케이블을 직접 통과시킬 수 있습니다.

3. 물체 집기 및 배치 작업:

 창고 관리 또는 소매 산업에서 로봇은 종종 품목을 한 곳에서 다른 곳으로 이동해야 하며, 이를 위해서는 로봇이 식별하고 운반할 수 있어야 합니다. 특정 항목. 강화 학습의 훈련 과정에서는 작동이 부족한 객체를 자동으로 재설정하기가 어렵습니다. SERL의 재설정 없는 강화 학습 기능을 활용하여 로봇은 1시간 45분 만에 100/100 성공률로 두 가지 정책을 동시에 학습했습니다. 상자 A에서 상자 B로 물건을 넣으려면 순방향 전략을 사용하고, 상자 B에서 상자 A로 물건을 다시 넣으려면 뒤로 전략을 사용합니다.
창고 관리 또는 소매 산업에서 로봇은 종종 품목을 한 곳에서 다른 곳으로 이동해야 하며, 이를 위해서는 로봇이 식별하고 운반할 수 있어야 합니다. 특정 항목. 강화 학습의 훈련 과정에서는 작동이 부족한 객체를 자동으로 재설정하기가 어렵습니다. SERL의 재설정 없는 강화 학습 기능을 활용하여 로봇은 1시간 45분 만에 100/100 성공률로 두 가지 정책을 동시에 학습했습니다. 상자 A에서 상자 B로 물건을 넣으려면 순방향 전략을 사용하고, 상자 B에서 상자 A로 물건을 다시 넣으려면 뒤로 전략을 사용합니다.
그림 9, 10, 11: SERL은 두 가지 전략 세트를 훈련했습니다. 하나는 오른쪽에서 왼쪽으로 물체를 옮기는 전략이고 다른 하나는 왼쪽에서 다시 오른쪽으로 물체를 옮기는 전략입니다. 로봇은 훈련 대상에 대해 100% 성공률을 달성할 뿐만 아니라 이전에 본 적이 없는 대상을 지능적으로 처리할 수도 있습니다. Jianlan Luo는 현재 University of California, Berkeley에서 박사후 연구원으로 재직하고 있습니다. Sergey Levine 교수와 협력하여 버클리 인공 지능 센터(BAIR)에서 그의 주요 연구 관심 분야는 기계 학습, 로봇공학, 최적 제어입니다. 학계로 돌아오기 전 그는 Google X에서 Stefan Schaal 교수와 함께 일하는 전임 연구원이었습니다. 그 전에는 University of California, Berkeley에서 컴퓨터 과학 석사 학위와 기계 공학 박사 학위를 받았으며, 이 기간 동안 Alice Agogino 교수와 Pieter Abbeel 교수와 함께 일했습니다. 그는 또한 Deepmind의 런던 본사에서 방문 연구 학자로도 활동했습니다. 캘리포니아대학교 버클리캠퍼스에서 컴퓨터과학과 응용수학을 전공했습니다. 현재 그는 Sergey Levine 교수가 이끄는 RAIL 연구실에서 연구를 수행하고 있습니다. 그는 로봇 학습 분야에 큰 관심을 갖고 있으며, 로봇이 현실 세계에서 능숙한 조작 기술을 빠르고 광범위하게 습득할 수 있는 방법 개발에 중점을 두고 있습니다. 캘리포니아대학교 버클리캠퍼스에서 전기공학과 컴퓨터공학을 전공하는 4학년 학부생입니다. 현재 그는 Sergey Levine 교수가 이끄는 RAIL 연구실에서 연구를 수행하고 있습니다. 그의 연구 관심 분야는 로봇 공학과 기계 학습의 교차점이며, 매우 강력하고 일반화가 가능한 자율 제어 시스템을 구축하는 것을 목표로 합니다. 그는 Sergey Levine 교수가 지도하는 Berkeley RAIL 연구소의 연구 엔지니어입니다. 그는 이전에 싱가포르 난양기술대학교에서 학사학위를 취득했고, 미국 조지아공과대학에서 석사학위를 취득했습니다. 그 전에는 Open Robotics Foundation의 회원이었습니다. 그의 작업은 기계 학습 및 로봇 공학 소프트웨어 기술의 실제 적용에 중점을 두고 있습니다. 그는 1991년 독일 뮌헨 공과대학교에서 기계 공학 및 인공 지능 박사 학위를 받았습니다. MIT 뇌인지과학과 인공지능연구소 박사후 연구원, 일본 ATR 인간정보처리연구소 초빙연구원, 조지아 공과대학 신체운동학과 겸임 조교수이다. 그리고 미국 펜실베이니아 주립대학교. 그는 또한 일본 ERATO 프로젝트인 Jawa Kinetic Brain Project(ERATO/JST)에서 컴퓨터 학습 그룹 리더로도 활동했습니다. 1997년에 그는 USC에서 컴퓨터공학, 신경과학, 의생명공학 교수가 되었고 종신교수로 승진했습니다. 그의 연구 관심 분야에는 통계 및 기계 학습, 신경망 및 인공 지능, 전산 신경 과학, 기능적 뇌 영상, 비선형 역학, 비선형 제어 이론, 로봇 공학 및 생체 모방 로봇과 같은 주제가 포함됩니다. 그는 독일 막스 플랑크 지능형 시스템 연구소의 창립 이사 중 한 명으로, 수년 동안 자율 모션 부서를 이끌었습니다. 그는 현재 Alphabet의 [Google] 새 로봇공학 자회사인 Intrinsic의 수석 과학자입니다. 스테판 샬(Stefan Schaal)은 IEEE 펠로우입니다. 그녀는 스탠포드 대학의 컴퓨터 과학 및 전기 공학과 조교수입니다. 그녀의 연구실인 IRIS는 대규모 로봇 상호 작용을 통해 지능을 탐구하며 SAIL 및 ML 그룹에 속해 있습니다. 그녀는 또한 Google Brain 팀의 구성원이기도 합니다. 그녀는 학습과 상호작용을 통해 광범위한 지능형 행동을 개발하는 로봇과 기타 지능형 에이전트의 능력에 관심이 있습니다. 그녀는 이전에 캘리포니아 대학교 버클리에서 컴퓨터 과학 박사 학위를 취득했고, MIT에서 전기 공학 및 컴퓨터 과학 학사 학위를 취득했습니다. 그는 워싱턴 대학교 컴퓨터 과학 및 공학부 Paul G. Allen 학교의 조교수이며 WEIRD 연구소를 이끌고 있습니다. 이전에는 MIT에서 박사후 연구원으로 Russ Tedrake 및 Pulkit Agarwal과 함께 일했습니다. 그는 Sergey Levine 교수와 Pieter Abbeel 교수의 지도 하에 UC Berkeley BAIR에서 기계 학습 및 로봇공학 박사 학위를 취득했습니다. 그 전에는 캘리포니아 대학교 버클리 캠퍼스에서 학사 학위도 취득했습니다. 그의 주요 연구 목표는 로봇 시스템이 사무실이나 집과 같은 다양한 비정형 환경에서 복잡한 작업을 수행하는 방법을 배울 수 있도록 하는 알고리즘을 개발하는 것입니다. 그는 버클리 캘리포니아 대학교 전기 공학 및 컴퓨터 과학과의 부교수입니다. 그의 연구는 자율 에이전트가 복잡한 행동을 학습할 수 있도록 하는 알고리즘, 특히 자율 시스템이 모든 작업을 해결하는 방법을 학습할 수 있도록 하는 일반적인 방법에 중점을 두고 있습니다. 이러한 방법의 응용 분야에는 로봇 공학뿐만 아니라 자율적인 의사 결정이 필요한 다양한 기타 영역이 포함됩니다. 위 내용은 20분만에 회로 기판 조립 방법을 배워보세요! 오픈 소스 SERL 프레임워크는 100% 정밀 제어 성공률을 가지며 인간보다 3배 빠릅니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

