
2단계로 25프레임의 고품질 애니메이션 생성(SVD의 8%로 계산됨) |

- PHPz앞으로
- 2024-02-20 15:54:161042검색
소비되는 컴퓨팅 리소스는 기존 Stable Video Diffusion(SVD)모델의 2/25에 불과합니다!
시간이 많이 걸리고 많은 계산이 필요한 반복 노이즈 제거를 위해 비디오 확산 모델을 변경하는 AnimateLCM-SVD-xt가 출시되었습니다.
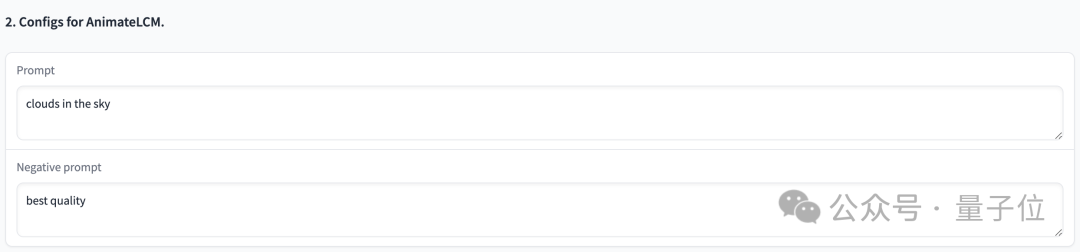
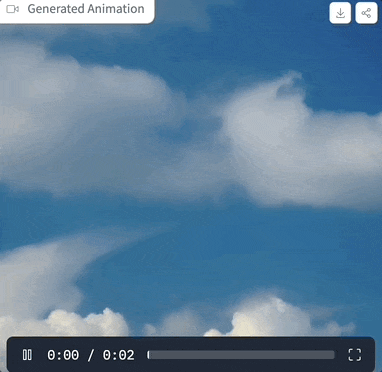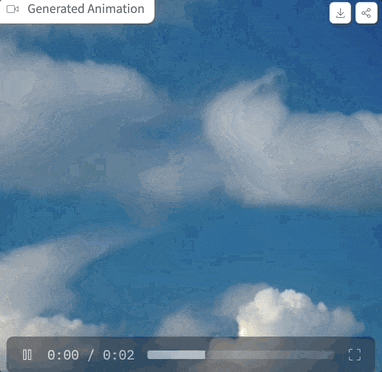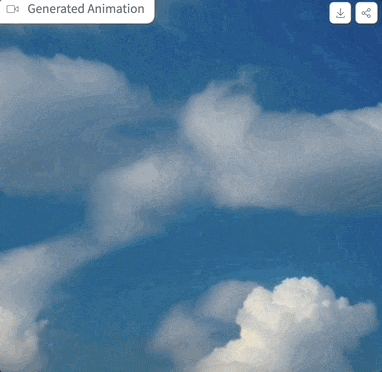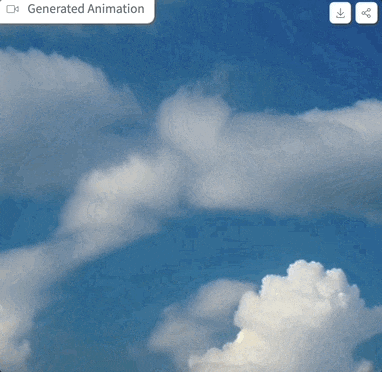
먼저 생성된 애니메이션 효과를 살펴보겠습니다.
사이버펑크 스타일은 제어하기 쉽고, 소년은 헤드폰을 끼고 네온 도시 거리에 서 있습니다.
 사진
사진
현실적인 스타일도 사용할 수 있습니다. 신혼 부부가 절묘한 꽃다발을 들고 함께 껴안고 있습니다. 고대 돌담 아래서 사랑을 목격하세요:
 picture
picture
공상 과학 스타일이며 외계인이 지구를 침략하는 느낌도 있습니다:
 picture
picture
AnimateLCM-SVD-xt from MMLab, The Chinese Avolution AI, Shanghai Artificial Intelligence Laboratory 및 SenseTime Research Institute의 연구원들이 공동으로 제안한 홍콩 대학교.
 pictures
pictures
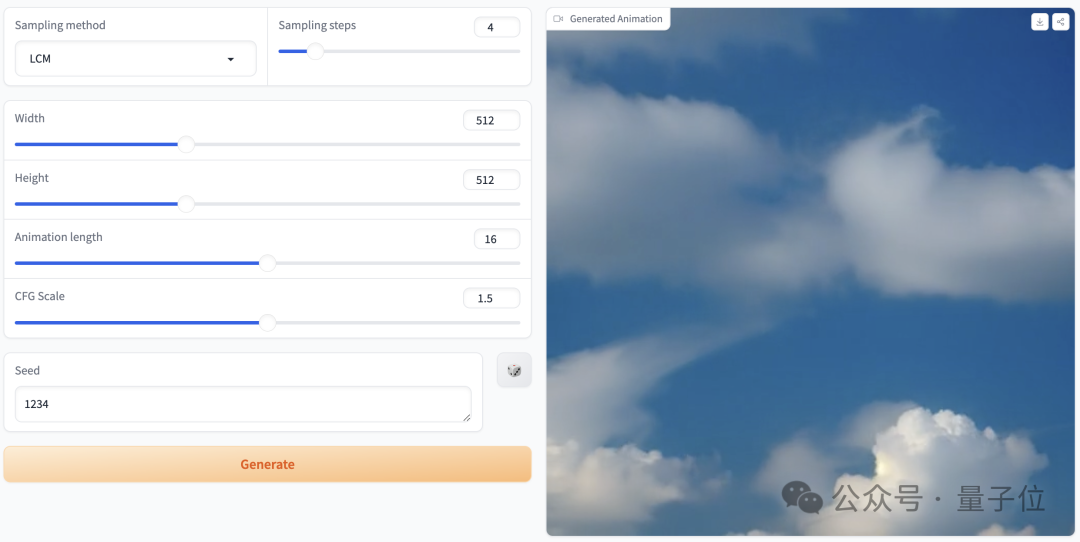
2~8단계로 25프레임, 해상도 576x1024로 고품질 애니메이션을 생성할 수 있으며, 분류자 안내 없이
, 4단계로 생성된 비디오는 높은 충실도를 달성할 수 있습니다. 기존 SVD보다 우수함 더 빠르고 효율적: Pictures
Pictures
 Pictures
Pictures
 picture
picture
 pictures
pictures
 Pictures
Pictures
 picture
picture
 Pictures
Pictures
 pictures
pictures
 pictures
pictures
 pictures
pictures
 사진
사진
어떻게 하나요?
일관되고 충실도가 높은 비디오를 생성하는 능력으로 인해 비디오 확산 모델이 점점 더 많은 관심을 받고 있지만, 어려움 중 하나는 반복적인 노이즈 제거 프로세스가 시간이 많이 걸릴 뿐만 아니라 계산 집약적이어서 작업이 제한된다는 점에 유의하세요. 적용 범위.
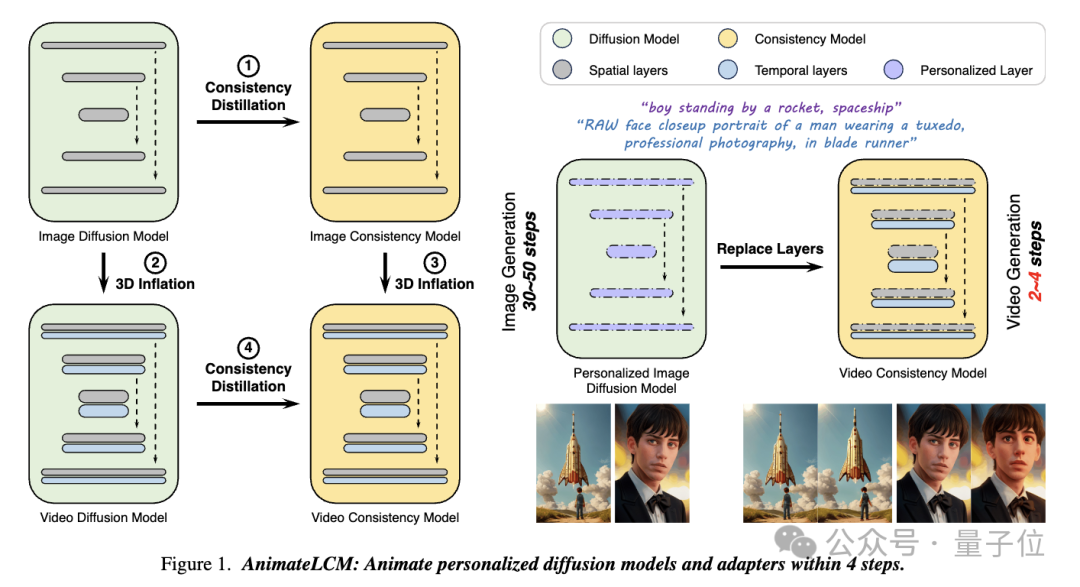
이 연구 AnimateLCM에서 연구원들은 사전 훈련된 이미지 확산 모델을 단순화하여 샘플링에 필요한 단계를 줄이고 조건부 이미지 생성 잠재 일관성 모델 (LCM)에서 성공적으로 확장하는 일관성 모델 (CM)에서 영감을 받았습니다. ) .
 Picture
Picture
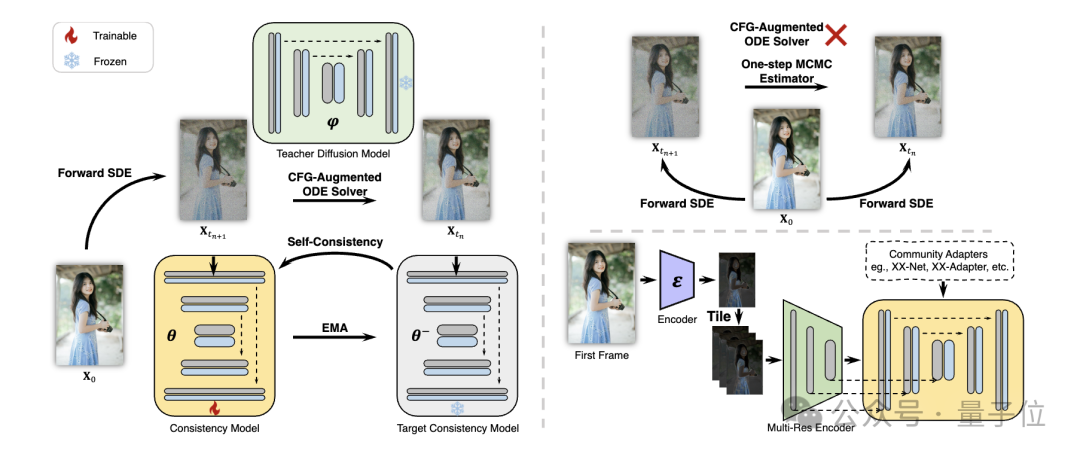
구체적으로 연구진은 Decoupled Consistency Learning(Decoupled Consistency Learning) 전략을 제안했습니다.
먼저 고품질 이미지-텍스트 데이터 세트에서 안정적인 확산 모델을 이미지 일관성 모델로 증류한 다음 비디오 데이터에 대해 일관성 증류를 수행하여 비디오 일관성 모델을 얻습니다. 이 전략은 공간적, 시간적 수준에서 별도로 훈련하여 훈련 효율성을 향상시킵니다.
 Pictures
Pictures
또한 Stable Diffusion 커뮤니티에서 플러그 앤 플레이 어댑터의 다양한 기능을 구현하기 위해 (예: ControlNet을 사용하여 제어 가능한 생성 달성) 연구원들은 Teacher- (Teacher-Free Adaptation) 전략을 무료로 적용하여 기존 제어 어댑터를 일관성 모델과 더욱 일관되게 만들고 더 나은 제어 가능한 비디오 생성을 달성합니다.
 Pictures
Pictures
양적, 정성적 실험 모두 방법의 효과를 입증합니다.
UCF-101 데이터세트에 대한 제로샷 텍스트-비디오 생성 작업에서 AnimateLCM은 FVD 및 CLIPSIM 지표 모두에서 최고의 성능을 달성했습니다.
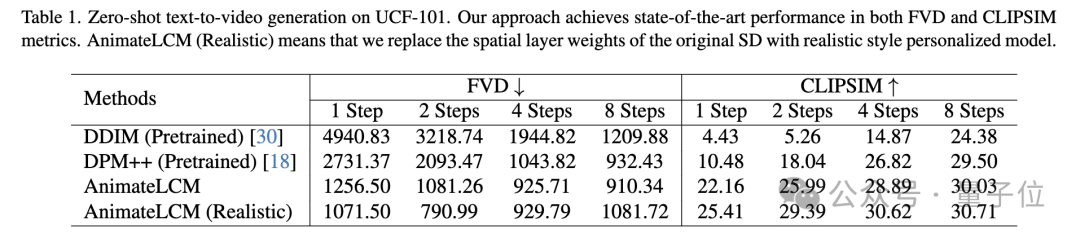 Picture
Picture
 Picture
Picture
Ablation 연구는 분리된 일관성 학습 및 특정 초기화 전략의 효과를 검증합니다:
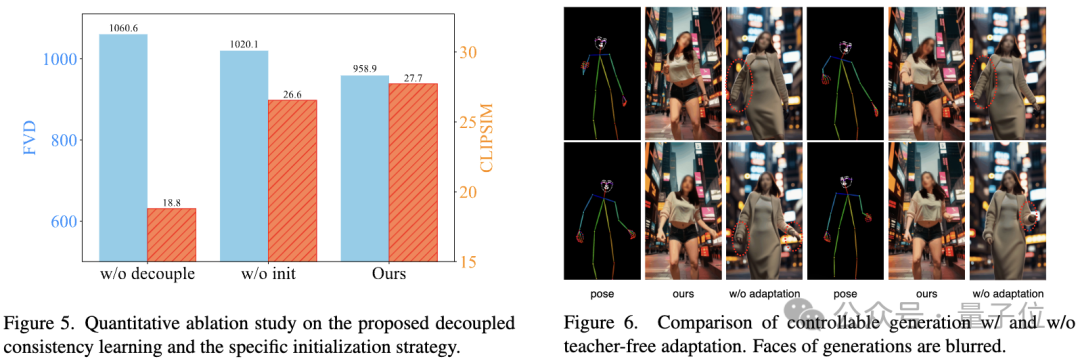 Picture
Picture
프로젝트 링크:
[1]https:// cm. github.io/
[2]https://huggingface.co/wangfuyun/AnimateLCM-SVD-xt
위 내용은 2단계로 25프레임의 고품질 애니메이션 생성(SVD의 8%로 계산됨) |의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!