
자연어 생성 작업의 5가지 샘플링 방법 및 Pytorch 코드 구현 소개

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-20 08:50:031286검색
자연어 생성 작업에서 샘플링 방법은 생성 모델에서 텍스트 출력을 얻는 기술입니다. 이 기사에서는 5가지 일반적인 방법을 논의하고 PyTorch를 사용하여 구현합니다.
1. Greedy Decoding
Greedy Decoding에서는 생성 모델이 입력 시퀀스 시간을 기준으로 출력 시퀀스의 단어를 시간별로 예측합니다. 각 시간 단계에서 모델은 각 단어의 조건부 확률 분포를 계산한 다음, 현재 시간 단계의 출력으로 조건부 확률이 가장 높은 단어를 선택합니다. 이 단어는 다음 시간 단계의 입력이 되며 지정된 길이의 시퀀스 또는 특수 종료 표시와 같은 일부 종료 조건이 충족될 때까지 생성 프로세스가 계속됩니다. Greedy Decoding의 특징은 매번 전역 최적해를 고려하지 않고 현재 조건부 확률이 가장 높은 단어를 출력으로 선택하는 것입니다. 이 방법은 간단하고 효율적이지만 덜 정확하거나 다양한 시퀀스가 생성될 수 있습니다. Greedy Decoding은 일부 간단한 시퀀스 생성 작업에 적합하지만 복잡한 작업의 경우 생성 품질을 향상시키기 위해 더 복잡한 디코딩 전략이 필요할 수 있습니다.
이 방법은 계산 속도가 빠르지만 그리디 디코딩은 로컬 최적 솔루션에만 초점을 맞추기 때문에 생성된 텍스트의 다양성이 부족하거나 부정확할 수 있으며 전역 최적 솔루션을 얻을 수 없습니다.
그리디 디코딩에는 한계가 있지만 특히 빠른 실행이 필요하거나 작업이 상대적으로 간단한 경우 많은 시퀀스 생성 작업에서 여전히 널리 사용됩니다.
def greedy_decoding(input_ids, max_tokens=300): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] next_token = torch.argmax(next_token_logits, dim=-1) if next_token == tokenizer.eos_token_id: break input_ids = torch.cat([input_ids, rearrange(next_token, 'c -> 1 c')], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
2. 빔 검색
빔 검색은 탐욕스러운 디코딩의 확장으로, 각 시간 단계에서 여러 후보 시퀀스를 유지하여 탐욕스러운 디코딩의 로컬 최적 문제를 극복합니다.
빔 검색은 각 시간 단계에서 가장 확률이 높은 후보 단어를 유지한 후, 생성이 끝날 때까지 다음 시간 단계에서 이러한 후보 단어를 기반으로 계속 확장하는 텍스트를 생성하는 방법입니다. 이 방법은 여러 후보 단어 경로를 고려하여 생성된 텍스트의 다양성을 향상시킬 수 있습니다.
빔 검색에서 모델은 하나의 최상의 시퀀스만 선택하는 대신 여러 후보 시퀀스를 동시에 생성합니다. 현재 생성된 부분 시퀀스와 히든 상태를 기반으로 다음 단계에서 가능한 단어를 예측하고 각 단어의 조건부 확률 분포를 계산합니다. 여러 후보 시퀀스를 병렬로 생성하는 이 방법은 검색 효율성을 향상시켜 모델이 전체 확률이 가장 높은 시퀀스를 더 빠르게 찾을 수 있게 해줍니다.
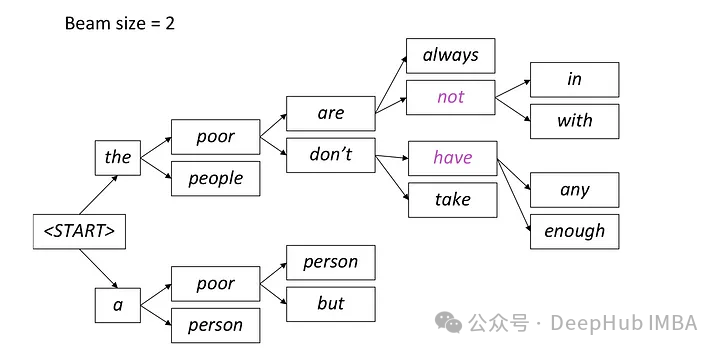
각 단계에서 가장 가능성이 높은 두 개의 경로만 유지되고 나머지 경로는 빔 = 2 설정에 따라 삭제됩니다. 이 프로세스는 시퀀스 끝 토큰을 생성하거나 모델에서 설정한 최대 시퀀스 길이에 도달하여 중지 조건이 충족될 때까지 계속됩니다. 최종 출력은 마지막 경로 세트 중에서 전체 확률이 가장 높은 시퀀스가 됩니다.
from einops import rearrange import torch.nn.functional as F def beam_search(input_ids, max_tokens=100, beam_size=2): beam_scores = torch.zeros(beam_size).to(device) beam_sequences = input_ids.clone() active_beams = torch.ones(beam_size, dtype=torch.bool) for step in range(max_tokens): outputs = model(beam_sequences) logits = outputs.logits[:, -1, :] probs = F.softmax(logits, dim=-1) top_scores, top_indices = torch.topk(probs.flatten(), k=beam_size, sorted=False) beam_indices = top_indices // probs.shape[-1] token_indices = top_indices % probs.shape[-1] beam_sequences = torch.cat([ beam_sequences[beam_indices], token_indices.unsqueeze(-1)], dim=-1) beam_scores = top_scores active_beams = ~(token_indices == tokenizer.eos_token_id) if not active_beams.any(): print("no active beams") break best_beam = beam_scores.argmax() best_sequence = beam_sequences[best_beam] generated_text = tokenizer.decode(best_sequence) return generated_text3. 온도 샘플링
온도 매개변수 샘플링(Temperature Sampling)은 언어 모델과 같은 확률 기반 생성 모델에 자주 사용됩니다. 모델 출력의 확률 분포를 조정하기 위해 "온도"라는 매개변수를 도입하여 생성된 텍스트의 다양성을 제어합니다.
온도 매개변수 샘플링에서는 모델이 각 시간 단계에서 단어를 생성할 때 단어의 조건부 확률 분포를 계산합니다. 그런 다음 모델은 이 조건부 확률 분포의 각 단어의 확률 값을 온도 매개변수로 나누고 결과를 정규화하여 새로운 정규화된 확률 분포를 얻습니다. 온도 값이 높을수록 확률 분포가 더 부드러워져 생성되는 텍스트의 다양성이 높아집니다. 확률이 낮은 단어는 선택될 확률도 더 높지만 온도 값이 낮을수록 확률 분포가 더 집중되고 확률이 높은 단어를 선택할 가능성이 높아지므로 생성된 텍스트가 더 결정적입니다. 마지막으로 모델은 이 새로운 정규화된 확률 분포에 따라 무작위로 샘플링하고 생성된 단어를 선택합니다.
import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
4. Top-K 샘플링
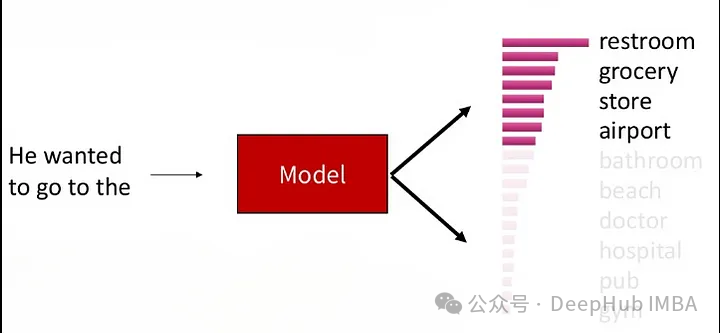
Top-K 샘플링(각 시간 단계에서 조건부 확률 순위로 상위 K 단어를 선택한 다음 이 K 단어 중에서 무작위로 샘플링합니다. 이 방법은 특정 생성 품질을 유지할 수 있습니다.
이 프로세스를 통해 생성된 텍스트는 특정 다양성을 유지하면서 특정 생성 품질을 유지할 수 있습니다. 후보 단어들 사이에는 여전히 어느 정도의 경쟁이 있습니다. 매개변수 K는 각 시간 단계에서 유지되는 후보 단어의 수를 제어합니다. K 값이 작을수록 소수의 단어만 무작위 샘플링에 참여하기 때문에 더 탐욕스러운 행동으로 이어집니다. K 값이 클수록 생성된 텍스트의 다양성이 증가하지만 계산 오버헤드도 증가합니다
def top_k_sampling(input_ids, max_tokens=100, top_k=50, temperature=1.0):for _ in range(max_tokens): with torch.inference_mode(): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] top_k_logits, top_k_indices = torch.topk(next_token_logits, top_k) top_k_probs = F.softmax(top_k_logits / temperature, dim=-1) next_token_index = torch.multinomial(top_k_probs, num_samples=1) next_token = top_k_indices.gather(-1, next_token_index) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
 .
.5、Top-P (Nucleus) Sampling:
Nucleus Sampling(核采样),也被称为Top-p Sampling旨在在保持生成文本质量的同时增加多样性。这种方法可以视作是Top-K Sampling的一种变体,它在每个时间步根据模型输出的概率分布选择概率累积超过给定阈值p的词语集合,然后在这个词语集合中进行随机采样。这种方法会动态调整候选词语的数量,以保持一定的文本多样性。

在Nucleus Sampling中,模型在每个时间步生成词语时,首先按照概率从高到低对词汇表中的所有词语进行排序,然后模型计算累积概率,并找到累积概率超过给定阈值p的最小词语子集,这个子集就是所谓的“核”(nucleus)。模型在这个核中进行随机采样,根据词语的概率分布来选择最终输出的词语。这样做可以保证所选词语的总概率超过了阈值p,同时也保持了一定的多样性。
参数p是Nucleus Sampling中的重要参数,它决定了所选词语的概率总和。p的值会被设置在(0,1]之间,表示词语总概率的一个下界。
Nucleus Sampling 能够保持一定的生成质量,因为它在一定程度上考虑了概率分布。通过选择概率总和超过给定阈值p的词语子集进行随机采样,Nucleus Sampling 能够增加生成文本的多样性。
def top_p_sampling(input_ids, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text总结
自然语言生成任务中,采样方法是非常重要的。选择合适的采样方法可以在一定程度上影响生成文本的质量、多样性和效率。上面介绍的几种采样方法各有特点,适用于不同的应用场景和需求。
贪婪解码是一种简单直接的方法,适用于速度要求较高的情况,但可能导致生成文本缺乏多样性。束搜索通过保留多个候选序列来克服贪婪解码的局部最优问题,生成的文本质量更高,但计算开销较大。Top-K 采样和核采样可以控制生成文本的多样性,适用于需要平衡质量和多样性的场景。温度参数采样则可以根据温度参数灵活调节生成文本的多样性,适用于需要平衡多样性和质量的任务。
위 내용은 자연어 생성 작업의 5가지 샘플링 방법 및 Pytorch 코드 구현 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!