
61초만에 리눅스의 상태를 파악해보세요!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-14 10:45:021377검색
모든 프로그램의 기초로서 운영 체제는 애플리케이션 성능에 중요한 영향을 미칩니다. 그러나 컴퓨터의 다양한 구성 요소 간의 속도 차이는 매우 큽니다. 예를 들어 CPU와 하드 드라이브의 속도 차이는 토끼와 거북이의 속도 차이보다 큽니다.
아래에서는 CPU, 메모리, I/O의 기본을 간략하게 소개하고 성능을 평가할 수 있는 몇 가지 명령어를 소개하겠습니다.
1.CPU
먼저 컴퓨터에서 가장 중요한 컴퓨팅 구성 요소인 중앙 처리 장치를 소개합니다. 일반적으로 top 명령을 통해 성능을 관찰할 수 있습니다.
1.1 최고 명령
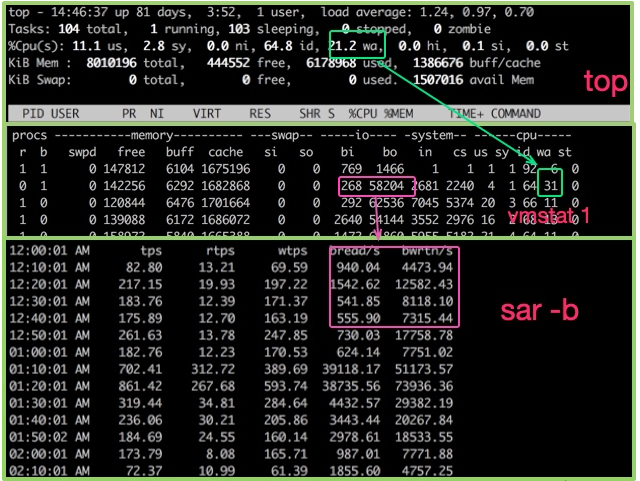
top命令可用于观测CPU的一些运行指标。如图,进入top命令之后,按1 키를 클릭하면 각 코어 CPU의 자세한 상태를 볼 수 있습니다.
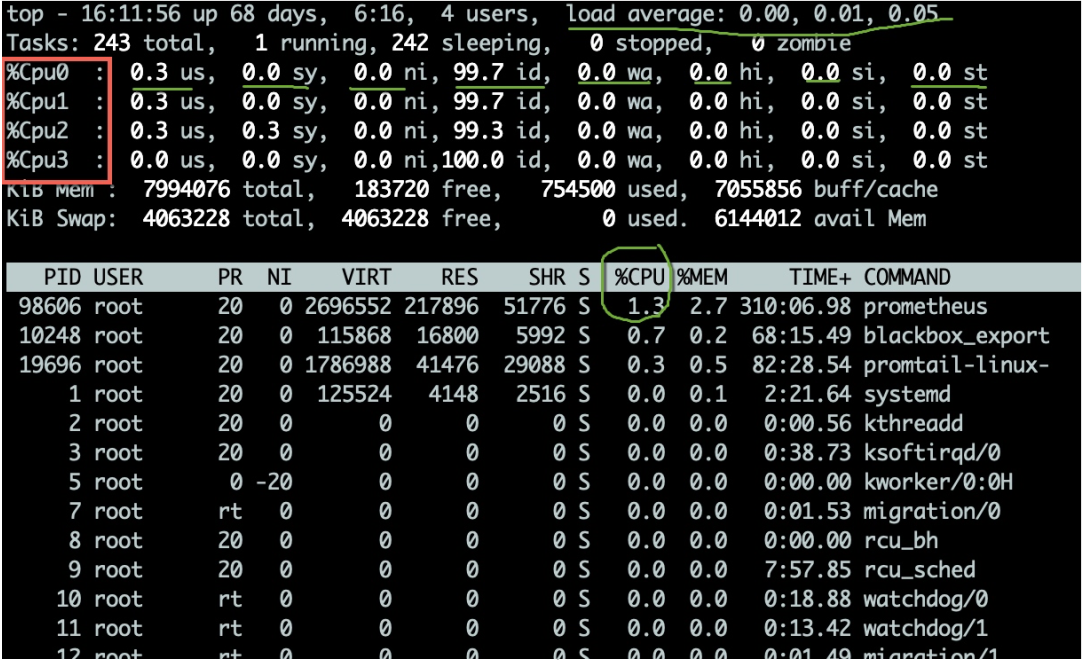
CPU 사용량에는 여러 가지 표시기가 있으며 아래에 설명되어 있습니다.
- us 사용자 모드에서 차지하는 CPU 비율입니다.
- sy 커널 모드가 차지하는 CPU 비율입니다. 이 값이 너무 높으면 vmstat 명령과 협력하여 컨텍스트 전환이 빈번한지 확인해야 합니다.
- ni 우선순위가 높은 애플리케이션이 차지하는 CPU 비율입니다.
- wa I/O 장치를 기다리는 동안 CPU가 차지하는 비율입니다. 이 값이 너무 높으면 입출력 장치에 심각한 병목 현상이 발생할 수 있습니다.
- hi 하드웨어 인터럽트가 차지하는 CPU 비율입니다.
- si 소프트 인터럽트가 차지하는 CPU 비율입니다.
- st 이는 일반적으로 가상 머신에서 발생하며 가상 CPU가 실제 CPU를 기다리는 시간의 비율을 나타냅니다. 이 값이 너무 크면 호스트에 너무 많은 압력이 가해질 수 있습니다. 클라우드 호스트인 경우 서비스 제공업체가 지나치게 판매하고 있을 수 있습니다.
- id 유휴 CPU 비율.
일반적으로 전체 CPU 사용률을 반영할 수 있는 유휴 CPU 비율에 더 많은 관심을 기울입니다.
1.2 로드란 무엇인가요
또한 CPU 작업 실행의 대기열 상황을 평가해야 하며, 이러한 값은 负载(load)입니다. top 명령으로 표시되는 CPU 로드는 각각 지난 1분, 5분, 15분의 값입니다.
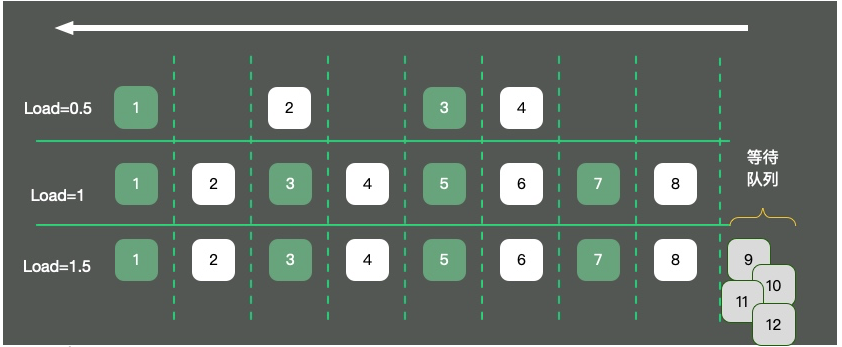
그림에 표시된 것처럼 단일 코어 운영 체제를 예로 들면 CPU 리소스는 단방향 도로로 추상화됩니다. 세 가지 상황이 발생합니다:
-
도로에 자동차가
4만 있고 교통도 원활하며 하중은 0.5 정도입니다. - 도로에는 8대의 차량이 있어 끝까지 안전하게 통과할 수 있습니다. 이때 하중은 약 1대입니다.
- 도로에는 12대의 차량이 있으며 도로 밖에는 4대의 차량이 대기하고 있어 줄을 서야 합니다. 이때 부하는 1.5 정도이다.
로드 1은 무엇을 의미하나요? 이 문제에 대해서는 아직도 많은 오해가 있습니다.
많은 학생들은 로드가 1에 도달하면 시스템이 병목 현상에 도달한다고 생각합니다. 이는 전적으로 정확하지 않습니다. 로드 값은 CPU 코어 수와 밀접한 관련이 있습니다. 예는 다음과 같습니다:
- 단일 코어의 부하는 1에 도달하고 총 부하 값은 약 1입니다.
- 듀얼 코어의 각 코어에 대한 부하는 1에 도달하고, 총 부하는 약 2입니다.
- 4개 코어 각각의 로드는 1이며, 총 로드는 약 4입니다.
따라서 로드가 10인 16코어 머신의 경우 시스템이 로드 제한에 도달하기에는 아직 멀었습니다. uptime 명령을 통해 로드 상태도 확인할 수 있습니다.
1.3 vmstat
CPU 사용량을 확인하려면 vmstat 명령을 사용할 수도 있습니다. 다음은 vmstat 명령의 일부 출력 정보입니다.
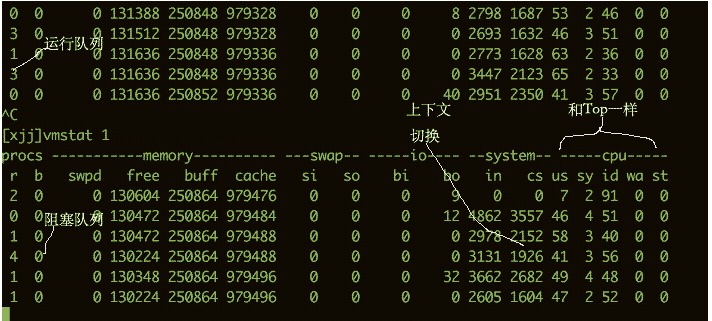
다음 열에 대해 더 우려하고 있습니다.
-
bI/O 대기 등 대기 큐에 존재하는 커널 스레드 수 숫자가 너무 크면 CPU 사용량이 너무 많아집니다. -
cs는 컨텍스트 전환 횟수를 나타냅니다. 컨텍스트 전환이 자주 수행된다면 스레드 수가 너무 많은지 고려해야 합니다. -
si/so스왑 파티션의 일부 사용법은 성능에 더 큰 영향을 미치며 특별한 주의가 필요함을 보여줍니다.
2. 추억
2.1 관찰 명령
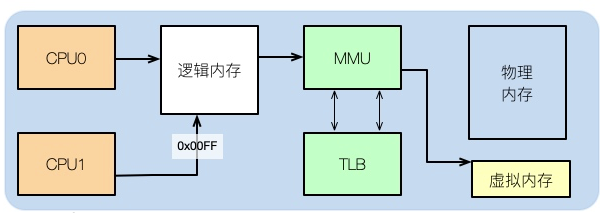
메모리가 성능에 미치는 영향을 이해하려면 운영 체제 수준에서 메모리 분포를 살펴봐야 합니다.
코드 작성을 마친 후, 예를 들어 C++ 프로그램을 작성하고 해당 어셈블리를 보면 그 안에 있는 메모리 주소가 실제 물리적 메모리 주소가 아니라는 것을 알 수 있습니다.
그럼 응용프로그램이 사용하는 것은 논리기억입니다. 컴퓨터의 구조를 공부해본 학생들은 다 알죠.
논리 주소는 물리적 메모리와 가상 메모리에 매핑될 수 있습니다. 예를 들어 실제 메모리가 8GB이고 16GB SWAP 파티션이 할당된 경우 애플리케이션에 사용할 수 있는 총 메모리는 24GB입니다.
상위 명령에서 여러 열의 데이터를 볼 수 있습니다. 사각형으로 둘러싸인 세 영역에 주의하세요.
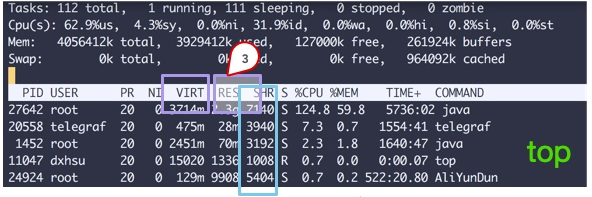
- VIRT 이는 가상 메모리로 일반적으로 상대적으로 크기가 크므로 크게 주의할 필요는 없습니다.
- RES 우리가 일반적으로 주목하는 것은 프로세스가 실제로 차지하는 메모리를 나타내는 이 열의 값입니다. 보통 모니터링을 할 때 이 값을 주로 모니터링합니다.
- SHR은 재사용이 가능한 일부 so 파일과 같은 공유 메모리를 의미합니다.
2.2 CPU 캐시
CPU 코어와 메모리의 속도 차이가 매우 크기 때문에 해결책은 캐시를 추가하는 것입니다. 실제로 이러한 캐시에는 아래 그림과 같이 여러 레이어가 있는 경우가 많습니다.
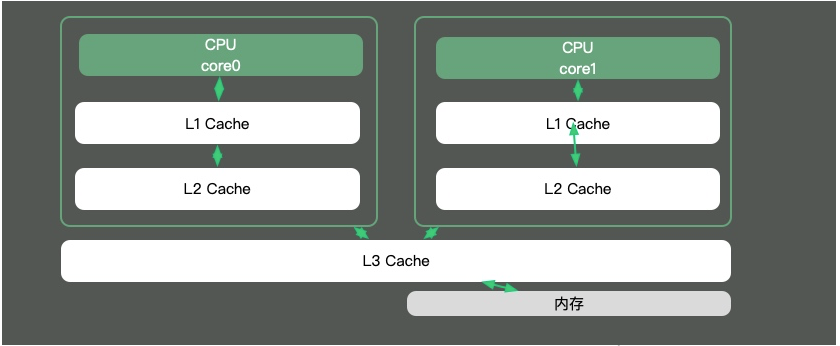
Java의 대부분의 지식 포인트는 멀티스레딩에 관한 것입니다. 이는 스레드의 시간 조각이 여러 CPU에 걸쳐 있으면 동기화 문제가 발생하기 때문입니다.
在Java中,最典型的和CPU缓存相关的知识点,就是并发编程中,针对Cache line的伪共享(false sharing)问题。
伪共享是指:在这些高速缓存中,是以缓存行为单位进行存储的。哪怕你修改了缓存行中一个很小很小的数据,它都会整个的刷新。所以,当多线程修改一些变量的值时,如果这些变量在同一个缓存行里,就会造成频繁刷新,无意中影响彼此的性能。
通过以下命令即可看到当前操作系统的缓存行大小。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
通过以下命令可以看到不同层次的缓存大小。
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/size 32K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/size 256K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/size 20480K
在JDK8以上的版本,通过开启参数-XX:-RestrictContended,就可以使用注解@sun.misc.Contended进行补齐,来避免伪共享的问题。在并发优化中,我们再详细讲解。
2.3 HugePage
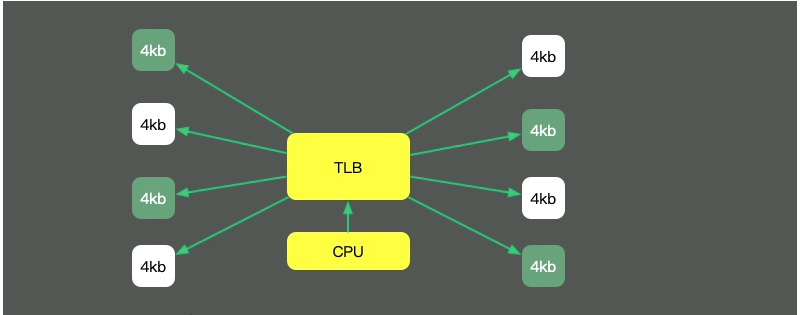
回头看我们最长的那副图,上面有一个叫做TLB的组件,它的速度虽然高,但容量也是有限的。这就意味着,如果物理内存很大,那么映射表的条目将会非常多,会影响CPU的检索效率。
默认内存是以4K的page来管理的。如图,为了减少映射表的条目,可采取的办法只有增加页的尺寸。像这种将Page Size加大的技术,就是Huge Page。
HugePage有一些副作用,比如竞争加剧,Redis还有专门的研究(https://redis.io/topics/latency) ,但在一些大内存的机器上,开启后会一定程度上增加性能。
2.4 预先加载
另外,一些程序的默认行为,也会对性能有所影响。比如JVM的-XX:+AlwaysPreTouch参数。默认情况下,JVM虽然配置了Xmx、Xms等参数,但它的内存在真正用到时,才会分配。
但如果加上这个参数,JVM就会在启动的时候,把所有的内存预先分配。这样,启动时虽然慢了些,但运行时的性能会增加。
3.I/O
3.1 观测命令
I/O设备可能是计算机里速度最差的组件了。它指的不仅仅是硬盘,还包括外围的所有设备。
硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,仅作参考)。
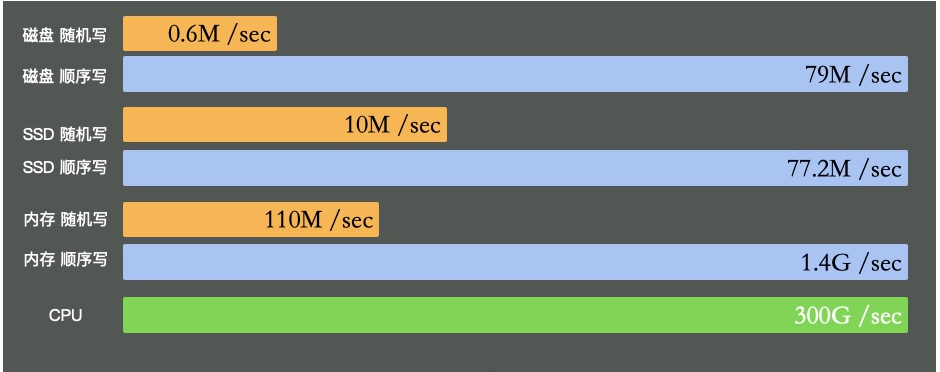
可以看到普通磁盘的随机写和顺序写相差是非常大的。而随机写完全和cpu内存不在一个数量级。
缓冲区依然是解决速度差异的唯一工具,在极端情况比如断电等,就产生了太多的不确定性。这些缓冲区,都容易丢。
I/O의 분주함을 반영하는 가장 좋은 방법은 top 명령과 vmstat命令中的wa%입니다. 애플리케이션이 많은 로그를 작성하는 경우 I/O 대기 시간이 매우 높을 수 있습니다.
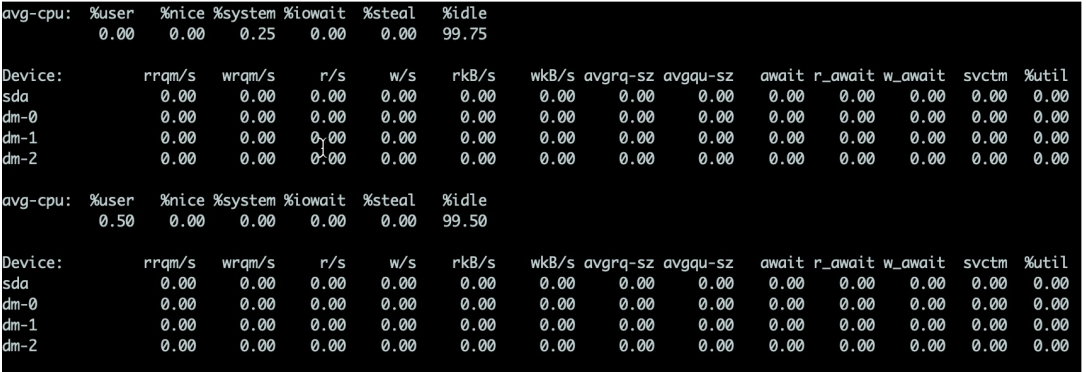
하드 드라이브의 경우 iostat 명령을 사용하여 특정 하드웨어 사용량을 볼 수 있습니다. %util이 80%를 초과하는 한 시스템은 기본적으로 실행될 수 없습니다.
자세한 내용은 다음과 같습니다.
- %util 가장 중요한 판단 매개변수입니다. 일반적으로 이 매개변수가 100%이면 장비가 최대 용량에 가깝게 작동하고 있음을 의미합니다
- Device는 이벤트가 발생한 하드 드라이브를 나타냅니다. 얼마나 빠르면 여러 줄이 표시됩니다
- avgqu-sz 이 값은 요청 큐의 포화도, 즉 평균 요청 큐 길이입니다. 대기열 길이가 짧을수록 좋다는 것은 의심의 여지가 없습니다.
- await 응답 시간은 5ms 미만이어야 하며, 10ms보다 크면 더 커집니다. 이 시간에는 대기열 시간과 서비스 시간이 포함됩니다
-
svctm은 장치
I/O操作的服务时间。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O의 시간당 평균 대기열 대기 시간이 너무 길어서 시스템에서 실행 중인 애플리케이션이 느려지는 것을 의미합니다.
3.2 제로 카피
kafka가 더 빠른 이유 중 하나는 zero copy를 사용하기 때문입니다. 소위 제로 복사(Zero copy)는 데이터를 조작할 때 한 메모리 영역에서 다른 메모리 영역으로 데이터 버퍼를 복사할 필요가 없음을 의미합니다. 메모리 복사본이 하나 줄어들기 때문에 CPU 효율성이 향상됩니다.
그들 사이의 차이점을 살펴보겠습니다:
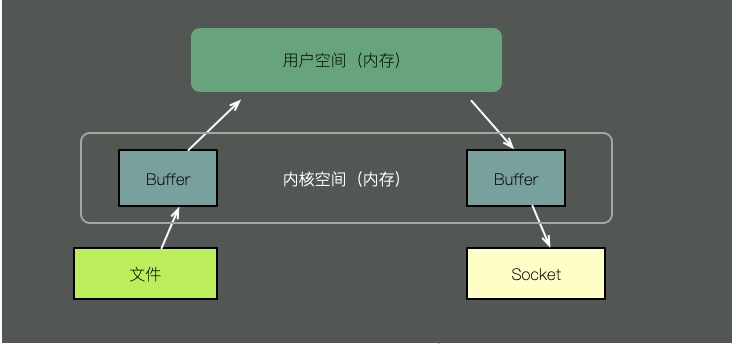
소켓을 통해 파일 내용을 보내려면 기존 방법에 다음 단계가 필요합니다.
- 파일 내용을 커널 공간에 복사합니다.
- 커널 공간의 내용을 Java 애플리케이션과 같은 사용자 공간 메모리에 복사합니다.
- 사용자 공간은 커널 공간 캐시에 콘텐츠를 씁니다.
- 소켓은 커널 캐시의 내용을 읽고 이를 전송합니다.
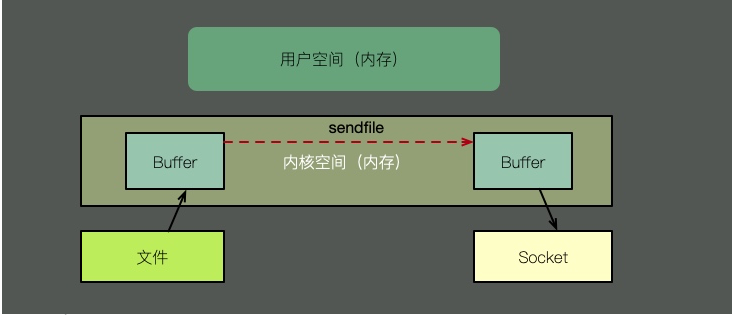
제로 복사 및 다중 모드를 설명하기 위해 sendfile을 사용하겠습니다. 위 그림에서 볼 수 있듯이 커널의 지원으로 제로 복사는 단계가 하나 줄어들게 되는데, 이는 커널 캐시를 사용자 공간에 복사하는 것입니다. 즉, 메모리와 CPU 스케줄링 시간을 절약하므로 매우 효율적입니다.
4.网络
除了iotop、iostat这些命令外,sar命令可以方便的看到网络运行状况,下面是一个简单的示例,用于描述入网流量和出网流量。
$ sar -n DEV 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00 12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00 12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00 12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00 12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ^C
当然,我们可以选择性的只看TCP的一些状态。
$ sar -n TCP,ETCP 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:17:19 AM active/s passive/s iseg/s oseg/s 12:17:20 AM 1.00 0.00 10233.00 18846.00 12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:20 AM 0.00 0.00 0.00 0.00 0.00 12:17:20 AM active/s passive/s iseg/s oseg/s 12:17:21 AM 1.00 0.00 8359.00 6039.00 12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:21 AM 0.00 0.00 0.00 0.00 0.00 ^C
5.End
不要寄希望于这些指标,能够立刻帮助我们定位性能问题。这些工具,只能够帮我们大体猜测发生问题的地方,它对性能问题的定位,只是起到辅助作用。想要分析这些bottleneck,需要收集更多的信息。
想要获取更多的性能数据,就不得不借助更加专业的工具,比如基于eBPF的BCC工具,这些牛x的工具我们将在其他文章里展开。读完本文,希望你能够快速的了解Linux的运行状态,对你的系统多一些掌控。
위 내용은 61초만에 리눅스의 상태를 파악해보세요!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!