
하위 쿼리에서 MySQL의 '구덩이'를 밟아야 한다는 것을 기억하십시오.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-13 18:12:27903검색
MySQL은 프로젝트에서 흔히 사용되는 데이터베이스이고, 쿼리에서도 매우 흔히 사용됩니다. 최근 프로젝트 디버깅 중에 예상치 못한 선택 쿼리가 발생했는데 실제로는 33초가 걸렸습니다!
1. 사용자 정보 테이블

2. 기사 테이블
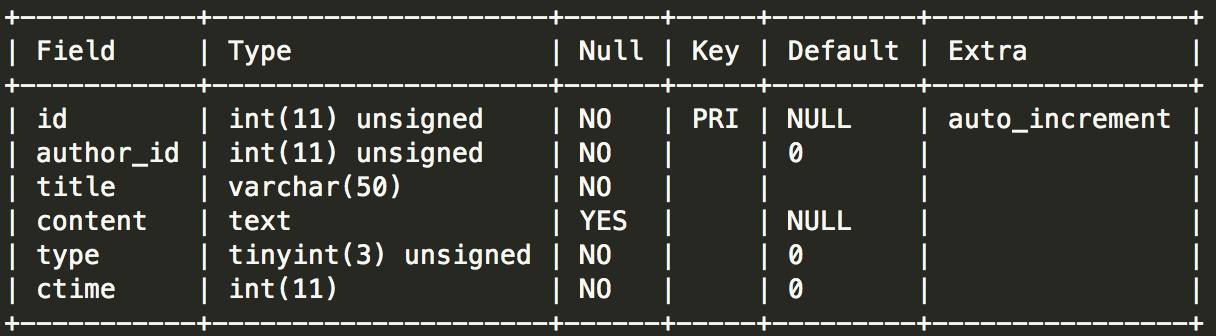
위 SQL을 처음 보시면 매우 간단한 서브쿼리라고 생각하실 수도 있습니다. 먼저 작성자 ID를 찾은 다음 in을 사용하여 쿼리합니다.
해당 색인이 있으면 분해가 매우 빠릅니다.
으아악하지만 사실은 이렇습니다:
으아악


33초! 왜 이렇게 느린가요?
공식 문서 설명: in 절은 쿼리 시 존재로 변환되는 경우가 있으며, 레코드 단위로 순회됩니다(버전 5.5에 존재, 5.6에 최적화됨).

참조:
https://dev.mysql.com/doc/refman/5.5/en/subquery-optimization.html
1. 임시 테이블을 사용하세요
으아악
2. Join
을 사용하세요. 으아악
버전 5.6은 하위 쿼리에 최적화되었습니다. 방법은 [4]의 임시 테이블 방법과 동일합니다.
구체화를 사용하지 않는 경우 최적화 프로그램은 때때로 상관되지 않은 하위 쿼리를 상관된 하위 쿼리로 다시 작성합니다.
예를 들어 다음 IN 하위 쿼리는 상관 관계가 없습니다(where_condition은 t1이 아닌 t2의 열만 포함함).
t1에서 *를 선택하세요
where t1.a in (t2 where where_condition에서 t2.b 선택);
최적화 프로그램은 이를 EXISTS 상관 하위 쿼리로 다시 작성할 수 있습니다.:
t1에서 *를 선택하세요
존재하는 곳(where_condition 및 t1.a=t2.b인 t2에서 t2.b 선택);
하위 쿼리 구체화 임시 테이블을 사용하면 이러한 재작성을 방지하고 외부 쿼리의 행당 한 번이 아닌 한 번만 하위 쿼리를 실행할 수 있습니다.
https://dev.mysql.com/doc/refman/5.6/en/subquery-materialization.html
기사는 WeChat 공개 계정에서 가져온 것입니다: HULK 최전선 기술 회담
위 내용은 하위 쿼리에서 MySQL의 '구덩이'를 밟아야 한다는 것을 기억하십시오.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!