
리눅스 메모리 관리: 가상 메모리와 물리 메모리를 변환하고 할당하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-10 17:24:261392검색
Linux 시스템에서 메모리 관리는 운영 체제의 가장 중요한 부분 중 하나입니다. 제한된 물리적 메모리를 여러 프로세스에 할당하고 각 프로세스가 고유한 주소 공간을 가지며 메모리를 보호하고 공유할 수 있도록 가상 메모리의 추상화를 제공하는 역할을 담당합니다. 본 글에서는 가상 메모리, 물리 메모리, 논리 메모리, 선형 메모리 등의 개념을 비롯해 리눅스 메모리 관리의 기본 모델, 시스템 호출, 구현 방법 등 리눅스 메모리 관리의 원리와 방법을 소개한다.
이 기사는 32비트 시스템을 기반으로 하며 메모리 관리에 대한 몇 가지 지식 포인트에 대해 설명합니다.
1. 가상 주소, 물리적 주소, 논리 주소, 선형 주소
가상 주소는 선형 주소라고도 합니다. Linux는 분할 메커니즘을 사용하지 않으므로 논리 주소와 가상 주소(선형 주소)(사용자 모드에서 커널 모드 논리 주소는 구체적으로 아래 언급된 선형 오프셋 이전의 주소를 나타냄)는 동일한 개념입니다. 실제 주소는 언급할 필요가 없습니다. 커널의 가상 주소와 물리적 주소의 대부분은 선형 오프셋만 다릅니다. 사용자 공간의 가상 주소와 물리적 주소는 다단계 페이지 테이블을 사용하여 매핑되지만 여전히 선형 주소라고 합니다.
2. DMA/HIGH_MEM/NROMAL 파티션
x86 구조에서 Linux 커널 가상 주소 공간은 사용자 공간인 0~3G와 커널 공간인 3~4G로 구분됩니다(커널이 사용할 수 있는 선형 주소는 1G뿐입니다). 커널 가상 공간(3G~4G)은 세 가지 유형의 영역으로 구분됩니다.
ZONE_DMA는 3G 이후 16MB부터 시작됩니다
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~1G
커널의 가상 주소와 물리적 주소는 하나의 오프셋만 다르기 때문에: 물리적 주소 = 논리 주소 – 0xC0000000. 따라서 1G 커널 공간이 선형 매핑에 완전히 사용된다면 물리적 메모리는 분명히 1G 범위에만 액세스할 수 있으며 이는 분명히 불합리합니다. HIGHMEM은 이 문제를 해결하기 위해 선형 매핑이 필요하지 않은 영역을 특별히 개방했으며, 1G 이상의 물리적 메모리 영역에 접근할 수 있도록 유연하게 맞춤화할 수 있습니다. 인터넷에서 사진을 캡쳐했어요
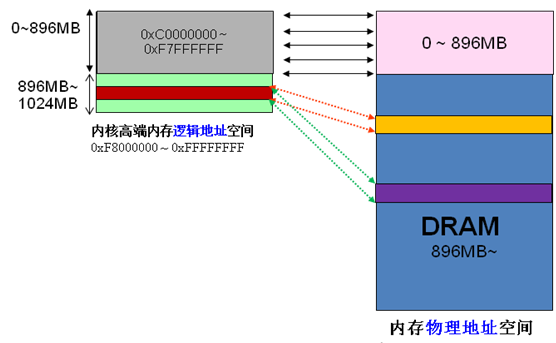
하이엔드 메모리의 구분은 아래와 같습니다,
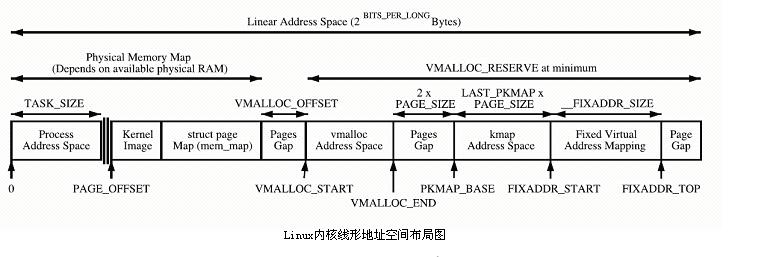
커널은 PAGE_OFFSET~VMALLOC_START 공간을 직접 매핑하고 kmalloc 및 __get_free_page()는 여기에 페이지를 할당합니다. 둘 다 슬랩 할당자를 사용하여 물리적 페이지를 직접 할당한 다음 이를 논리적 주소(물리적 주소는 연속적임)로 변환합니다. 작은 메모리 세그먼트를 할당하는 데 적합합니다. 이 영역에는 커널 이미지 및 물리적 페이지 프레임 테이블 mem_map과 같은 리소스가 포함되어 있습니다.
vmalloc에서 사용하는 커널 동적 매핑 공간 VMALLOC_START~VMALLOC_END은 표현 가능한 공간이 큽니다.
커널 영구 매핑 공간 PKMAP_BASE ~ FIXADDR_START, kmap
커널 임시 매핑 공간 FIXADDR_START~FIXADDR_TOP, kmap_atomic
3. 파트너 알고리즘 및 슬랩 할당자
Buddy 알고리즘은 외부 조각화 문제를 해결합니다. 커널은 각 영역에서 사용 가능한 페이지를 관리하고 이를 2(순서) 크기에 따라 연결 목록 대기열로 정렬하고 free_area 배열에 저장합니다.
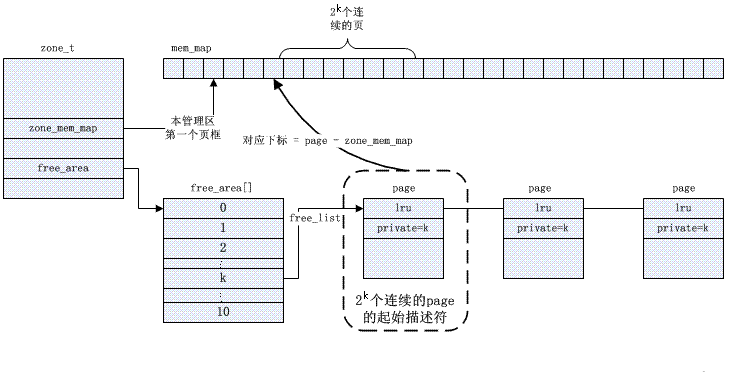
특정 버디 관리는 비트맵을 기반으로 하며 페이지 할당 및 재활용 알고리즘은 아래에 설명되어 있습니다.
버디 알고리즘 예시 설명:
시스템 메모리에 ***16*****페이지*****RAM*만 있다고 가정해 보겠습니다. RAM에는 16페이지만 있으므로 파트너 비트맵의 4단계(순서)만 사용하면 됩니다(최대 연속 메모리 크기는 ******16******** 페이지***이므로). 아래에 표시됩니다.
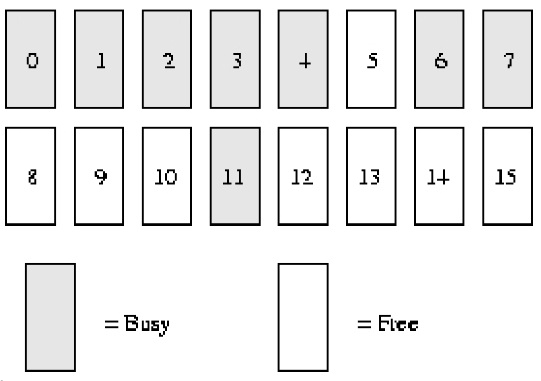

order(0) bimap에는 8비트가 있습니다(*** 페이지는 최대 ******16******** 페이지를 가질 수 있으므로 ******16/2***)
order(1) bimap에는 4비트가 있습니다(***order******(******0******)******bimap***** 있습니다. ****8******** ******비트****** 비트***, 즉 8/2);
즉, 순서(1)의 첫 번째 블록은 *** 두 개의 페이지 프레임 ****page1* *** 및 ******page2*****로 구성되며 *로 구성됩니다. order (1) 블록 2는 두 개의 페이지 프레임 ****page3* *** 및 ******page4********로 구성되며, 이 둘 사이에 ****가 있습니다. 블록 **bit****bit*
order(2) bimap에는 2비트가 있습니다(***order******(******1******)******bimap***** 있습니다. ******4************비트******자리***, 즉 4/2)
order(3) bimap에는 1비트가 있습니다(***order******(******2******)******bimap***** 있습니다. ******4************비트******자리***, 즉 2/2)
순서(0)에서 첫 번째 비트는 첫 번째 ****2****** 페이지***를 나타내고 두 번째 비트는 다음 2페이지를 나타냅니다. 4페이지가 할당되었고 5페이지는 비어 있으므로 세 번째 비트는 1입니다.
마찬가지로 순서(1)에서 bit3이 1인 이유는 한 파트너는 완전 무료(8 및 9페이지)이지만 해당 파트너(10 및 11페이지)는 그렇지 않기 때문에 향후 페이지를 재활용할 때, 병합될 수 있습니다.
할당 프로세스
*********주문******(******1******)의 무료 페이지 블록이 필요한 경우 *** 다음 단계를 수행합니다.
1. 초기 무료 연결 목록은 다음과 같습니다.
순서(0): 5, 10
주문(1): 8 [8,9]
순서(2): 12 [12,13,14,15]
순서(3):
2. 위의 무료 연결 목록을 보면 주문(1) 연결 목록에 * 무료 페이지 블록이 있는 것을 볼 수 있습니다. 이를 사용자에게 할당하고 연결 목록에서 삭제합니다. *
3. 또 다른 order(1) 블록이 필요할 때 order(1) 무료 목록에서도 스캔을 시작합니다.
4. ***주문******(******1********)에 무료 페이지 블록***이 없으면 더 높은 수준(주문)으로 이동합니다. ) 위에서 찾아 (2)를 주문하세요.
5. 현재(******주문******(******1*****)*에 무료 페이지 블록이 없습니다.) 무료 페이지 블록이 있습니다. 슬레이브 페이지 12가 시작됩니다. 페이지 블록은 두 개의 약간 작은 순서(1) 페이지 블록인 [12, 13] 및 [14, 15]로 분할됩니다. [14, 15] 페이지 블록이 주문******(******1*****) 무료 목록*에 추가되는 동시에 [12 ****** ,******13]****페이지 블록이 사용자에게 반환됩니다. *
6. 최종 무료 링크 목록은 다음과 같습니다.
순서(0): 5, 10
주문(1): 14 [14,15]
순서(2):
순서(3):
재활용 과정
***페이지 ******11******(******주문 0****)을 재활용하는 경우 다음 단계가 수행됩니다. *
***1******, **********주문******(******0******)에서 파트너를 찾았습니다. 그림은 ******11****** 페이지의 **** 비트를 나타내며 계산에는 다음 공개 정보가 사용됩니다. *
*index =* *page_idx >> (순서 + 1)*
*= 11 >> (0 + 1)*
*= 5*
2. 비트맵에서 해당 비트의 값을 계산하려면 위 단계를 확인하세요. 비트 값이 1이면 우리 주변에 유휴 파트너가 있다는 뜻입니다. 파트너 페이지 10이 무료이므로 Bit5의 값은 1입니다(bit0에서 시작하고 Bit5는 6번째 비트입니다).
3. 이제 두 파트너(10페이지 및 11페이지)가 완전히 유휴 상태이므로 이 비트의 값을 0으로 재설정합니다.
4. 주문(0) 무료 목록에서 10페이지를 제거합니다.
5. 이때 무료 페이지 2개(10페이지와 11페이지, 순서 (1))에 대한 추가 작업을 수행합니다.
6. 새로운 무료 페이지는 10페이지부터 시작하므로 order(1)의 파트너 비트맵에서 해당 인덱스를 찾아 추가 병합 작업을 위한 유휴 파트너가 있는지 확인합니다. 1단계에서 계산된 회사를 사용하여 비트 2(숫자 3)를 얻습니다.
7. 파트너 페이지 블록(8페이지 및 9페이지)이 무료이므로 비트 2(order(1) 비트맵)도 1입니다.
8. bit2(order(1) 비트맵)의 값을 재설정한 다음 order(1) 연결 리스트에서 사용 가능한 페이지 블록을 삭제합니다.
9. 이제 4페이지 크기의 무료 블록(8페이지부터 시작)으로 병합하여 다른 레벨로 들어갑니다. (2)번 순서대로 파트너 비트맵에 해당하는 비트값을 찾으면 bit1 이고 값은 1이다. 추가로 merge해야 한다(이유는 위와 동일).
10. oder(2) 링크 목록에서 사용 가능한 페이지 블록(12페이지부터 시작)을 제거한 다음 이 페이지 블록을 이전 병합으로 얻은 페이지 블록과 추가로 병합합니다. 이제 우리는 8페이지부터 시작하여 8페이지 크기의 무료 페이지 블록을 얻습니다.
11. 또 다른 레벨, 주문(3)으로 들어갑니다. 비트 인덱스는 0이고 값도 0입니다. 이는 해당 파트너가 모두 무료가 아니므로 추가 병합 가능성이 없음을 의미합니다. 우리는 이 비트를 1로 설정한 다음 병합된 여유 페이지 블록을 order(3) 자유 연결 목록에 넣습니다.
12. 마침내 8페이지의 무료 블록을 얻었습니다.

내부 잔해물 방지를 위한 버디의 노력
물리적 메모리 조각화는 항상 Linux 운영 체제의 약점 중 하나였습니다. 많은 솔루션이 제안되었지만 메모리 버디 할당은 솔루션 중 하나입니다. 디스크 파일에도 조각화 문제가 있다는 것을 알고 있지만 디스크 파일 조각화는 시스템의 읽기 및 쓰기 속도를 저하시킬 뿐이며 기능적 오류를 일으키지 않습니다. 또한 디스크 기능에 영향을 주지 않고 디스크를 조각화할 수도 있습니다. 정돈하다. 물리적 메모리 조각화는 완전히 다릅니다. 물리적 메모리와 운영 체제가 너무 밀접하게 통합되어 있어 런타임 중에 물리적 메모리를 이동하기가 어렵습니다. (이 시점에서 디스크 조각화는 훨씬 쉽습니다. 실제로 mel gorman은 메모리 압축 패치를 가지고 있습니다. 제출되었지만 아직 메인라인 커널에서 수신되지 않았습니다). 따라서 솔루션 방향은 주로 이물질 방지에 중점을 두고 있습니다. 2.6.24 커널을 개발하는 동안 조각화를 방지하는 커널 기능이 메인라인 커널에 추가되었습니다. 조각화 방지의 기본 원리를 이해하기 전에 먼저 메모리 페이지를 분류하세요.
1. 이동할 수 없는 페이지: 메모리 내 위치는 고정되어 있어야 하며 코어 커널에 의해 할당된 대부분의 페이지가 이 범주에 속합니다.
2. 회수 가능 페이지 회수 가능: 페이지를 특정 소스에서 재구성할 수도 있으므로 재활용할 수 있습니다. 예를 들어 kswapd는 해당 페이지를 주기적으로 재활용합니다. 특정 규칙에 따라.
3. 이동 가능한 페이지 이동 가능: 마음대로 이동할 수 있습니다. 사용자 공간 애플리케이션에 속하는 페이지는 페이지 테이블을 통해 매핑되므로 페이지 테이블 항목을 업데이트하고 데이터를 새 위치에 복사하기만 하면 됩니다. 여러 프로세스 공유에 의해 사용될 수 있습니다. 이는 여러 페이지 테이블 항목에 해당합니다.
조각화를 방지하는 방법은 이 세 가지 유형의 페이지를 서로 다른 연결 목록에 배치하여 서로 다른 유형의 페이지가 서로 간섭하지 않도록 하는 것입니다. 움직일 수 없는 페이지가 이동 가능한 페이지의 중간에 있는 상황을 생각해 보십시오. 이러한 페이지를 이동하거나 재활용한 후에는 이 움직일 수 없는 페이지로 인해 더 큰 연속적인 물리적 여유 공간을 확보할 수 없습니다.
또한 각 영역에는 두 개의 교차 영역 전역 큐, 비활성화된 더티 페이지 큐 및 활성 큐에 해당하는 자체 비활성화된 클린 페이지 큐가 있습니다. 이러한 큐는 페이지 구조의 lru 포인터를 통해 연결됩니다.
생각하기: 비활성화 대기열의 의미는 무엇입니까(
slab 할당자: 내부 조각화 문제 해결
커널은 종종 시스템 수명 동안 여러 번 할당되는 작은 개체 할당에 의존합니다. 슬랩 캐시 할당자는 유사한 크기(1페이지보다 훨씬 작은)의 개체를 캐싱하여 이 기능을 제공하므로 일반적인 내부 조각화 문제를 방지합니다. 다음은 그 원리에 관한 그림입니다. 공통 참고자료 3을 참조하세요. 분명히 슬래브 메커니즘은 버디 알고리즘을 기반으로 하며 전자는 후자를 개선한 것입니다.
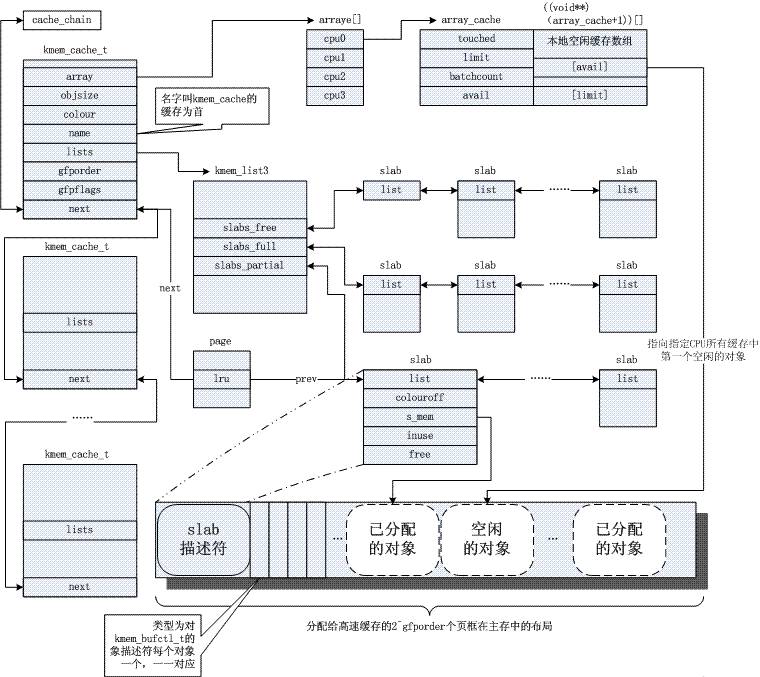
4. 페이지 재활용/초점 메커니즘
정보 페이지 사용하기
이전 기사에서 우리는 Linux 커널이 여러 상황에서 페이지를 할당한다는 것을 배웠습니다.
1. 커널 코드는 alloc_pages와 같은 함수를 호출하여 물리적 페이지(관리 영역의 free_area 여유 목록)를 관리하는 파트너 시스템에서 페이지를 직접 할당할 수 있습니다("Linux 커널 메모리 관리에 대한 간략한 분석" 참조). 예를 들어, 드라이버는 이러한 방식으로 캐시를 할당할 수 있습니다. 프로세스를 생성할 때 커널도 이러한 방식으로 프로세스의 thread_info 구조 및 커널 스택으로 두 개의 연속 페이지를 할당합니다. 파트너 시스템에서 페이지를 할당하는 것이 가장 기본적인 페이지 할당 방법이며, 다른 메모리 할당도 이 방법을 기반으로 합니다.
2. 커널의 많은 개체는 슬랩 메커니즘을 사용하여 관리됩니다("Linux Slub Allocator에 대한 간략한 분석" 참조). Slab은 페이지를 "객체"로 "형식화"하고 사람이 사용할 수 있도록 풀에 저장하는 객체 풀과 동일합니다. 슬래브에 객체가 부족한 경우 슬래브 메커니즘은 자동으로 파트너 시스템에서 페이지를 할당하고 이를 새 객체로 "형식화"합니다.
3. 디스크 캐시("Linux 커널 파일 읽기 및 쓰기에 대한 간략한 분석" 참조) 파일을 읽고 쓸 때 파트너 시스템에서 페이지가 할당되어 디스크 캐시에 사용된 다음 디스크의 파일 데이터가 해당 디스크 캐시 페이지에 로드됩니다.
4. 메모리 매핑. 여기서 소위 메모리 매핑은 실제로 사용자 프로세스에서 사용하기 위해 메모리 페이지를 사용자 공간에 매핑하는 것을 의미합니다. 프로세스의 task_struct->mm 구조의 각 vma는 매핑을 나타내며, 매핑의 실제 구현은 사용자 프로그램이 해당 메모리 주소에 액세스한 후 페이지 폴트 예외로 인해 발생한 페이지가 할당되고 페이지 테이블이 생성되는 것입니다. 업데이트되었습니다("Linux 커널 메모리 관리에 대한 간략한 분석" 참조).
페이지 재활용에 대한 간략한 소개
페이지 할당이 있으면 페이지 재활용이 발생합니다. 페이지 재활용 방법은 대략 두 가지 유형으로 나눌 수 있습니다.
하나는 활성 릴리스입니다. 사용자 프로그램이 malloc 함수를 통해 한번 할당받은 메모리를 free 함수를 통해 해제하는 것처럼, 페이지 사용자는 해당 페이지가 언제 사용될 것인지, 언제 더 이상 필요하지 않은 것인지를 명확히 알 수 있다.
위에서 언급한 처음 두 가지 할당 방법은 일반적으로 커널 프로그램에 의해 적극적으로 릴리스됩니다. 파트너 시스템에서 직접 할당된 페이지의 경우 free_pages와 같은 기능을 사용하여 사용자가 적극적으로 해제합니다. 페이지가 해제된 후에는 kmem_cache_alloc 함수를 사용하여 슬랩에서 할당된 개체도 파트너 시스템으로 직접 해제됩니다. 사용자에 의해 해제되었습니다(kmem_cache_free 함수 사용).
페이지 재활용의 또 다른 방법은 Linux 커널에서 제공하는 PFRA(페이지 프레임 재활용 알고리즘)를 이용하는 것입니다. 페이지 사용자는 일반적으로 시스템의 운영 효율성을 높이기 위해 페이지를 일종의 캐시로 취급합니다. 캐시는 항상 존재하면 좋지만, 캐시가 없어져도 오류가 발생하지 않고 효율성만 영향을 받습니다. 페이지 사용자는 캐시된 페이지가 언제 가장 잘 보관되는지, 언제 재활용되는 것이 가장 좋은지 명확하게 알지 못하며, 이는 PFRA에 맡겨져 처리됩니다.
간단히 말해서, PFRA가 해야 할 일은 재활용 가능한 페이지를 재활용하는 것입니다. 시스템의 페이지 부족을 방지하기 위해 커널 스레드에서 PFRA가 주기적으로 호출됩니다. 또는 시스템에 이미 페이지가 부족하기 때문에 페이지를 할당하려는 커널 실행 프로세스가 필요한 페이지를 얻을 수 없고 PFRA를 동기적으로 호출합니다.
PFRA 재활용 일반 페이지
위에서 언급한 처음 두 페이지 할당 방법(직접 페이지 할당 및 슬랩을 통한 객체 할당)의 경우 PFRA를 통해 재활용해야 할 수도 있습니다.
페이지 사용자는 PFRA에 콜백 함수를 등록할 수 있습니다(register_shrink 함수 사용). 그런 다음 이러한 콜백 함수는 적절한 시간에 PFRA에 의해 호출되어 해당 페이지 또는 개체의 재활용을 트리거합니다.
가장 대표적인 것 중 하나가 덴트리의 재활용이다. Dentry는 slab에서 할당한 객체로, 가상 파일 시스템의 디렉토리 구조를 표현하는데 사용됩니다. dentry의 참조 횟수가 0으로 줄어들면 dentry가 직접 해제되지 않고 이후 사용을 위해 LRU 연결 목록에 캐시됩니다. ("Linux 커널 가상 파일 시스템에 대한 간략한 분석"을 참조하십시오.)
이 LRU 연결 리스트의 dentry는 결국 재활용되어야 하므로 가상 파일 시스템이 초기화되면 Register_shrinker가 호출되어 재활용 함수shrink_dcache_memory를 등록합니다.
시스템의 모든 파일 시스템의 슈퍼블록 객체는 연결된 목록에 저장됩니다.shrink_dcache_memory 함수는 이 연결된 목록을 스캔하고 각 슈퍼블록의 사용되지 않은 덴트리의 LRU를 얻은 다음 여기에서 가장 오래된 덴트리 중 일부를 회수합니다. dentry가 해제되면 해당 inode가 참조 취소되고 이로 인해 inode가 해제될 수도 있습니다.
inode가 해제된 후에는 초기화 중에 사용되지 않는 연결 목록에도 배치됩니다. 가상 파일 시스템은 또한 이러한 사용되지 않는 inode를 재활용하기 위해 콜백 함수shrink_icache_memory를 등록하기 위해register_shrinker를 호출합니다. 출시된.
또한 시스템이 실행됨에 따라 슬래브에 유휴 객체가 많이 있을 수 있습니다(예: 특정 객체의 최대 사용량이 지난 후). PFRA의 캐시_reap 기능은 이러한 중복 유휴 개체를 재활용하는 데 사용됩니다. 일부 유휴 개체를 페이지에 복원할 수 있으면 해당 페이지를 파트너 시스템으로 다시 해제할 수 있습니다.
캐시_reap 함수가 하는 일은 간단합니다. 시스템의 객체 풀을 저장하는 모든 kmem_cache 구조는 연결 목록으로 연결됩니다. 캐시_reap 함수는 각 객체 풀을 검색한 다음 재활용할 수 있는 페이지를 찾아 재활용합니다. (물론 실제 과정은 좀 더 복잡합니다.)
메모리 매핑 정보
앞서 언급했듯이 디스크 캐시와 메모리 매핑은 일반적으로 PFRA에 의해 재활용됩니다. PFRA의 두 가지 재활용은 실제로 디스크 캐시가 사용자 공간에 매핑될 가능성이 매우 높습니다. 다음은 메모리 매핑에 대한 간략한 소개입니다:
파일 매핑은 이 매핑을 나타내는 vma가 파일의 특정 영역에 해당함을 의미합니다. 이 매핑 방법은 사용자 모드 프로그램에서 명시적으로 사용되는 경우가 상대적으로 거의 없습니다. 사용자 모드 프로그램은 일반적으로 파일을 연 다음 파일을 읽고 쓰는 데 익숙합니다.
실제로 사용자 프로그램은 mmap 시스템 호출을 사용하여 파일의 특정 부분을 메모리(vma에 해당)에 매핑한 다음 메모리에 액세스하여 파일을 읽고 쓸 수도 있습니다. 사용자 프로그램이 이 방법을 거의 사용하지 않지만 사용자 프로세스는 이러한 매핑으로 가득 차 있습니다. 즉, 프로세스에서 실행되는 실행 코드(실행 파일 및 lib 라이브러리 파일 포함)가 이러한 방식으로 매핑됩니다.
"Linux 커널 파일 읽기 및 쓰기에 대한 간략한 분석" 기사에서는 파일 매핑 구현에 대해 논의하지 않았습니다. 실제로 파일 매핑은 파일의 디스크 캐시에 있는 페이지를 사용자 공간에 직접 매핑하고(파일이 매핑한 페이지는 디스크 캐시 페이지의 하위 집합임을 알 수 있음), 사용자는 이를 0으로 읽고 쓸 수 있다. 사본. 읽기/쓰기를 사용하면 사용자 공간 메모리와 디스크 캐시 사이에 복사가 발생합니다.
익명 매핑은 파일 매핑과 관련이 있습니다. 즉, 이 매핑의 vma가 파일과 일치하지 않음을 의미합니다. 사용자 공간(힙 공간, 스택 공간)의 일반적인 메모리 할당의 경우 모두 익명 매핑에 속합니다.
분명히 여러 프로세스가 자체 파일 매핑을 통해 동일한 파일에 매핑될 수 있습니다. 예를 들어 대부분의 프로세스는 libc 라이브러리의 so 파일을 매핑합니다. 실제로 여러 프로세스가 자체 익명 매핑을 통해 동일한 물리적 메모리에 매핑될 수 있습니다. 이러한 상황은 포크 후 원래 물리적 메모리(쓰기 시 복사)를 공유하는 상위-하위 프로세스로 인해 발생합니다.
어떤 페이지를 재활용해야 합니까?
재활용의 경우 디스크 캐시 페이지(파일 매핑 페이지 포함)를 폐기하고 재활용할 수 있습니다. 그러나 페이지가 더러워지면 삭제하기 전에 디스크에 다시 기록해야 합니다.
익명 매핑 페이지는 페이지에 사용자 프로그램에서 사용 중인 데이터가 포함되어 있고 삭제된 데이터를 복원할 수 없기 때문에 삭제할 수 없습니다. 반면, 디스크 캐시 페이지의 데이터 자체는 디스크에 저장되어 재생이 가능합니다.
따라서 익명으로 매핑된 페이지를 재활용하려면 먼저 페이지의 데이터를 디스크에 덤프해야 합니다. 이것이 페이지 스왑(swap)입니다. 분명히 페이지 교환 비용은 상대적으로 높습니다.
익명으로 매핑된 페이지는 디스크의 스왑 파일이나 스왑 파티션으로 스왑될 수 있습니다(파티션은 장치이고 장치도 파일이므로 이하에서는 스왑 파일이라고 통칭합니다).
재활용할 수 있는 페이지가 많지만 PFRA가 재활용/스왑을 가능한 한 적게 해야 한다는 것은 분명합니다(이러한 페이지는 디스크에서 복원해야 하며 많은 비용이 필요하기 때문입니다). 따라서 PFRA는 거의 사용되지 않는 페이지 중 필요할 때만 일부만 회수/교환하며, 매번 회수되는 페이지 수는 실증적인 값인 32개이다.
그래서 이러한 모든 디스크 캐시 페이지와 익명 매핑 페이지는 LRU 세트에 배치됩니다. (실제로 각 zone에는 이러한 LRU 세트가 있고 페이지는 해당 zone의 LRU에 배치됩니다.)
LRU 그룹은 디스크 캐시 페이지(파일 매핑 페이지 포함)의 링크 목록, 익명 매핑 페이지의 링크 목록 등을 포함하여 여러 쌍의 링크 목록으로 구성됩니다. 연결된 목록 쌍은 실제로 두 개의 연결된 목록입니다: 활성 및 비활성 전자는 최근에 사용된 페이지이고 후자는 최근에 사용되지 않은 페이지입니다.
페이지를 재활용할 때 PFRA는 두 가지 작업을 수행해야 합니다. 하나는 활성 연결 목록에서 가장 최근에 사용된 페이지를 비활성 연결 목록으로 이동하는 것입니다. 다른 하나는 비활성 연결 목록에서 가장 최근에 사용된 페이지를 재활용하려고 시도하는 것입니다.
최근에 가장 적게 사용한 항목을 확인하세요
이제 질문이 있습니다. 활성/비활성 목록에서 가장 최근에 사용된 페이지를 확인하는 방법은 무엇입니까?
한 가지 접근 방식은 정렬하는 것입니다. 페이지에 액세스하면 해당 페이지를 연결된 목록의 끝 부분으로 이동합니다(재활용이 머리 부분에서 시작된다고 가정). 그러나 이는 연결된 목록의 페이지 위치가 자주 이동할 수 있으며 이동하기 전에 페이지를 잠가야 함을 의미합니다(동시에 액세스하는 여러 CPU가 있을 수 있음). 이는 효율성에 큰 영향을 미칩니다.
리눅스 커널은 표시 및 주문 방법을 채택합니다. 페이지가 활성 및 비활성 연결 목록 사이를 이동할 때 항상 연결 목록의 끝에 배치됩니다(위와 동일, 재활용이 헤드에서 시작된다고 가정).
연결된 목록 간에 페이지가 이동되지 않으면 순서가 조정되지 않습니다. 대신, 액세스 태그는 페이지에 방금 액세스되었는지 여부를 나타내는 데 사용됩니다. 비활성 연결리스트에 설정된 접근 태그가 있는 페이지에 다시 접속하면 활성 연결리스트로 이동되고 접근 태그가 지워집니다. (실제로 접근 충돌을 피하기 위해 페이지가 비활성 연결 목록에서 활성 연결 목록으로 직접 이동하지는 않지만, 연결 목록이 잠기는 것을 방지하기 위해 버퍼로 사용되는 pagevec 중간 구조가 있습니다.)
페이지에는 두 가지 유형의 액세스 태그가 있습니다. 하나는 페이지->플래그에 배치된 PG_referenced 태그입니다. 이 태그는 페이지에 액세스할 때 설정됩니다. 디스크 캐시에 있는 페이지(매핑되지 않음)의 경우 사용자 프로세스는 읽기 및 쓰기와 같은 시스템 호출을 통해 페이지에 액세스합니다. 시스템 호출 코드는 해당 페이지의 PG_referenced 플래그를 설정합니다.
메모리 매핑된 페이지의 경우 사용자 프로세스는 커널을 통하지 않고 직접 액세스할 수 있으므로 이 경우 액세스 플래그는 커널이 아니라 mmu에 의해 설정됩니다. 가상 주소를 물리적 주소에 매핑한 후 mmu는 해당 페이지 테이블 항목에 액세스된 플래그를 설정하여 페이지가 액세스되었음을 나타냅니다. (같은 방식으로 mmu는 작성 중인 페이지에 해당하는 페이지 테이블 항목에 더티 플래그를 배치하여 해당 페이지가 더티 페이지임을 나타냅니다.)
페이지의 액세스 태그(위의 두 태그 포함)는 PFRA의 페이지 재활용 프로세스 중에 삭제됩니다. 액세스 태그에는 분명히 유효 기간이 있어야 하고 PFRA의 실행 주기는 이 유효 기간을 나타내기 때문입니다. 페이지->플래그의 PG_referenced 표시는 직접 지울 수 있는 반면, 페이지 테이블 항목의 액세스된 비트는 페이지를 통해 해당 페이지 테이블 항목을 찾은 후에만 지울 수 있습니다(아래 "역 매핑" 참조).
그렇다면 재활용 프로세스는 LRU 연결 목록을 어떻게 스캔합니까?
LRU 그룹이 여러 개 있으므로(시스템에는 여러 영역이 있고 각 영역에는 여러 LRU 그룹이 있음) PFRA가 재활용에 가장 적합한 페이지를 찾기 위해 각 재활용에 대한 모든 LRU를 검색하면 재활용 효율성은 알고리즘은 이상적이지 않습니다.
Linux 커널 PFRA에서 사용하는 스캔 방법은 스캔 우선순위를 정의하고 이 우선순위를 사용하여 각 LRU에서 스캔해야 하는 페이지 수를 계산하는 것입니다. 전체 재활용 알고리즘은 가장 낮은 우선순위부터 시작하여 각 LRU에서 가장 최근에 사용된 페이지를 검색한 다음 이를 회수하려고 시도합니다. 한 번의 스캔 후 충분한 수의 페이지가 재활용되면 재활용 프로세스가 종료됩니다. 그렇지 않으면 우선순위를 높이고 충분한 수의 페이지가 회수될 때까지 다시 검색하십시오. 그리고 충분한 수의 페이지를 재활용할 수 없는 경우 우선 순위가 최대로 높아집니다. 즉, 모든 페이지가 스캔됩니다. 이때 재활용 페이지 수가 여전히 부족하더라도 재활용 프로세스가 종료됩니다.
LRU가 스캔될 때마다 활성 연결 목록과 비활성 연결 목록에서 현재 우선 순위에 해당하는 페이지 수를 가져온 다음 페이지를 재활용할 수 없는 경우(예: 유지 또는 잠금) 페이지를 처리합니다. ), 링크된 목록의 헤드에 해당하여 다시 배치됩니다(위와 동일, 재활용이 헤드에서 시작된다고 가정). 그렇지 않으면 페이지의 액세스 플래그가 설정된 경우 플래그를 지우고 페이지를 다시 끝으로 보냅니다. 해당 연결 목록(위와 동일, 재활용이 헤드에서 시작된다고 가정). 그렇지 않으면 페이지가 활성 연결 목록에서 비활성 연결 목록으로 이동되거나 비활성 연결 목록에서 재활용됩니다.
스캔된 페이지는 액세스 플래그 설정 여부에 따라 결정됩니다. 그렇다면 이 액세스 태그는 어떻게 설정되나요? 두 가지 방법이 있습니다. 하나는 사용자가 읽기/쓰기 등의 시스템 호출을 통해 파일에 액세스할 때 커널이 디스크 캐시의 페이지를 작동하고 이러한 페이지의 액세스 플래그(페이지 구조에 설정됨)를 설정하는 것입니다. 프로세스가 파일에 직접 액세스한다는 점은 페이지가 매핑될 때 mmu가 자동으로 해당 페이지 테이블 항목(페이지 테이블의 pte에 설정됨)에 액세스 태그를 추가한다는 것입니다. 액세스 태그에 대한 판단은 이 두 가지 정보를 기반으로 합니다. (한 페이지에 이를 참조하는 여러 PTE가 있을 수 있습니다. 이러한 PTE에 액세스 태그가 설정되어 있는지 어떻게 알 수 있나요? 그런 다음 역 매핑을 통해 이러한 PTE를 찾아야 합니다. 이에 대해서는 아래에서 설명하겠습니다.)
PFRA는 활성 연결 목록에서 익명으로 매핑된 페이지를 재활용하지 않는 경향이 있습니다. 사용자 프로세스에서 사용하는 메모리는 일반적으로 상대적으로 작고 재활용에는 비용이 많이 드는 스왑이 필요하기 때문입니다. 따라서 남은 메모리가 많고 익명 매핑의 비율이 적은 경우 익명 매핑에 해당하는 활성 연결 목록의 페이지는 재활용되지 않습니다. (그리고 해당 페이지가 비활성 목록에 있는 경우 더 이상 걱정할 필요가 없습니다.)
역 매핑
이처럼 PFRA에서 처리하는 페이지 재활용 과정에서 LRU의 비활성 목록 중 일부 페이지가 재활용되려고 할 수 있다.
페이지가 매핑되지 않은 경우 파트너 시스템으로 직접 재활용될 수 있습니다(더티 페이지의 경우 먼저 다시 쓴 다음 재활용). 그렇지 않으면 여전히 처리해야 할 번거로운 일이 하나 있습니다. 사용자 프로세스의 특정 페이지 테이블 항목이 이 페이지를 참조하고 있으므로 페이지를 재활용하기 전에 이를 참조하는 페이지 테이블 항목에 대한 설명이 제공되어야 합니다.
그렇다면 질문이 생깁니다. 커널은 이 페이지에서 어떤 페이지 테이블 항목이 참조되는지 어떻게 알 수 있습니까? 이를 위해 커널은 페이지에서 페이지 테이블 항목으로의 역방향 매핑을 설정합니다.
매핑된 페이지에 해당하는 vma는 reverse mapping을 통해 찾을 수 있고, 해당 페이지 테이블은 vma->vm_mm->pgd를 통해 찾을 수 있다. 그런 다음 페이지->인덱스를 통해 페이지의 가상 주소를 가져옵니다. 그런 다음 가상 주소를 통해 페이지 테이블에서 해당 페이지 테이블 항목을 찾습니다. (앞서 언급한 페이지 테이블 항목의 액세스된 태그는 역 매핑을 통해 달성됩니다.)
페이지에 해당하는 페이지 구조에서 페이지->매핑의 최하위 비트가 설정되면 익명 매핑 페이지이고, 그렇지 않으면 파일 매핑 페이지입니다. 페이지->매핑은 파일에 해당하는 address_space 구조입니다. (물론 anon_vma 구조체와 address_space 구조체를 할당할 때 주소를 정렬해야 하며, 최소한 최하위 비트는 0이 되어야 합니다.)
익명으로 매핑된 페이지의 경우 anon_vma 구조는 연결 목록 헤더 역할을 하며 vma->anon_vma_node 연결 목록 포인터를 통해 이 페이지를 매핑하는 모든 vmas를 연결합니다. 페이지가 (익명으로) 사용자 공간에 매핑될 때마다 해당 vma가 이 연결 목록에 추가됩니다.
파일 매핑된 페이지의 경우 address_space 구조는 디스크 캐시 페이지를 저장하기 위한 기수 트리를 유지할 뿐만 아니라 파일에 매핑된 모든 vmas에 대한 우선순위 검색 트리도 유지합니다. 파일로 매핑된 이러한 VMA가 반드시 전체 파일을 매핑하는 것은 아니기 때문에 파일의 일부만 매핑될 수도 있습니다. 따라서 매핑된 모든 vmas를 인덱싱하는 것 외에도 이 우선순위 검색 트리는 파일의 어떤 영역이 어떤 vmas에 매핑되는지 알아야 합니다. 페이지(파일)가 사용자 공간에 매핑될 때마다 해당 vma가 이 우선순위 검색 트리에 추가됩니다. 따라서 디스크 캐시에 있는 페이지가 주어지면 페이지->인덱스를 통해 파일 내 페이지의 위치를 알 수 있고, 우선순위 검색 트리를 통해 이 페이지에 매핑된 모든 vmas를 찾을 수 있다.
위의 두 단계에서 마법의 페이지->인덱스는 페이지의 가상 주소를 가져오는 것과 파일 디스크 캐시에서 페이지 위치를 가져오는 두 가지 작업을 수행합니다.
vma->vm_start는 vma의 첫 번째 가상 주소를 기록하고, vma->vm_pgoff는 해당 매핑 파일(또는 공유 메모리)에 vma의 오프셋을 기록하고, page->index는 파일(또는 공유 메모리)에 페이지를 기록합니다. 오프셋 .
vma에 있는 페이지의 오프셋은 vma->vm_pgoff와 page->index를 통해 얻을 수 있고, 페이지의 가상 주소는 vma->vm_start를 추가하여 얻을 수 있으며, 파일 디스크 캐시에 있는 페이지는 다음을 통해 얻을 수 있습니다. 페이지->index.s 위치.
페이지 교체 및 교체
재활용할 페이지를 참조하는 페이지 테이블 항목을 찾은 후 파일 매핑을 위해 해당 페이지를 참조하는 페이지 테이블 항목을 직접 삭제할 수 있습니다. 사용자가 이 주소에 다시 액세스하면 페이지 오류 예외가 발생합니다. 예외 처리 코드는 페이지를 재할당하고 디스크에서 해당 데이터를 읽습니다. (페이지가 이미 해당 디스크 캐시에 있을 수 있습니다. 다른 프로세스가 해당 페이지에 액세스했기 때문일 수 있습니다.) 첫 번째). 이는 매핑 후 처음 페이지에 액세스할 때와 동일합니다.
익명 매핑의 경우 페이지는 먼저 스왑 파일에 다시 기록된 다음 스왑 파일의 페이지 인덱스가 페이지 테이블 항목에 기록되어야 합니다.
페이지 테이블 항목에 현재 비트가 있습니다. 이 비트가 지워지면 mmu는 페이지 테이블 항목이 유효하지 않은 것으로 간주합니다. 페이지 테이블 항목이 유효하지 않은 경우 다른 비트는 mmu에서 관리되지 않으며 다른 정보를 저장하는 데 사용될 수 있습니다. 여기서는 스왑 파일에 페이지 인덱스를 저장하는 데 사용됩니다(실제로는 스왑 파일 번호 + 스왑 파일의 인덱스 번호).
익명으로 매핑된 페이지를 스왑 파일로 바꾸는 프로세스(스왑 아웃 프로세스)는 디스크 캐시의 더티 페이지를 파일에 다시 쓰는 프로세스와 매우 유사합니다.
스왑 파일에는 해당 address_space 구조도 있습니다. 스왑 아웃 시 익명으로 매핑된 페이지는 먼저 이 address_space에 해당하는 디스크 캐시에 배치된 다음 더티 페이지가 다시 기록되는 것처럼 스왑 파일에 다시 기록됩니다. 쓰기 저장이 완료되면 페이지가 해제됩니다(우리의 목적은 페이지를 해제하는 것임을 기억하세요).
그렇다면 디스크 캐시를 거치는 대신 페이지를 스왑 파일에 다시 쓰는 것은 어떨까요? 이 페이지는 여러 번 매핑되었을 수 있으므로 모든 사용자 프로세스의 페이지 테이블에 있는 해당 페이지 테이블 항목을 한 번에 수정(스왑 파일의 페이지 인덱스로 수정)하는 것은 불가능합니다. 페이지가 해제되면 페이지는 일시적으로 디스크 캐시에 배치됩니다.
페이지 테이블 항목에 대한 모든 수정이 성공적인 것은 아닙니다(예를 들어 수정 전에 페이지에 다시 액세스했으므로 지금 페이지를 재활용할 필요가 없음). 따라서 페이지가 디스크 캐시에 배치되는 데 걸리는 시간이 그것도 아주 오래.
마찬가지로 스왑 파일에서 익명으로 매핑된 페이지를 읽는 프로세스(스왑 인 프로세스)도 파일 데이터를 읽는 프로세스와 매우 유사합니다.
먼저 해당 디스크 캐시로 이동하여 페이지가 있는지 확인하세요. 그렇지 않은 경우 스왑 파일에서 읽어보세요. 파일의 데이터도 디스크 캐시로 읽힌 다음 사용자 프로세스의 페이지 테이블에 있는 해당 페이지 테이블 항목이 이 페이지를 직접 가리키도록 다시 작성됩니다.
이 페이지는 디스크 캐시에서 즉시 가져오지 못할 수 있습니다. 왜냐하면 이 페이지에 매핑된 다른 사용자 프로세스가 있는 경우(해당 페이지 테이블 항목이 스왑 파일의 인덱스로 수정되었음) 여기서도 참조할 수 있기 때문입니다. . 다른 페이지 테이블 항목이 스왑 파일 인덱스를 참조하지 않을 때까지 디스크 캐시에서 페이지를 가져올 수 없습니다.
마지막 확실한 킬
앞서 언급했듯이 PFRA는 모든 LRU를 스캔했지만 여전히 필요한 페이지를 회수하지 못했을 수 있습니다. 마찬가지로 페이지는 slab, dentry 캐시, inode 캐시 등에서 재활용되지 않을 수 있습니다.
이때 특정 커널 코드가 페이지를 얻어야 한다면(페이지가 없으면 시스템이 충돌할 수 있음) 어떻게 될까요? PFRA는 최후의 수단인 OOM(메모리 부족)을 사용할 수밖에 없었습니다. 소위 OOM은 가장 덜 중요한 프로세스를 찾아 종료하는 것입니다. 이 프로세스가 차지하는 메모리 페이지를 해제하여 시스템 부담을 완화하십시오.
5. 메모리 관리 아키텍처
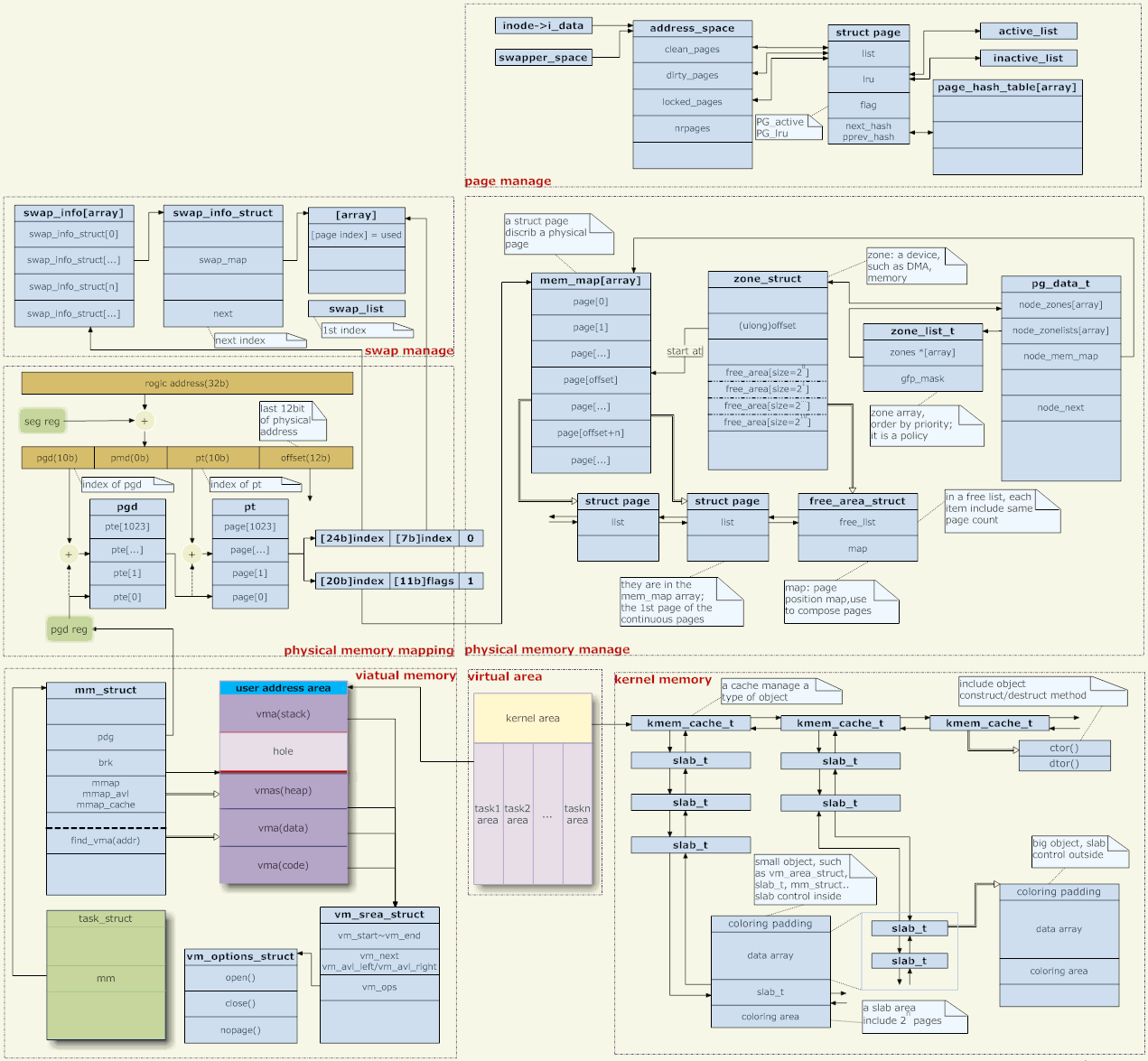
위 사진에 대한 몇 마디
주소 매핑
리눅스 커널은 페이지 메모리 관리를 사용합니다. 애플리케이션에서 제공하는 메모리 주소는 실제 물리적 주소가 되기 전에 여러 수준의 페이지 테이블을 통해 수준별로 변환되어야 합니다.
생각해 보세요. 주소 매핑은 여전히 무서운 일입니다. 가상 주소로 표시되는 메모리 공간에 액세스할 때 매핑이 완료되기 전에 페이지 테이블의 각 수준(페이지 테이블은 메모리에 저장됨)에서 변환에 사용되는 페이지 테이블 항목을 얻기 위해 여러 번의 메모리 액세스가 필요합니다. 즉, 메모리 액세스를 달성하려면 실제로 메모리에 N+1회(N=페이지 테이블 수준) 액세스하고 N개의 추가 작업을 수행해야 합니다.
따라서 주소 매핑이 하드웨어에서 지원되어야 하며, mmu(메모리 관리 장치)가 바로 이 하드웨어입니다. 그리고 페이지 테이블을 저장하기 위해 캐시가 필요합니다. 이 캐시는 TLB(Translation Lookaside Buffer)입니다.
그럼에도 불구하고 주소 매핑에는 여전히 상당한 오버헤드가 있습니다. 캐시 접근 속도가 메모리 속도의 10배, 적중률이 40%이고, 페이지 테이블이 3개 레벨로 구성되어 있다고 가정하면, 평균적으로 하나의 가상 주소 접근은 물리적 메모리 접근 시간의 약 2배를 소비하게 된다.
따라서 일부 임베디드 하드웨어에서는 mmu 사용을 중단할 수 있습니다. 이러한 하드웨어는 VxWorks(매우 효율적인 임베디드 실시간 운영 체제), Linux(Linux에는 mmu를 비활성화하는 컴파일 옵션도 있음) 및 기타 시스템을 실행할 수 있습니다.
그러나 mmu를 사용하면 장점도 크며, 가장 중요한 것은 보안 고려 사항입니다. 각 프로세스는 독립적인 가상 주소 공간을 가지며 서로 간섭하지 않습니다. 주소 매핑을 포기하면 모든 프로그램이 동일한 주소 공간에서 실행됩니다. 따라서 mmu가 없는 시스템에서는 프로세스의 범위를 벗어난 메모리 액세스로 인해 다른 프로세스에서 설명할 수 없는 오류가 발생하거나 커널이 충돌할 수도 있습니다.
주소 매핑 문제에서 커널은 페이지 테이블만 제공하고 실제 변환은 하드웨어에 의해 완료됩니다. 그렇다면 커널은 이러한 페이지 테이블을 어떻게 생성합니까? 여기에는 가상 주소 공간 관리와 물리적 메모리 관리라는 두 가지 측면이 있습니다. (실제로는 사용자 모드 주소 매핑만 관리하면 되며, 커널 모드 주소 매핑은 하드코딩되어 있습니다.)
가상 주소 관리
각 프로세스는 프로세스의 메모리 관리자인 mm 구조를 가리키는 작업 구조에 해당합니다. (스레드의 경우 각 스레드에도 작업 구조가 있지만 모두 동일한 mm을 가리키므로 주소 공간이 공유됩니다.)
mm->pgd는 페이지 테이블을 포함하는 메모리를 가리킵니다. 각 프로세스에는 자체 mm이 있고 각 mm에는 자체 페이지 테이블이 있습니다. 따라서 프로세스가 스케줄링되면 페이지 테이블이 전환됩니다(일반적으로 X86 아래에는 CR3과 같이 페이지 테이블의 주소를 저장하는 CPU 레지스터가 있고, 페이지 테이블 전환은 레지스터의 값을 변경하는 것입니다). 따라서 각 프로세스의 주소 공간은 서로 영향을 미치지 않는다(페이지 테이블이 다르기 때문에 당연히 다른 사람의 주소 공간에 접근할 수 없다. 공유 메모리를 제외하고는 의도적으로 서로 다른 페이지 테이블이 동일한 물리적 주소에 접근할 수 있도록 하기 위함이다). .).
메모리에 대한 사용자 프로그램의 작업(할당, 재활용, 매핑 등)은 모두 mm에 대한 작업, 특히 mm의 vma(가상 메모리 공간)에 대한 작업입니다. 이러한 vma는 힙, 스택, 코드 영역, 데이터 영역, 다양한 매핑 영역 등과 같은 프로세스 공간의 다양한 영역을 나타냅니다.
사용자 프로그램의 메모리 작업은 물리적 메모리 할당은 물론이고 페이지 테이블에 직접적인 영향을 미치지 않습니다. 예를 들어, malloc이 성공하면 특정 vma만 변경되며 페이지 테이블은 변경되지 않으며 실제 메모리 할당도 변경되지 않습니다.
사용자가 메모리를 할당한 다음 이 메모리에 액세스한다고 가정합니다. 해당 매핑이 페이지 테이블에 기록되지 않으므로 CPU는 페이지 폴트 예외를 발생시킵니다. 커널은 예외를 포착하고 예외가 발생한 주소가 합법적인 vma에 존재하는지 확인합니다. 그렇지 않은 경우 프로세스에 "세그먼트 오류"를 제공하고 충돌이 발생하면 물리적 페이지를 할당하고 이에 대한 매핑을 설정합니다.
물리적 메모리 관리
그렇다면 물리적 메모리는 어떻게 할당되나요?
우선 리눅스는 NUMA(비균질 스토리지 아키텍처)를 지원하며 물리적 메모리 관리의 첫 번째 단계는 미디어 관리이다. pg_data_t 구조는 매체를 설명합니다. 일반적으로 우리의 메모리 관리 매체는 메모리 뿐이고 균일하기 때문에 시스템에 pg_data_t 객체가 하나만 있다고 간단히 생각할 수 있습니다.
각 매체 아래에는 여러 영역이 있습니다. 일반적으로 DMA, NORMAL, HIGH의 세 가지가 있습니다.
DMA: 일부 하드웨어 시스템의 DMA 버스는 시스템 버스보다 좁기 때문에 주소 공간의 일부만 DMA에 사용할 수 있습니다. 이 주소 부분은 DMA 영역에서 관리됩니다(고급 제품입니다).
높음: 고급 메모리입니다. 32비트 시스템에서 주소 공간은 4G입니다. 커널은 3~4G 범위가 커널 공간이고 0~3G가 사용자 공간이라고 규정합니다(각 사용자 프로세스에는 매우 큰 가상 공간이 있음)(그림: 중간 하단). 앞서 언급했듯이 커널의 주소 매핑은 하드코딩되어 있는데, 이는 3~4G의 해당 페이지 테이블이 하드코딩되어 물리적 주소 0~1G에 매핑된다는 의미이다. (실제로 1G는 매핑되지 않고 896M만 남아있습니다. 1G보다 큰 물리적 주소를 매핑하기 위해 남은 공간이 남아 있는데 이 부분은 당연히 하드코딩되지 않습니다.) 따라서 896M보다 큰 물리적 주소에는 이에 대응하는 하드 코딩된 페이지 테이블이 없으며(매핑이 설정되어야 함) 이를 고급 메모리라고 합니다(물론 머신 메모리가 896M 미만이면 고급 메모리가 없습니다. 64비트 시스템의 경우 주소 공간이 매우 크고 커널에 속한 공간이 1G 이상이므로 고급 메모리가 없습니다. ;
NORMAL: DMA 또는 HIGH에 속하지 않는 메모리를 NORMAL이라고 합니다.
영역 위의 zone_list는 할당 전략, 즉 메모리 할당 시 영역 우선순위를 나타냅니다. 일종의 메모리 할당은 한 영역에만 할당되지 않는 경우가 많습니다. 예를 들어 커널이 사용할 페이지를 할당할 때 우선 순위가 가장 높은 것은 NORMAL에서 할당하는 것입니다. 그래도 안 되면 DMA(HIGH)에서 할당합니다. 아직 할당되지 않았기 때문에 작동하지 않습니다). 이는 할당 전략입니다.
각 메모리 매체는 mem_map을 유지하며, 매체 내 각 물리 페이지마다 해당 페이지 구조를 구축하여 물리 메모리를 관리한다.
각 영역은 mem_map에 시작 위치를 기록합니다. 그리고 이 zone의 free 페이지들은 free_area를 통해 연결됩니다. 실제 메모리 할당은 여기에서 옵니다. free_area에서 페이지를 제거하면 할당됩니다. (커널의 메모리 할당은 사용자 프로세스의 메모리 할당과 다릅니다. 사용자의 메모리 사용은 커널에 의해 감독되며 부적절한 사용은 "세그먼트 오류"를 유발합니다. 반면 커널은 감독되지 않으며 의식에만 의존할 수 있습니다. . free_area에서 선택하지 않은 페이지를 사용하지 마세요. )
[주소 매핑 만들기]
커널에 물리적 메모리가 필요한 경우 대부분의 경우 전체 페이지가 할당됩니다. 이렇게 하려면 위의 mem_map에서 페이지를 선택하면 됩니다. 예를 들어 앞서 언급한 커널은 페이지 오류 예외를 캡처한 다음 매핑을 설정하기 위해 페이지를 할당해야 합니다.
이렇게 말하면 커널이 페이지를 할당하고 주소 매핑을 설정할 때 커널이 가상 주소를 사용합니까, 아니면 물리적 주소를 사용합니까? 우선, CPU 명령어가 가상 주소를 수신하기 때문에 커널 코드에서 액세스하는 주소는 가상 주소입니다(주소 매핑은 CPU 명령어에 투명합니다). 그러나 주소 매핑을 설정할 때 주소 매핑의 목적은 물리적 주소를 얻는 것이므로 커널이 페이지 테이블에 채운 내용이 물리적 주소입니다.
그렇다면 커널은 어떻게 이 물리적 주소를 얻습니까? 실제로 위에서 언급한 것처럼 mem_map의 페이지들은 물리적인 메모리를 기반으로 구성되며, 각 페이지는 물리적인 페이지에 해당한다.
따라서 가상 주소 매핑은 여기서 페이지 구조에 의해 완료되고 최종 물리적 주소를 제공한다고 말할 수 있습니다. 그러나 페이지 구조는 분명히 가상 주소를 통해 관리됩니다(앞서 언급한 것처럼 CPU 명령어는 가상 주소를 받습니다). 그렇다면 페이지 구조는 다른 사람의 가상 주소 매핑을 구현하는데, 페이지 구조 자체의 가상 주소 매핑은 누가 구현하게 될까요? 누구도 그것을 달성할 수 없습니다.
이로 인해 앞서 언급한 문제가 발생합니다. 커널 공간의 페이지 테이블 항목은 하드 코딩되어 있습니다. 커널이 초기화되면 주소 매핑이 커널의 주소 공간에 하드 코딩됩니다. 페이지 구조는 분명히 커널 공간에 존재하므로 주소 매핑 문제는 "하드 코딩"을 통해 해결되었습니다.
커널 공간의 페이지 테이블 항목이 하드 코딩되어 있으므로 NORMAL(또는 DMA) 영역의 메모리가 커널 공간과 사용자 공간 모두에 매핑될 수 있으므로 또 다른 문제가 발생합니다. 커널 공간에 매핑되는 것은 이 매핑이 하드 코딩되어 있기 때문에 분명합니다. 이러한 페이지는 사용자 공간에 매핑될 수도 있으며, 이는 앞서 언급한 페이지 누락 예외 시나리오에서 가능합니다. 사용자 공간에 매핑된 페이지는 HIGH 영역에서 먼저 얻어야 합니다. 이러한 메모리는 커널이 접근하기 불편하기 때문에 사용자 공간에 주는 것이 가장 좋습니다. 하지만 HIGH 영역이 소진되거나, 기기의 물리적 메모리 부족으로 인해 시스템에 HIGH 영역이 없을 수도 있으므로, NORMAL 영역을 사용자 공간으로 매핑하는 것은 불가피합니다.
그러나 NORMAL 영역의 메모리가 커널 공간과 사용자 공간 모두에 매핑되는 것은 문제가 되지 않는다. 왜냐하면 커널이 페이지를 사용하고 있다면 해당 페이지는 free_area에서 제거되어야 하므로 페이지 폴트 예외가 발생하기 때문이다. 처리 코드는 더 이상 이 페이지가 사용자 공간에 매핑되지 않습니다. 반대의 경우에도 마찬가지입니다. 사용자 공간에 매핑된 페이지는 자연스럽게 free_area에서 제거되었으며 커널은 더 이상 이 페이지를 사용하지 않습니다.
커널 공간 관리
전체 메모리 페이지를 사용하는 것 외에도 사용자 프로그램이 malloc을 사용하는 것처럼 커널은 때때로 임의 크기의 공간을 할당해야 합니다. 이 기능은 슬래브 시스템에 의해 구현됩니다.
Slab은 작업 구조에 해당하는 풀, mm 구조에 해당하는 풀 등 커널에서 일반적으로 사용되는 일부 구조 개체에 대한 개체 풀을 설정하는 것과 같습니다.
Slab은 "32바이트 크기" 개체 풀, "64바이트 크기" 개체 풀 등과 같은 일반 개체 풀도 유지 관리합니다. 이러한 일반 개체 풀에는 커널에서 일반적으로 사용되는 kmalloc 함수(사용자 모드의 malloc과 유사)가 할당됩니다.
객체가 실제로 사용하는 메모리 공간 외에도 slab에는 해당 제어 구조도 있습니다. 이를 구성하는 방법에는 두 가지가 있습니다. 객체가 더 큰 경우 제어 구조는 특수 페이지를 사용하여 객체를 저장합니다. 객체가 더 작은 경우 제어 구조는 객체 공간과 동일한 페이지를 사용합니다.
슬랩 외에도 Linux 2.6에서는 mempool(메모리 풀)도 도입했습니다. 의도는 다음과 같습니다. 메모리 부족으로 인해 특정 개체 할당에 실패하는 것을 방지하기 위해 미리 여러 개를 할당하고 mempool에 저장합니다. 일반적인 상황에서는 객체를 할당할 때 mempool의 리소스는 건드리지 않고 평소대로 slab을 통해 할당됩니다. 시스템 메모리가 부족하여 slab을 통해 메모리를 할당할 수 없는 경우 mempool의 내용이 사용됩니다.
페이지 스왑 인/아웃(사진: 오른쪽 상단)
페이지 교환은 또 다른 매우 복잡한 시스템입니다. 메모리 페이지를 디스크로 교체하는 것과 디스크 파일을 메모리로 매핑하는 것은 두 가지 매우 유사한 프로세스입니다(메모리 페이지를 디스크로 교체하는 동기는 나중에 디스크에서 메모리로 다시 로드하기 위한 것입니다). 따라서 스왑은 파일 하위 시스템의 일부 메커니즘을 재사용합니다.
페이지를 들어오고 나가는 것은 매우 CPU 및 IO 집약적인 문제이지만, 메모리가 비싸다는 역사적 이유로 인해 메모리를 확장하려면 디스크를 사용해야 합니다. 하지만 이제 메모리 가격이 저렴해졌기 때문에 쉽게 몇 기가바이트의 메모리를 설치한 다음 스왑 시스템을 종료할 수 있습니다. 따라서 스왑 구현은 실제로 탐색하기 어렵기 때문에 여기서는 자세히 설명하지 않겠습니다. (참조: "Linux 커널 페이지 재활용에 대한 간략한 분석")
[사용자 공간 메모리 관리]
Malloc은 libc의 라이브러리 함수이며 사용자 프로그램은 일반적으로 이를(또는 유사한 함수) 사용하여 메모리 공간을 할당합니다.
libc가 메모리를 할당하는 방법에는 두 가지가 있습니다. 하나는 힙의 크기를 조정하는 것이고, 다른 하나는 새로운 가상 메모리 영역을 mmap하는 것입니다(힙도 vma임).
커널에서 힙은 고정된 끝과 철회 가능한 끝이 있는 vma입니다(그림: 왼쪽 가운데). 확장 가능한 끝은 brk 시스템 호출을 통해 조정됩니다. Libc는 힙 공간을 관리합니다. 사용자가 메모리 할당을 위해 malloc을 호출하면 libc는 기존 힙에서 이를 할당하려고 시도합니다. 힙 공간이 충분하지 않으면 brk를 통해 힙 공간을 늘립니다.
사용자가 할당된 공간을 해제하면 libc는 brk를 통해 힙 공간을 줄일 수 있습니다. 그러나 힙 공간을 늘리기는 쉽지만 줄이기는 어렵습니다. 사용자 공간에 지속적으로 10블록의 메모리가 할당되고 처음 9블록이 해제된 상황을 생각해 보세요. 이때, Free가 아닌 10번째 블록의 크기가 1바이트에 불과하더라도 libc는 힙 크기를 줄일 수 없습니다. 더미의 한쪽 끝만 팽창 및 수축이 가능하고 가운데는 비워질 수 없기 때문입니다. 10번째 메모리 블록은 힙의 확장 가능한 끝 부분을 차지합니다. 힙 크기는 줄어들 수 없으며 관련 리소스는 커널로 반환될 수 없습니다.
사용자가 대용량 메모리를 malloc하면 libc는 mmap 시스템 호출을 통해 새 vma를 매핑합니다. 힙 크기 조정 및 공간 관리는 여전히 번거롭기 때문에 vma를 다시 빌드하는 것이 더 편리할 것입니다(위에서 언급한 무료 문제도 이유 중 하나입니다).
그렇다면 malloc 중에 항상 새 vma를 mmap하지 않는 이유는 무엇입니까? 첫째, 작은 공간의 할당과 재활용을 위해 libc가 관리하는 힙 공간은 이미 요구 사항을 충족할 수 있으며 매번 시스템 호출을 할 필요가 없습니다. 그리고 vma는 페이지를 기반으로 하며 최소 1페이지를 할당하는 것입니다. vma가 너무 많으면 시스템 성능이 저하됩니다. 페이지 결함 예외, vma 생성 및 파괴, 힙 공간 크기 조정 등은 모두 vma에 대한 작업이 필요합니다. 현재 프로세스의 모든 vma 중에서 작동해야 하는 vma를 찾아야 합니다. vmas가 너무 많으면 필연적으로 성능 저하가 발생합니다. (프로세스에 VMA가 더 적으면 커널은 연결된 목록을 사용하여 VMA를 관리합니다. VMA가 더 많으면 대신 레드-블랙 트리가 사용됩니다.)
[사용자의 스택]
힙과 마찬가지로 스택도 vma입니다(그림: 왼쪽 가운데). 이 vma는 한쪽 끝은 고정되어 있고 다른 쪽 끝은 확장 가능합니다(참고, 축소할 수 없음). 이 vma는 특별합니다. 이 vma를 늘리기 위해 brk와 같은 시스템 호출이 없습니다.
사용자가 액세스한 가상 주소가 이 vma를 초과하면 커널은 페이지 오류 예외를 처리할 때 자동으로 vma를 증가시킵니다. 커널은 현재 스택 레지스터(예: ESP)를 확인하며 액세스된 가상 주소는 ESP에 n을 더한 값을 초과할 수 없습니다(n은 CPU 푸시 명령이 한 번에 스택에 푸시할 수 있는 최대 바이트 수입니다). 즉, 커널은 ESP를 벤치마크로 사용하여 액세스가 범위를 벗어났는지 확인합니다.
그러나 ESP의 값은 사용자 모드 프로그램에서 자유롭게 읽고 쓸 수 있습니다. 사용자 프로그램이 ESP를 조정하여 스택을 매우 크게 만든다면 어떻게 될까요? 스택 크기 구성을 포함하여 커널에는 프로세스 제한에 대한 구성 세트가 있습니다. 스택은 너무 커질 수 있으며 더 크면 오류가 발생합니다.
프로세스의 경우 스택은 일반적으로 상대적으로 크게 확장될 수 있습니다(예: 8MB). 하지만 스레드는 어떻습니까?
첫째, 스레드 스택에서는 무슨 일이 벌어지고 있는 걸까요? 앞서 언급했듯이 스레드의 mm은 상위 프로세스를 공유합니다. 스택이 mm 단위의 vma이지만 스레드는 이 vma를 상위 프로세스와 공유할 수 없습니다(실행 중인 두 엔터티는 분명히 스택을 공유할 필요가 없습니다). 따라서 스레드가 생성되면 스레드 라이브러리는 스레드의 스택으로 mmap을 통해 새로운 vma를 생성합니다(일반적으로 2M보다 큼).
스레드의 스택은 어떤 의미에서는 실제 스택이 아니며 고정된 영역이며 매우 제한된 용량을 가지고 있음을 알 수 있습니다.
이 글을 통해 Linux 메모리 관리에 대한 기본적인 이해가 필요합니다. 이는 가상 메모리와 물리적 메모리를 변환하고 할당하는 효과적인 방법이며 Linux 시스템의 다양한 요구에 적응할 수 있습니다. 물론 메모리 관리는 고정적이지 않습니다. 특정 하드웨어 플랫폼과 커널 버전에 따라 사용자 정의하고 수정해야 합니다. 간단히 말해서 메모리 관리는 Linux 시스템에서 없어서는 안 될 구성 요소이며 심층적으로 연구하고 숙달할 가치가 있습니다.
위 내용은 리눅스 메모리 관리: 가상 메모리와 물리 메모리를 변환하고 할당하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!