
Linux 커널의 CPU 로드 밸런싱 메커니즘: 원칙, 프로세스 및 최적화

- 王林앞으로
- 2024-02-09 13:50:111309검색
CPU 로드 밸런싱이란 멀티 코어 또는 멀티 프로세서 시스템에서 실행 중인 프로세스나 작업을 서로 다른 CPU에 할당하여 각 CPU의 로드가 최대한 균형을 이루도록 하여 시스템 성능과 효율성을 향상시키는 것을 말합니다. CPU 로드 밸런싱은 Linux 커널의 중요한 기능입니다. 이를 통해 Linux 시스템은 멀티 코어 또는 멀티 프로세서를 최대한 활용하여 다양한 애플리케이션 시나리오와 요구 사항에 적응할 수 있습니다. 그런데 Linux 커널의 CPU 로드 밸런싱 메커니즘을 실제로 이해하고 계십니까? 작동 원리, 프로세스 및 최적화 방법을 알고 있습니까? 이 기사에서는 Linux 커널의 CPU 로드 밸런싱 메커니즘에 대한 관련 지식을 자세히 소개하여 Linux에서 이 강력한 커널 기능을 더 잘 사용하고 이해할 수 있도록 합니다.
이 문제는 여전히 마법의 프로세스 스케줄링 문제로 인해 발생합니다. Linux 프로세스 그룹 스케줄링 메커니즘 분석을 참조하세요. 그룹 스케줄링 메커니즘은 다시 시작하는 동안 많은 커널 호출 스택이 차단되는 것으로 나타났습니다. double_rq_lock 함수와 double_rq_lock이 load_balance에 의해 트리거되는 경우, 당시 코어 간 스케줄링에 문제가 있는 것으로 의심되었으며 특정 책임 시나리오에서 멀티 코어 연동이 발생했습니다. 나중에 CPU 부하 하에서 코드 구현을 살펴보았습니다. 균형을 맞추고 요약을 썼습니다.
커널 코드 버전: kernel-3.0.13-0.27.
커널 코드 함수는 load_balance 함수에서 시작됩니다. load_balance 함수에서 이를 참조하는 함수를 살펴보면 여기에서 __schedule에 다음 문장이 있습니다.
으아악위에서 커널이 CPU 로드 밸런싱을 수행하려고 시도하는 경우, 즉 현재 CPU 실행 대기열이 NULL인 경우를 볼 수 있습니다.
CPU 로드 밸런싱에는 두 가지 방법이 있습니다. 즉, 유휴 CPU가 다른 사용 중인 CPU 큐에서 현재 CPU 큐로 프로세스를 가져오거나, 사용 중인 CPU 큐가 프로세스를 유휴 CPU 큐로 푸시하는 것입니다. Idle_balance가 하는 일은 당기기(Pull)입니다. 구체적인 푸시는 아래에 설명되어 있습니다.
유휴_균형에는 현재 CPU의 풀 여부를 제어하는 proc 밸브가 있습니다.
sysctl_sched_migration_cost에 해당하는 proc 제어 파일은 /proc/sys/kernel/sched_migration_cost입니다. 스위치는 CPU 대기열이 500us(sysctl_sched_migration_cost 기본값) 이상 유휴 상태이면 pull이 수행되고, 그렇지 않으면 반환됨을 의미합니다.
for_each_domain(this_cpu, sd)는 task_group과 유사하게 CPU 그룹으로 직관적으로 이해될 수 있습니다. 그룹 내 균형을 의미합니다. 로드 밸런싱에는 모순이 있습니다. 로드 밸런싱의 빈도와 CPU 캐시 적중률이 모순됩니다. CPU 스케줄링 도메인은 각 CPU를 서로 다른 수준의 그룹으로 나눕니다. 낮은 수준에서 달성된 균형은 절대 업그레이드되지 않습니다. 처리 수준이 높아 캐시 적중률에 영향을 미치지 않습니다.
사진은 다음과 같습니다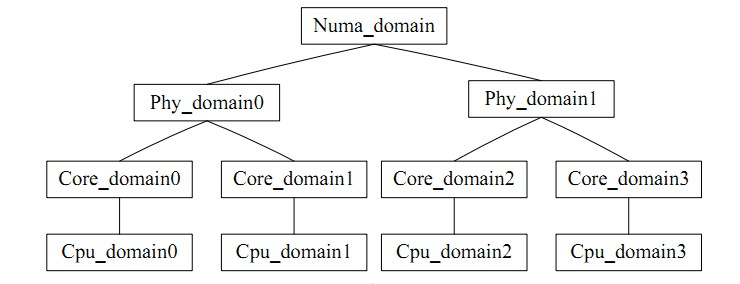
마지막으로 load_balance를 통해 본론으로 들어가겠습니다.
먼저 find_busiest_group을 통해 현재 스케줄링 도메인에서 가장 바쁜 스케줄링 그룹을 구합니다. 먼저 update_sd_lb_stats는 sd의 상태를 업데이트합니다. 즉, 해당 sd를 순회하여 다음과 같이 sds에 구조 데이터를 채웁니다.
으아악 으아악스케줄링 도메인에서 가장 바쁜 그룹을 선택하기 위한 기준 기준은 그룹 내 모든 CPU의 로드 합계입니다. 그룹에서 바쁜 실행 큐를 찾는 기준 기준은 CPU 실행 큐의 길이입니다. 는 부하이고, 부하 값이 클수록 더 바쁜 것입니다. 밸런싱 프로세스 중에 현재 대기열의 로드 상태를 이전에 기록된 가장 바쁜 대기열과 비교하여 이러한 변수는 적시에 업데이트되므로 가장 바쁜 대기열은 항상 도메인에서 가장 바쁜 그룹을 가리키므로 쉽게 검색할 수 있습니다.
스케줄링 도메인의 평균 부하 계산
로드 크기를 비교하는 과정에서 현재 실행 중인 CPU에서 가장 바쁜 그룹이 비어 있거나, 현재 실행 중인 CPU 큐가 가장 바쁜 그룹이거나, 현재 CPU 큐의 로드가 평균보다 작지 않은 것으로 확인된 경우 이 그룹에서 부하가 부하 상태이거나 불균형 양이 크지 않은 경우 NULL 값이 반환됩니다. 즉, 가장 바쁜 그룹의 부하가 평균 부하보다 작으면 그룹 간 균형이 필요하지 않습니다. 스케줄링 도메인에서는 작은 범위의 로드만 수행하면 됩니다. 전송될 작업의 양이 각 프로세스의 평균 로드보다 적을 경우 가장 바쁜 스케줄링 그룹이 획득됩니다.
그런 다음 find_busiest_queue에서 가장 바쁜 스케줄링 큐를 찾고, 그룹의 모든 CPU 큐를 순회한 후, 차례로 각 큐의 로드를 비교하여 가장 바쁜 큐를 찾습니다.
위 계산을 통해 가장 바쁜 대기열을 얻었습니다.
가장 바쁜->nr_running 숫자가 1보다 크면 가져오기 작업이 수행되기 전에 move_tasks가 double_rq_lock에 의해 잠깁니다.
move_tasks 프로세스 가져오기 작업은 실패할 수 있습니다. 즉, move_tasks->balance_tasks입니다. 여기에는 프로세스 마이그레이션 수를 제어하는 sysctl_sched_nr_ migration 스위치가 있습니다. 해당 proc은 /proc/sys/kernel/sched_nr_ migration입니다.
다음은 선택한 프로세스를 마이그레이션할 수 있는지 확인하는 함수입니다. 1. 마이그레이션된 프로세스가 실행 중입니다. 2. 프로세스가 대상 CPU로 마이그레이션될 수 없습니다. 프로세스 캐시는 여전히 뜨겁습니다. 이는 캐시 적중률을 보장하기 위한 것이기도 합니다.
프로세스 캐시가 유효한지 확인하고 조건을 확인합니다. 프로세스의 실행 시간이 /proc/sys/kernel/sched_migration_cost_ns
디렉터리에 해당하는 proc 제어 스위치 sysctl_sched_migration_cost보다 깁니다.static int
task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
delta = now - p->se.exec_start;
return delta
在load_balance中,move_tasks返回失败也就是ld_moved==0,其中sd->nr_balance_failed++对应can_migrate_task中的”too many balance attempts have failed”,然后busiest->active_balance = 1设置,active_balance = 1。
if (active_balance) //如果pull失败了,开始触发push操作 stop_one_cpu_nowait(cpu_of(busiest), active_load_balance_cpu_stop, busiest, &busiest->active_balance_work);
push整个触发操作代码机制比较绕,stop_one_cpu_nowait把active_load_balance_cpu_stop添加到cpu_stopper每CPU变量的任务队列里面,如下:
void stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
cpu_stop_queue_work(&per_cpu(cpu_stopper, cpu), work_buf);
}
而cpu_stopper则是cpu_stop_init函数通过cpu_stop_cpu_callback创建的migration内核线程,触发任务队列调度。因为migration内核线程是绑定每个核心上的,进程迁移失败的1和3问题就可以通过push解决。active_load_balance_cpu_stop则调用move_one_task函数迁移指定的进程。
上面描述的则是整个pull和push的过程,需要补充的pull触发除了schedule后触发,还有scheduler_tick通过触发中断,调用run_rebalance_domains再调用rebalance_domains触发,不再细数。
void __init sched_init(void)
{
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
}
通过本文,你应该对 Linux 内核的 CPU 负载均衡机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了 CPU 负载均衡机制的作用和影响,以及如何在 Linux 下正确地使用和配置它。我们建议你在使用多核或多处理器的 Linux 系统时,使用 CPU 负载均衡机制来提高系统的性能和效率。同时,我们也提醒你在使用 CPU 负载均衡机制时要注意一些潜在的问题和挑战,如负载均衡策略、能耗、调度延迟等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受 CPU 负载均衡机制的优势和便利。
위 내용은 Linux 커널의 CPU 로드 밸런싱 메커니즘: 원칙, 프로세스 및 최적화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!