
Tongyi Qianwen은 다시 오픈 소스이며 Qwen1.5는 6개 볼륨 모델을 제공하며 성능은 GPT3.5를 초과합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-07 22:15:021598검색
춘절을 앞두고 Tongyi Qianwen Large Model(Qwen) 버전 1.5가 온라인에 출시되었습니다. 오늘 아침, 새 버전 소식이 AI 커뮤니티에 우려를 불러일으켰습니다.
대형 모델의 새 버전에는 0.5B, 1.8B, 4B, 7B, 14B 및 72B의 6가지 모델 크기가 포함됩니다. 그 중 가장 강력한 버전의 성능은 GPT 3.5와 Mistral-Medium을 능가합니다. 이 버전에는 기본 모델과 채팅 모델이 포함되어 있으며 다국어 지원을 제공합니다.
Alibaba Tongyi Qianwen 팀은 관련 기술이 Tongyi Qianwen 공식 웹사이트와 Tongyi Qianwen 앱에도 출시되었다고 밝혔습니다.
또한 오늘의 Qwen 1.5 릴리스에는 다음과 같은 주요 기능이 있습니다.
- 32K 컨텍스트 길이를 지원합니다.
- 기본 + 채팅 모델의 체크포인트를 엽니다.
- Transformers는 로컬에서 실행됩니다.
- GPTQ Int-4/Int8, AWQ 및 GGUF 가중치가 동시에 출시되었습니다.
Tongyi Qianwen 팀은 더욱 발전된 대형 모델을 심사위원으로 활용하여 널리 사용되는 두 가지 벤치마크인 MT-Bench와 Alpaca-Eval에서 Qwen1.5의 예비 평가를 수행했습니다. 평가 결과는 다음과 같습니다.
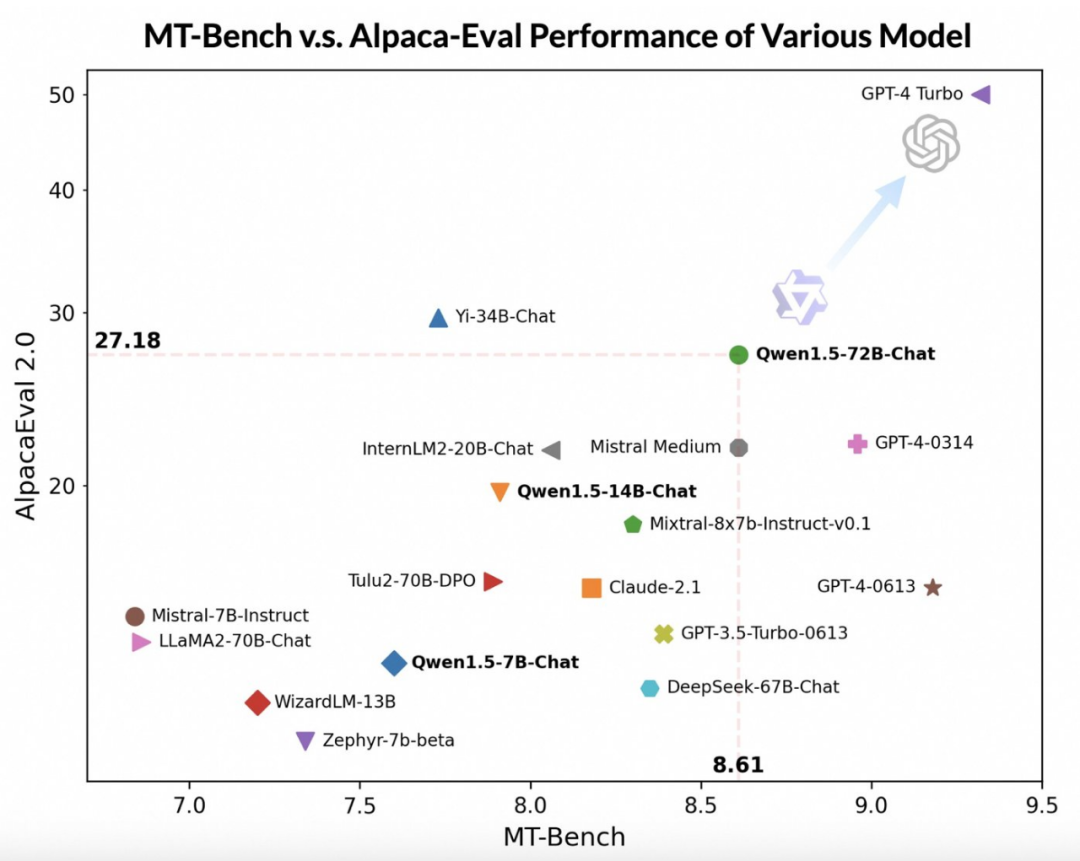
Qwen1.5-72B-Chat 모델은 GPT-4-Turbo에 비해 뒤떨어지지만 MT-Bench 및 Alpaca-Eval v2 테스트에서 인상적인 성능을 보여주었습니다. 잡기 성능. 실제로 Qwen1.5-72B-Chat은 성능면에서 Claude-2.1, GPT-3.5-Turbo-0613, Mixtral-8x7b-instruct 및 TULU 2 DPO 70B를 능가하며 최근 많은 주목을 받고 있는 Mistral Medium 모델과 비슷합니다. . 이는 Qwen1.5-72B-Chat 모델이 자연어 처리에 상당한 강점을 가지고 있음을 보여줍니다.
Tongyi Qianwen 팀은 대형 모델의 점수가 답변의 길이와 관련이 있을 수 있지만 인간 관찰에 따르면 Qwen1.5가 지나치게 긴 답변을 생성하여 점수에 영향을 미치지 않는 것으로 나타났습니다. AlpacaEval 2.0 데이터에 따르면 Qwen1.5-Chat의 평균 길이는 1618로, 이는 GPT-4와 길이가 동일하고 GPT-4-Turbo보다 짧습니다.
Tongyi Qianwen의 개발자는 최근 몇 달 동안 우수한 모델을 구축하고 개발자 경험을 지속적으로 개선하기 위해 열심히 노력해 왔다고 말했습니다.

이전 버전과 비교하여 이번 업데이트는 Chat 모델을 인간의 선호도에 맞게 조정하는 데 중점을 두고 모델의 다국어 처리 기능을 크게 향상시켰습니다. 시퀀스 길이 측면에서 모든 확장 모델은 32768 토큰의 컨텍스트 길이 범위 지원을 구현했습니다. 동시에 사전 훈련된 기본 모델의 품질도 핵심적으로 최적화되어 미세 조정 과정에서 사람들에게 더 나은 경험을 제공할 것으로 예상됩니다.
기본 성능
모델의 기본 성능 평가와 관련하여 Tongyi Qianwen 팀은 MMLU(5-shot), C-Eval, Humaneval, GS8K, BBH 등의 벤치마크 데이터 세트에 대해 Qwen1.5를 수행했습니다. . 평가하다.
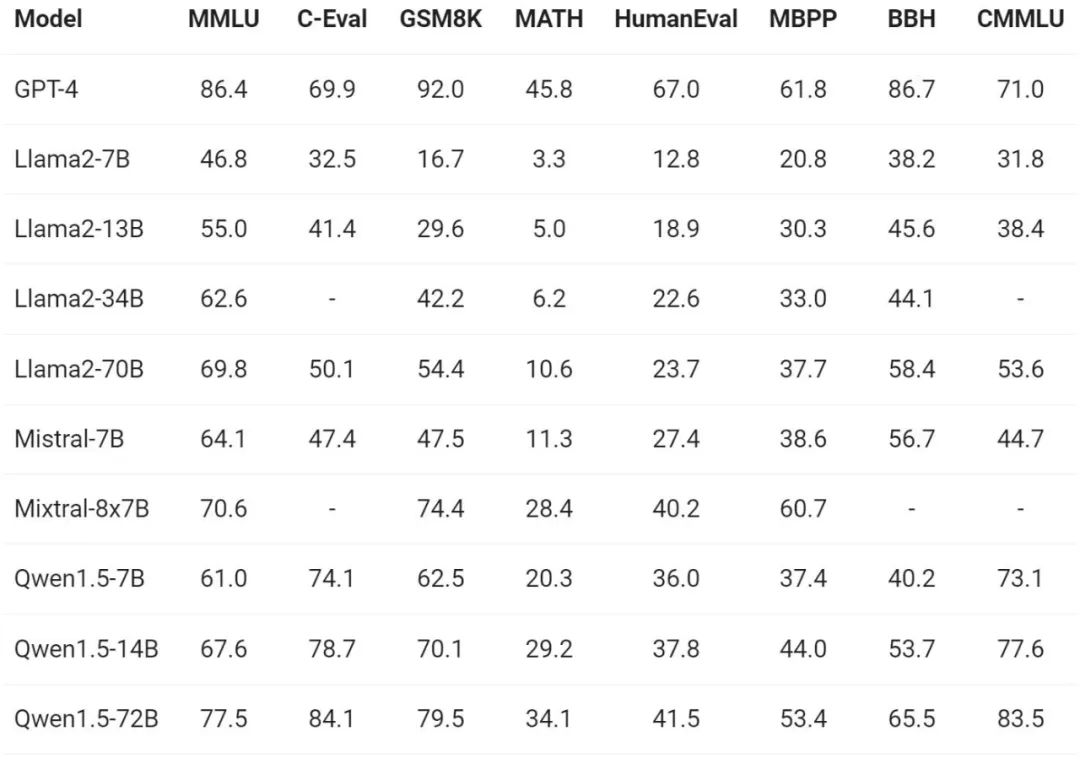
Qwen1.5는 다양한 모델 크기에서 평가 벤치마크에서 강력한 성능을 보여주었습니다. 72B 버전은 모든 벤치마크 테스트에서 Llama2-70B를 능가하여 언어 이해 및 추론 능력에서 성능을 입증했습니다.
최근 소형 모델 제작이 업계에서 가장 핫한 분야 중 하나였습니다. Tongyi Qianwen 팀은 모델 매개변수가 70억 미만인 Qwen1.5 모델을 커뮤니티의 중요한 소형 모델과 비교했습니다.
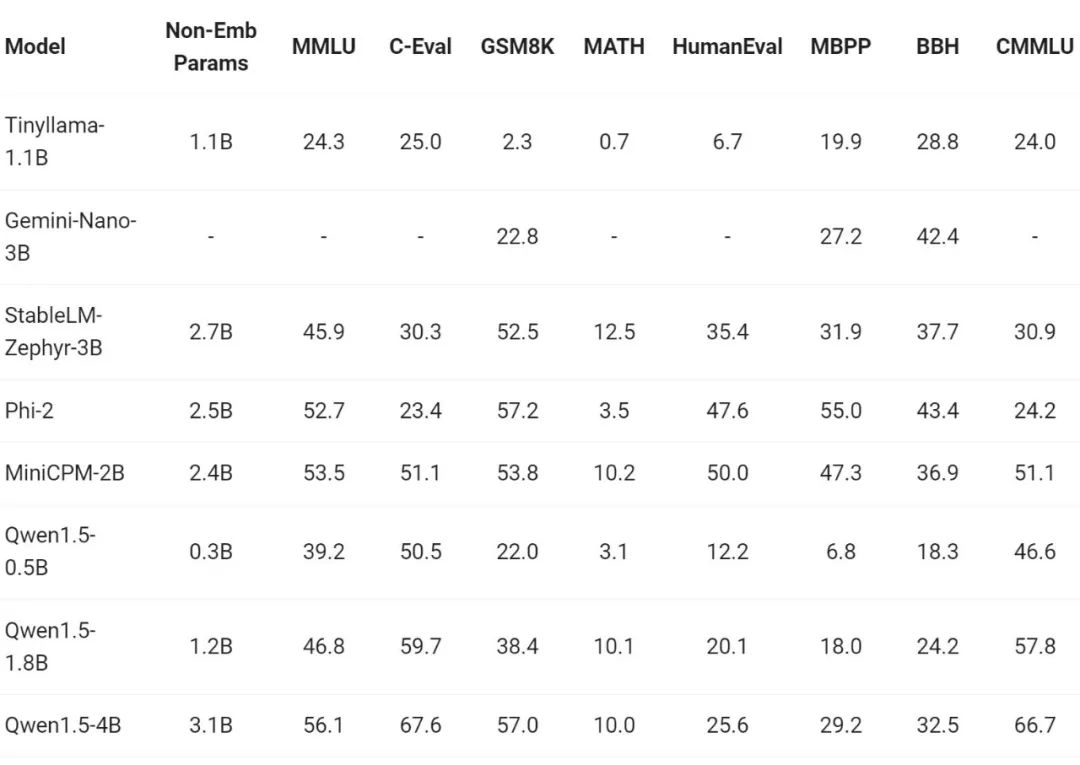
Qwen1.5는 70억 이하의 매개변수 크기 범위에서 업계 최고의 소형 모델과 경쟁이 치열합니다.
다국어 기능
Tongyi Qianwen 팀은 유럽, 동아시아, 동남아시아의 12개 언어로 Base 모델의 다국어 기능을 평가했습니다. Alibaba 연구원들은 오픈 소스 커뮤니티의 공개 데이터 세트에서 시험, 이해, 번역, 수학이라는 4가지 차원을 다루는 다음 표에 표시된 평가 세트를 구성했습니다. 아래 표에는 평가 구성, 평가 지표 및 관련된 특정 언어를 포함하여 각 테스트 세트에 대한 세부 정보가 제공됩니다.
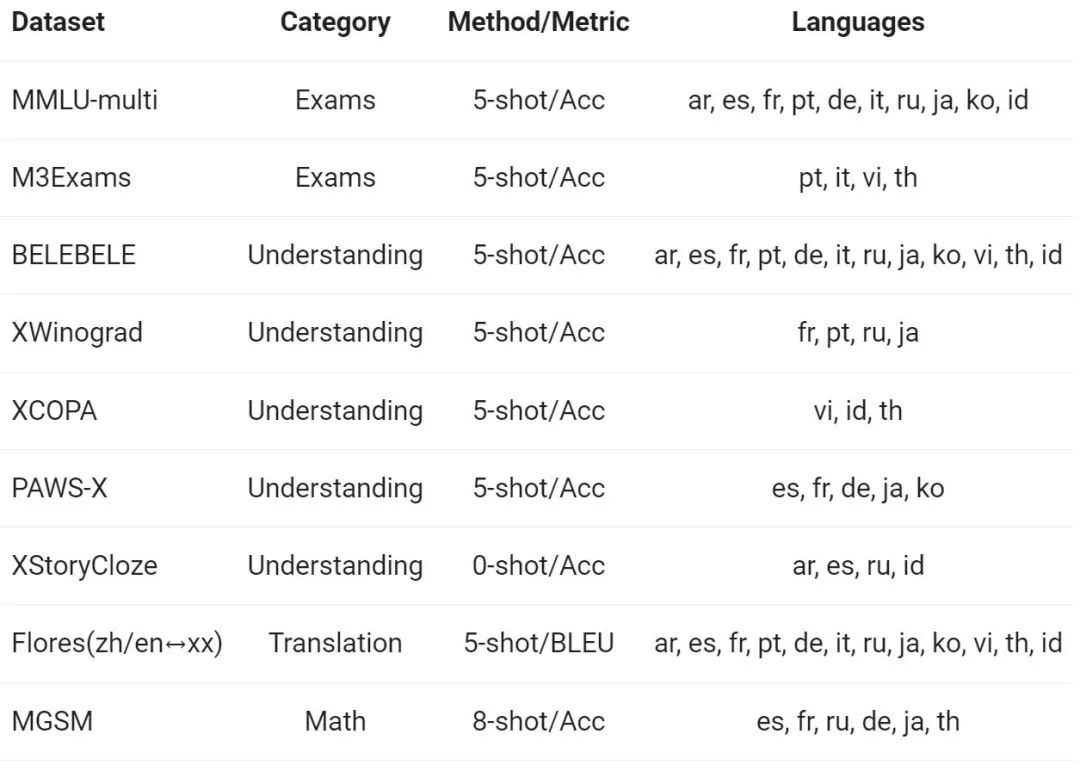
자세한 결과는 다음과 같습니다.
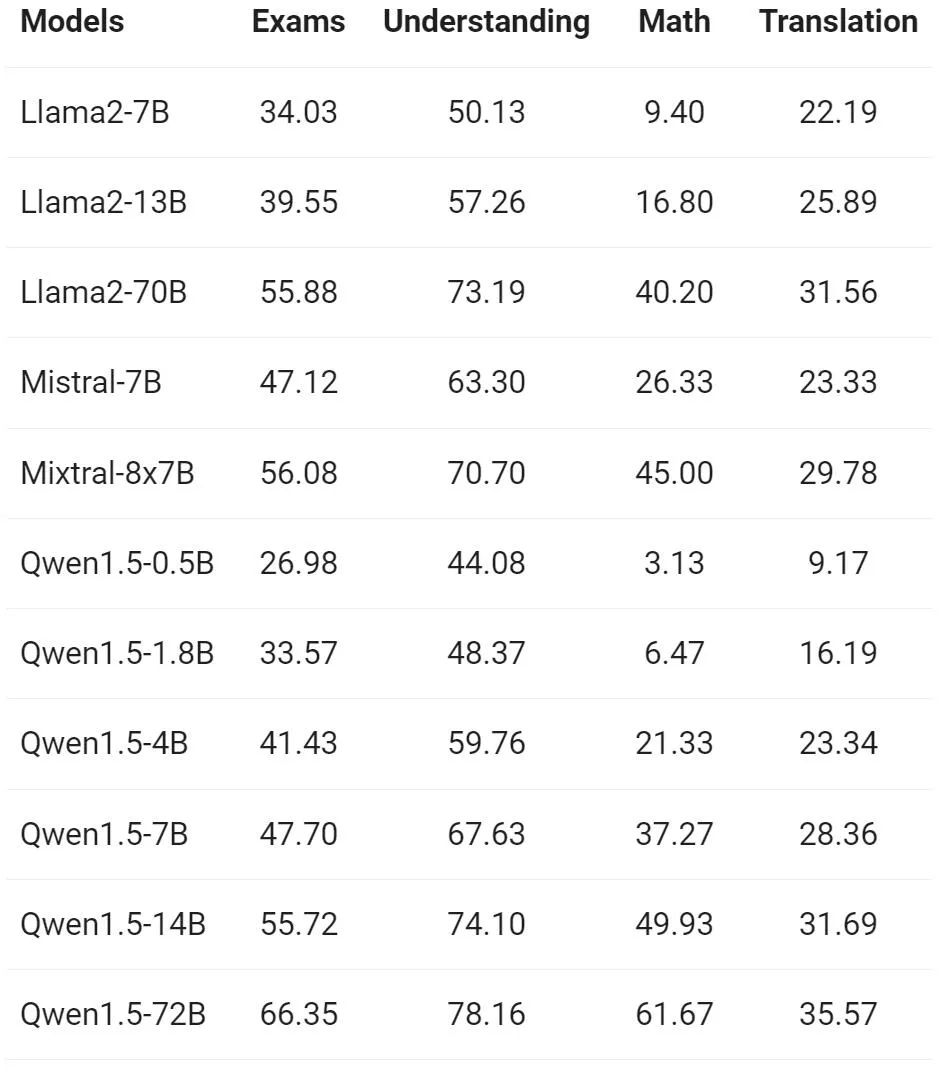
위 결과는 Qwen1.5 Base 모델이 12개 언어의 다국어 능력에서 좋은 성능을 발휘하고 있으며, 교과 지식, 언어 이해, 번역, 수학 등 다양한 차원의 평가에서 좋은 결과를 보여주고 있습니다. 또한 채팅 모델의 다국어 기능 측면에서 다음과 같은 결과를 볼 수 있습니다.
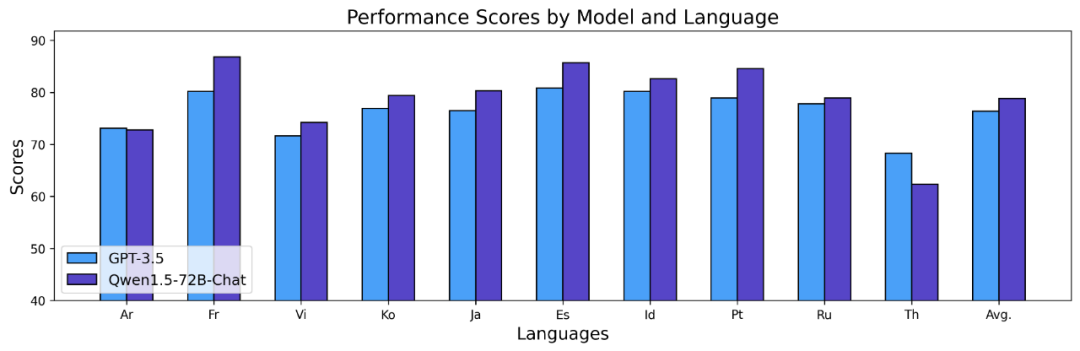
Long Sequences
긴 시퀀스 이해에 대한 수요가 계속 증가함에 따라 Alibaba는 새 버전의 수천 모델의 해당 기능에 대해 물었을 때 Qwen1.5 모델의 전체 시리즈는 32K 토큰의 컨텍스트를 지원합니다. Tongyi Qianwen 팀은 긴 맥락을 기반으로 응답을 생성하는 모델의 능력을 측정하는 L-Eval 벤치마크에서 Qwen1.5 모델의 성능을 평가했습니다.
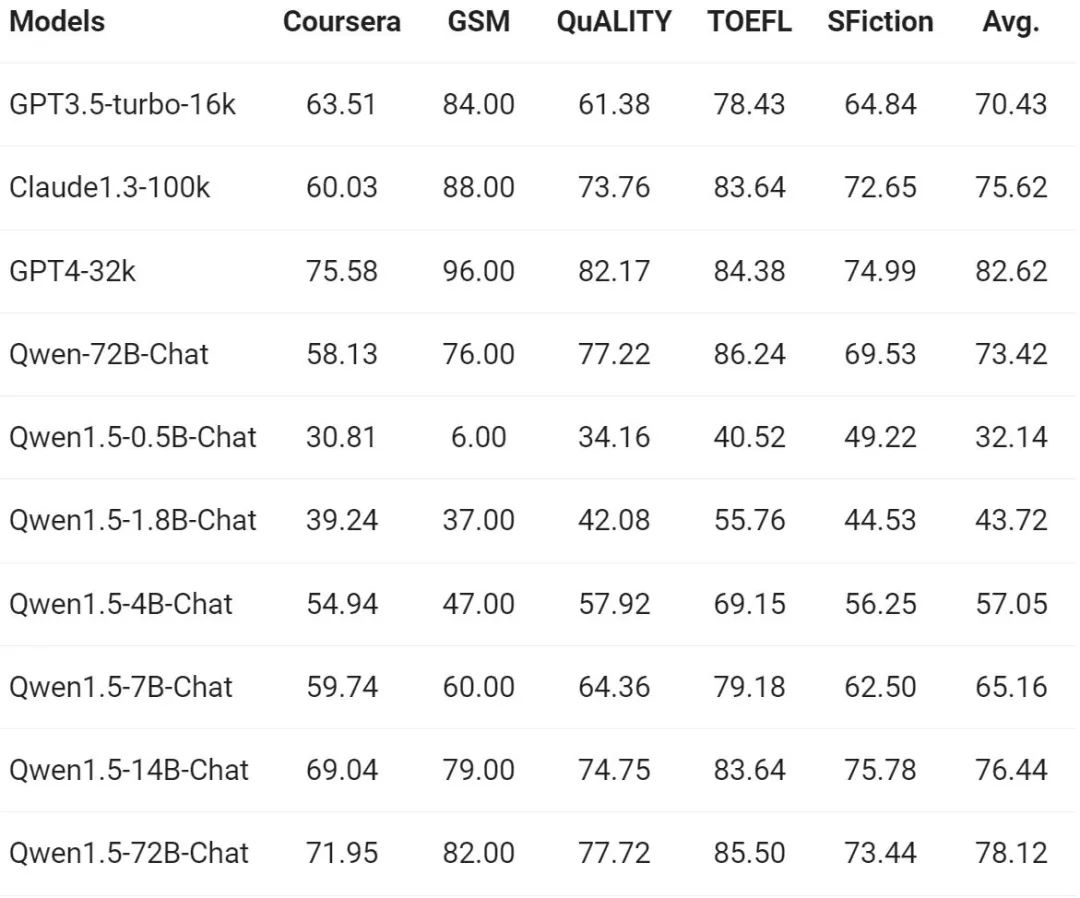
결과에 따르면 Qwen1.5-7B-Chat과 같은 소규모 모델이라도 GPT-3.5와 비슷한 성능을 보일 수 있는 반면, 가장 큰 모델인 Qwen1.5-72B-는 채팅은 GPT4-32k보다 약간 뒤쳐져 있습니다.
위 결과는 32K 토큰 길이 이하에서 Qwen 1.5의 효과만을 보여주고 있으며 모델이 최대 길이 32K만 지원할 수 있다는 의미는 아닙니다. 개발자는 config.json의 max_position_embedding을 더 큰 값으로 수정하여 모델이 더 긴 상황 이해 시나리오에서 만족스러운 결과를 얻을 수 있는지 관찰할 수 있습니다.
외부 시스템에 연결
요즘 일반 언어 모델의 매력 중 하나는 외부 시스템과 인터페이스할 수 있는 잠재적인 능력에 있습니다. 커뮤니티에서 빠르게 떠오르는 작업인 RAG는 환각, 실시간 업데이트 또는 개인 데이터를 얻을 수 없는 등 대규모 언어 모델이 직면한 몇 가지 일반적인 문제를 효과적으로 해결합니다. 또한 언어 모델은 API를 사용하고 지침과 예제를 기반으로 코드를 작성하는 데 있어 강력한 기능을 보여줍니다. 대형 모델은 코드 해석기를 사용하거나 AI 에이전트 역할을 하여 더 넓은 가치를 달성할 수 있습니다.
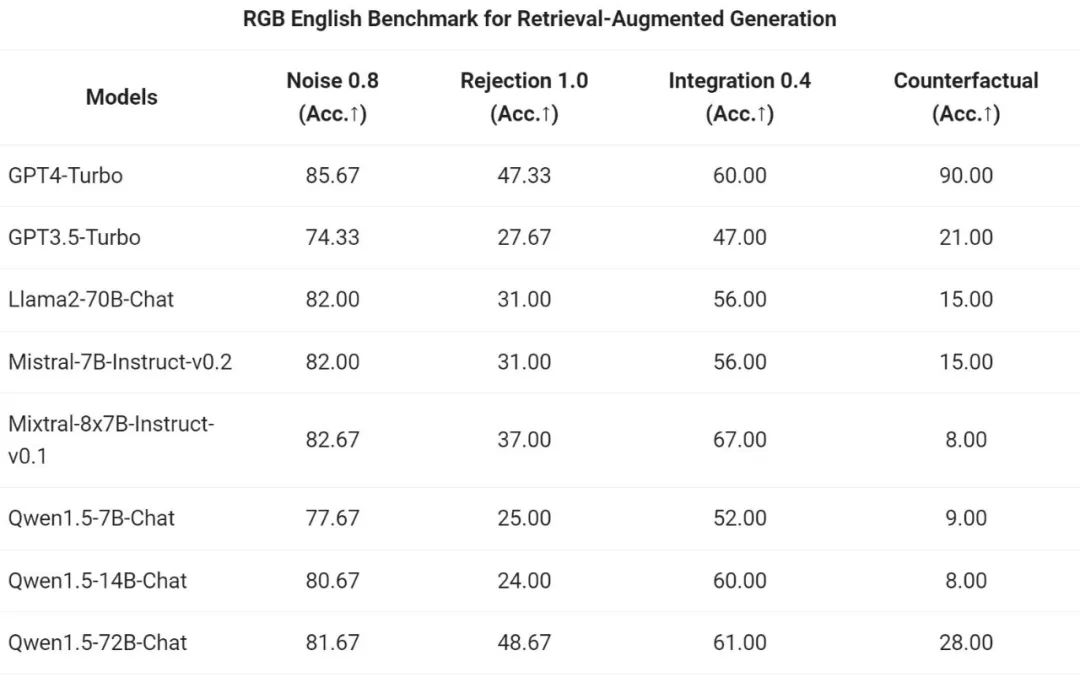
Tongyi Qianwen 팀은 RAG 작업에 대한 Qwen1.5 시리즈 채팅 모델의 엔드투엔드 효과를 평가했습니다. 평가는 중국어 및 영어 RAG 평가에 사용되는 세트인 RGB 테스트 세트를 기반으로 합니다.
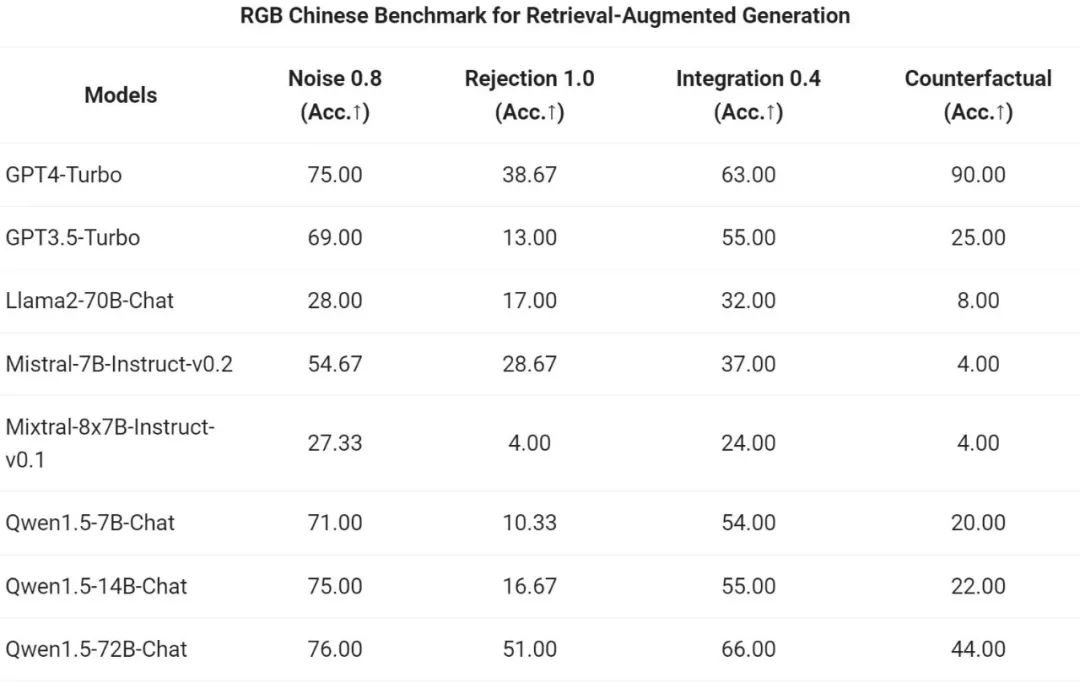
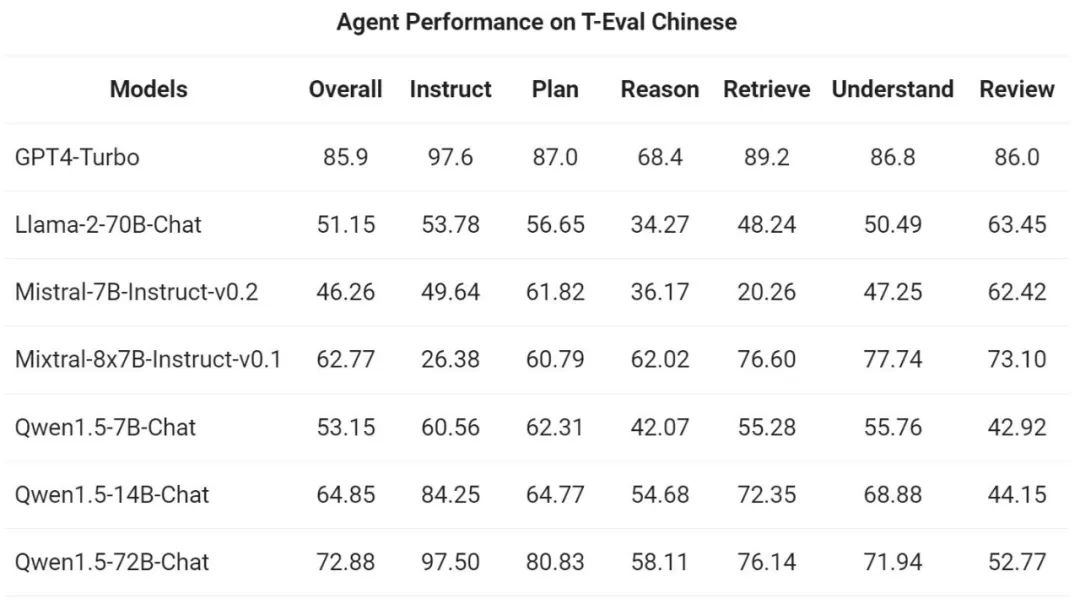
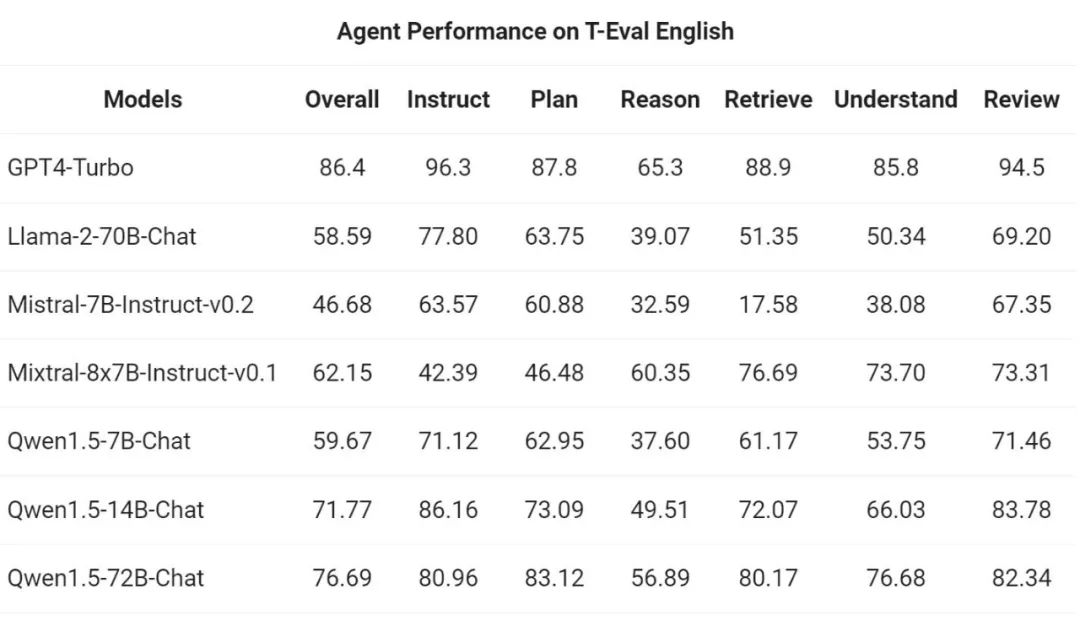
그런 다음 Tongyi Qianwen 팀은 Qwen1.5를 T-A의 일반 에이전트로 평가했습니다. 평가 벤치마크 테스트 실행 기능. 모든 Qwen1.5 모델은 특별히 벤치마크에 최적화되어 있지 않습니다.
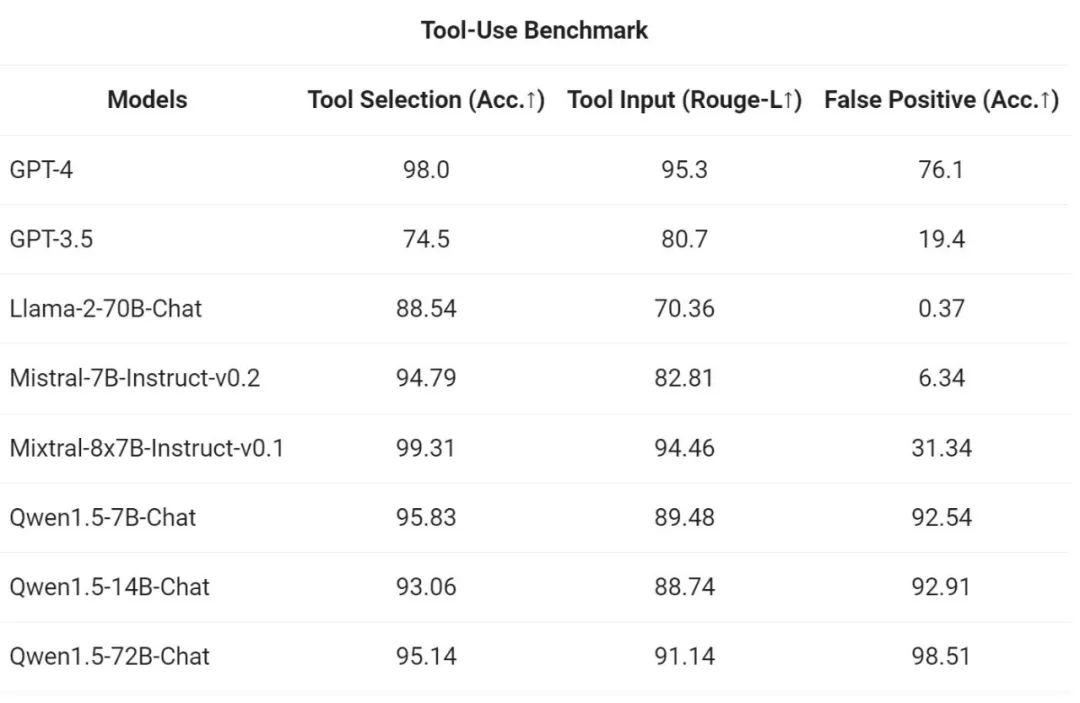
도구 호출 기능을 테스트하기 위해 Alibaba는 자체 오픈 소스 평가 벤치마크를 사용하여 도구를 올바르게 선택하고 호출하는 모델의 기능을 테스트했습니다. 결과는 다음과 같습니다.
마지막으로 Python 코드 해석기가 고급 LLM을 위한 점점 더 강력한 도구가 되면서 Tongyi Qianwen 팀은 이전 오픈 소스를 기반으로 이 도구를 활용할 수 있는 새로운 모델의 능력도 평가했습니다. 평가 벤치마크:
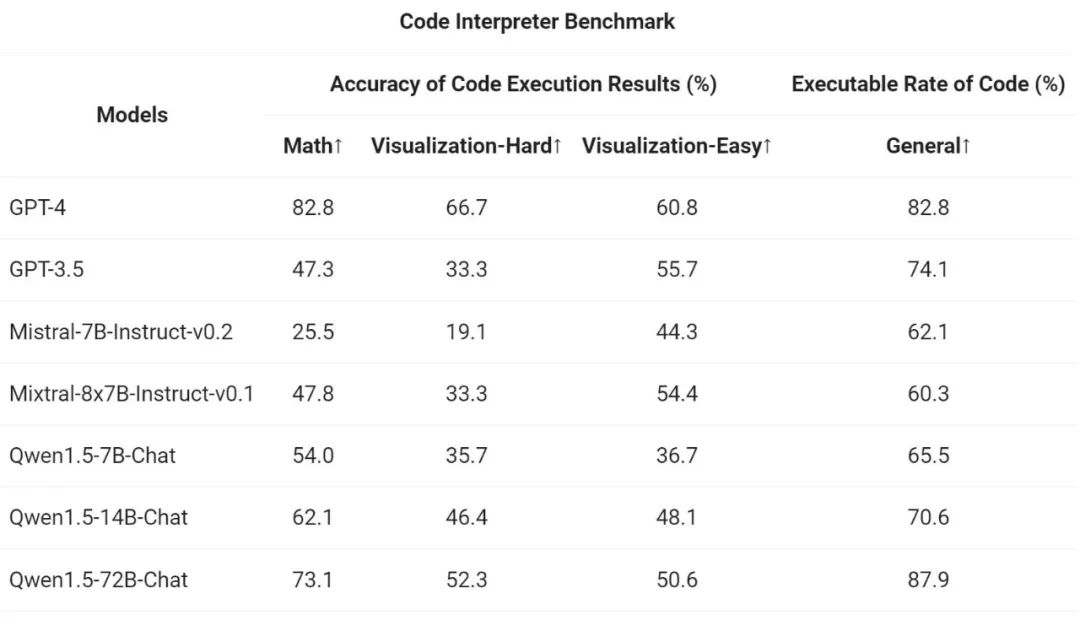
결과에 따르면 Qwen1.5-Chat 모델은 일반적으로 더 큰 Qwen1.5-Chat 모델이 더 작은 모델보다 성능이 뛰어나며 Qwen1.5-72B-Chat은 GPT-4의 도구 사용 성능에 접근합니다. 그러나 수학적 문제 해결 및 시각화와 같은 코드 해석기 작업에서는 가장 큰 Qwen1.5-72B-Chat 모델이라도 코딩 능력 측면에서 GPT-4보다 크게 뒤떨어집니다. Ali는 향후 버전의 사전 훈련 및 정렬 과정에서 모든 Qwen 모델의 코딩 기능을 향상시킬 것이라고 밝혔습니다.
Qwen1.5는 HuggingFace 변환기 코드 베이스와 통합되었습니다. 버전 4.37.0부터 개발자는 사용자 정의 코드(trust_remote_code 옵션 지정)를 로드하지 않고도 변환기 라이브러리 네이티브 코드를 직접 사용하여 Qwen1.5를 사용할 수 있습니다.
오픈 소스 생태계에서 Alibaba는 vLLM, SGLang(배포용), AutoAWQ, AutoGPTQ(정량화용), Axolotl, LLaMA-Factory(미세 조정용) 및 llama.cpp(로컬 LLM 추론용)와 협력했습니다. 등 프레임워크 협력을 통해 이러한 모든 프레임워크는 이제 Qwen1.5를 지원합니다. Qwen1.5 시리즈는 현재 Ollama 및 LMStudio와 같은 플랫폼에서도 사용할 수 있습니다.
위 내용은 Tongyi Qianwen은 다시 오픈 소스이며 Qwen1.5는 6개 볼륨 모델을 제공하며 성능은 GPT3.5를 초과합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!