
Linux 파이프 및 FIFO 애플리케이션 노트

- 王林앞으로
- 2024-02-05 17:30:03874검색
개요
파이프의 가장 일반적인 위치는 다음과 같이 셸입니다.
으아아아위 명령을 실행하기 위해 셸은 각각 실행할 두 개의 프로세스를 생성합니다. ls 和 wc (通过 fork() 和 exec() 완료), 다음과 같습니다.
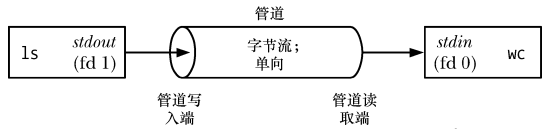
위 그림에서 볼 수 있듯이 파이프라인은 한 프로세스에서 다른 프로세스로 데이터가 흐를 수 있도록 하는 일련의 수도관으로 생각할 수 있으며, 여기서 파이프라는 이름이 유래되었습니다.
위 그림에서 볼 수 있듯이 두 프로세스가 파이프에 연결되어 쓰기 프로세스ls 就将其标准输出(文件描述符为1)连接到来管道的写入段,读取进程 wc가 표준 입력(파일 설명자 0)을 파이프의 읽기 끝 부분에 연결합니다. 실제로 이 두 프로세스는 파이프의 존재를 인식하지 못하고 표준 파일 설명자에서 데이터를 읽고 쓰기만 합니다. 쉘이 작업을 수행해야 합니다.
파이프는 바이트 스트림입니다
파이프는 바이트 스트림입니다. 즉, 파이프를 사용할 때 메시지나 메시지 경계에 대한 개념이 없습니다.
- 파이프에서 데이터를 읽는 프로세스는 쓰기 프로세스에 의해 파이프에 쓰여진 데이터 블록의 크기에 관계없이 모든 크기의 데이터 블록을 읽을 수 있습니다
-
파이프를 통해 전달된 데이터는 순차적입니다. 파이프에서 읽은 바이트의 순서는 파이프에 기록된 순서와 정확히 동일합니다.
lseek()를 사용하여 파이프의 데이터에 무작위로 액세스할 수 없습니다. 파이프라인에서 개별 메시지 개념을 구현해야 하는 경우 애플리케이션에서 이 작업을 완료해야 합니다. 이것이 가능하기는 하지만 이러한 요구 사항이 발생하면 메시지 대기열 및 데이터그램 소켓과 같은 다른 IPC 메커니즘을 사용하는 것이 더 좋습니다.
현재 비어 있는 파이프에서 읽으려고 하면 파이프에 최소 1바이트가 기록될 때까지 차단됩니다.
파이프의 쓰기 끝이 닫히면 파이프에서 데이터를 읽는 프로세스는 파이프에 남아 있는 모든 데이터를 읽은 후 파일의 끝(예:
반환 0)을 보게 됩니다.
read()
파이프라인의 데이터 전송 방향은 단방향입니다. 파이프의 한쪽 끝은 쓰기에 사용되고 다른 쪽 끝은 읽기에 사용됩니다.
다른 UNIX 구현, 특히 System V 릴리스 4에서 발전된 UNIX 구현에서는 파이프가 양방향입니다(소위 스트림 파이프). 양방향 파이프는 UNIX 표준에 지정되어 있지 않으므로 양방향 파이프를 제공하는 구현에서도 이 의미에 의존하지 않는 것이 가장 좋습니다. 대안으로 표준 양방향 통신 메커니즘을 제공하고 그 의미가 스트림 파이프와 동일한 UNIX 도메인 스트림 소켓 쌍(socketpair() 시스템 호출을 통해 생성됨)을 사용할 수 있습니다.
PIPE_BUF 바이트 이하의 쓰기가 원자적으로 이루어지도록 보장합니다
여러 프로세스가 동일한 파이프에 쓰는 경우, 한 번에 쓰는 데이터의 양이 PIPE_BUF 바이트를 초과하지 않으면 쓰여진 데이터가 서로 섞이지 않도록 할 수 있습니다.
SUSv3에서는 원자 쓰기 작업에 대한 실제 상한을 반환하려면 PIPE_BUF가 _POSIX_PIPE_BUF(512)。一个实现应该定义 PIPE_BUF(在 <limits.h></limits.h> 中)并/或允许调用 fpathconf(fd,_PC_PIPE_BUF) 이상이어야 합니다. PIPE_BUF는 UNIX 구현에 따라 다릅니다. 예를 들어 FreeBSD 6.0에서는 해당 값이 512바이트이고, Tru64 5.1에서는 해당 값이 4096바이트이고, Solaris 8에서는 해당 값이 5120바이트입니다. Linux에서 PIPE_BUF 값은 4096입니다.
-
파이프에 기록된 데이터 블록의 크기가 PIPE_BUF 바이트를 초과하면 커널은 전송을 위해 데이터를 여러 개의 작은 조각으로 분할하고 리더가 파이프의 데이터를 소비할 때 후속 데이터를 추가할 수 있습니다. 파이프에 기록됩니다)
write()
하나의 프로세스만 파이프에 데이터를 쓰는 경우(일반적인 상황) PIPE_BUF 값은 중요하지 않습니다 - 그러나 여러 쓰기 프로세스가 있는 경우 큰 데이터 블록 쓰기는 임의 크기의 세그먼트(PIPE_BUF 바이트보다 작을 수 있음)로 분할될 수 있으며 다른 프로세스에서 쓴 데이터와 겹칠 수 있습니다
는 파이프에 작업을 원자적으로 완료하기에 충분한 여유 공간이 있을 때까지 필요한 경우 차단됩니다. 작성된 데이터가 PIPE_BUF 바이트보다 큰 경우 write() 会在必要的时候阻塞知道管道中的可用空间足以原子的完成此操作。如果写入的数据大于 PIPE_BUF 字节,那么 write() 会尽可能的多传输数据以充满整个管道,然后阻塞直到一些读取进程从管道中移除了数据。如果此类阻塞的 write()는 전체 파이프를 채울 수 있도록 최대한 많은 데이터를 전송한 다음 일부 읽기 프로세스가 파이프에서 데이터를 제거할 때까지 차단합니다. 이러한 차단
파이프라인 용량이 제한되어 있습니다
파이프는 실제로 커널 메모리에 유지되는 버퍼입니다. 이 버퍼의 저장 용량은 제한되어 있습니다. 파이프가 채워지면 판독기가 파이프에서 일부 데이터를 제거할 때까지 파이프에 대한 후속 쓰기가 차단됩니다.
SUSv3은 파이프라인의 저장 용량을 지정하지 않습니다. 2.6.11 이전의 Linux 커널에서는 파이프의 저장 용량이 시스템 페이지 크기(예: x86-32의 경우 4096바이트)와 일치하며, Linux 2.6.11부터 파이프의 저장 용량은 65,536입니다. 바이트. 다른 UNIX 구현에서 파이프의 저장 기능은 다를 수 있습니다. 🎜
一般来讲,一个应用程序无需知道管道的实际存储能力。如果需要防止写者进程阻塞,那么从管道中读取数据的进程应该被设计成以尽可能快的速度从管道中读取数据。
创建和使用管道
#include int pipe(int fd[2]);
-
pipe()创建一个新管道 -
成功的调用在数组
fd中返回两个打开的文件描述符,一个表示管道的读取端fd[0],一个表示管道的写入端fd[1]
调用 pipe() 函数时,首先在内核中开辟一块缓冲区用于通信,它有一个读端和一个写端,然后通过 fd 参数传出给用户进程两个文件描述符,fd[0] 指向管道的读端,fd[1] 指向管道的写段。
不要用 fd[0] 写数据,也不要用 fd[1] 读数据,其行为未定义的,但在有些系统上可能会返回 -1 表示调用失败。数据只能从 fd[0] 中读取,数据也只能写入到fd[1],不能倒过来。
与所有文件描述符一样,可以使用 read() 和 write() 系统调用来在管道上执行 IO,一旦向管道的写入端写入数据之后立即就能从管道的读取端读取数据。管道上的 read() 调用会读取的数据量为所请求的字节数与管道中当前存在的字节数两者之间的较小值。当管道为空时,读取操作阻塞。
파이프에서도 stdio 함수를 사용할 수 있습니다(printf()、scanf() 等),只需要首先使用 fdopen() 获取一个与 filedes 中的某个描述符对应的文件流即可。但在这样做的时候需要解决 stdio 버퍼링 문제.
파이프는 프로세스 내 내부 통신에 사용될 수 있습니다.
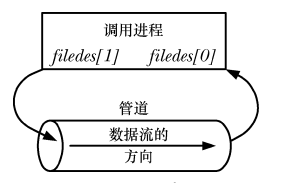
파이프는 친족 관계의 프로세스 내 통신에 사용될 수 있습니다(하위 프로세스는 상위 프로세스의 파일 설명자 복사본을 상속함).
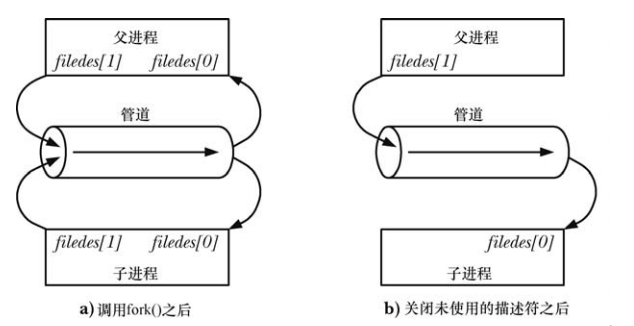
단일 파이프를 전이중으로 사용하거나 해당 읽기/쓰기 끝을 닫지 않고 반이중으로 사용하는 것은 권장되지 않습니다. 두 프로세스가 파이프에서 읽으려고 하면 교착 상태가 발생할 수 있습니다. 동시에 데이터를 가져오면 어떤 프로세스가 먼저 데이터를 성공적으로 읽을지 결정할 수 없으므로 두 프로세스가 데이터를 놓고 경쟁하게 됩니다. 이러한 경쟁 조건이 발생하지 않도록 하려면 일종의 동기화 메커니즘을 사용해야 합니다. 이때 두 프로세스 모두 빈 파이프에서 데이터를 읽으려고 하거나 가득 찬 파이프에 데이터를 쓰려고 하면 교착 상태가 발생할 수 있으므로 교착 상태 문제를 고려해야 합니다.
양방향 데이터 흐름을 원한다면 각 방향에 하나씩 두 개의 파이프를 만들 수 있습니다.
파이프를 통해 관련 프로세스 간의 통신이 가능합니다
사실 파이프는 하위 프로세스를 생성하는 일련의 fork() 호출 이전에 공통 조상 프로세스를 통해 파이프가 생성되는 한 두 개 이상의 관련 프로세스 간의 통신에 사용될 수 있습니다.
사용하지 않는 파이프 파일 설명자를 닫습니다
프로세스가 파일 설명자 제한을 소진하지 않도록 하기 위해서만이 아니라 사용하지 않는 파이프 파일 설명자를 닫습니다.
파이프에서 데이터를 읽는 프로세스는 보유하고 있는 파이프의 쓰기 설명자를 닫으므로 다른 프로세스가 출력을 완료하고 쓰기 설명자를 닫은 후에 리더가 파일의 끝을 볼 수 있습니다. 반면에 읽기 프로세스가 파이프의 쓰기 끝을 닫지 않으면 다른 프로세스가 쓰기 설명자를 닫은 후 리더는 파이프의 모든 데이터를 읽었더라도 파일의 끝을 볼 수 없습니다. 왜냐하면 이때 커널은 최소한 하나의 파이프 쓰기 설명자가 열려 있음을 알고 있기 때문에 read() 차단이 발생합니다.
当一个进程视图向一个管道中写入数据但没有任何进程拥有该管道的打开着的读取描述符时,内核会向写入进程发送一个 SIGPIPE 信号,默认情况下,这个信号将会杀死进程,但进程可以选择忽略或者设置信号处理器,这样 write() 将因为 EPIPE 错误而失败。收到 SIGPIPE 信号和得到 EPIPE 错误对于标识管道的状态是有意义的,这就是为什么需要关闭管道的未使用读取描述符的原因。如果写入进程没有关闭管道的读取端,那么即使在其他进程已经关闭了管道的读取端之后,写入进程仍然能够向管道写入数据,最后写入进程会将数据充满整个管道,后续的写入请求会将永远阻塞。
使用管道连接过滤器
当管道被创建之后,为管道的两端分配的文件描述符是可用描述符中数值最小的两个,由于通常情况下,进程已经使用了描述符 0,1,2,因此会为管道分配一些数值更大的描述符。如果需要使用管道连接两个过滤器(即从 stdin 读取和写入到 stdout),使得一个程序的标准输出被重定向到管道中,就需要采用复制文件描述符技术。
int pfd[2]; pipe(pfd); close(STDOUT_FILENO); dup2(pfd[1],STDOUT_FILENO);
上面这些调用的最终结果是进程的标准输出被绑定到管道的写入端,而对应的一组调用可以用来将进程的标准的输入绑定到管道的读取端上。
通过管道与 shell 命令进行通信: popen()
#include FILE *popen (const char *command, const char *mode);
-
pipe()和close()是最底层的系统调用,它的进一步封装是popen()和pclose() -
popen()函数创建了一个管道,然后创建了一个子进程来执行 shell,而 shell 又创建了一个子进程来执行command字符串 -
mode参数是一个字符串: -
-
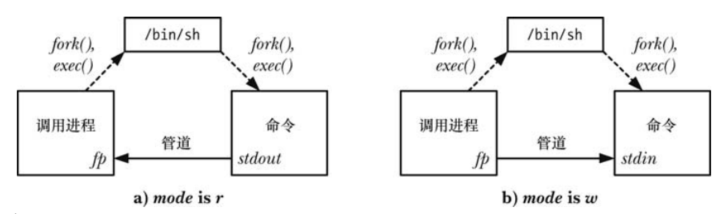
它确定调用进程是从管道中读取数据(
mode是r)还是将数据写入到管道中(mode是w) -
由于管道是向的,因此无法在执行的
command中进行双向通信 -
mode的取值确定了所执行的命令的标准输出是连接到管道的写入端还是将其标准输入连接到管道的读取端
-
它确定调用进程是从管道中读取数据(
-
popen()在成功时会返回可供stdio库函数使用的文件流指针。当发生错误时,popen()会返回NULL并设置errno以标示出发生错误的原因 -
在
popen()调用之后,调用进程使用管道来读取command的输出或使用管道向其发送输入。与使用pipe()创建的管道一样,当从管道中读取数据时,调用进程在command关闭管道的写入端之后会看到文件结束;当向管道写入数据时,如果command已经关闭了管道的读取端,那么调用进程就会收到SIGPIPE信号并得到EPIPE错误
#include int pclose ( FILE * stream);
-
一旦IO结束之后可以使用
pclose()函数关闭管道并等待子进程中的 shell 终止(不应该使用fclose()函数,因为它不会等待子进程。) -
pclose()성공하면 하위 프로세스에 있는 셸의 종료 상태가 반환됩니다(즉, 셸이 신호에 의해 종료되지 않는 한 셸에서 실행한 마지막 명령의 종료 상태) -
및
시스템 (), 쉘을 실행할 수 없는 경우system()一样,如果无法执行shell,那么pclose()会返回一个值就像子进程中的 shell 通过调用_exit(127)는_exit(127)동일 -
또 다른 오류가 발생하면
pclose()는 -1을 반환합니다. 발생할 수 있는 오류 중 하나는 종료 상태를 알 수 없다는 것입니다
하위 프로세스에서 쉘 상태를 가져오기 위해 대기를 수행할 때 SUSv3에서는 pclose() 与 system() 一样,即在内部的 waitpid()가 system()은 동일합니다. 즉, 내부적으로 waitpid() 통화가 끝난 후 자동으로 통화를 다시 시작합니다. 신호 처리기에 의해 중단되었습니다.
그리고 system() 一样,在特权进程中永远都不应该使用 popen().
popen장점과 단점:
-
장점: Linux의 모든 매개변수 확장은 셸에서 수행됩니다. 따라서 시작 시
command命令之前程序先启动 shell 来分析command字符串,就可以使用各种 shell 扩展(比如通配符),这样我们可以通过popen()매우 복잡한 쉘 명령을 호출하세요 -
단점: 각
popen()调用,不仅要启动一个被请求的程序,还需要启动一个 shell。即每一个popen()에 대해 두 개의 프로세스가 시작됩니다.从效率和资源的角度看,popen()函数的调用比正常方式要慢一些
pipe()` VS `popen()
-
pipe()是一个底层调用,popen()是一个高级的函数 -
pipe()单纯的创建管道,而popen()创建管道的同时fork()子进程 -
popen()在两个进程中传递数据时需要调用 shell 来解释请求命令;pipe()在两个进程中传递数据不需要启动 shell 来解释请求命令,同时提供了对读写数据的更多控制(popen()必须时 shell 命令,pipe()则无硬性要求) -
popen()函数是基于文件流(FILE)工作的,而pipe()是基于文件描述符工作的,所以在使用pipe()后,数据必须要用底层的read()和write()调用来读取和发送
管道和 stdio 缓冲
由于 popen() 调用返回的文件流指针没有引用一个终端,因此 stdio 库会对这种流应用块缓冲。这意味着当 mode 的值为 w 来调用 popen() 时,默认情况下只有当 stdio 缓冲区被充满或者使用 pclose() 关闭了管道之后才会被发送到管道的另一端的子进程。在很多情况下,这种处理方式是不存在问题的。하지만 하위 프로세스가 파이프에서 데이터를 즉시 수신할 수 있는지 확인해야 한다면 정기적으로 호출해야 합니다. fflush() 或使用 setbuf(fp, NULL) 调用禁用 stdio 缓冲。当使用 pipe() 系统调用创建管道,然后使用 fdopen() 이 기술은 파이프의 쓰기 끝 부분에 해당하는 stdio 스트림을 얻을 때도 사용할 수 있습니다
부르면 popen() 的进程正在从管道中读取数据(即 mode 是 r),那么事情就不是那么简单了。在这样情况下如果子进程正在使用 stdio 库,那么——除非它显式地调用了 fflush() 或 setbuf() ,其输出只有在子进程填满 stdio 缓冲器或调用了 fclose() 之后才会对调用进程可用。(如果正在从使用 pipe() 创建的管道中读取数据并且向另一端写入数据的进程正在使用 stdio 库,那么同样的规则也是适用的。)如果这是一个问题,那么能采取的措施就比较有限的,除非能够修改在子进程中运行的程序的源代码使之包含对 setbuf() 或 fflush()이 부릅니다.
소스 코드를 수정할 수 없는 경우 의사 터미널을 사용하여 파이프를 교체할 수 있습니다. 의사 터미널은 프로세스에 터미널로 나타나는 IPC 채널입니다. 결과적으로 stdio 라이브러리는 버퍼의 데이터를 한 줄씩 출력합니다.
명명된 파이프(FIFO)
위 파이프라인은 프로세스 간 통신을 구현하지만 특정 제한 사항이 있습니다.
- 익명 파이프는 혈액으로 연결된 프로세스 간에만 통신할 수 있습니다
- 하나의 프로세스만 쓰고 다른 프로세스는 읽을 수 있도록 할 수 있습니다. 동시에 두 가지 작업을 모두 수행해야 한다면 파이프를 다시 열어야 합니다
두 프로세스 간의 통신을 활성화하기 위해 명명된 파이프( 명명된 파이프 또는 FIFO)가 제안되었습니다.
- FIFO 与管道的区别:FIFO 在文件系统中拥有一个名称,并且其打开方式与打开一个普通文件一样,能够实现任何两个进程之间通信。而匿名管道对于文件系统是不可见的,它仅限于在父子进程之间的通信
-
一旦打开了 FIFO,就能在它上面使用与操作管道和其他文件的系统调用一样的 IO 系统调用
read(),write(),close()。与管道一样,FIFO 也有一个写入端和读取端,并且总是遵循先进先出的原则,即第一个进来的数据会第一个被读走 - 与管道一样,当所有引用 FIFO 的描述符都关闭之后,所有未被读取的数据都将被丢弃
-
使用
mkfifo命令可以在 shell 中创建一个 FIFO:
mkfifo [-m mode] pathname
-
pathname是创建的 FIFO 的名称,-m选项指定权限mode,其工作方式与chmod命令一样 -
fstat()和stat()函数会在stat结构的st_mode字段返回S_IFIFO,使用ls -l列出文件时,FIFO 文件在第一列的类型为p,ls -F会在 FIFO 路径名后面附加管道符|
#include #include int mkfifo(const char *pathname,mode_t mode);
-
mode参数指定了新 FIFO 的权限,这些权限会按照进程的umask值来取掩码 - 一旦创建了 FIFO,任何进程都能够打开它,只要它通过常规的文件权限检测
-
使用 FIFO 时唯一明智的做法是在两端分别设置一个读取进程和一个写入进程。这样在默认情况下,打开一个 FIFO 以便读取数据(
open() O_RDONLY标记)将会阻塞直到另一个进程打开 FIFO 以写入数(open() O_WRONLY标记)为止。相应地,打开一个 FIFO 以写入数据将会阻塞直到另一个进程打开 FIFO 以读取数据为止。换句话说,打开一个 FIFO 会同步读取进程和写入进程。如果一个 FIFO 的另一端已经打开(可能是因为一对进程已经打开了 FIFO 的两端),那么open()调用会立即成功。
在大多数 Unix 实现上(包含 Linux),当打开一个 FIFO 时可以通过指定 O_RDWR 标记来绕过打开 FIFO 时的阻塞行为。这样,open() 会立即返回,但无法使用返回的文件描述符在 FIFO 上读取和写入数据。这种做法破坏了 FIFO 的 IO 模型,SUSv3 明确指出以 O_RDWR 标记打开一个 FIFO 的结果是未知的,因此出于可移植性的原因,开发人员不应该使用这项技术。对于那些需要避免在打开 FIFO 时发生阻塞的需求,open() 的 O_NONBLOCK 标记提供了一种标准化的方法来完成这个任务:
open(const char *path, O_RDONLY | O_NONBLOCK); open(const char *path, O_WRONLY | O_NONBLOCK);
在打开一个 FIFO 时避免使用 O_RDWR 标记还有另外一个原因,当采用那种方式调用 open() 之后,调用进程在从返回的文件描述符中读取数据时永远都不会看到文件结束,因为永远都至少存在一个文件描述符被打开着以等待数据被写入 FIFO,即进程从中读取数据的那个描述符。
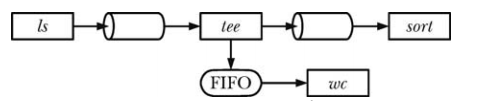
使用 FIFO 和 tee 创建双重管道线
shell 管道线的其中一个特征是它们是线性的,管道线中的每个进程都能读取前一个进程产生的数据并将数据发送到其后一个进程中,使用 FIFO 就能够在管道线中创建子进程,这样除了将一个进程的输出发送给管道线中的后面一个进程之外,还可以复制进程的输出并将数据发送到另一个进程中,要完成这个任务就需要使用 tee 命令,它将其从标准输入中读取到的数据复制两份并输出:一份写入标准输出,另一份写入到通过命令行参数指定的文件中。
mkfifo myfifo wc -l
非阻塞 IO
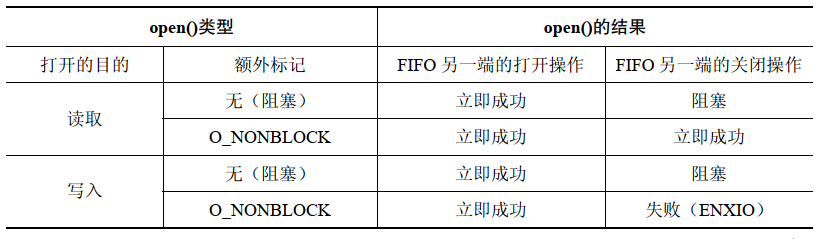
当一个进程打开一个 FIFO 的一端时,如果 FIFO 的另一端还没有被打开,那么该进程会被阻塞。但有些时候阻塞并不是期望的行为,而这可以通过在调用 open() 时指定 O_NONBLOCK 标记来实现。
如果 FIFO 的另一端已经被打开,那么 O_NONBLOCK 对 open() 调用不会产生任何影响,它会像往常一样立即成功地打开 FIFO。只有当 FIFO 的另一端还没有被打开的时候 O_NONBLOCK 标记才会起作用,而具体产生的影响则依赖于打开 FIFO 是用于读取还是用于写入的:
-
如果打开 FIFO 是为了读取,并且 FIFO 的写入端当前已经被打开,那么
open()调用会立即成功(就像 FIFO 的另一端已经被打开一样) -
如果打开 FIFO 是为了写入,并且还没有打开 FIFO 的另一端来读取数据,那么
open()调用会失败,并将errno设置为ENXIO
为读取而打开 FIFO 和为写入而打开 FIFO 时 O_NONBLOCK 标记所起的作用不同是有原因的。当 FIFO 的另一个端没有写者时打开一个 FIFO 以便读取数据是没有问题的,因为任何试图从 FIFO 读取数据的操作都不会返回任何数据。但当试图向没有读者的 FIFO 中写入数据时将会导致 SIGPIPE 信号的产生以及 write() 返回 EPIPE 错误。
在 FIFO 上调用 open() 的语义总结如下:
在打开一个 FIFO 时,使用 O_NOBLOCK 标记存在两个目的:
-
它允许单个进程打开一个 FIFO 的两端,这个进程首先会在打开 FIFO 时指定
O_NOBLOCK标记以便读取数据,接着打开 FIFO 以便写入数据 - 它防止打开两个 FIFO 的进程之间产生死锁
例如,下面的情况将会发生死锁:

非阻塞 read() 和 write()
O_NONBLOCK 标记不仅会影响 open() 的语义,而且还会影响——因为在打开的文件描述中这个标记仍然被设置着——后续的 read() 和 write() 调用的语义。
有些时候需要修改一个已经打开的 FIFO(或另一种类型的文件)的 O_NONBLOCK 标记的状态,具体存在这个需求的场景包括以下几种:
-
使用
O_NONBLOCK打开了一个 FIFO 但需要后续的read()和write()在阻塞模式下运行 -
需要启用从
pipe()返回的一个文件描述符的非阻塞模式。更一般地,可能需要更改从除open()调用之外的其他调用中,如每个由 shell 运行的新程序中自动被打开的三个标准描述符的其中一个或socket()返回的文件描述符,取得的任意文件描述符的非阻塞状态 -
出于一些应用程序的特殊需求,需要切换一个文件描述符的
O_NONBLOCK设置的开启和关闭状态
当碰到上面的需求时可以使用 fcntl() 启用或禁用打开着的文件的 O_NONBLOCK 状态标记。通过下面的代码(忽略的错误检查)可以启用这个标记:
int flags; flags = fcntl(fd, F_GETFL); flags != O_NONBLOCK; fcntl(fd, F_SETFL, flags);
通过下面的代码可以禁用这个标记:
flags = fcntl(fd, F_GETFL); flags &= ~O_NONBLOCK; fcntl(fd, F_SETFL, flags);
管道和 FIFO 中 read() 和 write() 的语义
FIFO 上的 read() 操作:
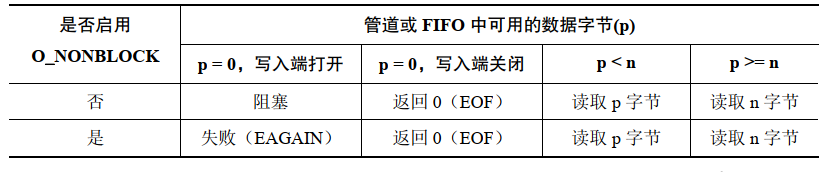
只有当没有数据并且写入端没有被打开时阻塞和非阻塞读取之间才存在差别。在这种情况下,普通的 read() 会被阻塞,而非阻塞 read() 会失败并返回 EAGAIN 错误。
当 O_NONBLOCK 标记与 PIPE_BUF 限制共同起作用时 O_NONBLOCK 标记对象管道或 FIFO 写入数据的影响会变得复杂。
FIFO 上的 write() 操作:
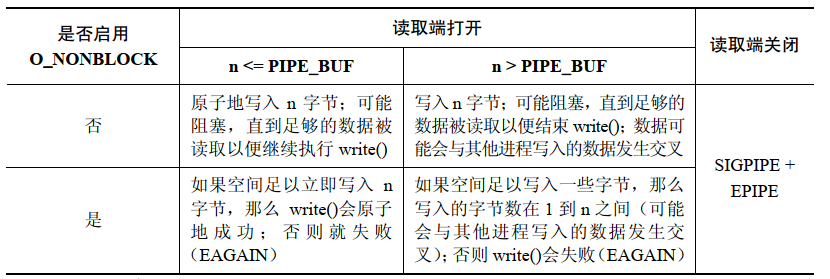
-
데이터를 즉시 전송할 수 없는 경우
O_NONBLOCK标记会导致在一个管道或 FIFO 上的write()失败(错误是EAGAIN)。这意味着当写入了PIPE_BUF字节之后,如果在管道或 FIFO 中没有足够的空间了,那么write()会失败,因为内核无法立即完成这个操作并且无法执行部分写入,否则就会破坏不超过PIPE_BUF바이트 쓰기 작업의 원자성에 대한 요구 사항 -
한번에 쓰는 데이터의 양이
PIPE_BUF字节时,该写入操作无需是原子的。因此,write()会尽可能多地传输字节(部分写)以充满管道或 FIFO。在这种情况下,从write()返回的值是实际传输的字节数,并且调用者随后必须要进行重试以写入剩余的字节。但如果管道或 FIFO 已经满了,从而导致哪怕连一个字节都无法传输了,那么write()会失败并返回EAGAIN오류 를 초과하는 경우
위 내용은 Linux 파이프 및 FIFO 애플리케이션 노트의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!