
Linux 바이트 정렬에 관한 사항

- WBOY앞으로
- 2024-02-05 11:06:101119검색
최근에 프로젝트를 진행하다가 문제가 발생했습니다. ARM에서 실행되는 ThreadX는 DSP와 통신할 때 메시지 큐를 사용하여 메시지를 전달합니다(최종 구현에서는 인터럽트 및 공유 메모리 방법을 사용함). 그러나 실제 작동 중에 ThreadX가 자주 충돌하는 것으로 나타났습니다. 조사 결과 메시지를 전달하는 구조가 바이트 정렬을 고려하지 않는다는 사실에 문제가 있는 것으로 나타났습니다.
C언어의 바이트 정렬 문제를 정리해서 공유해드리고자 합니다.
1. 컨셉
바이트 정렬은 메모리 내 데이터 위치와 관련이 있습니다. 변수의 메모리 주소가 정확히 해당 길이의 정수배인 경우 자연 정렬되었다고 합니다. 예를 들어 32비트 CPU에서는 정수 변수의 주소가 0x00000004라고 가정하면 자연스럽게 정렬됩니다.
먼저 비트, 바이트, 단어가 무엇인지 이해하세요
| 이름 | 영어 이름 | 의미 |
|---|---|---|
| bits | 비트 | 1개의 이진수를 1비트라고 합니다 |
| 바이트 | 바이트 | 8개의 바이너리 비트를 1바이트라고 합니다 |
| 단어 | 단어 | 한 번에 거래를 처리하기 위해 컴퓨터가 사용하는 고정 길이 |
길이
워드의 비트 수, 현대 컴퓨터의 워드 길이는 일반적으로 16, 32 또는 64비트입니다. (일반적으로 N비트 시스템의 워드 길이는 N/8바이트입니다.)
서로 다른 CPU는 한 번에 서로 다른 수의 데이터 비트를 처리할 수 있습니다. 32비트 CPU는 한 번에 32비트 데이터를 처리할 수 있으며, 64비트 CPU는 한 번에 64비트 데이터를 처리할 수 있습니다. 단어 길이.
소위 단어 길이를 단어라고도 합니다. 16비트 CPU에서 한 워드는 정확히 2바이트인 반면, 32비트 CPU에서는 한 워드는 4바이트입니다. 문자를 단위로 하면 위쪽으로는 더블문자(2자)와 쿼드문자(4자)가 있습니다.
2. 정렬 규칙
표준 데이터 유형의 경우 주소는 길이의 정수배만 있으면 됩니다. 비표준 데이터 유형은 다음 원칙에 따라 정렬됩니다. 배열: 기본 데이터 유형에 따라 정렬되면 다음과 같습니다. 자연스럽게 정렬될 것입니다. Union: 가장 큰 길이를 포함하는 데이터 유형을 기준으로 정렬됩니다. 구조: 구조의 각 데이터 유형은 정렬되어야 합니다.
3. 고정 바이트 정렬 비트 수를 제한하는 방법은 무엇입니까?
1. 기본
기본적으로 C 컴파일러는 자연 경계 조건에 따라 각 변수 또는 데이터 단위에 공간을 할당합니다. 일반적으로 다음 방법을 통해 기본 경계 조건을 변경할 수 있습니다.
2. #프라그마 팩(n)
· #pragma pack (n) 지시어를 사용하면 C 컴파일러는 n 바이트 단위로 정렬합니다. · 사용자 정의 바이트 정렬을 취소하려면 #pragma pack() 지시문을 사용합니다.
#pragma pack(n)은 변수를 n바이트 정렬로 설정하는 데 사용됩니다. n바이트 정렬은 변수가 저장되는 시작 주소의 오프셋에 대해 두 가지 상황이 있음을 의미합니다.
- n이 변수가 차지하는 바이트 수보다 크거나 같은 경우 오프셋은 기본 정렬을 충족해야 합니다
- n이 변수 유형이 차지하는 바이트 수보다 작은 경우 오프셋은 n의 배수이며 기본 정렬을 충족할 필요가 없습니다.
구조체의 전체 크기에도 제약이 있습니다. n이 모든 멤버 변수 유형이 차지하는 바이트 수보다 크거나 같으면 구조의 전체 크기는 해당 유형이 차지하는 공간의 배수가 되어야 합니다. 가장 큰 공백을 갖는 변수입니다. 그렇지 않으면 n 배수여야 합니다.
3.__속성
또한 다음과 같은 방법이 있습니다: · __attribute((aligned (n))), n 바이트의 자연 경계에 구조체 멤버를 정렬할 수 있습니다. 구조의 멤버 길이가 n보다 큰 경우 가장 큰 멤버의 길이에 따라 정렬됩니다. · attribute ((packed)), 컴파일 중에 구조의 최적화된 정렬을 취소하고 실제 점유된 바이트 수에 따라 정렬합니다.
3. 컴파일.align
어셈블리 코드는 일반적으로 .align을 사용하여 바이트 정렬 비트 수를 지정합니다.
.align: 데이터 정렬을 지정하는 데 사용되며 형식은 다음과 같습니다.
으아악사용되지 않는 저장 영역을 특정 정렬의 값으로 묶습니다. 첫 번째 값은 4, 8, 16 또는 32의 정렬을 나타냅니다. 두 번째 표현식 값은 채워진 값을 나타냅니다.
四、为什么要对齐?
操作系统并非一个字节一个字节访问内存,而是按2,4,8这样的字长来访问。因此,当CPU从存储器读数据到寄存器,IO的数据长度通常是字长。如32位系统访问粒度是4字节(bytes), 64位系统的是8字节。当被访问的数据长度为n字节且该数据地址为n字节对齐时,那么操作系统就可以高效地一次定位到数据, 无需多次读取,处理对齐运算等额外操作。数据结构应该尽可能地在自然边界上对齐。如果访问未对齐的内存,CPU需要做两次内存访问。
字节对齐可能带来的隐患:
代码中关于对齐的隐患,很多是隐式的。比如在强制类型转换的时候。例如:
unsigned int i = 0x12345678; unsigned char *p=NULL; unsigned short *p1=NULL; p=&i; *p=0x00; p1=(unsigned short *)(p+1); *p1=0x0000;
最后两句代码,从奇数边界去访问unsignedshort型变量,显然不符合对齐的规定。在x86上,类似的操作只会影响效率,但是在MIPS或者sparc上,可能就是一个error,因为它们要求必须字节对齐.
五、举例
例1:os基本数据类型占用的字节数
首先查看操作系统的位数
在64位操作系统下查看基本数据类型占用的字节数:
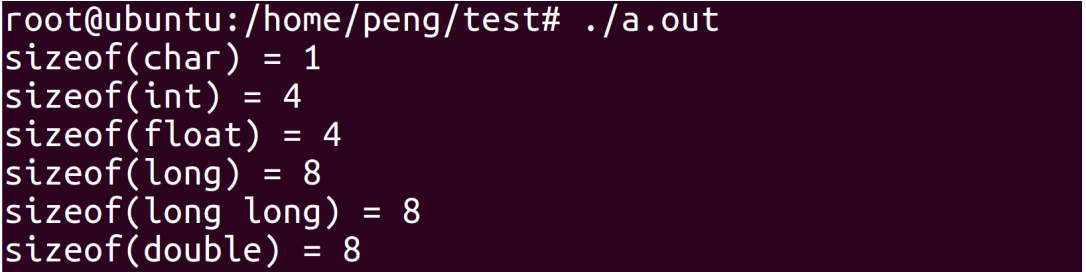
#include
int main()
{
printf("sizeof(char) = %ld\n", sizeof(char));
printf("sizeof(int) = %ld\n", sizeof(int));
printf("sizeof(float) = %ld\n", sizeof(float));
printf("sizeof(long) = %ld\n", sizeof(long));
printf("sizeof(long long) = %ld\n", sizeof(long long));
printf("sizeof(double) = %ld\n", sizeof(double));
return 0;
}
例2:结构体占用的内存大小–默认规则
考虑下面的结构体占用的位数
struct yikou_s
{
double d;
char c;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 16
在内容中各变量位置关系如下:
其中成员C的位置
还受字节序的影响,有的可能在位置8
编译器给我们进行了内存对齐,各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量类型所占用的字节数的倍数, 且结构的大小为该结构中占用最大空间的类型所占用的字节数的倍数。
对于偏移量:变量type n起始地址相对于结构体起始地址的偏移量必须为sizeof(type(n))的倍数结构体大小:必须为成员最大类型字节的倍数
char: 偏移量必须为sizeof(char) 即1的倍数 int: 偏移量必须为sizeof(int) 即4的倍数 float: 偏移量必须为sizeof(float) 即4的倍数 double: 偏移量必须为sizeof(double) 即8的倍数
例3:调整结构体大小
我们将结构体中变量的位置做以下调整:
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 24
各变量在内存中布局如下:
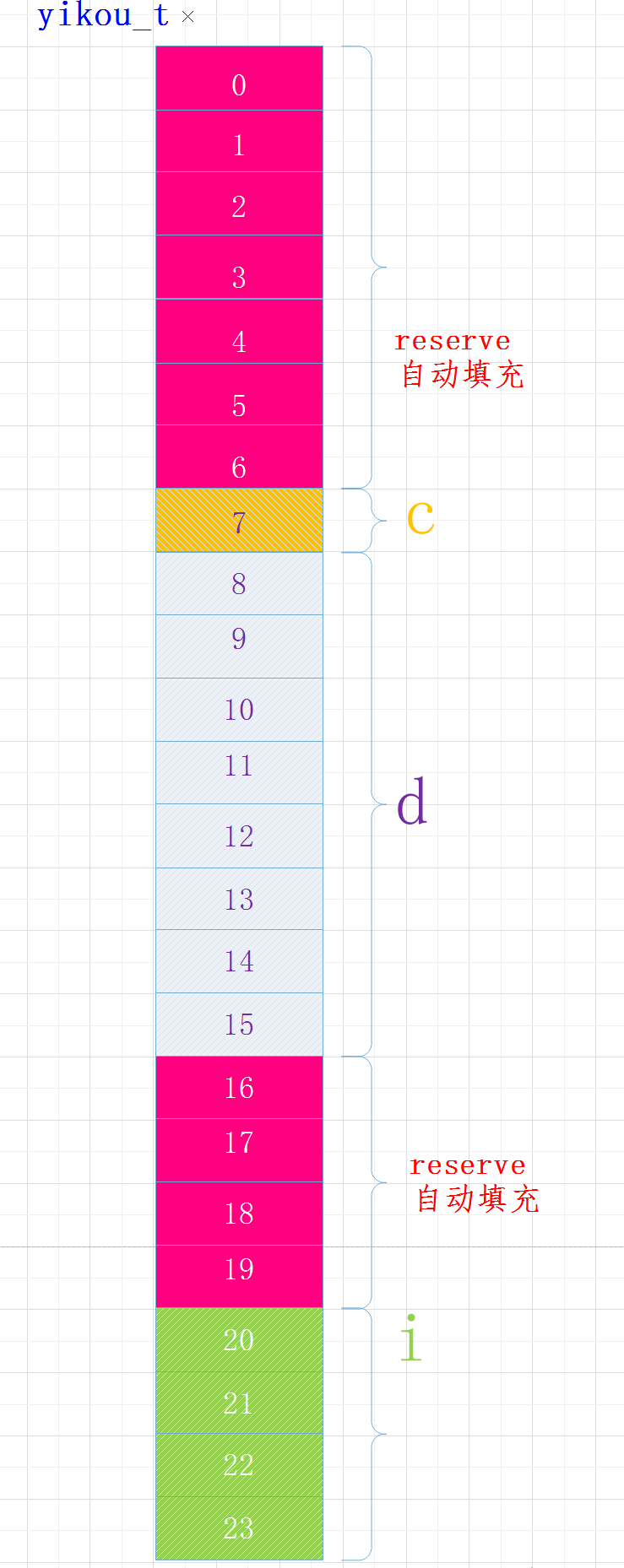
当结构体中有嵌套符合成员时,复合成员相对于结构体首地址偏移量是复合成员最宽基本类型大小的整数倍。
例4:#pragma pack(4)
#pragma pack(4)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 16
例5:#pragma pack(8)
#pragma pack(8)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 24
例6:汇编代码
举例:以下是截取的uboot代码中异常向量irq、fiq的入口位置代码: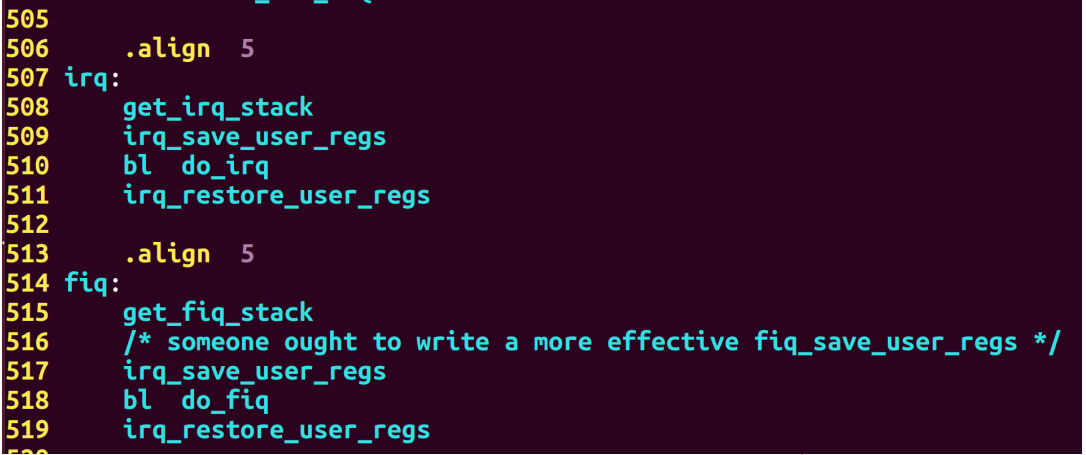
六、汇总实力
有手懒的同学,直接贴一个完整的例子给你们:
#include
main()
{
struct A {
int a;
char b;
short c;
};
struct B {
char b;
int a;
short c;
};
struct AA {
// int a;
char b;
short c;
};
struct BB {
char b;
// int a;
short c;
};
#pragma pack (2) /*指定按2字节对齐*/
struct C {
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
#pragma pack (1) /*指定按1字节对齐*/
struct D {
char b;
int a;
short c;
};
#pragma pack ()/*取消指定对齐,恢复缺省对齐*/
int s1=sizeof(struct A);
int s2=sizeof(struct AA);
int s3=sizeof(struct B);
int s4=sizeof(struct BB);
int s5=sizeof(struct C);
int s6=sizeof(struct D);
printf("%d\n",s1);
printf("%d\n",s2);
printf("%d\n",s3);
printf("%d\n",s4);
printf("%d\n",s5);
printf("%d\n",s6);
}
위 내용은 Linux 바이트 정렬에 관한 사항의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!