
토큰으로 나누지 않고 바이트에서 직접 학습하는 것도 이런 방식으로 효율적으로 사용할 수 있습니다.

- 王林앞으로
- 2024-02-04 14:54:29759검색
언어 모델을 정의할 때 기본적인 단어 분할 방법을 사용하여 문장을 단어, 하위 단어 또는 문자로 나누는 경우가 많습니다. 하위 단어 세분화는 훈련 효율성과 어휘 외부 단어를 처리하는 능력 사이의 균형을 맞추기 때문에 오랫동안 가장 인기 있는 선택이었습니다. 그러나 일부 연구에서는 오타 처리에 대한 견고성 부족, 철자법 및 대소문자 변경, 형태학적 변경과 같은 하위 단어 분할과 관련된 문제를 지적했습니다. 따라서 모델의 정확성과 견고성을 향상시키기 위해 언어 모델 설계 시 이러한 문제를 신중하게 고려해야 합니다.
따라서 일부 연구자들은 바이트 시퀀스를 사용하는 접근 방식, 즉 단어 분할 없이 원시 데이터를 예측 결과에 엔드투엔드 매핑하는 방식을 선택했습니다. 하위 단어 모델과 비교하여 바이트 수준 언어 모델은 다양한 쓰기 형식 및 형태학적 변화로 일반화하기가 더 쉽습니다. 그러나 텍스트를 바이트로 모델링한다는 것은 생성된 시퀀스가 해당 하위 단어보다 길다는 것을 의미합니다. 효율성을 높이려면 아키텍처를 개선해야 합니다.
Autoregressive Transformer는 언어 모델링에서 지배적인 위치를 차지하고 있지만 효율성 문제가 특히 두드러집니다. 시퀀스 길이가 증가함에 따라 계산 비용이 2차적으로 증가하므로 긴 시퀀스의 확장성이 저하됩니다. 이 문제를 해결하기 위해 연구원들은 긴 시퀀스를 처리하기 위해 Transformer의 내부 표현을 압축했습니다. 한 가지 접근 방식은 중간 계층 내의 토큰 그룹을 병합하여 계산 비용을 줄이는 길이 인식 모델링 접근 방식을 개발하는 것입니다. 최근 Yu 등은 MegaByte Transformer라는 방법을 제안했습니다. 고정 크기 바이트 조각을 사용하여 압축된 형식을 하위 단어로 시뮬레이션하므로 계산 비용이 절감됩니다. 그러나 이는 현재로서는 최선의 솔루션이 아닐 수 있으며 추가 연구와 개선이 필요합니다.
최근 연구에서 코넬 대학의 학자들은 MambaByte라는 효율적이고 간단한 바이트 수준 언어 모델을 도입했습니다. 이 모델은 최근 도입된 Mamba 아키텍처를 직접적으로 개선한 것에서 파생되었습니다. Mamba 아키텍처는 SSM(상태 공간 모델) 방법을 기반으로 구축되었으며, MambaByte는 보다 효율적인 선택 메커니즘을 도입하여 텍스트와 같은 개별 데이터를 처리할 때 더 나은 성능을 발휘하고 효율적인 GPU 구현도 제공합니다. 연구원들은 수정되지 않은 Mamba를 사용하여 간략하게 관찰한 결과 언어 모델링의 주요 계산 병목 현상을 완화할 수 있음을 발견했습니다. 이를 통해 패치가 필요하지 않고 사용 가능한 계산 리소스를 최대한 활용할 수 있었습니다.

- 논문 제목: MambaByte: Token-free Selective State Space Model
- 논문 링크: https://arxiv.org/pdf/2401.13660.pdf
실험에서 그들은 MambaByte를 Transformers, SSM 및 MegaByte(패칭) 아키텍처와 비교했습니다. 이러한 아키텍처는 고정 매개변수 및 계산 설정과 여러 장문 텍스트 데이터 세트에서 평가됩니다. 그림 1에는 주요 결과가 요약되어 있습니다.
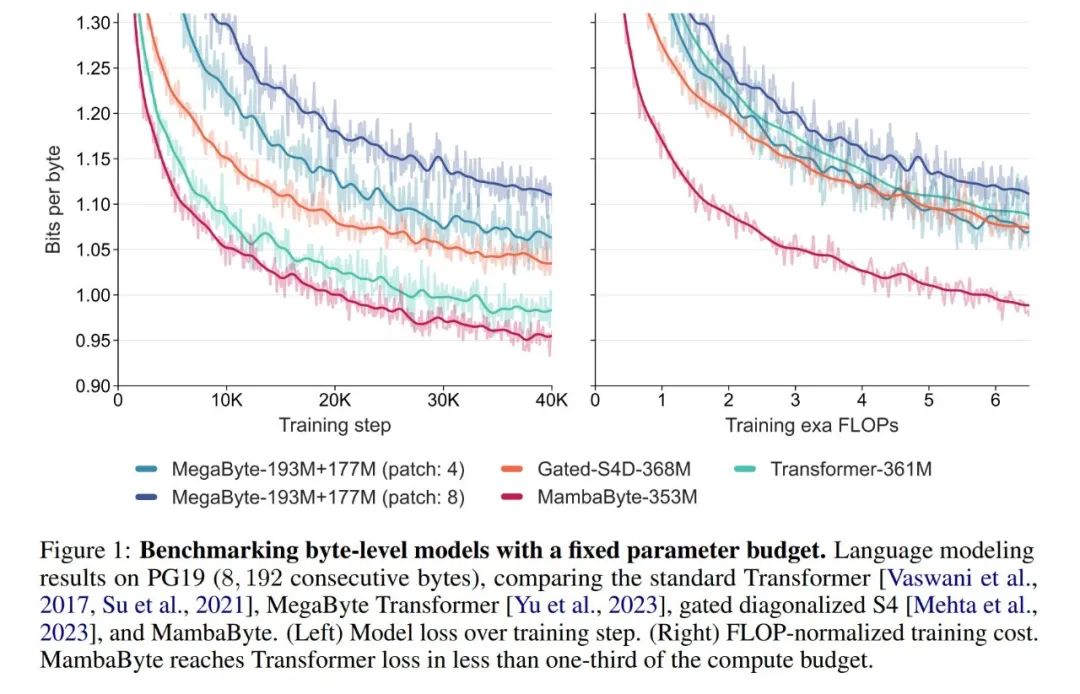
바이트 수준 Transformer와 비교하여 MambaByte는 더 빠르고 고성능 솔루션을 제공하는 동시에 컴퓨팅 효율성도 크게 향상되었습니다. 연구원들은 또한 토큰 없는 언어 모델을 현재의 최첨단 하위 단어 모델과 비교한 결과 MambaByte가 이 점에서 경쟁력이 있고 더 긴 시퀀스를 처리할 수 있다는 것을 발견했습니다. 이 연구 결과는 MambaByte가 이에 의존하는 기존 토크나이저에 대한 강력한 대안이 될 수 있으며 엔드투엔드 학습의 추가 개발을 촉진할 것으로 예상된다는 것을 보여줍니다.
배경: 선택적 상태 공간 시퀀스 모델
SSM은 1차 미분 방정식을 사용하여 숨겨진 상태의 시간 변화를 모델링합니다. 선형 시불변 SSM은 다양한 딥 러닝 작업에서 좋은 결과를 보여주었습니다. 그러나 최근 Mamba 저자인 Gu와 Dao는 이러한 방법의 지속적인 역학에는 언어 모델링과 같은 작업에 필요할 수 있는 숨겨진 상태에서 입력 종속 컨텍스트 선택이 부족하다고 주장했습니다. 따라서 그들은 주어진 입력 x(t) ∈ R, 숨겨진 상태 h(t) ∈ R^n을 취하고 출력 y(t) ∈ R을 시변 연속 상태로 취하여 동적으로 정의되는 Mamba 방법을 제안했습니다. 시간 t는 다음과 같습니다.
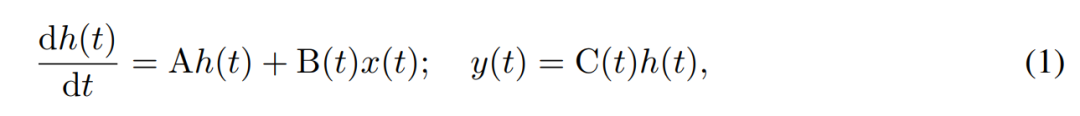
해당 매개변수는 대각선 시불변 시스템 행렬 A∈R^(n×n)과 시변 입력 및 출력 행렬 B(t)∈R^입니다. (n× 1) 및 C(t)∈R^(1×n).
바이트와 같은 이산 시계열을 모델링하려면 (1)의 연속 시간 역학을 이산화를 통해 근사화해야 합니다. 이는 각 시간 단계에서 새로운 행렬 A, B 및 C를 사용하여 이산시간 잠재 재발을 생성합니다. 즉,
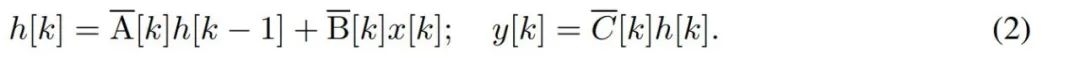
(2)는 찾을 수 있는 순환 신경망의 선형 버전과 유사합니다. 언어에서 이 루프는 모델 생성 중에 적용됩니다. 이산화를 위해서는 각 입력 위치에 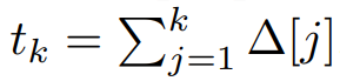 의 x [k] = x (t_k)에 해당하는 시간 단계, 즉 Δ[k]가 있어야 합니다. 이산시간 행렬 A, B, C는 Δ[k]로부터 계산될 수 있습니다. 그림 2는 Mamba가 개별 시퀀스를 모델링하는 방법을 보여줍니다.
의 x [k] = x (t_k)에 해당하는 시간 단계, 즉 Δ[k]가 있어야 합니다. 이산시간 행렬 A, B, C는 Δ[k]로부터 계산될 수 있습니다. 그림 2는 Mamba가 개별 시퀀스를 모델링하는 방법을 보여줍니다.
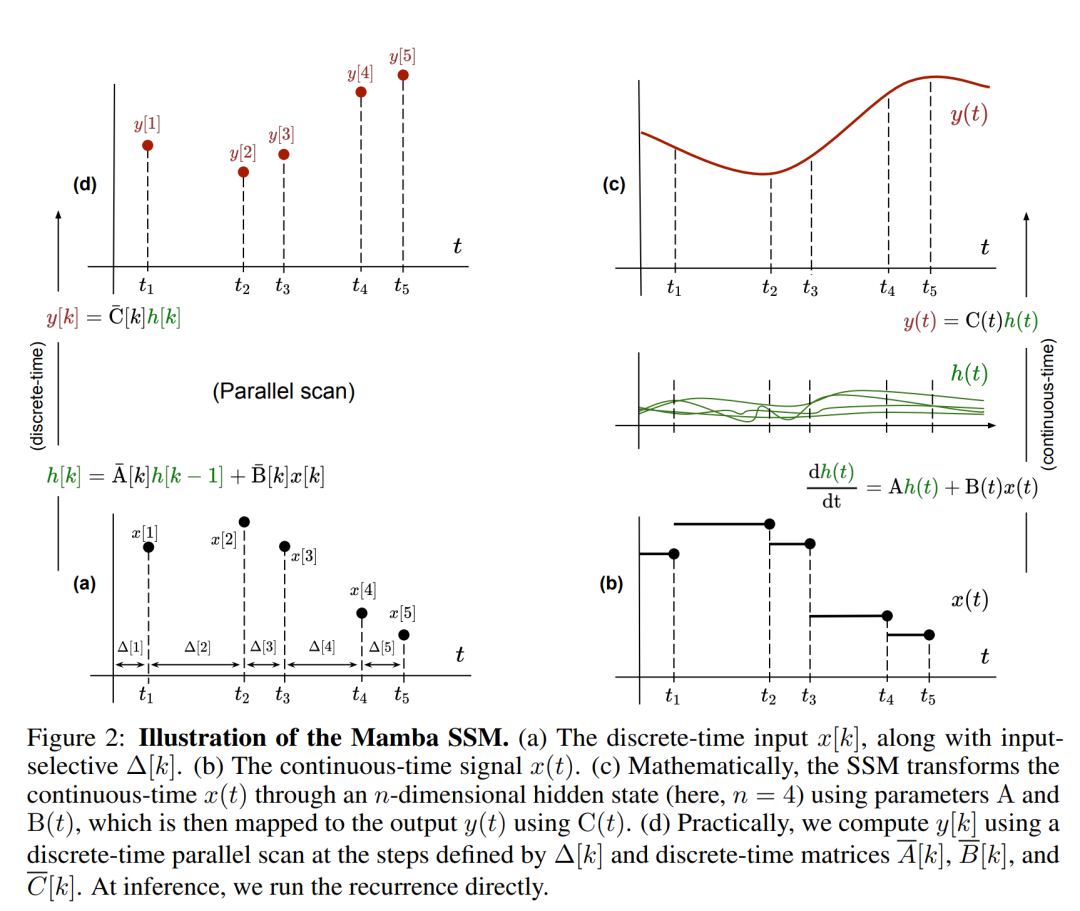
Mamba에서 SSM 용어는 입력 선택적입니다. 즉, B, C 및 Δ는 입력 x [k]∈R^d의 함수로 정의됩니다.
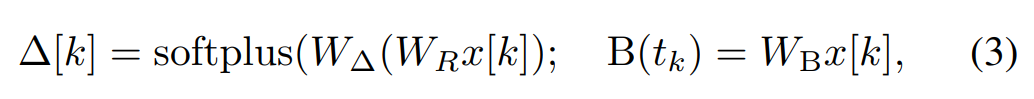
여기서 W_B ∈ R^(n×d)(C는 유사하게 정의됨), W_Δ ∈ R^(d×r) 및 W_R ∈ R^(r×d)(일부 r ``d의 경우)는 학습 가능한 가중치이고, 소프트플러스는 다음을 보장합니다. 양성. 각 입력 차원 d에 대해 SSM 매개변수 A, B, C는 동일하지만 시간 단계 Δ의 수는 다릅니다. 이로 인해 각 시간 단계 k에 대한 숨겨진 상태 크기가 n × d가 됩니다.
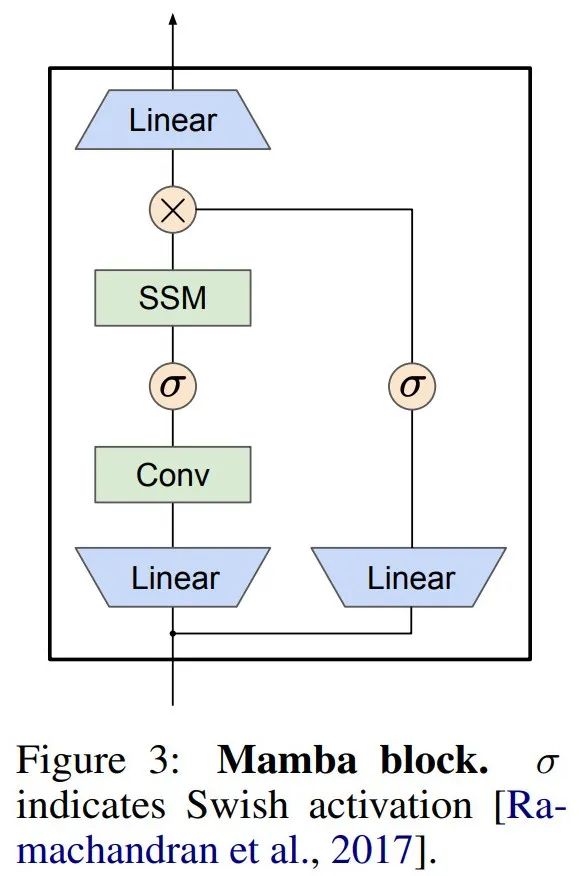
Mamba는 이 SSM 레이어를 완전한 신경망 언어 모델에 내장합니다. 특히 이 모델은 이전 게이트 SSM에서 영감을 받은 일련의 게이팅 레이어를 사용합니다. 그림 3은 SSM 레이어와 게이트 신경망을 결합한 Mamba 아키텍처를 보여줍니다.
선형 재발의 병렬 스캔. 훈련 시간에 작성자는 전체 시퀀스 x에 액세스할 수 있으므로 선형 재발을 보다 효율적으로 계산할 수 있습니다. Smith 등의 연구[2023]는 선형 SSM의 순차적 재발이 효율적인 병렬 스캔을 사용하여 효율적으로 계산될 수 있음을 보여줍니다. Mamba의 경우 저자는 먼저 반복을 L 튜플 시퀀스(여기서 e_k = )에 매핑한 다음
)에 매핑한 다음  와 같은 연관 연산자
와 같은 연관 연산자 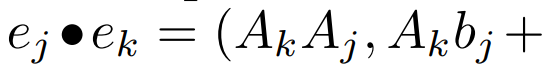
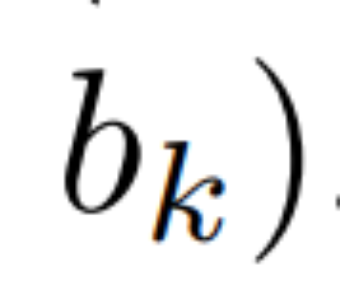 를 정의합니다. 마지막으로 병렬 스캔을 적용하여 시퀀스
를 정의합니다. 마지막으로 병렬 스캔을 적용하여 시퀀스 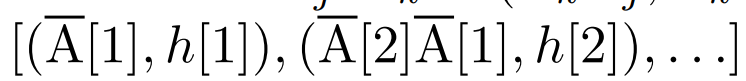 를 계산합니다. 일반적으로 L/2 프로세서를 사용하면
를 계산합니다. 일반적으로 L/2 프로세서를 사용하면 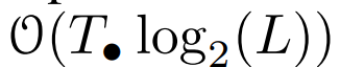 시간이 걸립니다. 여기서
시간이 걸립니다. 여기서 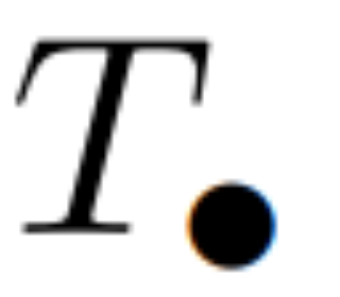 는 행렬 곱셈 비용입니다. A는 대각 행렬이고 선형 재발은
는 행렬 곱셈 비용입니다. A는 대각 행렬이고 선형 재발은 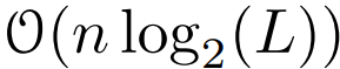 시간과 O(nL) 공간에서 병렬로 계산될 수 있습니다. 대각 행렬을 사용한 병렬 스캔도 매우 효율적으로 실행되므로 O(nL) FLOP만 필요합니다.
시간과 O(nL) 공간에서 병렬로 계산될 수 있습니다. 대각 행렬을 사용한 병렬 스캔도 매우 효율적으로 실행되므로 O(nL) FLOP만 필요합니다.
실험 결과
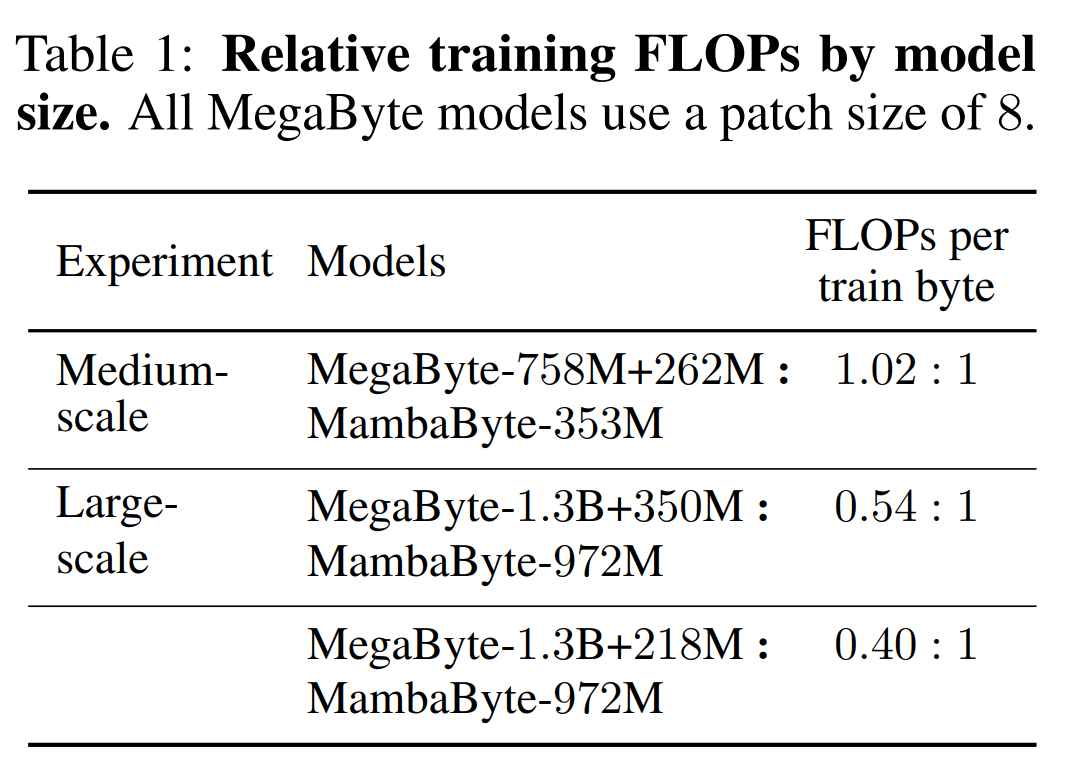
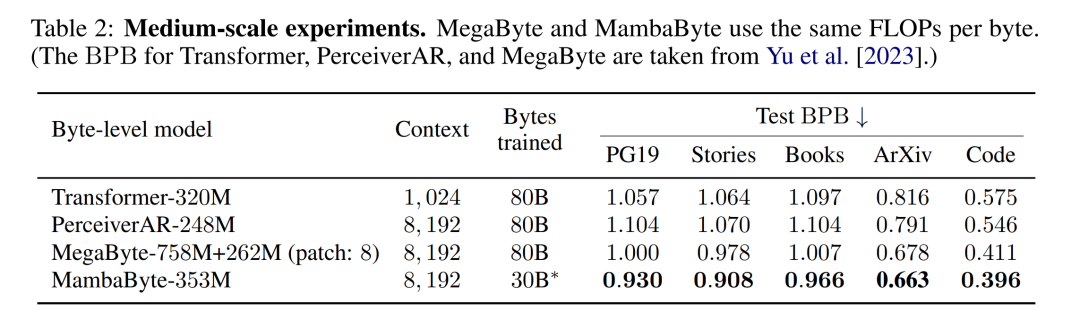
표 2는 각 데이터 세트의 BPB(비트당 비트 수)를 보여줍니다. 이 실험에서 MegaByte758M+262M 및 MambaByte 모델은 바이트당 동일한 수의 FLOP를 사용합니다(표 1 참조). 저자는 MambaByte가 모든 데이터 세트에서 지속적으로 MegaByte보다 뛰어난 성능을 발휘한다는 사실을 발견했습니다. 또한 저자는 자금 제약으로 인해 전체 80B 바이트에서 MambaByte를 교육할 수 없었지만 MambaByte는 여전히 63% 적은 계산과 63% 적은 교육 데이터로 MegaByte보다 성능이 뛰어났다고 지적합니다. 또한 MambaByte-353M은 바이트 규모 Transformer 및 PerceiverAR보다 성능이 뛰어납니다.
MambaByte가 몇 가지 훈련 단계에서 훨씬 더 큰 모델보다 더 나은 성능을 발휘하는 이유는 무엇입니까? 그림 1은 동일한 수의 매개변수를 가진 모델을 살펴봄으로써 이 관계를 더 자세히 살펴봅니다. 그림은 동일한 매개변수 크기의 MegaByte 모델의 경우 입력 패칭이 적은 모델의 성능이 더 우수하지만 정규화를 계산한 후에는 유사한 성능을 나타냅니다. 실제로 전체 길이 Transformer는 절대적 측면에서는 느리지만 계산 정규화 후에는 MegaByte와 유사한 성능을 발휘합니다. 이와 대조적으로 Mamba 아키텍처로 전환하면 계산 사용량과 모델 성능이 크게 향상될 수 있습니다.
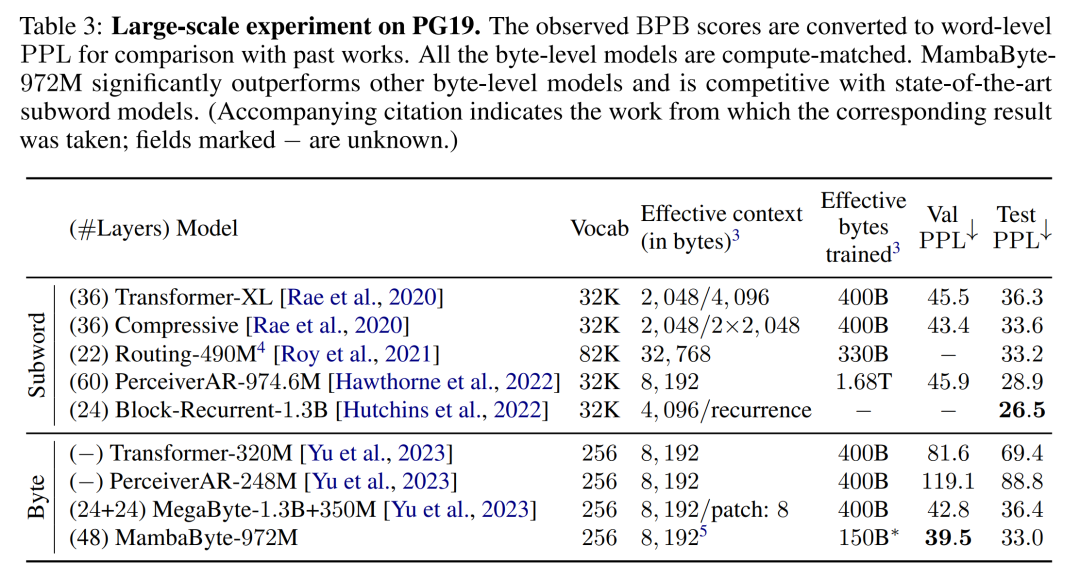
이러한 결과를 바탕으로 표 3은 PG19 데이터 세트에서 이러한 모델의 더 큰 버전을 비교합니다. 이 실험에서 저자는 MambaByte-972M을 MegaByte-1.3B+350M 및 기타 바이트 수준 모델과 여러 SOTA 하위 단어 모델과 비교했습니다. 그들은 MambaByte-972M이 모든 바이트 수준 모델보다 성능이 뛰어나고 150B 바이트만 훈련한 경우에도 하위 단어 모델과 경쟁할 수 있다는 것을 발견했습니다.
텍스트 생성. Transformer 모델의 자동회귀 추론에는 전체 컨텍스트를 캐싱해야 하며 이는 생성 속도에 큰 영향을 미칩니다. MambaByte는 레이어당 시변 은닉 상태를 하나만 유지하므로 이러한 병목 현상이 발생하지 않으며, 따라서 생성 단계당 시간이 일정합니다. 표 4는 A100 80GB PCIe GPU에서 MambaByte-972M 및 MambaByte-1.6B와 MegaByte-1.3B+350M의 텍스트 생성 속도를 비교합니다. MegaByte는 패치를 통해 생성 비용을 크게 절감했지만 루프 생성을 사용하기 때문에 유사한 매개 변수 설정에서 MambaByte가 2.6배 더 빠른 것을 관찰했습니다.

위 내용은 토큰으로 나누지 않고 바이트에서 직접 학습하는 것도 이런 방식으로 효율적으로 사용할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!