
경고! 장거리 LiDAR 감지

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-02 11:33:311190검색
1. 소개
작년 투산 AI 데이가 끝난 후, 저는 항상 장거리 인식에 관한 우리의 작업을 텍스트 형식으로 요약하고 싶다는 생각을 했습니다. 최근에 시간이 좀 생겨 지난 몇 년간의 연구 과정을 기록하고자 글을 쓰기로 결심했습니다. 이 글에서 다루는 내용은 투싼 AI 데이 영상[0]과 당사가 공개적으로 발표한 논문에서 확인할 수 있지만, 구체적인 엔지니어링 세부 사항이나 기술적 비밀은 포함되어 있지 않습니다.
우리 모두 알고 있듯이 투싼은 자율주행 트럭 운전 기술에 중점을 두고 있습니다. 트럭은 자동차보다 제동 거리가 길고 차선 변경도 더 깁니다. 결과적으로 투싼은 다른 자율주행 기업과의 경쟁에서 남다른 우위를 점하고 있다. 투싼의 일원으로서 LiDAR 센싱 기술을 담당하고 있는데, 이제 장거리 센싱에 LiDAR를 활용한 관련 내용을 자세히 소개하겠습니다.
회사가 처음 합류했을 당시 주류 LiDAR 센싱 솔루션은 대개 BEV(Bird's Eye View) 솔루션이었습니다. 하지만 여기서 BEV는 잘 알려진 Battery Electric Vehicle의 약자가 아니라 LiDAR 포인트 클라우드를 BEV 공간에 투영하고 2D 컨볼루션과 2D 탐지 헤드를 결합하여 표적 탐지를 수행하는 솔루션을 의미합니다. 저는 개인적으로 Tesla가 사용하는 LiDAR 센싱 기술을 "BEV 공간의 다시점 카메라 융합 기술"이라고 불러야 한다고 생각합니다. 내가 아는 한, BEV 솔루션의 최초 기록은 CVPR17 컨퍼런스에서 Baidu가 발표한 "MV3D" 논문입니다[1]. 제가 알고 있는 많은 기업에서 실제로 사용하고 있는 솔루션을 포함하여 많은 후속 연구 작업에서는 표적 탐지를 위해 LiDAR 포인트 클라우드를 BEV 공간에 투영하는 방식을 채택하고 있으며 BEV 솔루션으로 분류할 수 있습니다. 이 솔루션은 실제 응용 분야에서 널리 사용됩니다. 요약하자면, 제가 처음 회사에 입사했을 때 주류 LiDAR 감지 솔루션은 일반적으로 LiDAR 포인트 클라우드를 BEV 공간에 투영한 다음 표적 감지를 위해 2D 컨볼루션과 2D 감지 헤드를 결합했습니다. 테슬라가 사용하는 LiDAR 센싱 기술은 'BEV 공간의 멀티뷰 카메라 융합 기술'이라 할 수 있다. CVPR17 컨퍼런스에서 Baidu가 발표한 논문 "MV3D"는 BEV 솔루션의 초기 기록이었습니다. 이후 많은 회사에서도 표적 탐지를 위해 유사한 솔루션을 채택했습니다.
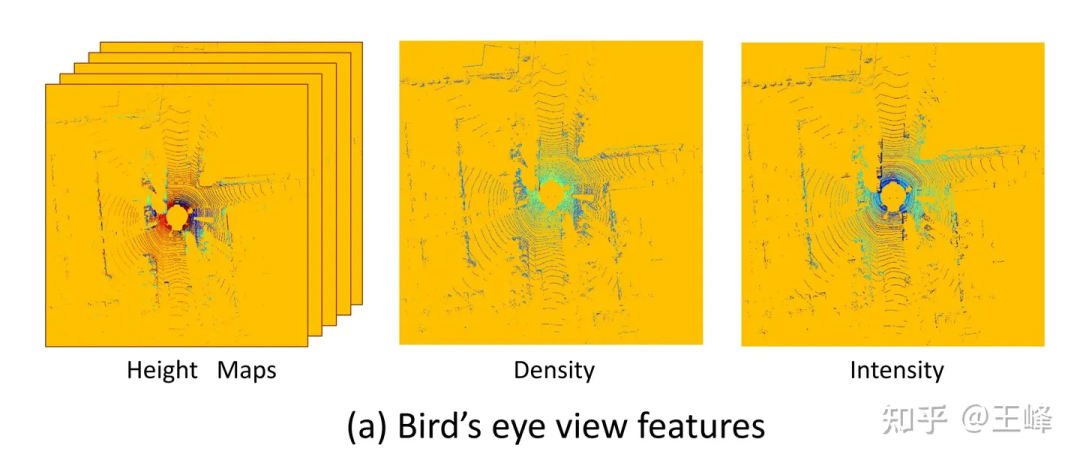 MV3D에서 사용하는 BEV 투시 기능[1]
MV3D에서 사용하는 BEV 투시 기능[1]
BEV 솔루션의 가장 큰 장점은 성숙한 2D 감지기를 직접 적용할 수 있다는 점이지만 감지 범위를 제한한다는 치명적인 단점도 있습니다. 위 그림에서 볼 수 있듯이 2D 검출기를 사용해야 하기 때문에 2D 특징 맵을 형성해야 합니다. 이때 거리 임계값을 설정해야 합니다. 실제로 범위 밖에는 여전히 LiDAR 지점이 있습니다. 위 그림에서는 잘림 작업으로 인해 삭제되었습니다. 해당 위치가 포함될 때까지 거리 임계값을 늘릴 수 있습니까? 불가능한 것은 아니지만 LiDAR는 스캐닝 모드, 반사 강도(4승까지의 거리에 따라 감쇠), 폐색 등의 문제로 인해 원거리에 포인트 클라우드가 거의 없으므로 비용 효율적이지 않습니다.
학계에서는 주로 데이터 세트의 한계로 인해 BEV 계획 문제에 많은 관심을 기울이지 않았습니다. 현재 주류 데이터 세트의 주석 범위는 일반적으로 80미터 미만입니다(예: nuScenes의 50미터, KITTI의 70미터 및 Waymo의 80미터). 이 거리 범위 내에서는 BEV 기능 맵의 크기가 클 필요가 없습니다. 그러나 산업계에서 사용되는 중거리 LiDAR는 일반적으로 200미터의 스캐닝 범위를 달성할 수 있으며, 최근에는 500미터의 스캐닝 범위를 달성할 수 있는 일부 장거리 LiDAR가 출시되었습니다. 특징 맵의 면적과 계산량은 거리가 증가함에 따라 2차적으로 증가한다는 점에 유의해야 한다. BEV 체계에서는 500미터 범위는 물론 200미터 범위를 처리하는 데 필요한 계산량이 이미 상당합니다. 따라서 이 문제는 업계의 더 많은 관심과 해결이 필요합니다.
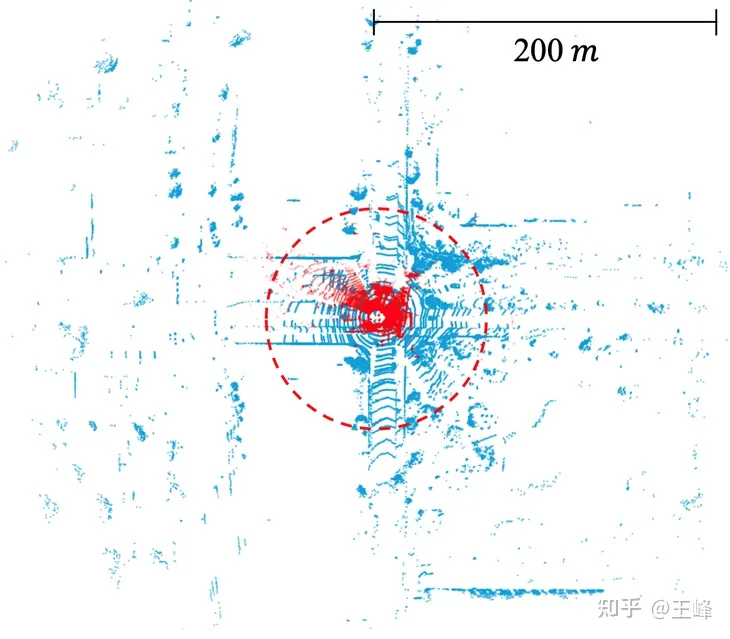
공개 데이터 세트의 LiDAR 스캔 범위. KITTI(빨간 점, 70m) vs. Argoverse 2(파란 점, 200m)
BEV 솔루션의 한계를 인식하고 수년간의 연구 끝에 마침내 실현 가능한 대안을 찾았습니다. 연구 과정은 쉽지 않았고 우여곡절도 많았습니다. 일반적으로 논문이나 보고서에서는 성공만 강조하고 실패는 언급하지 않지만, 실패의 경험 역시 매우 귀중한 것입니다. 그래서 우리는 블로그를 통해 우리의 연구 여정을 공유하기로 결정했습니다. 다음은 타임라인에 따라 차근차근 설명하겠습니다.
2. 포인트 기반 솔루션
CVPR19에서 홍콩 중국인은 PointRCNN[2]이라는 포인트 클라우드 탐지기를 발표했습니다. 기존 방법과 달리 PointRCNN은 포인트 클라우드 데이터를 BEV(조감도) 형식으로 변환하지 않고 직접 계산을 수행합니다. 따라서 이 포인트 클라우드 기반 솔루션은 이론적으로 장거리 감지를 달성할 수 있습니다.
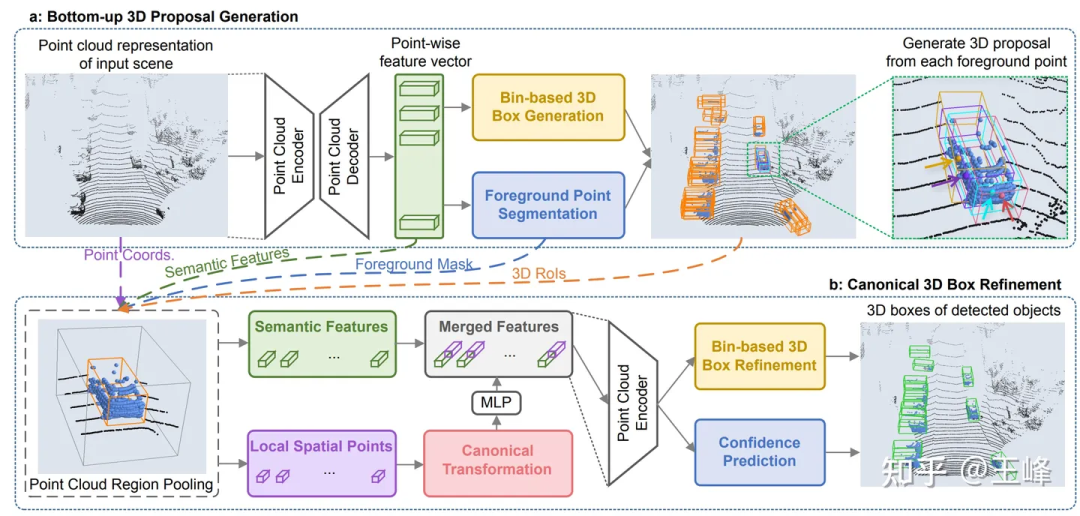
하지만 시도한 결과 KITTI의 한 프레임에 있는 포인트 클라우드 수는 포인트 손실 없이 16,000포인트로 다운샘플링될 수 있습니다. 그러나 우리의 LiDAR 조합은 한 프레임에 100,000포인트가 넘습니다. , 10배는 분명히 탐지 정확도에 큰 영향을 미칠 것입니다. 다운샘플링을 하지 않으면 PointRCNN의 백본에는 O(n^2) 연산까지 있기 때문에, 비록 bev는 걸리지 않지만 계산량은 여전히 감당하기 힘들 정도입니다. 이러한 시간 소모적인 작업은 주로 포인트 클라우드 자체의 무질서한 특성으로 인해 발생합니다. 즉, 다운샘플링이든 이웃 검색이든 모든 포인트를 통과해야 합니다. 관련 작업이 많고 모두 최적화되지 않은 표준 작업이므로 단기적으로 실시간으로 최적화할 수 있는 가능성이 없으므로 이 경로는 포기되었습니다.
그러나 이 연구는 백본의 계산량이 너무 크지만 두 번째 단계는 전경에서만 수행되므로 계산량이 여전히 상대적으로 적습니다. PointRCNN의 두 번째 단계를 BEV 방식의 첫 번째 단계 감지기에 직접 적용하면 감지 프레임의 정확도가 크게 향상됩니다. 신청 과정에서 작은 문제도 발견했습니다. 이를 해결한 후 이를 요약하여 CVPR21에 게시된 기사 [3]에 게시했습니다. 또한 이 블로그에서 확인할 수 있습니다:
Wang Feng: LiDAR. R-CNN: 빠르고 다재다능한 2단계 3D 검출기
3. Range-View 솔루션
Point 기반 솔루션이 실패한 후 Range View로 관심을 돌렸습니다. 당시의 LiDAR는 모두 기계식이었습니다. 예를 들어, 64개 라인의 라이더는 서로 다른 피치 각도를 가진 64개 라인의 포인트 클라우드를 스캔합니다. 예를 들어, 각 라인이 2048개의 포인트를 스캔하면 64*2048 범위의 이미지가 형성될 수 있습니다.
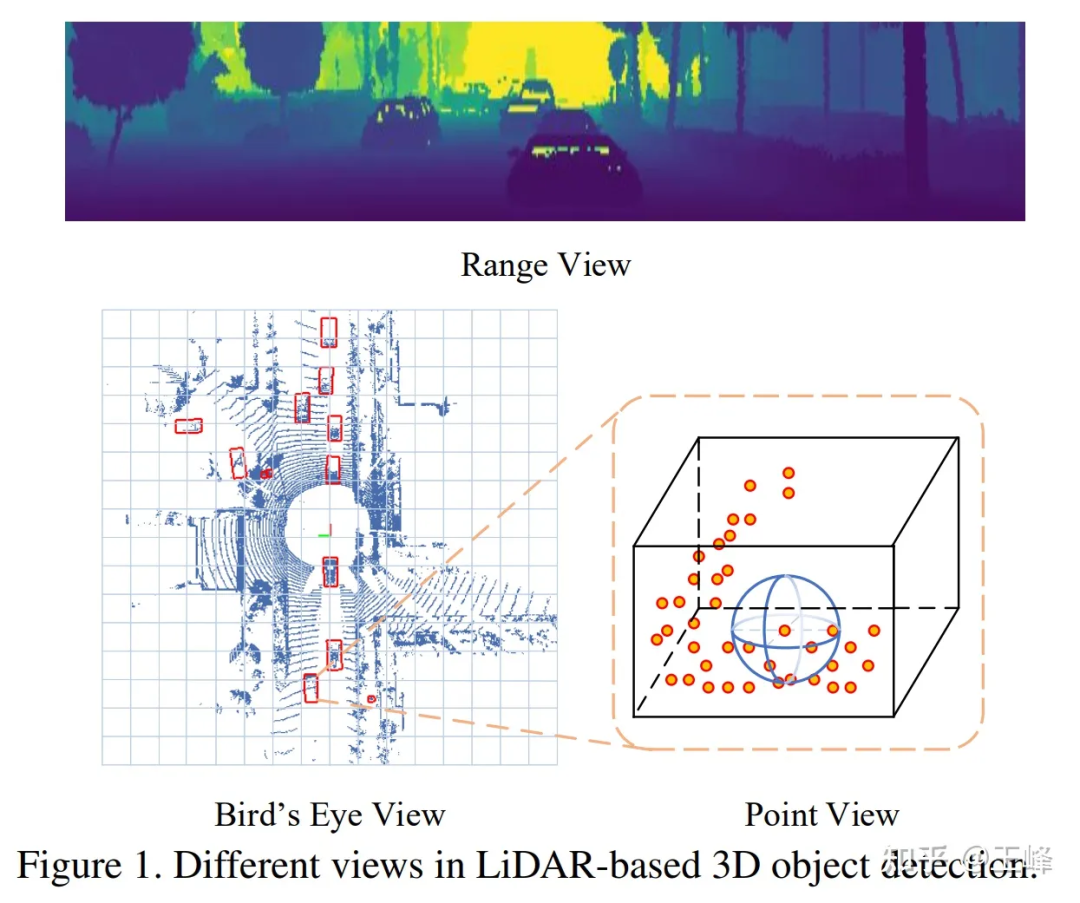 RV, BEV, PV 비교
RV, BEV, PV 비교
Range View에서는 포인트 클라우드가 더 이상 희박하지 않고 촘촘하게 배열되어 있습니다. 거리 이미지에서는 먼 대상이 더 작을 뿐이므로 버리지 않습니다. 이론적으로 감지할 수 있습니다.
이미지와 더 유사해서인지 RV에 대한 연구는 실제로 BEV보다 더 일찍 이루어졌습니다. 제가 찾을 수 있는 가장 초기의 기록도 Baidu의 논문[4]에서 나온 것입니다. RV입니다. BEV의 최초 적용은 Baidu에서 나왔습니다.
그래서 그때 한번 시도해 보았는데, BEV 방식과 비교했을 때 RV의 AP가 30~40포인트 정도 떨어졌는데... 2D 범위 영상에서는 검출이 실제로는 괜찮았으나 출력이 3D인 것을 확인했습니다. 프레임 효과가 너무 안좋습니다. 당시 RV의 특징을 분석해보면, 불균일한 물체 스케일, 전경과 배경이 혼합된 특징, 불분명한 장거리 표적 특징 등 이미지의 단점을 모두 가지고 있다고 느꼈습니다. 그러나 풍부하다는 장점은 없었습니다. 이미지의 의미론적 특징 때문에 당시 저는 이 솔루션에 대해 상대적으로 비관적이었습니다.
구현 작업은 결국 정식 직원이 해야 하기 때문에 이런 탐구적인 질문은 인턴에게 맡기는 것이 좋습니다. 나중에 이 문제를 함께 연구하기 위해 두 명의 인턴을 모집했습니다. 그들은 공개 데이터 세트에서 그것을 시도했고, 당연히 그들은 30점을 잃었습니다... 다행스럽게도 두 명의 인턴은 일련의 노력과 참고를 통해 더 유능해졌습니다. 기타 논문의 일부 세부 사항을 수정한 후 주류 BEV 방법과 유사한 수준으로 요점을 가져왔고 최종 논문은 ICCV21에 게시되었습니다[5].
포인트가 늘어났지만 당시에는 문제가 완전히 해결되지 않았습니다. LiDAR는 포인트 수가 적기 때문에 신호 대 잡음비를 개선하기 위해 다중 프레임 융합이 필요하다는 것이 공감대가 되었습니다. , 장거리 대상은 정보의 양을 늘리기 위해 프레임을 쌓아야 합니다. BEV 솔루션에서는 다중 프레임 융합이 매우 간단합니다. 타임스탬프를 입력 포인트 클라우드에 직접 추가한 다음 여러 프레임을 변경하지 않고도 전체 네트워크를 개선할 수 있습니다. 그러나 RV에서는 많은 트릭이 변경되었습니다. 비슷한 효과를 얻지 못했습니다.
그리고 현재 LiDAR도 하드웨어 기술 솔루션 측면에서 기계적 회전에서 고체/반고체 상태로 전환되었습니다. 대부분의 고체/반고체 LiDAR는 더 이상 범위 이미지를 형성할 수 없으며 강제로 범위 이미지를 구성합니다. 정보가 손실되므로 이 경로는 결국 포기되었습니다.
4. Sparse Voxel Scheme
앞서 언급한 것처럼 Point-based 방식의 문제점은 포인트 클라우드의 불규칙한 배열로 인해 다운샘플링이 발생하고 이웃 검색 문제로 인해 모든 포인트 클라우드를 순회해야 하므로 과도한 계산이 발생한다는 것입니다. BEV 방식 데이터는 정리되어 있지만 빈 영역이 너무 많아 계산량이 과다하게 발생합니다. 이 둘을 합치면 점선 영역에서는 복셀화를 수행하여 규칙적으로 만들고, 점선이 아닌 영역에서는 계산이 잘못되는 것을 방지하기 위해 표현하지 않는 것이 희소 복셀 솔루션인 것 같습니다.
SECOND[6]의 작성자 Yan Yan이 Tucson에 합류했기 때문에 초기에는 sparse conv의 백본을 시도했지만 spconv는 표준 op가 아니기 때문에 자체 구현한 spconv는 여전히 너무 느리고 부족합니다. 탐지는 실시간으로 수행되며 때로는 Dense Conv보다 느리게 수행되므로 당분간 보류됩니다.
나중에 500m를 스캔할 수 있는 최초의 LiDAR: Livox Tele15가 도착했고, 장거리 LiDAR 감지 알고리즘이 임박했습니다. BEV 솔루션을 시도했지만 너무 비싸서 Tele15의 fov가 상대적으로 좁고 멀리 있는 포인트 클라우드도 매우 드물기 때문에 spconv는 실시간 성능을 거의 달성할 수 없습니다.
그러나 bev를 사용하지 않으면 감지 헤드가 2D 감지에서 더 성숙한 앵커나 중심 할당을 사용할 수 없습니다. 이는 주로 LiDAR가 물체의 표면을 스캔하고 중심 위치가 반드시 지점이 아니기 때문입니다. 아래 그림 참조) 포인트가 없으면 당연히 전경 타겟 지정이 불가능합니다. 실제로 우리는 내부적으로 많은 할당 방법을 시도했지만 여기서는 회사에서 사용하는 실제 방법에 대해 자세히 설명하지 않습니다. 인턴도 할당 방식을 시도하고 이를 NIPS2022에 게시했습니다.
明月不谙愿: Fully sparse 3D object detector
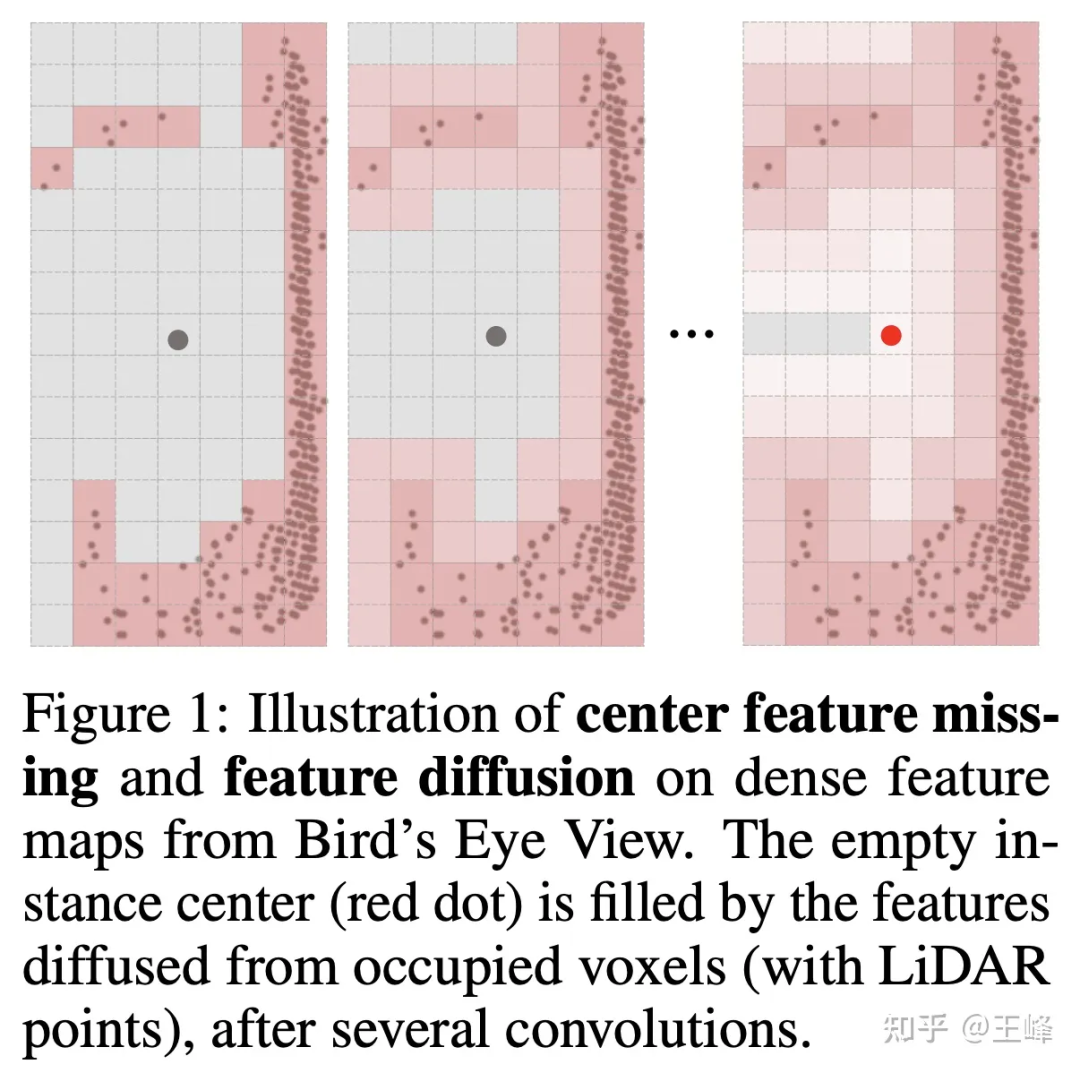
하지만 이 알고리즘을 전방 500m, 후방 150m, 좌우의 LiDAR 조합에 적용하려면 아직 부족합니다. 마침 그 인턴이 인기를 쫓기 전에 Swin Transformer의 아이디어를 끌어내고 Sparse Transformer에 대한 기사를 썼던 일이 있었습니다[8]. 또한 20점 이상을 조금씩 브러싱하는 데에도 많은 노력이 필요했습니다. 지도해 주신 인턴 tql ) 당시 저는 여전히 불규칙한 포인트 클라우드 데이터에 Transformer 방식이 매우 적합하다고 느꼈기 때문에 회사의 데이터 세트에도 시도해 보았습니다.
안타깝게도 이 방법은 회사의 데이터 세트에서 항상 BEV 방법을 능가하지 못했고 그 차이는 지금 돌이켜보면 내가 익히지 못한 몇 가지 트릭이나 훈련 기술이 있을 수 있습니다. 트랜스포머의 표현력이 컨버전보다 약한 것은 아니지만 나중에 다시 시도하지는 않았습니다. 그런데 이번에 할당방식이 최적화되어 계산량이 많이 줄어들어서 다시 spconv를 해보고 싶었습니다. 놀라운 결과는 Transformer를 spconv로 직접 교체하면 근거리에서 BEV 방식과 동일한 정확도를 얻을 수 있다는 점입니다. 물론, 장거리 표적도 탐지할 수 있습니다.
Yan Yan이 spconv[9]의 두 번째 버전을 만든 것도 이때였습니다. 속도가 크게 향상되어 컴퓨팅 지연이 더 이상 병목 현상이 되지 않았습니다. 마침내 장거리 LiDAR 인식이 모든 장애물을 제거하고 가능해졌습니다. 자동차가 실시간으로 달리기 시작했습니다.
나중에 LiDAR 배열을 업데이트하여 스캔 범위를 앞으로 500m, 뒤로 300m, 왼쪽 및 오른쪽으로 150m로 늘렸습니다. 이 알고리즘도 앞으로도 컴퓨팅 성능이 계속 향상됨에 따라 계산 지연이 줄어들 것이라고 믿습니다. . 점점 문제가 줄어들고 있습니다.
최종 장거리 탐지 효과는 아래와 같습니다. Tucson AI Day 영상의 01:08:30쯤 위치를 보시면 동적 탐지 효과를 보실 수 있습니다:
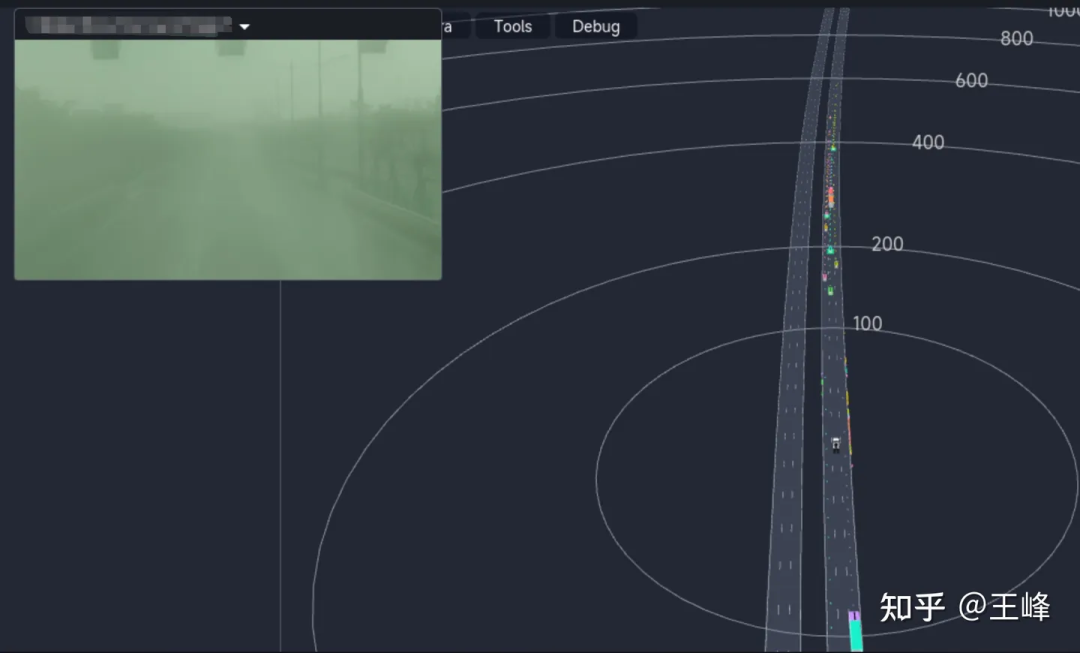
최종 융합이지만 결과이지만, 이날 안개로 인해 이미지의 시인성이 매우 낮았기 때문에 결과는 기본적으로 LiDAR 인식에서 나온 것입니다.
5. Postscript
점 기반 방법부터 거리 이미지 방법, 희소 복셀 기반의 Transformer 및 희소 변환 방법에 이르기까지 장거리 인식 탐색은 순조롭게 진행되었다고 할 수 없습니다. 가시밭길일 뿐입니다. 결국, 우리가 이 단계를 달성할 수 있었던 것은 실제로 컴퓨팅 성능의 지속적인 향상과 많은 동료들의 지속적인 노력 덕분이었습니다. Tucson 수석 과학자 Wang Naiyan과 Tucson의 모든 동료 및 인턴들에게 감사의 말씀을 전하고 싶습니다. 대부분의 아이디어와 엔지니어링 구현은 과거와 미래를 연결하는 역할을 하는 것이 매우 부끄럽습니다.
이렇게 긴 글을 오랜만에 작성했는데 감동적인 스토리를 형성하지 못한 채 러닝 계정처럼 쓰게 되었습니다. 최근에는 L4를 고집하는 동료가 점점 줄어들고 있으며 L2 동료는 점차 순전히 시각적인 연구로 전환하고 있습니다. 비록 저는 여전히 직접 거리 측정 센서를 하나 더 선택하는 것이 더 낫다고 굳게 믿고 있습니다. , 그러나 업계 내부자들은 점점 더 동의하지 않는 것 같습니다. 프레쉬 블러드의 이력서에 점점 더 많은 BEV와 Occupancy가 보이면서, LiDAR 센싱이 언제까지 계속될 수 있을지, 이런 글을 쓰는 것도 기념이 될 수 있을 것 같습니다.
밤늦게 울고 있는데 무슨 말인지 이해가 안 돼요, 미안해요.
위 내용은 경고! 장거리 LiDAR 감지의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!