
Gemini Pro를 따라잡고 추론 및 OCR 기능을 향상시키는 LLaVA-1.6은 너무 강력합니다.

- PHPz앞으로
- 2024-02-01 16:51:29826검색
지난해 4월 위스콘신대학교 매디슨캠퍼스, 마이크로소프트 리서치, 컬럼비아대학교 연구진이 공동으로 LLaVA(Large Language and Vision Assistant)를 출시했습니다. LLaVA는 작은 다중 모드 명령 데이터 세트로만 교육되었지만 일부 샘플에서는 GPT-4와 매우 유사한 추론 결과를 보여줍니다. 그런 다음 10월에 원래 LLaVA에 대한 간단한 수정을 통해 11개 벤치마크에서 SOTA를 업데이트한 LLaVA-1.5를 출시했습니다. 이 업그레이드의 결과는 매우 흥미롭고 다중 모드 AI 보조 분야에 새로운 혁신을 가져옵니다.
연구팀은 추론, OCR 및 세계 지식 분야에서 대폭적인 성능 향상을 이룬 LLaVA-1.6 버전의 출시를 발표했습니다. 이 LLaVA-1.6 버전은 여러 벤치마크에서 Gemini Pro보다 성능이 뛰어납니다.
- 데모 주소: https://llava.hliu.cc/
- 프로젝트 주소: https://github.com/haotian-liu/LLaVA
LLaVA-1.5와 비교하여 LLaVA-1.6에는 다음과 같은 개선 사항이 있습니다.
- 입력 이미지 해상도를 4배 높이고 최대 672x672, 336x1344, 1344x336 해상도의 세 가지 화면비를 지원합니다. 이를 통해 LLaVA-1.6은 더 많은 시각적 세부 정보를 캡처할 수 있습니다.
- LLaVA-1.6은 데이터 혼합을 조정하기 위한 향상된 시각적 지침을 통해 더 나은 시각적 추론 및 OCR 기능을 제공합니다.
- 더 나은 시각적 대화, 더 많은 장면, 다양한 응용 프로그램을 포괄합니다. LLaVA-1.6은 더 많은 세계 지식을 습득했으며 더 나은 논리적 추론 능력을 갖추고 있습니다.
- 효율적인 배포 및 추론을 위해 SGLang을 사용하세요.

이미지 출처: https://twitter.com/imhaotian/status/1752621754273472927
LLaVA-1.6은 LLaVA-1.5를 기반으로 미세 조정되고 최적화되었습니다. LLaVA-1.5의 단순한 디자인과 효율적인 데이터 처리 기능을 유지하며 100만 개 미만의 시각적 명령 튜닝 샘플을 계속 사용합니다. 32개의 A100 그래픽 카드를 사용하여 가장 큰 34B 모델을 약 하루만에 학습시켰습니다. 또한 LLaVA-1.6은 130만 개의 데이터 샘플을 활용하며 계산/훈련 데이터 비용은 다른 방법에 비해 100~1000배에 불과합니다. 이러한 개선으로 LLaVA-1.6은 더욱 효율적이고 비용 효율적인 버전이 되었습니다.
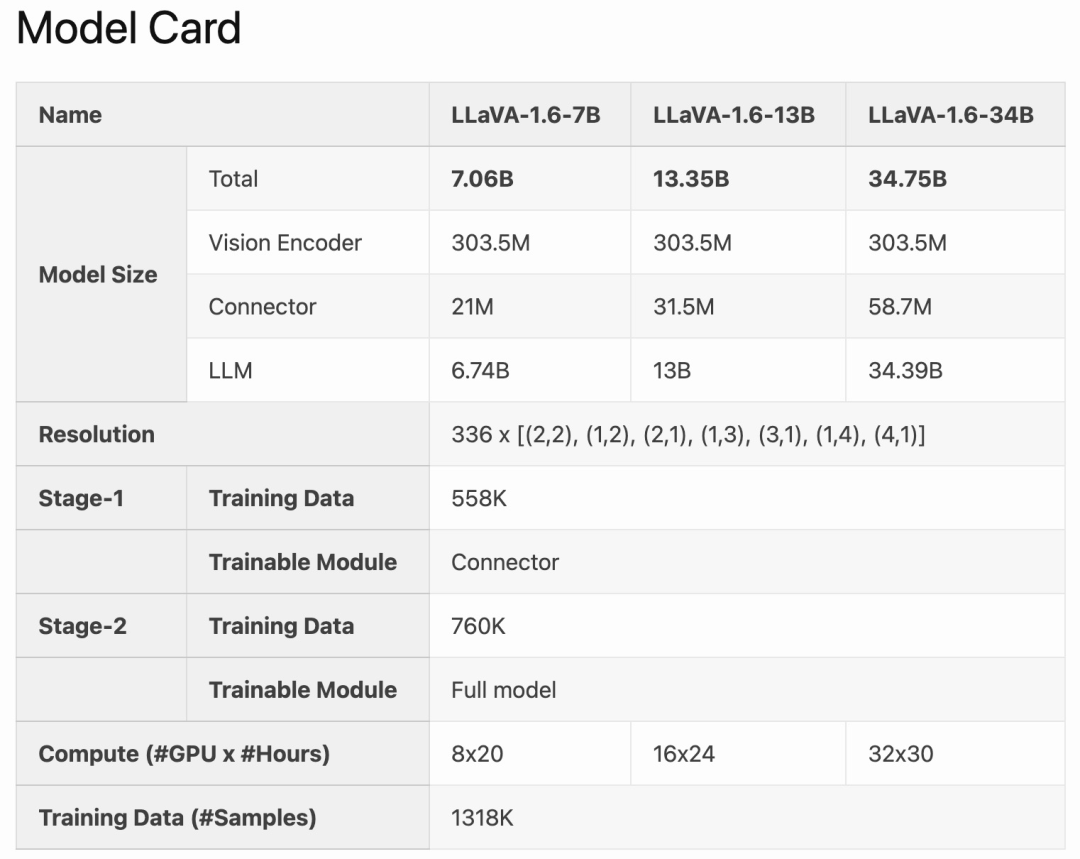
CogVLM 또는 Yi-VL과 같은 오픈 소스 LMM과 비교할 때 LLaVA-1.6은 SOTA 성능을 달성합니다. 상용 제품과 비교했을 때 LLaVA-1.6은 Gemini Pro와 비슷하며 일부 벤치마크에서는 Qwen-VL-Plus보다 우수합니다.
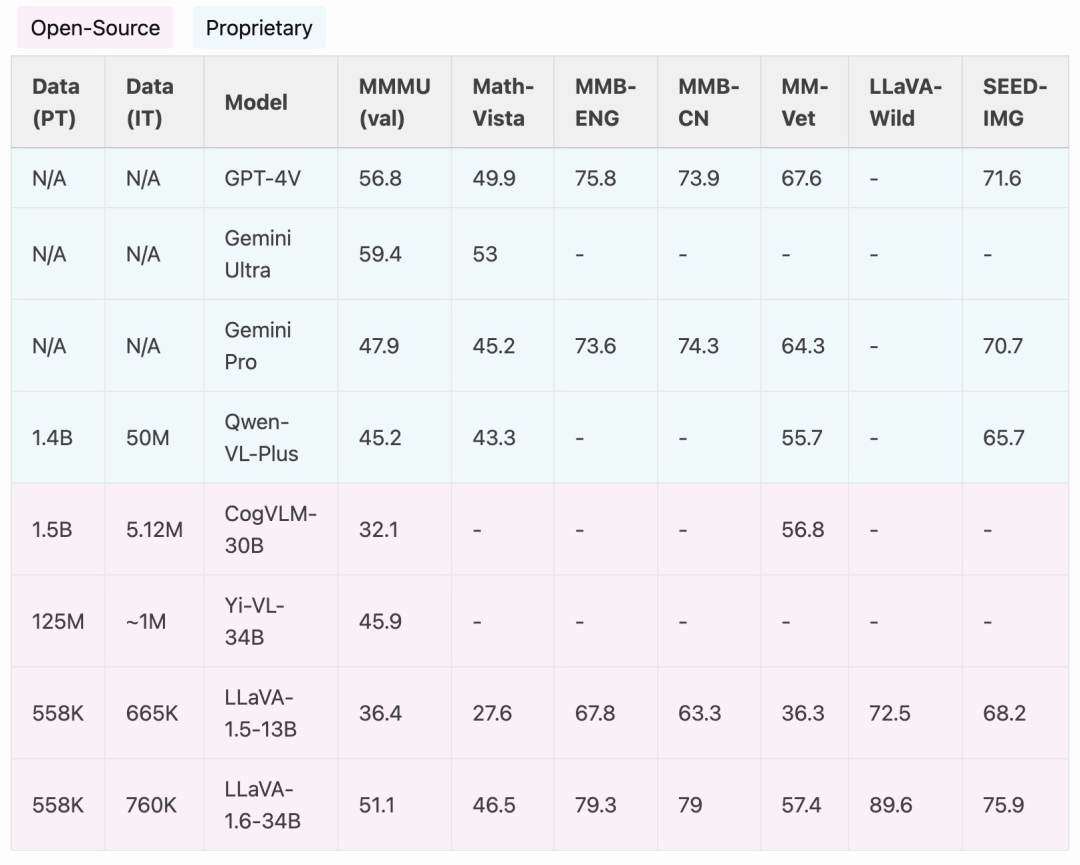
LLaVA-1.6은 강력한 제로샷 중국어 기능을 보여주고 멀티모달 벤치마크 MMBench-CN에서 SOTA 성능을 달성했다는 점을 언급할 가치가 있습니다.
방법 개선
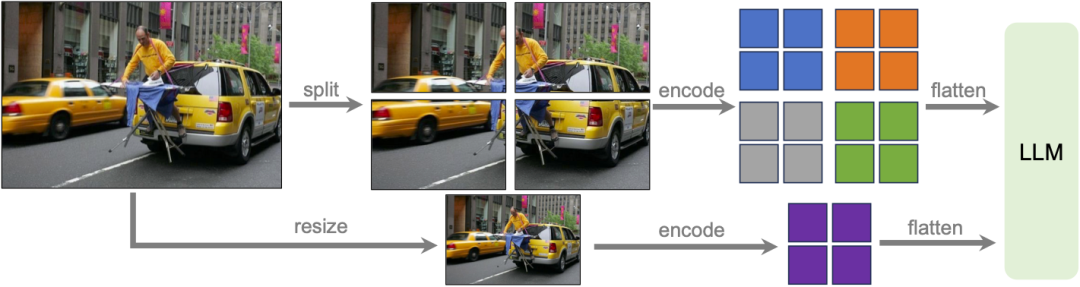
동적 고해상도
연구팀은 데이터 효율성을 유지하는 것을 목표로 LLaVA-1.6 모델을 고해상도로 설계했습니다. 고해상도 이미지와 세부 사항이 보존된 표현이 제공되면 이미지의 복잡한 세부 사항을 인식하는 모델의 능력이 크게 향상됩니다. 저해상도 이미지를 직면할 때, 즉 상상한 시각적 내용을 추측할 때 모델의 환각을 줄여줍니다.
데이터 혼합
고품질 사용자 지침 데이터. 데이터를 따르는 고품질 시각적 지침에 대한 연구의 정의는 두 가지 주요 기준에 따라 달라집니다. 첫째, 작업 지침의 다양성, 특히 작업 중에 실제 시나리오에서 접할 수 있는 광범위한 사용자 의도를 적절하게 표현하는 것입니다. 모델 배포 단계. 둘째, 호의적인 사용자 피드백을 유도하는 것을 목표로 응답의 우선순위를 정하는 것이 중요합니다.
따라서 이 연구에서는 두 가지 데이터 소스를 고려했습니다.
기존 GPT-V 데이터(LAION-GPT-V 및 ShareGPT-4V); 더 많은 시나리오에서 더 나은 시각적 대화를 더욱 촉진하기 위해 연구팀은 다양한 애플리케이션을 포괄하는 작은 15K 시각적 명령 튜닝 데이터 세트를 수집하고, 개인 정보 보호 문제가 있거나 해로울 수 있는 샘플을 신중하게 필터링하고, GPT-4V를 사용하여 응답을 생성했습니다. 다중 모드 문서/차트 데이터. (1) 연구팀은 TextCap이 TextVQA와 동일한 교육 이미지 세트를 사용한다는 것을 깨달았기 때문에 교육 데이터에서 TextCap을 제거합니다. 이를 통해 연구팀은 TextVQA를 평가할 때 모델의 제로샷 OCR 기능을 더 잘 이해할 수 있었습니다. 모델의 OCR 기능을 유지하고 더욱 향상시키기 위해 본 연구에서는 TextCap을 DocVQA 및 SynDog-EN으로 대체했습니다. (2) Qwen-VL-7B-Chat을 통해 이 연구에서는 플롯과 차트에 대한 더 나은 이해를 위해 ChartQA, DVQA 및 AI2D를 추가로 추가했습니다. 연구팀은 또한 Vicuna-1.5(7B 및 13B) 외에도 Mistral-7B 및 Nous-Hermes-2-Yi-34B를 포함한 더 많은 LLM 솔루션을 채택하여 LLaVA를 활성화하는 것을 고려하고 있다고 밝혔습니다. 더 넓은 범위의 사용자와 더 많은 장면을 지원합니다. 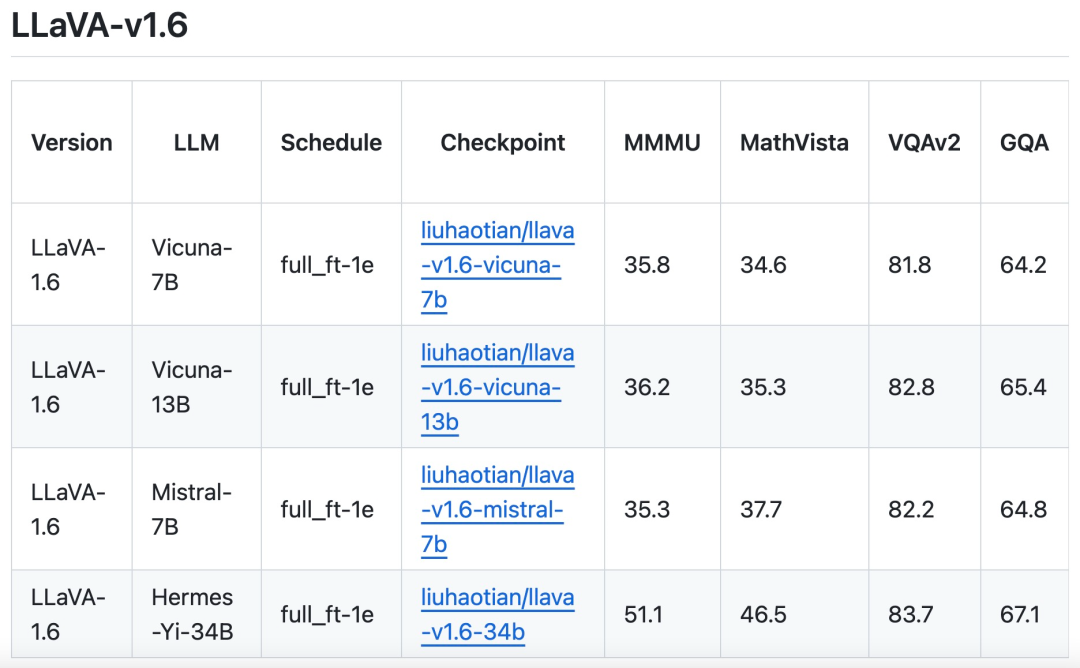
위 내용은 Gemini Pro를 따라잡고 추론 및 OCR 기능을 향상시키는 LLaVA-1.6은 너무 강력합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!