
SQL 효율성 최적화 연구

- 王林앞으로
- 2024-01-28 08:09:051138검색
2016년 8월 상하이 MOORACLE 컨퍼런스에서 Chen Hongyi(Old K)님이 공유한 사례입니다. 병합 SQL을 plsql에 다시 작성하여 실행 효율성이 크게 향상되었습니다. Tiger Liu는 이 사례를 처음 봤을 때 실행 계획에 표시된 각 테이블의 실제 레코드 수를 눈치채지 못했고 plsql을 다시 작성하는 방법이 분석 함수를 작성하는 방법보다 더 효율적이라고 생각하지도 않았습니다. 첸 선생님과 여러 번의 이메일 토론을 하고 나서야 실행 계획을 자세히 살펴보았습니다.
원본 SQL은 다음과 같습니다. 를 사용하여 t_customer c에 병합(
a.cstno, t_trade a의 금액을 선택하세요.
(t_trade에서 cstno,max(trade_date) trade_date를 선택하세요
그룹 by cstno)b
여기서 a.cstno = b.cstno 및 a.trade_date=b.trade_date
) 음
on(c.cstno = m.cstno)
일치하면 그때
업데이트 세트 c.amount = m.amount;
이 SQL은 병합 연산을 통해 사용자 거래 내역 테이블(t_trade)의 최근 소비 금액을 사용자 정보 테이블(t_customer)의 소비 금액 필드로 업데이트하는 SQL입니다.
실행 계획:

타이거 리우 참고:
분석 함수 작성 방법을 익히기 전, SQL의 빨간색 부분은 그룹별로 다른 필드 정보를 작성하는 일반적인 방법이며, 이는 이 SQL의 실행 효율성이 떨어지는 근본적인 이유이기도 합니다.
원래 SQL에는 또 다른 숨겨진 위험이 있습니다. 즉, t_trade의 특정 cstno에 해당하는 최대 trade_date가 반복되면 이 SQL은 ORA-30926 오류를 보고하고 실행될 수 없습니다.
실행 계획(두 테이블의 실제 데이터 볼륨 정보)을 주의 깊게 살펴보지 않으면 이러한 종류의 SQL에 대한 일반적인 최적화 방법은 분석 함수를 사용하여 다시 작성하는 것입니다.
다시 쓰기 방법 1: 를 사용하여 t_customer c에 병합(
a.cstno,a.amount from
을 선택하세요.(거래 날짜,cstno,금액,
을 선택하세요.row_number()over(partition by cstno order by trade_date desc) RNO from t_trade)a
RNO=1
) 음
on(c.cstno = m.cstno)
일치하면 그때
업데이트 세트 c.amount = m.amount;
이 재작성 방법은 원본 SQL보다 훨씬 효율적이며 특정 cstno에 해당하는 최대 trade_date에 대해 반복 오류가 발생하는 문제가 없습니다.
하지만 Chen 선생님은 분석 함수의 재작성 방법을 사용하지 않고, 대신 두 테이블 간의 데이터 양의 큰 차이를 기반으로 SQL을 보다 효율적인 plsql로 재작성했습니다.
다시 쓰는 방법 2:선언
잔액수;
시작
for v in (t_customer에서 * 선택)
루프
vamount에서 금액 선택
(t_trade에서 금액 선택, 여기서 cstno=v.cstno trade_date desc로 주문)
rownum
t_customer 설정 금액 업데이트 = vmount 여기서 cstno=v.cstno;
끝 루프
커밋;
끝;
/
원래 SQL 실행 계획에 따르면, t_customer 테이블의 레코드 수는 1,000개를 넘을 정도로 비교적 적은 반면, t_trade 테이블의 레코드 수는 1:10,000의 비율로 1,000만 개라는 것을 알고 있습니다. 이것이 실제 데이터인지 테스트 데이터인지 알 수 있는 것은 사용자가 1,000명이 넘고 사용자가 평균 10,000개의 소비 내역을 가지고 있어 실제 데이터처럼 보이지 않습니다.
두 테이블 간의 데이터가 상당히 다른 특별한 경우에는 plsql 작성 방법이 분석 함수 작성 방법보다 실제로 더 효율적입니다. 이 재작성은 매우 영리합니다.
이 두 가지 재작성의 장점과 단점을 분석해 보겠습니다.1. plsql의 재작성 방법은 t_customer 테이블이 상대적으로 작고 t_customer 및 t_trade 테이블의 레코드 수 비율이 상대적으로 큰 상황에 적합합니다. . 이 예에서 t_customer 테이블의 레코드 수가 100,000개라면 분석 함수를 작성하는 방법은 plsql을 작성하는 방법보다 수십~수백 배 빠릅니다.
3. plsql을 다시 작성하려면 t_trade 테이블의 cstno + trade_date 두 필드에 대한 공동 인덱스가 있어야 합니다. 분석 함수를 다시 작성하는 데에는 인덱스 지원이 필요하지 않습니다.
4. t_trade와 같이 수천만 개의 레코드가 있는 테이블의 경우 분석 기능을 사용하는 작성 방법은 병렬성을 켜면 속도를 높일 수 있습니다. plsql을 다시 작성할 때 효율성을 높이려면 먼저 t_customer 테이블을 cstno로 그룹화해야 합니다. 여러 세션을 사용하여 동시에 실행합니다.
첸 선생님의 plsql이 단일 SQL로 구현될 수 있는지 확인해 보겠습니다. SQL 코드는 다음과 같습니다.
를 사용하여 t_customer c에 병합
(tc.cstno를 선택하세요,
(금액선택
t_trade td1에서
여기서 td1.cstno=tc.cstno 및 td1.trade_date = (t_trade td2에서 max(trade_date) 선택, 여기서 tc.cstno = td2.cstno) 및 rownum=1) 금액
from t_customer tc
) 음
on(c.cstno = m.cstno)
일치하면 그때
업데이트 세트 c.amount = m.amount;
실행 계획은 대략 다음과 같습니다.
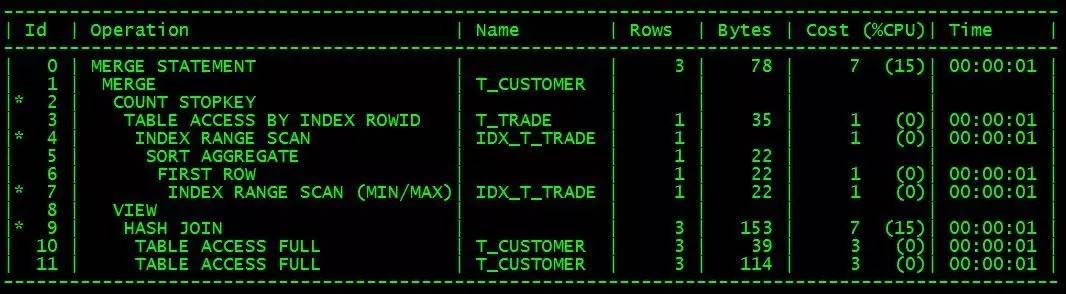
이 작성 방법도 t_trade 테이블에 cstno+trade_date 공동 인덱스(IDX_T_TRADE)가 있어야 하며, T_customer 테이블의 데이터 양은 T_trade보다 훨씬 적습니다.
실행 계획에 따르면 이 SQL의 실행 효율성은 plsql 작성 효율성과 비슷해야 합니다.
요약:SQL 최적화는 비효율적인 SQL 작성을 방지하는 것 외에도 주로 테이블의 데이터 볼륨 및 데이터 분포에 따라 달라집니다. plsql의 재작성 방법은 일부 데이터의 경우 더 높은 효율성을 보여줍니다. 효율성은 원래 SQL만큼 좋지 않을 수 있습니다. 그러나 최적화 아이디어는 배울 가치가 있습니다.
분석 기능이 다시 작성되는 방식은 데이터가 어떻게 분산되어 있든 원래 SQL보다 더 효율적이고 다재다능할 것입니다.
이 예제를 다시 작성하기 전에도 SQL을 사용하는 개발자와 DBA가 많았을 것입니다. 분석 기능을 사용하는 방법을 이해한 후에는 원래 SQL을 작성하는 비효율적인 방법을 완전히 버려야 합니다.
마지막 plsql은 단일 SQL로 다시 작성되었습니다. 로직이 복잡하고 이해하기 어려울 것 같습니다. 일반적으로 이러한 다시 작성은 사용되지 않습니다.
동일한 문장이지만 최적화에 대한 명확한 공식은 없습니다. 최적화 프로그램은 죽었지만 인간의 두뇌는 살아 있습니다. 원칙을 숙지해야만 SQL 실행 효율성이 더욱 높아질 수 있습니다.
위 내용은 SQL 효율성 최적화 연구의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!