
Jia Yangqing의 대규모 추론 비용 고효율 순위가 공개되었습니다.

- 王林앞으로
- 2024-01-26 14:15:34701검색
"대형 모델 API는 손실을 가져오는 거래입니까?"
대형 언어 모델 기술이 실용화되면서 많은 기술 회사에서 개발자가 사용할 수 있는 대형 모델 API를 출시했습니다. 그러나 특히 OpenAI가 하루 70만 달러를 지출하고 있다는 점을 고려하면 대형 모델을 기반으로 한 비즈니스가 지속될 수 있을지 의문이 들지 않을 수 없습니다.
이번 주 목요일, AI 스타트업 마션이 우리를 위해 세심하게 계산해 주었습니다.
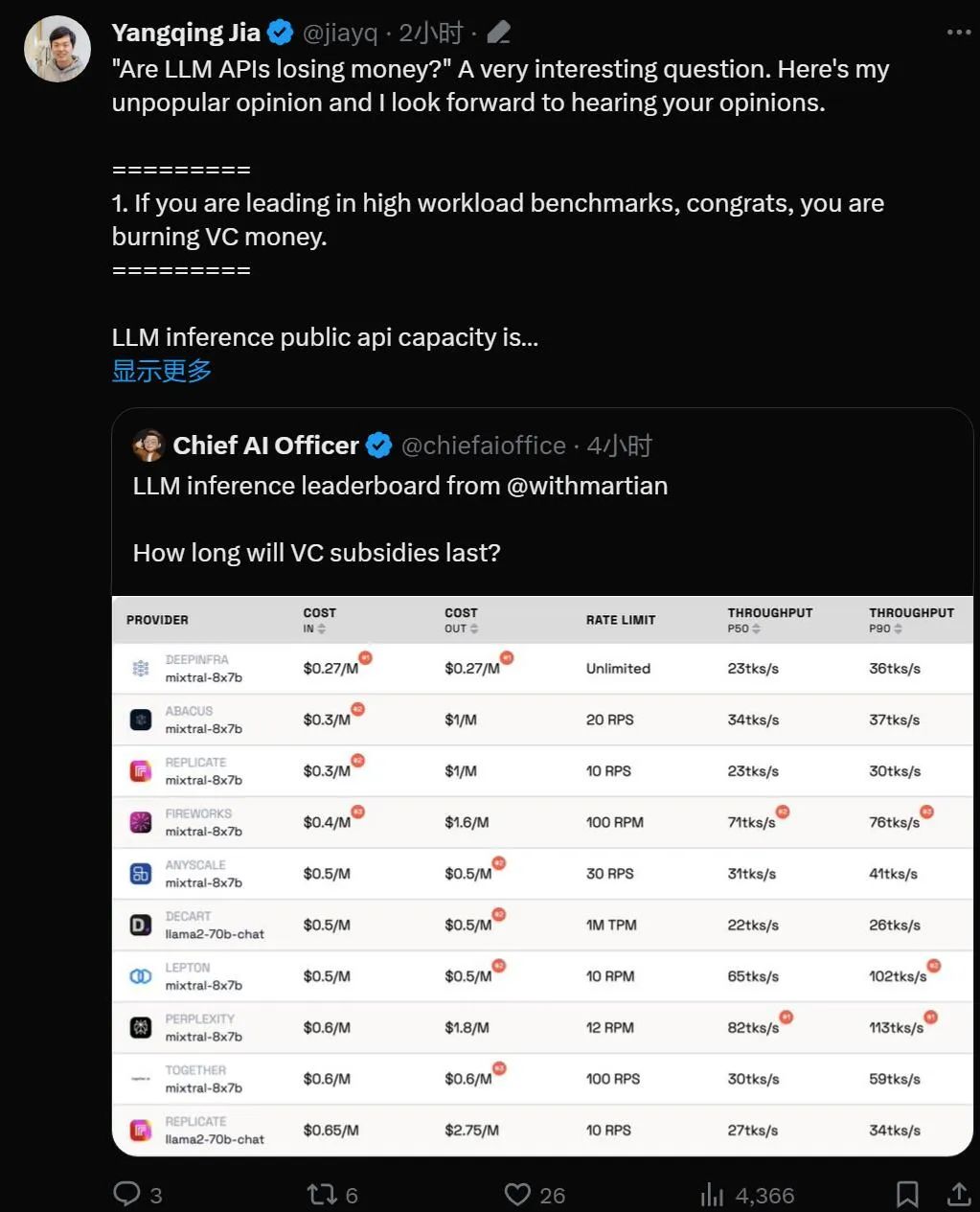
순위 링크: https://leaderboard.withmartian.com/
LLM Inference Provider Leaderboard는 대형 모델을 위한 API 추론 제품의 오픈 소스 순위입니다. 비용, 속도 제한을 벤치마킹합니다. , 처리량, 각 공급업체의 Mixtral-8x7B 및 Llama-2-70B-Chat 공개 엔드포인트에 대한 P50 및 P90 TTFT입니다.
서로 경쟁하지만 Martian은 각 회사의 대규모 모델 서비스가 비용에 따라 처리량 및 속도 제한에 상당한 차이가 있습니다. 이러한 차이는 5배의 비용 차이, 6배의 처리량 차이, 심지어 더 큰 속도 제한 차이를 초과합니다. 다양한 API를 선택하는 것은 비즈니스 수행의 일부일지라도 최고의 성능을 얻는 데 중요합니다.
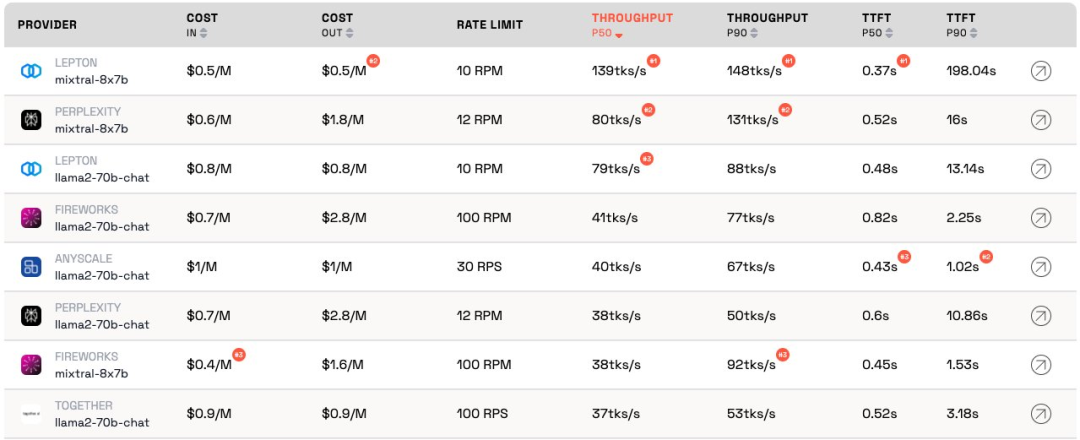
현재 순위에 따르면 Anyscale에서 제공하는 서비스는 Llama-2-70B의 중간 서비스 로드에서 최고의 처리량을 보입니다. 대규모 서비스 로드의 경우 Together AI는 Llama-2-70B 및 Mixtral-8x7B에서 P50 및 P90 처리량으로 가장 좋은 성능을 발휘했습니다.
또한 Jia Yangqing의 LeptonAI는 짧은 입력 및 긴 출력 신호로 작은 작업 로드를 처리할 때 최고의 처리량을 보여주었습니다. 130tks/s의 P50 처리량은 현재 시장에 나와 있는 모든 제조업체가 제공하는 모델 중에서 가장 빠릅니다.
저명 AI 학자이자 Lepton AI의 창립자인 Jia Yangqing이 순위가 공개된 직후에 그가 말한 내용을 살펴보겠습니다.

Jia Yangqing은 먼저 인공 지능 분야의 업계 현황을 설명한 후 벤치마크 테스트의 중요성을 확인한 후 마지막으로 LeptonAI가 사용자가 최고의 기본 AI 전략을 찾는 데 도움이 될 것이라고 지적했습니다.
1. 빅 모델 API는 "돈을 태운다"
모델이 높은 워크로드 벤치마크에서 앞서면 축하합니다. "돈을 태운다".
LLM 공개 API의 용량에 대해 추론하는 것은 레스토랑을 운영하는 것과 같습니다. 요리사가 있고 고객 트래픽을 추정해야 합니다. 요리사를 고용하는 데에는 돈이 듭니다. 지연 시간과 처리량은 "고객을 위해 얼마나 빨리 요리할 수 있는지"로 이해될 수 있습니다. 합리적인 사업을 위해서는 "합리적인" 수의 셰프가 필요합니다. 즉, 몇 초 만에 발생하는 갑작스러운 트래픽 폭주가 아니라 정상적인 트래픽을 처리할 수 있는 용량을 원합니다. 교통량이 급증한다는 것은 기다리는 것을 의미합니다. 그렇지 않으면 "요리사"는 할 일이 없습니다.
인공지능의 세계에서는 GPU가 '요리사' 역할을 합니다. 기본 로드가 폭증합니다. 작업 부하가 낮은 경우 기준 부하가 일반 트래픽과 혼합되며, 측정 결과는 현재 작업 부하에서 서비스가 어떻게 수행되는지 정확하게 나타냅니다.
높은 서비스 로드 시나리오는 중단을 유발하기 때문에 흥미롭습니다. 벤치마크는 하루/주에 몇 번만 실행되므로 일반적인 트래픽은 아닙니다. 요리사가 얼마나 빨리 요리하는지 확인하기 위해 100명의 사람들이 현지 레스토랑에 모여들었다고 상상해 보세요. 양자물리학 용어를 빌리자면, 이것을 '관찰자 효과'라고 합니다. 간섭이 강할수록(즉, 버스트 부하가 클수록) 정확도는 낮아집니다. 즉, 서비스에 갑자기 높은 부하를 가하고 서비스가 매우 빠르게 응답하는 것을 보면 서비스에 유휴 용량이 꽤 많다는 것을 알 수 있습니다. 투자자로서 이러한 상황을 볼 때 다음과 같이 질문해야 합니다. 이렇게 돈을 소각하는 방식이 책임이 있습니까?
2. 이 모델은 결국 비슷한 성능을 발휘하게 됩니다
인공지능 분야는 경쟁적인 경쟁을 좋아하는데, 정말 흥미롭습니다. 모두가 동일한 솔루션으로 신속하게 수렴하고 GPU 덕분에 Nvidia가 항상 승리합니다. 이는 훌륭한 오픈 소스 프로젝트 덕분에 vLLM이 좋은 예입니다. 즉, 공급자로서 자신의 모델이 다른 모델보다 성능이 훨씬 떨어지더라도 오픈 소스 솔루션을 살펴보고 우수한 엔지니어링을 적용하면 쉽게 따라잡을 수 있습니다.
3. "고객으로서 나는 공급자의 비용에 관심이 없습니다."
AI 애플리케이션 빌더에게는 운이 좋습니다. 항상 "돈을 태울" 의향이 있는 API 공급자가 있습니다. AI 업계는 트래픽 확보를 위해 돈을 태우고 있고, 다음 단계는 이익을 걱정하는 것이다.
벤치마킹은 지루하고 오류가 발생하기 쉬운 작업입니다. 좋든 나쁘든 승자는 당신을 칭찬하고 패자는 당신을 비난하는 경우가 많습니다. 컨볼루셔널 신경망 벤치마크의 마지막 라운드에서도 마찬가지였습니다. 쉬운 작업은 아니지만 벤치마킹은 AI 인프라에서 다음 10배를 달성하는 데 도움이 될 것입니다.
LeptonAI는 인공지능 프레임워크와 클라우드 인프라를 기반으로 사용자가 최고의 AI 기본 전략을 찾을 수 있도록 도와줍니다.
위 내용은 Jia Yangqing의 대규모 추론 비용 고효율 순위가 공개되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!