AIF(인공지능 피드백)가 RLHF를 대체하게 되나요?
대형 모델 분야에서 미세 조정은 모델 성능을 향상시키는 중요한 단계입니다. 오픈 소스 대형 모델의 수가 점차 증가함에 따라 사람들은 다양한 미세 조정 방법을 요약했으며 그 중 일부는 좋은 결과를 얻었습니다. 최근 메타대학교와 뉴욕대학교 연구진은 '자기 보상 방식'을 사용해 대형 모델이 스스로 미세 조정 데이터를 생성할 수 있게 해 사람들에게 새로운 충격을 안겨주었습니다. 새로운 방법에서 저자는 Llama 2 70B를 세 번의 반복으로 미세 조정했으며 생성된 모델은 Claude 2, Gemini Pro 및 GPT -4를 포함하여 AlpacaEval 2.0 순위에서 기존의 중요한 대형 모델보다 성능이 뛰어났습니다. . 그래서 이 논문은 arXiv에 게시된 지 몇 시간 만에 사람들의 관심을 끌었습니다. 방법이 아직 오픈소스는 아니지만, 논문에 사용된 방법이 명확하게 기술되어 있어 재현이 어렵지 않을 것으로 믿습니다. 
인간 선호도 데이터를 사용하여 LLM(대형 언어 모델)을 튜닝하면 사전 훈련된 모델의 명령 추적 성능을 크게 향상시킬 수 있는 것으로 알려져 있습니다. GPT 시리즈에서 OpenAI는 대규모 모델이 인간의 선호도로부터 보상 모델을 학습할 수 있도록 한 다음, 보상 모델을 동결하고 강화 학습을 사용하여 LLM을 훈련하는 데 사용할 수 있는 인간 피드백 강화 학습(RLHF)의 표준 방법을 제안했습니다. 방법은 큰 성공을 거두었습니다. 최근 등장한 새로운 아이디어는 보상 모델 교육을 완전히 피하고 DPO(직접 선호 최적화)와 같은 인간 선호도를 직접 활용하여 LLM을 교육하는 것입니다. 위의 두 경우 모두 튜닝은 인간 선호도 데이터의 크기와 품질에 의해 병목 현상이 발생하며, RLHF의 경우 튜닝 품질도 학습된 동결 보상 모델의 품질에 의해 병목 현상이 발생합니다. Meta의 새로운 작업에서 저자는 이러한 병목 현상을 피하기 위해 LLM 튜닝 중에 동결되지 않고 지속적으로 업데이트되는 자체 개선 보상 모델을 훈련할 것을 제안합니다. 이 접근 방식의 핵심은 (보상 모델과 언어 모델로 분할하는 대신) 훈련 중에 필요한 모든 기능을 갖춘 에이전트를 개발하여 지시에 따른 작업의 사전 훈련과 다중 작업 훈련을 허용하는 것입니다. 작업 마이그레이션을 달성하기 위해 여러 작업을 동시에 교육합니다. 그래서 저자는 에이전트가 모델의 지침을 따르고 주어진 프롬프트에 대한 응답을 생성하는 역할을 하며 예제를 기반으로 새로운 지침을 생성하고 평가하여 자신의 지침에 추가할 수 있는 자기 보상형 언어 모델을 소개합니다. 트레이닝 세트 . 새로운 방법은 반복적 DPO와 유사한 프레임워크를 사용하여 이러한 모델을 교육합니다. 그림 1에 표시된 것처럼 시드 모델에서 시작하면 각 반복마다 모델이 새로 생성된 프롬프트에 대한 후보 응답을 생성하고 동일한 모델에 의해 보상이 할당되는 자체 지침 생성 프로세스가 있습니다. 후자는 LLM-as-a-Judge의 지시를 통해 달성되며, 이는 지침을 따르는 작업으로도 볼 수 있습니다. 생성된 데이터로부터 선호도 데이터 세트가 구성되고 모델의 다음 반복은 DPO를 통해 교육됩니다.
저자가 제안한 접근 방식은 먼저 사전 훈련된 기본 언어 모델과 소량의 인간 주석 시드 데이터에 대한 액세스를 가정합니다. 두 가지 기술을 모두 갖추는 것을 목표로 합니다. 1. 지침을 따르세요. 사용자의 요청을 설명하는 프롬프트를 제공하고 고품질의 유용한(그리고 무해한) 응답을 생성할 수 있습니다. 2. 자기 교육 생성: 자신의 훈련 세트에 추가할 예제를 따라 새로운 지침을 생성하고 평가하는 능력. 이러한 기술은 모델이 자체 정렬을 수행할 수 있도록 하는 데 사용됩니다. 즉, AIF(인공 지능 피드백)를 사용하여 자체적으로 반복적으로 훈련하는 데 사용되는 구성 요소입니다. 자기 지침 생성에는 후보 응답을 생성한 다음 모델 자체가 품질을 판단하도록 하는 작업이 포함됩니다. 즉, 자체 보상 모델 역할을 하여 외부 모델의 필요성을 대체합니다. 이는 LLM-as-a-Judge 메커니즘[Zheng et al., 2023b]을 통해, 즉 응답 평가를 지침에 따른 작업으로 공식화함으로써 달성됩니다. 자체 생성된 AIF 선호도 데이터가 훈련 세트로 사용되었습니다. 따라서 미세 조정 과정에서는 "학습자"와 "판사"라는 두 가지 역할에 동일한 모델이 사용됩니다. 새로운 심사위원 역할을 기반으로 모델은 상황별 미세 조정을 통해 성과를 더욱 향상시킬 수 있습니다. 전체적인 자체 정렬 프로세스는 각 모델이 이전 모델보다 개선된 일련의 모델을 구축하여 진행되는 반복 프로세스입니다. 여기서 중요한 점은 모델이 생성 능력을 향상시키고 자체 보상 모델과 동일한 생성 메커니즘을 사용할 수 있기 때문에 이러한 반복을 통해 보상 모델 자체가 향상될 수 있으며 이는 보상 모델에 내재된 표준과 일치한다는 것입니다. 접근 방식에 차이가 있습니다. 연구원들은 이러한 접근 방식이 이러한 학습 모델의 잠재력을 높여 미래에 스스로를 향상시키고 제한적인 병목 현상을 제거할 수 있다고 믿습니다.
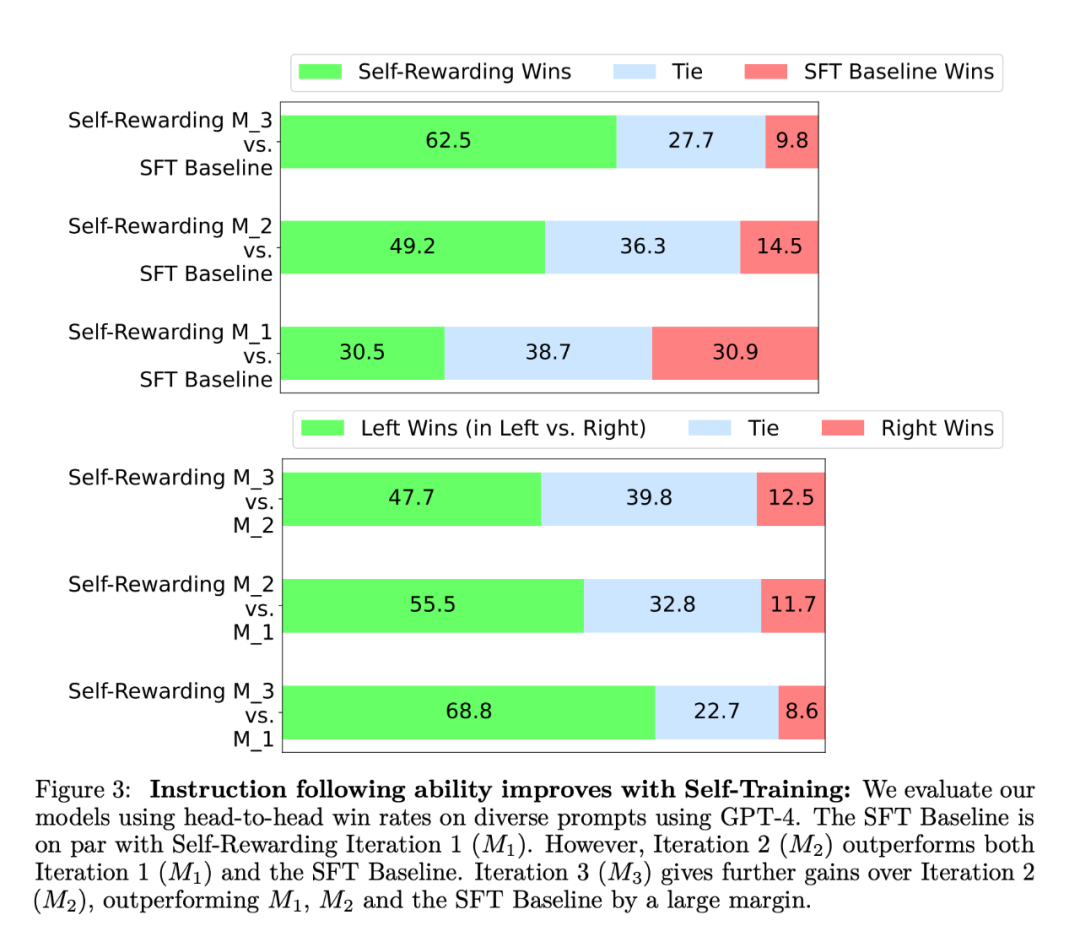
실험에서 연구원은 Llama 2 70B를 기본 사전 훈련 모델로 사용했습니다. 그들은 자기 보상 LLM 정렬이 지침에 따른 성과를 향상시킬 뿐만 아니라 기본 시드 모델에 비해 보상 모델링 기능도 향상된다는 것을 발견했습니다. 이는 반복 학습에서 모델이 이전 반복보다 특정 반복에서 더 나은 품질의 선호도 데이터 세트를 제공할 수 있음을 의미합니다. 이 효과는 현실 세계에서 포화되는 경향이 있지만, 결과적인 보상 모델(및 이에 따른 LLM)이 인간이 작성한 원시 시드 데이터로만 훈련된 모델보다 낫다는 흥미로운 가능성을 제공합니다. 지시 추종 능력 측면에서 실험 결과는 그림 3과 같습니다. 연구원들은 AlpacaEval 2 순위 목록에서 자기 보상 모델을 평가했으며 그 결과는 표 1에 나와 있습니다. 그들은 정면 평가와 동일한 결론을 관찰했습니다. 즉, 훈련 반복의 승률은 GPT4-Turbo보다 1차 반복의 9.94%, 2차 반복의 15.38%, 2차 반복의 20.44%로 더 높았습니다. 반복 3. 한편, Iteration 3 모델은 Claude 2, Gemini Pro 및 GPT4 0613을 포함한 많은 기존 모델보다 성능이 뛰어납니다.
보상 모델링 평가 결과는 표 2에 나와 있습니다. 결론은 다음과 같습니다.
EFT는 SFT 기준에 비해 개선되었으며 IFT+EFT를 사용한 경우 5가지 측정 지표가 모두 개선되었습니다. 예를 들어, 인간과의 쌍별 정확도 일치는 65.1%에서 78.7%로 증가했습니다.
자체 학습을 통해 보상 모델링 역량을 향상하세요. 일련의 자기 보상 훈련 후에는 다음 반복에 대한 자기 보상을 제공하는 모델의 능력이 향상되고 지침을 따르는 능력도 향상됩니다.
LLMA 판사 팁의 중요성. 연구원들은 다양한 프롬프트 형식을 사용했으며 SFT 기준선을 사용할 때 LLMas-a-Judge 프롬프트가 쌍별 정확도가 더 높다는 것을 발견했습니다.
저자는 자기 보상 훈련 방법이 모델의 지시 추적 능력을 향상시킬 뿐만 아니라 반복을 통해 모델의 보상 모델링 능력도 향상시킨다고 믿습니다. 이것은 예비 연구일 뿐이지만 흥미로운 연구 방향인 것 같습니다. 이러한 모델은 지침 준수를 개선하고 양성 주기를 달성하기 위해 향후 반복에서 보상을 더 잘 할당할 수 있습니다. 이 방법은 또한 더 복잡한 판단 방법에 대한 특정 가능성을 열어줍니다. 예를 들어, 대규모 모델은 데이터베이스를 검색하여 답변의 정확성을 확인할 수 있으므로 더 정확하고 신뢰할 수 있는 결과를 얻을 수 있습니다. 참조 콘텐츠: https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_언어_models_meta_2024/위 내용은 자기 보상을 받는 대형 모델: Llama2는 메타 학습을 통해 스스로를 최적화하여 GPT-4의 성능을 능가합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!







 연구원들은 AlpacaEval 2 순위 목록에서 자기 보상 모델을 평가했으며 그 결과는 표 1에 나와 있습니다. 그들은 정면 평가와 동일한 결론을 관찰했습니다. 즉, 훈련 반복의 승률은 GPT4-Turbo보다 1차 반복의 9.94%, 2차 반복의 15.38%, 2차 반복의 20.44%로 더 높았습니다. 반복 3. 한편, Iteration 3 모델은 Claude 2, Gemini Pro 및 GPT4 0613을 포함한 많은 기존 모델보다 성능이 뛰어납니다.
연구원들은 AlpacaEval 2 순위 목록에서 자기 보상 모델을 평가했으며 그 결과는 표 1에 나와 있습니다. 그들은 정면 평가와 동일한 결론을 관찰했습니다. 즉, 훈련 반복의 승률은 GPT4-Turbo보다 1차 반복의 9.94%, 2차 반복의 15.38%, 2차 반복의 20.44%로 더 높았습니다. 반복 3. 한편, Iteration 3 모델은 Claude 2, Gemini Pro 및 GPT4 0613을 포함한 많은 기존 모델보다 성능이 뛰어납니다. 