



트윈 신경망은 이중 가지 구조의 신경망으로 유사성 측정, 분류, 검색 작업에 자주 사용됩니다. 이러한 네트워크의 두 가지 분기는 동일한 구조와 매개변수를 갖습니다. 입력이 각각 두 개의 분기를 거친 후 유사성 측정 레이어(예: 유클리드 거리, 맨해튼 거리 등)를 통해 유사성을 계산합니다. 훈련 중에는 일반적으로 대조 손실 함수 또는 삼중 손실 함수가 사용됩니다.
대비 손실 함수는 샴 신경망에 대한 이진 분류 손실 함수로, 유사한 샘플의 유사성을 1에 가깝게, 서로 다른 유형의 샘플의 유사성을 0에 가깝게 최대화하는 것을 목표로 합니다. 수식은 다음과 같습니다.
L_{con}(y,d)=ycdot d^2+(1-y)cdotmax(m-d,0)^2
이 손실 함수는 측정에 사용됩니다. two 샘플의 카테고리에 따라 샘플 간의 유사성이 최적화됩니다. 이 중 y는 샘플이 동일한 카테고리에 속하는지 여부를 나타내고, d는 두 샘플의 유사성을 나타내며, m은 미리 설정된 경계값을 나타냅니다. y=1일 때 손실 함수의 목표는 동일한 범주의 두 샘플이 더 유사하더라도 d를 가능한 한 작게 만드는 것입니다. 이때, 손실함수의 값은 d의 제곱으로 표현될 수 있는데, 즉 손실함수의 값은 d^2이다. y=0일 때 손실 함수의 목표는 서로 다른 두 범주의 샘플이 최대한 유사하더라도 d를 m보다 크게 만드는 것입니다. 이때, d가 m보다 작을 경우 손실함수의 값은 d^2로, d가 m보다 클 경우에는 손실함수의 값이 0이 되어 샘플간 유사성을 나타낸다. 경계값 m을 가정하면 손실은 더 이상 계산되지 않습니다.
삼중항 손실 함수는 트윈 신경망에서 사용되는 손실 함수로, 동일한 유형의 샘플 간의 거리를 최소화하고 최대화하는 것을 목표로 합니다. 서로 다른 유형의 샘플 사이의 거리. 이 함수의 수학적 표현은 다음과 같습니다:
L_{tri}(a,p,n)=max(|f(a)-f(p)|^2-|f(a)-f( n )|^2+margin,0)
이 중 a는 앵커 샘플, p는 동일한 유형의 샘플, n은 다른 유형의 샘플, f는 샴 신경망의 특징 추출 계층을 나타냅니다. , |cdot|은 유클리드 거리를 나타내고, margin은 미리 설정된 경계값을 나타냅니다. 손실 함수의 목표는 동일한 유형의 샘플 간의 거리를 가능한 한 작게 만들고, 다른 유형의 샘플 간의 거리를 최대한 크게, 마진보다 크게 만드는 것입니다. 동일한 유형의 샘플 사이의 거리가 다른 유형의 샘플 거리에서 마진을 뺀 값보다 작을 때, 동일한 유형의 샘플 사이의 거리가 다른 유형의 샘플 사이의 거리보다 클 경우 손실 함수의 값은 0입니다. 마진을 빼면 손실 함수의 값은 두 거리의 차이입니다.
대비 손실 함수와 삼중항 손실 함수는 모두 일반적으로 사용되는 트윈 신경망 손실 함수입니다. 이들의 목표는 특징 공간에서 동일한 범주의 샘플을 최대한 가깝게 만들고, 서로 다른 범주의 샘플을 최대한 멀리 만드는 것입니다. 기능 공간에서. 실제 적용에서는 특정 작업 및 데이터 세트를 기반으로 적절한 손실 함수를 선택하고 모델 최적화를 위해 다른 기술(예: 데이터 향상, 정규화 등)과 결합할 수 있습니다.
위 내용은 트윈 신경망에 공통 손실 함수 적용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 解析二元神经网络的功能和原理Jan 22, 2024 pm 03:00 PM
解析二元神经网络的功能和原理Jan 22, 2024 pm 03:00 PM二元神经网络(BinaryNeuralNetworks,BNN)是一种神经网络,其神经元仅具有两个状态,即0或1。相对于传统的浮点数神经网络,BNN具有许多优点。首先,BNN可以利用二进制算术和逻辑运算,加快训练和推理速度。其次,BNN减少了内存和计算资源的需求,因为二进制数相对于浮点数来说需要更少的位数来表示。此外,BNN还具有提高模型的安全性和隐私性的潜力。由于BNN的权重和激活值仅为0或1,其模型参数更难以被攻击者分析和逆向工程。因此,BNN在一些对数据隐私和模型安全性有较高要求的应用中具
 探究RNN、LSTM和GRU的概念、区别和优劣Jan 22, 2024 pm 07:51 PM
探究RNN、LSTM和GRU的概念、区别和优劣Jan 22, 2024 pm 07:51 PM在时间序列数据中,观察之间存在依赖关系,因此它们不是相互独立的。然而,传统的神经网络将每个观察看作是独立的,这限制了模型对时间序列数据的建模能力。为了解决这个问题,循环神经网络(RNN)被引入,它引入了记忆的概念,通过在网络中建立数据点之间的依赖关系来捕捉时间序列数据的动态特性。通过循环连接,RNN可以将之前的信息传递到当前观察中,从而更好地预测未来的值。这使得RNN成为处理时间序列数据任务的强大工具。但是RNN是如何实现这种记忆的呢?RNN通过神经网络中的反馈回路实现记忆,这是RNN与传统神经
 计算神经网络的浮点操作数(FLOPS)Jan 22, 2024 pm 07:21 PM
计算神经网络的浮点操作数(FLOPS)Jan 22, 2024 pm 07:21 PMFLOPS是计算机性能评估的标准之一,用来衡量每秒的浮点运算次数。在神经网络中,FLOPS常用于评估模型的计算复杂度和计算资源的利用率。它是一个重要的指标,用来衡量计算机的计算能力和效率。神经网络是一种复杂的模型,由多层神经元组成,用于进行数据分类、回归和聚类等任务。训练和推断神经网络需要进行大量的矩阵乘法、卷积等计算操作,因此计算复杂度非常高。FLOPS(FloatingPointOperationsperSecond)可以用来衡量神经网络的计算复杂度,从而评估模型的计算资源使用效率。FLOP
 模糊神经网络的定义和结构解析Jan 22, 2024 pm 09:09 PM
模糊神经网络的定义和结构解析Jan 22, 2024 pm 09:09 PM模糊神经网络是一种将模糊逻辑和神经网络结合的混合模型,用于解决传统神经网络难以处理的模糊或不确定性问题。它的设计受到人类认知中模糊性和不确定性的启发,因此被广泛应用于控制系统、模式识别、数据挖掘等领域。模糊神经网络的基本架构由模糊子系统和神经子系统组成。模糊子系统利用模糊逻辑对输入数据进行处理,将其转化为模糊集合,以表达输入数据的模糊性和不确定性。神经子系统则利用神经网络对模糊集合进行处理,用于分类、回归或聚类等任务。模糊子系统和神经子系统之间的相互作用使得模糊神经网络具备更强大的处理能力,能够
 改进的RMSprop算法Jan 22, 2024 pm 05:18 PM
改进的RMSprop算法Jan 22, 2024 pm 05:18 PMRMSprop是一种广泛使用的优化器,用于更新神经网络的权重。它是由GeoffreyHinton等人在2012年提出的,并且是Adam优化器的前身。RMSprop优化器的出现主要是为了解决SGD梯度下降算法中遇到的一些问题,例如梯度消失和梯度爆炸。通过使用RMSprop优化器,可以有效地调整学习速率,并且自适应地更新权重,从而提高深度学习模型的训练效果。RMSprop优化器的核心思想是对梯度进行加权平均,以使不同时间步的梯度对权重的更新产生不同的影响。具体而言,RMSprop会计算每个参数的平方
 浅层特征与深层特征的结合在实际应用中的示例Jan 22, 2024 pm 05:00 PM
浅层特征与深层特征的结合在实际应用中的示例Jan 22, 2024 pm 05:00 PM深度学习在计算机视觉领域取得了巨大成功,其中一项重要进展是使用深度卷积神经网络(CNN)进行图像分类。然而,深度CNN通常需要大量标记数据和计算资源。为了减少计算资源和标记数据的需求,研究人员开始研究如何融合浅层特征和深层特征以提高图像分类性能。这种融合方法可以利用浅层特征的高计算效率和深层特征的强表示能力。通过将两者结合,可以在保持较高分类准确性的同时降低计算成本和数据标记的要求。这种方法对于那些数据量较小或计算资源有限的应用场景尤为重要。通过深入研究浅层特征和深层特征的融合方法,我们可以进一
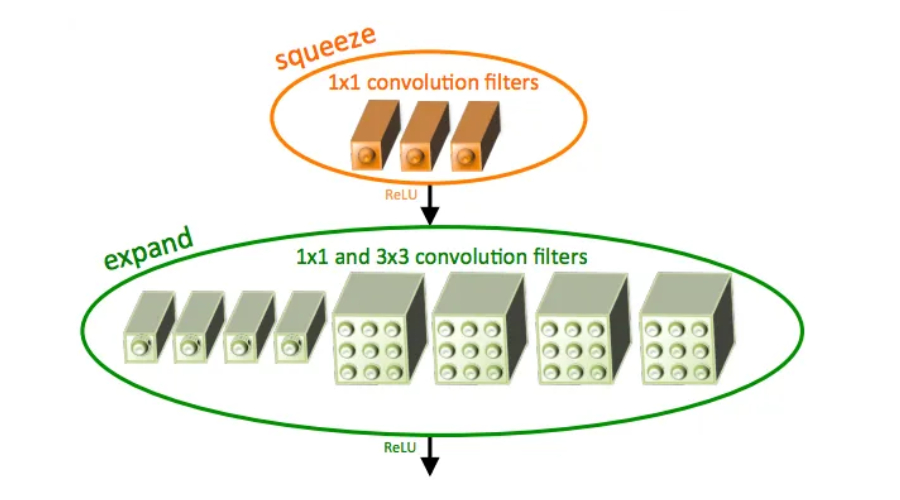 SqueezeNet简介及其特点Jan 22, 2024 pm 07:15 PM
SqueezeNet简介及其特点Jan 22, 2024 pm 07:15 PMSqueezeNet是一种小巧而精确的算法,它在高精度和低复杂度之间达到了很好的平衡,因此非常适合资源有限的移动和嵌入式系统。2016年,DeepScale、加州大学伯克利分校和斯坦福大学的研究人员提出了一种紧凑高效的卷积神经网络(CNN)——SqueezeNet。近年来,研究人员对SqueezeNet进行了多次改进,其中包括SqueezeNetv1.1和SqueezeNetv2.0。这两个版本的改进不仅提高了准确性,还降低了计算成本。SqueezeNetv1.1在ImageNet数据集上的精度
 蒸馏模型的基本概念Jan 22, 2024 pm 02:51 PM
蒸馏模型的基本概念Jan 22, 2024 pm 02:51 PM模型蒸馏是一种将大型复杂的神经网络模型(教师模型)的知识转移到小型简单的神经网络模型(学生模型)中的方法。通过这种方式,学生模型能够从教师模型中获得知识,并且在表现和泛化性能方面得到提升。通常情况下,大型神经网络模型(教师模型)在训练时需要消耗大量计算资源和时间。相比之下,小型神经网络模型(学生模型)具备更高的运行速度和更低的计算成本。为了提高学生模型的性能,同时保持较小的模型大小和计算成本,可以使用模型蒸馏技术将教师模型的知识转移给学生模型。这种转移过程可以通过将教师模型的输出概率分布作为学生


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

WebStorm Mac 버전
유용한 JavaScript 개발 도구

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

Dreamweaver Mac版
시각적 웹 개발 도구

