1월 22일, Yi 시리즈 모델 패밀리가 새로운 멤버를 맞이했습니다. Yi Vision Language(Yi-VL) 다중 모달 언어 대형 모델이 공식적으로 전 세계에 오픈 소스로 공개되었습니다. Yi-VL 모델은 Yi-VL-34B와 Yi-VL-6B의 두 가지 버전을 포함하여 Yi 언어 모델을 기반으로 개발된 것으로 보고되었습니다. Yi-VL 모델 오픈 소스 주소:
- https://huggingface.co/01-ai
- https://www.modelscope.cn/organization/01ai
뛰어난 이미지 및 텍스트 이해와 대화 생성 기능을 갖춘 Yi-VL 모델은 영어 데이터 세트 MMMU 및 중국어 데이터 세트 CMMMU에서 선도적인 결과를 달성하여 복잡한 학제간 작업에서 강력한 강점을 보여주었습니다.
MMMU(전체 이름 Massive Multi-discipline Multi-modal Understanding & Reasoning) 데이터 세트에는 6개 핵심 분야(예술 및 디자인, 비즈니스, 과학, 보건 및 의학, 인문학 및 사회 과학, 기술 및 과학)의 11,500개 데이터가 포함되어 있습니다. 엔지니어링) 매우 이질적인 이미지 유형과 서로 얽힌 텍스트-이미지 정보와 관련된 문제는 모델의 고급 인식 및 추론 기능에 대한 요구가 매우 높습니다. 이 테스트 세트에서
Yi-VL-34B는 41.6%의 정확도로 일련의 다중 모드 대형 모델을 능가했으며, 이는 GPT-4V(55.7%)에 이어 두 번째로 강력한 학제간 지식 이해와 응용 능력을 입증했습니다. 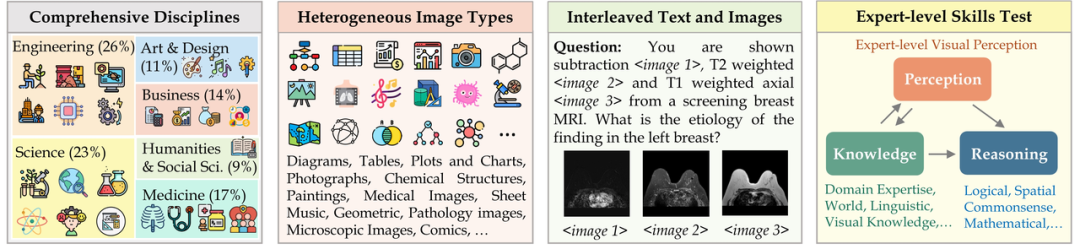
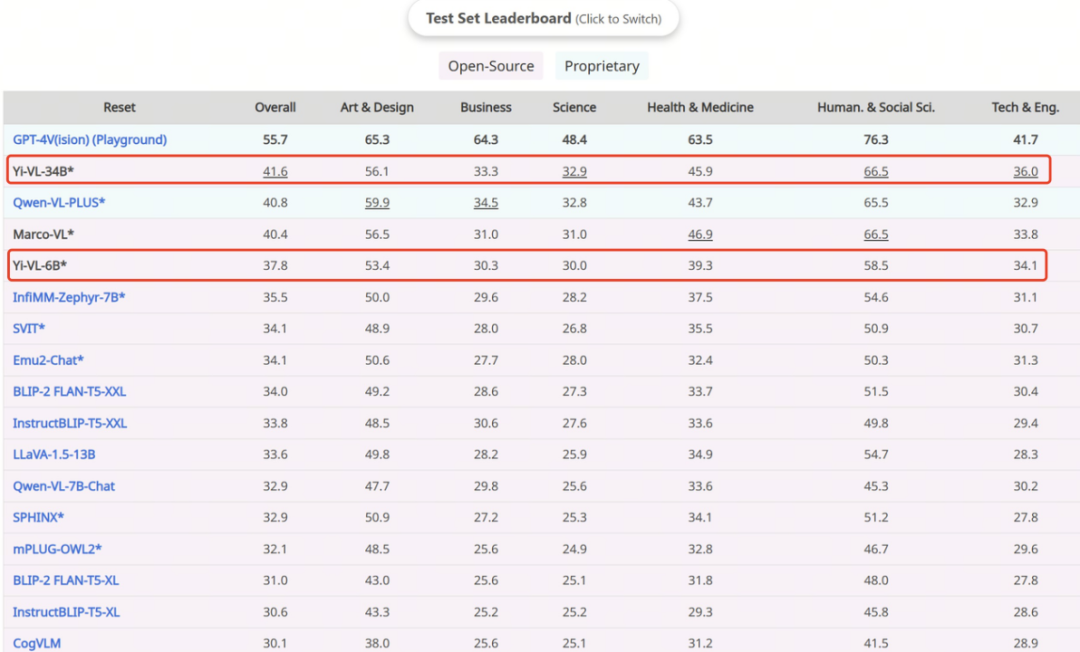
출처: https://mmmu-benchmark.github.io 중국 장면을 위해 생성된 CMMMU 데이터 세트에서 Yi-VL 모델은 "더 나은 이해를 보여줍니다. " 중국인의 독특한 장점. CMMMU에는 대학 시험, 퀴즈, 교과서에서 파생된 약 12,000개의 중국어 복합 문제가 포함되어 있습니다. 그 중
GPT-4V는 이 테스트 세트에서 43.7%의 정확도를 보였고, Yi-VL-34B는 36.5%의 정확도로 그 뒤를 바짝 쫓으며 기존 오픈 소스 다중 모드 모델 중 선두를 차지했습니다. 
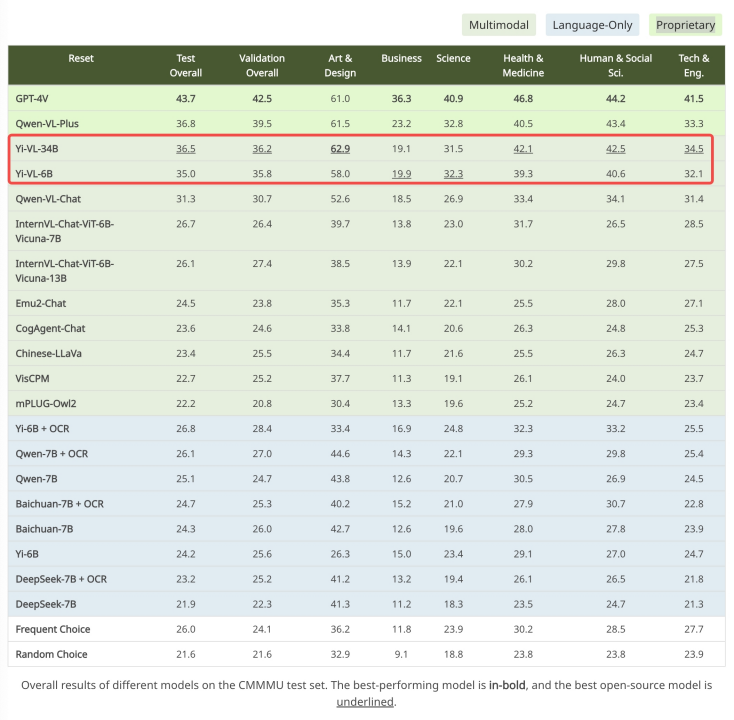
출처: https://cmmmu-benchmark.github.io/ 그러면 Yi-VL 모델은 그래픽 및 텍스트 대화와 같은 다양한 시나리오에서 어떻게 작동합니까? ?
먼저 두 가지 예를 살펴보겠습니다.


Yi 언어 모델의 강력한 텍스트 이해 기능을 기반으로 이미지를 정렬하는 것만으로도 좋은 다중 모드 비전을 얻을 수 있음을 알 수 있습니다. 언어 모델 - 이는 Yi-VL 모델의 핵심 하이라이트 중 하나이기도 합니다.
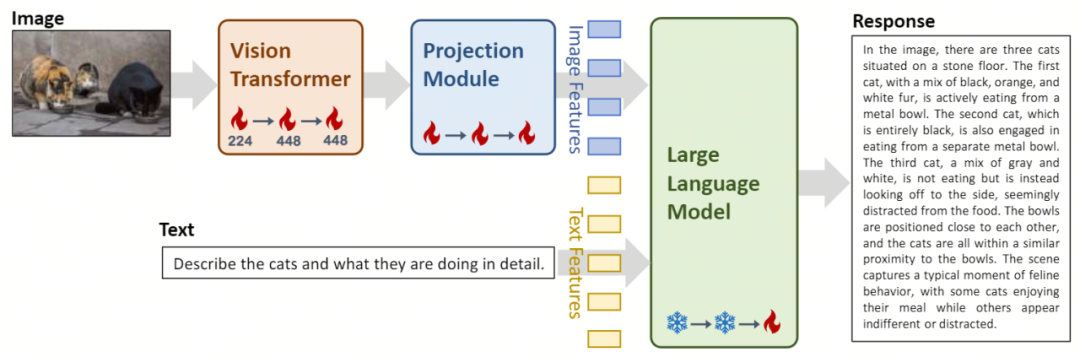 Yi-VL 모델 아키텍처 설계 및 훈련 방법 프로세스 개요. 아키텍처 디자인에서 Yi-VL 모델 은 오픈 소스 LLaVA 아키텍처를 기반으로 하며 세 가지 주요 모듈을 포함합니다:
Yi-VL 모델 아키텍처 설계 및 훈련 방법 프로세스 개요. 아키텍처 디자인에서 Yi-VL 모델 은 오픈 소스 LLaVA 아키텍처를 기반으로 하며 세 가지 주요 모듈을 포함합니다:
- Vision Transformer(약어로 ViT)가 사용됩니다. 이미지 인코딩의 경우 오픈 소스 OpenClip ViT-H/14 모델을 사용하여 학습 가능한 매개변수를 초기화하고 대규모 "이미지-텍스트" 쌍에서 특징을 추출하는 방법을 학습하여 모델에 이미지를 처리하고 이해하는 기능을 제공합니다.
- Projection 모듈은 이미지 특징과 텍스트 특징을 모델에 공간적으로 정렬하는 기능을 제공합니다. 이 모듈은 레이어 정규화를 포함하는 MLP(Multilayer Perceptron)로 구성됩니다. 이 설계를 통해 모델은 시각적 정보와 텍스트 정보를 보다 효과적으로 융합하고 처리할 수 있어 다중 모드 이해 및 생성의 정확성이 향상됩니다.
- Yi-34B-Chat 및 Yi-6B-Chat 대규모 언어 모델의 도입으로 Yi-VL은 강력한 언어 이해 및 생성 기능을 제공합니다. 모델의 이 부분은 고급 자연어 처리 기술을 사용하여 Yi-VL이 복잡한 언어 구조를 깊이 이해하고 일관되고 관련성 있는 텍스트 출력을 생성하도록 돕습니다.
훈련 방법에서 Yi-VL 모델의 훈련 과정은 모델의 시각 및 언어 처리 능력을 종합적으로 향상시키는 것을 목표로 세심하게 설계된 세 단계로 나뉩니다.
- 1단계: Zero One Wish는 1억 개의 "이미지-텍스트" 쌍 데이터 세트를 사용하여 ViT 및 프로젝션 모듈을 교육합니다. 이 단계에서는 이미지 해상도가 224x224로 설정되어 특정 아키텍처에서 ViT의 지식 획득 기능을 향상시키는 동시에 대규모 언어 모델과 효율적으로 정렬할 수 있습니다.
- 두 번째 단계: Zero One Thing은 ViT의 이미지 해상도를 448x448로 높입니다. 이러한 개선으로 모델은 복잡한 시각적 세부 사항을 더 잘 인식할 수 있습니다. 이 단계에서는 약 2,500만 개의 이미지-텍스트 쌍을 사용합니다.
- 세 번째 단계: Zero One Wish는 다중 모드 채팅 상호 작용에서 모델의 성능을 향상시키는 것을 목표로 훈련을 위해 전체 모델의 매개 변수를 엽니다. 훈련 데이터는 총 약 100만 개의 "이미지-텍스트" 쌍을 포함한 다양한 범위의 데이터 소스를 다루며 데이터의 폭과 균형을 보장합니다.
또한, Zero-One-Things 기술팀은 Yi 언어 모델의 강력한 언어 이해 및 생성 기능을 기반으로 BLIP, Flamingo, EVA 등을 사용하여 이미지 이해와 원활한 그래픽 텍스트 대화를 위한 효율적인 다중 모드 그래픽 텍스트 모델을 신속하게 교육합니다. Yi 시리즈 모델은 다중 모드 모델의 기본 언어 모델로 사용되어 오픈 소스 커뮤니티에 새로운 옵션을 제공할 수 있습니다. 현재 Yi-VL 모델은 Hugging Face 및 ModelScope와 같은 플랫폼에 공개되어 있습니다. 사용자는 다음 링크를 통해 그래픽 및 텍스트 대화와 같은 다양한 시나리오에서 이 모델의 탁월한 성능을 경험할 수 있습니다. Yi-VL 다중 모달 언어 모델의 강력한 기능을 살펴보고 최첨단 AI 기술 성과를 경험해 보세요. 위 내용은 Yi-VL 대형 모델은 오픈 소스이며 MMMU 및 CMMMU에서 1위를 차지합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

