
예제를 사용하여 바이너리 클래스의 혼동 행렬을 이해하는 방법을 보여줍니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-01-22 14:30:22987검색
혼란 행렬은 기계 학습 엔지니어가 모델 성능을 더 잘 이해하는 데 도움이 되는 평가 모델입니다. 이 기사에서는 바이너리 클래스 불균형 데이터 세트를 예로 들어 테스트 세트는 기계 학습 모델을 평가하기 위해 60개의 포지티브 클래스 샘플과 40개의 네거티브 클래스 샘플로 구성됩니다.
바이너리 클래스 데이터 세트에는 두 가지 데이터 범주만 있으며 간단히 "양수" 및 "음수" 범주로 명명할 수 있습니다.
이제 이 이진 분류 문제의 혼동 행렬을 완전히 이해하려면 먼저 다음 용어를 숙지해야 합니다.
참 긍정(TP)은 긍정 클래스에 속하는 샘플이 올바르게 분류된다는 의미입니다.
True Negative(TN)은 Negative 클래스에 속하는 샘플이 올바르게 분류되었음을 의미합니다.
False Positive(FP)는 음성 클래스에 속하는 샘플이 양성 클래스에 속하는 것으로 잘못 분류되는 것을 의미합니다.
False Negative(FN)는 양성 클래스에 속하는 샘플이 음성 클래스로 잘못 분류되는 것을 의미합니다.
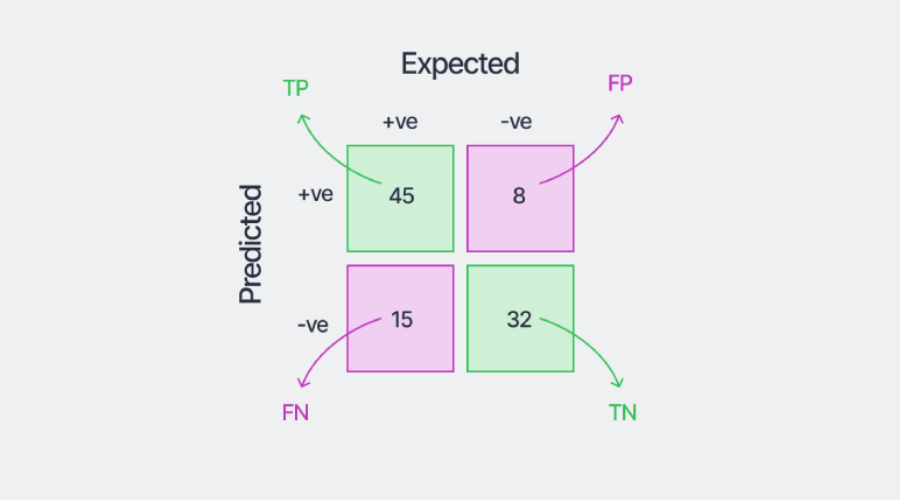
모델 학습을 통해 얻을 수 있는 혼동 행렬의 예는 이 예제 데이터 세트에 대해 위에 나와 있습니다.
첫 번째 열의 숫자를 더하면 양성 클래스의 총 샘플 수가 45+15=60임을 알 수 있습니다. 네거티브 클래스의 샘플 수(이 경우 40개)를 얻으려면 두 번째 열의 숫자를 더하세요. 모든 상자에 있는 숫자의 합은 평가된 총 샘플 수를 나타냅니다. 또한 올바른 범주는 행렬의 대각선 요소(양수 45개, 음수 32개)입니다.
이제 모델은 왼쪽 하단 상자를 양성 샘플로 분류하므로 모델이 예측한 '부정'이 틀렸기 때문에 'FN'이라고 합니다. 마찬가지로 오른쪽 상단 상자는 네거티브 클래스에 속할 것으로 예상되지만 모델에서는 "포지티브"로 분류됩니다. 따라서 이를 "FP"라고 합니다. 행렬의 서로 다른 네 가지 숫자를 사용하여 모델을 보다 주의 깊게 평가할 수 있습니다.
위 내용은 예제를 사용하여 바이너리 클래스의 혼동 행렬을 이해하는 방법을 보여줍니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!