
RoSA: 대규모 모델 매개변수를 효율적으로 미세 조정하기 위한 새로운 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-01-18 17:27:17731검색
언어 모델이 전례 없는 규모로 확장됨에 따라 다운스트림 작업을 포괄적으로 미세 조정하는 데 비용이 많이 듭니다. 이러한 문제를 해결하기 위해 연구자들은 PEFT 방식에 주목하고 채택하기 시작했다. PEFT 방법의 주요 아이디어는 미세 조정 범위를 작은 매개변수 세트로 제한하여 계산 비용을 줄이면서도 자연어 이해 작업에서 최첨단 성능을 달성하는 것입니다. 이러한 방식으로 연구자들은 고성능을 유지하면서 컴퓨팅 리소스를 절약할 수 있어 자연어 처리 분야에 새로운 연구 핫스팟을 가져올 수 있습니다.
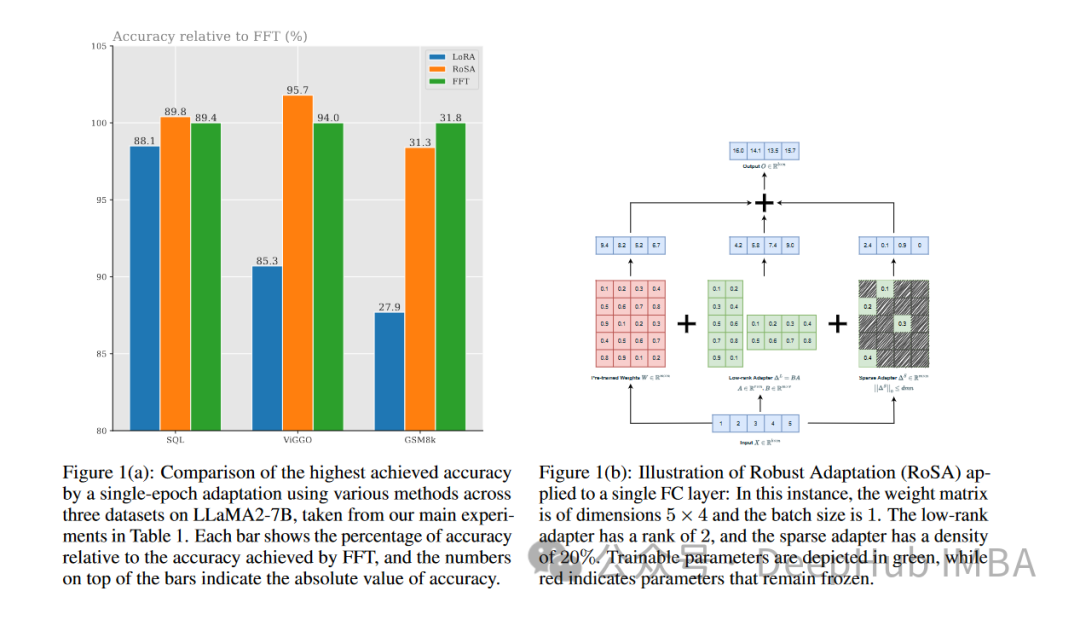
RoSA는 일련의 벤치마크에 대한 실험을 통해 동일한 매개변수 예산을 사용하면서 이전의 낮은 순위 적응(LoRA)보다 더 나은 성능을 발휘하는 것으로 나타났습니다. - 튜닝 방법.
이 기사에서는 RoSA 원칙, 방법 및 결과를 심층적으로 살펴보고 RoSA의 성과가 어떻게 의미 있는 진전을 이루는지 설명합니다. 대규모 언어 모델을 효과적으로 미세 조정하려는 사람들을 위해 RoSA는 이전 솔루션보다 뛰어난 새로운 솔루션을 제공합니다.
매개변수의 효율적인 미세 조정의 필요성
NLP는 GPT-4와 같은 변환기 기반 언어 모델에 의해 혁명을 일으켰습니다. 이 모델은 큰 텍스트 말뭉치에 대한 사전 학습을 통해 강력한 언어 표현을 학습합니다. 그런 다음 간단한 프로세스를 통해 이러한 표현을 다운스트림 언어 작업으로 전송합니다.
모델 크기가 수십억에서 수조 개의 매개변수로 증가함에 따라 미세 조정으로 인해 엄청난 계산 부담이 발생합니다. 예를 들어, 1조 7600억 개의 매개변수가 있는 GPT-4와 같은 모델의 경우 미세 조정에 수백만 달러의 비용이 소요될 수 있습니다. 이로 인해 실제 애플리케이션에 배포하는 것은 매우 비실용적입니다.
PEFT 방법은 미세 조정의 매개변수 범위를 제한하여 효율성과 정확성을 향상시킵니다. 최근 효율성과 정확성을 절충하는 다양한 PEFT 기술이 등장했습니다.
LoRA
주요 PEFT 방법은 LoRA(저위 적응)입니다. LoRA는 Meta와 MIT의 연구진에 의해 2021년에 출시되었습니다. 이 접근 방식은 변압기가 헤드 매트릭스에서 낮은 순위 구조를 나타낸다는 관찰에 의해 동기가 부여되었습니다. LoRA는 이러한 낮은 순위 구조를 활용하여 계산 복잡성을 줄이고 모델 효율성과 속도를 향상시키기 위해 제안되었습니다.
LoRA는 처음 k개의 특이 벡터만 미세 조정하고 다른 매개변수는 변경되지 않습니다. 이를 위해서는 O(n) 대신 O(k)개의 추가 매개변수만 필요합니다.
이 낮은 순위 구조를 활용하여 LoRA는 다운스트림 작업 일반화에 필요한 의미 있는 신호를 캡처하고 이러한 상위 특이 벡터에 대한 미세 조정을 제한하여 최적화 및 추론을 더욱 효율적으로 만들 수 있습니다.
실험에 따르면 LoRA는 100배 이상 적은 매개변수를 사용하면서도 GLUE 벤치마크에서 완벽하게 미세 조정된 성능을 발휘할 수 있습니다. 그러나 모델 규모가 계속 확장됨에 따라 LoRA를 통해 강력한 성능을 얻으려면 순위 k를 높여야 하므로 전체 미세 조정에 비해 계산 절감 효과가 줄어듭니다.
RoSA 이전에 LoRA는 다양한 행렬 분해와 같은 기술을 사용하거나 소수의 추가 미세 조정 매개변수를 추가하는 등의 기술을 사용하여 약간만 개선한 PEFT 방법의 최첨단을 대표했습니다.
RoSA(강력한 적응)
RoSA(강력한 적응)는 새로운 매개변수 효율적인 미세 조정 방법을 도입합니다. RoSA는 하위 구조에만 의존하는 것이 아니라 강력한 주성분 분석(강력한 PCA)에서 영감을 받았습니다.
전통적인 주성분 분석에서는 데이터 매트릭스 강력한 PCA는 한 단계 더 나아가 X를 깨끗한 낮은 순위 L과 "오염/손상된" 희소 S로 분해합니다.
RoSA는 여기서 영감을 얻어 언어 모델의 미세 조정을 다음과 같이 분해합니다.
우세한 작업 관련 신호에 근접하도록 미세 조정된 LoRA와 유사한 하위 순위 적응형(L) 행렬
A 높이 L이 놓친 잔여 신호를 인코딩하는 선택적으로 미세 조정된 매우 적은 수의 대규모 매개변수를 포함하는 희소 미세 조정(S) 행렬입니다.
잔여 희소 구성요소를 명시적으로 모델링하면 RoSA는 LoRA만 사용할 때보다 더 높은 정확도를 달성할 수 있습니다.
RoSA는 모델의 머리 행렬에 대한 낮은 순위 분해를 수행하여 L을 구성합니다. 이는 다운스트림 작업에 유용한 기본 의미 표현을 인코딩합니다. 그런 다음 RoSA는 각 계층의 가장 중요한 상위 m개 매개변수를 선택적으로 S로 미세 조정하고 다른 모든 매개변수는 변경하지 않습니다. 이 단계에서는 낮은 순위 피팅에 적합하지 않은 잔여 신호를 캡처합니다.
미세 조정 매개변수 m의 수는 LoRA 단독으로 요구되는 랭크 k보다 한 자릿수 작습니다. 따라서 L의 낮은 순위 헤드 매트릭스와 결합하여 RoSA는 매우 높은 매개변수 효율성을 유지합니다.
RoSA는 간단하지만 효과적인 다른 최적화도 사용합니다.
잔여 희소 연결: S 잔차는 레이어 정규화 및 피드포워드 하위 레이어를 거치기 전에 각 변환기 블록의 출력에 직접 추가됩니다. 이는 L이 놓친 신호를 시뮬레이션할 수 있습니다.
독립적인 희소 마스크: 미세 조정을 위해 S에서 선택한 메트릭은 각 변환기 레이어에 대해 독립적으로 생성됩니다.
공유 하위 구조: LoRA와 마찬가지로 L의 모든 레이어 간에 동일한 하위 기본 U,V 행렬이 공유됩니다. 이는 일관된 하위 공간에서 의미론적 개념을 포착합니다.
이러한 아키텍처 선택은 RoSA 모델링에 전체 미세 조정과 유사한 유연성을 제공하는 동시에 최적화 및 추론을 위한 매개변수 효율성을 유지합니다. RoSA는 강력한 하위 순위 적응과 매우 희박한 잔차를 결합한 PEFT 방법을 활용하여 정확도와 효율성을 절충하는 새로운 기술을 달성합니다.
실험 및 결과
연구원들은 텍스트 감지, 감정 분석, 자연어 추론 및 견고성 테스트와 같은 작업을 다루는 12개 NLU 데이터 세트의 포괄적인 벤치마크에서 RoSA를 평가했습니다. 그들은 120억 개의 매개변수 모델을 사용하여 인공지능 보조 LLM을 기반으로 RoSA를 사용하여 실험을 수행했습니다.
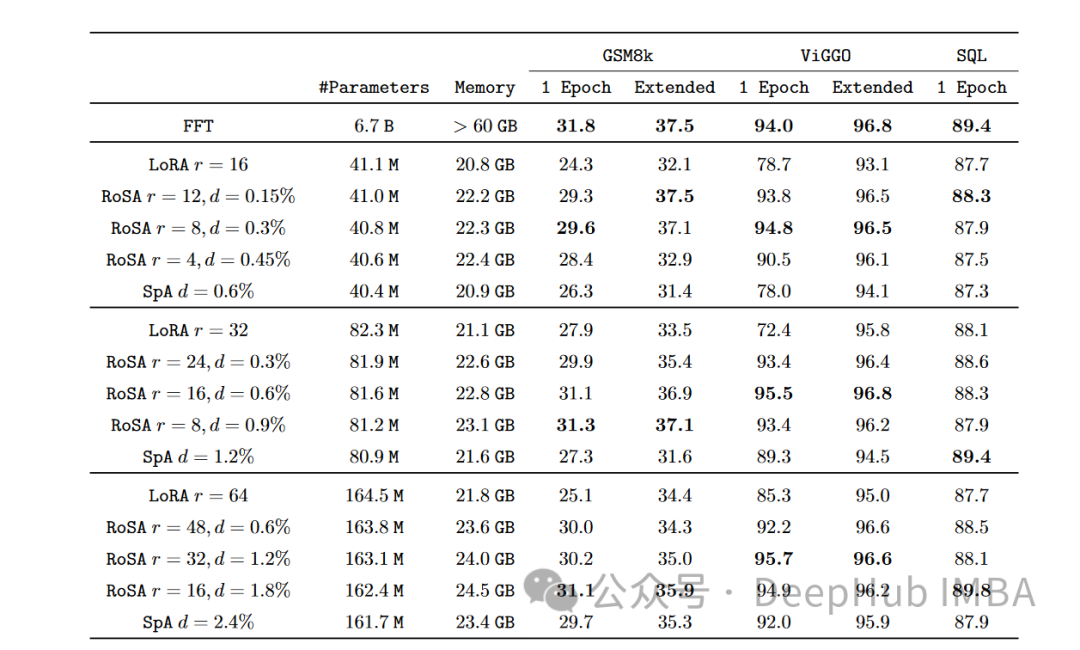
모든 작업에서 RoSA는 동일한 매개변수를 사용할 때 LoRA보다 훨씬 더 나은 성능을 발휘합니다. 두 방법의 전체 매개변수는 전체 모델의 약 0.3%입니다. 이는 LoRA의 경우 k = 16이고 RoSA의 경우 m = 5120인 경우 두 경우 모두 약 450만 개의 미세 조정 매개변수가 있음을 의미합니다.
RoSA는 또한 순수 희소 미세 조정 기준선의 성능과 일치하거나 그 이상입니다.
적대적 사례에 대한 견고성을 평가하는 ANLI 벤치마크에서 RoSA는 55.6점, LoRA는 52.7점을 받았습니다. 이는 일반화 및 교정의 개선을 보여줍니다.
감정 분석 작업 SST-2와 IMDB의 경우 RoSA의 정확도는 91.2%, 96.9%에 달하는 반면 LoRA의 정확도는 90.1%, 95.3%에 달합니다.
어려운 단어 의미 명확성 테스트인 WIC에서 RoSA는 F1 점수 93.5점을, LoRA는 F1 점수 91.7점을 획득했습니다.
RoSA는 일반적으로 12개 데이터세트 전체에서 일치하는 매개변수 예산 하에서 LoRA보다 더 나은 성능을 보여줍니다.
특히 RoSA는 작업별 튜닝이나 전문화 없이도 이러한 이점을 얻을 수 있습니다. 이로 인해 RoSA는 범용 PEFT 솔루션으로 사용하기에 적합합니다.
요약
언어 모델의 규모가 지속적으로 빠르게 성장함에 따라 이를 미세 조정하기 위한 계산 요구 사항을 줄이는 것이 해결해야 할 시급한 문제입니다. LoRA와 같은 매개변수 효율적인 적응형 훈련 기술은 초기 성공을 보였지만 낮은 순위 근사의 본질적인 한계에 직면해 있습니다.
RoSA는 강력한 하위 순위 분해와 잔여 고도로 희소한 미세 조정을 유기적으로 결합하여 설득력 있는 새로운 솔루션을 제공합니다. 선택적 희소 잔차를 통해 낮은 순위 피팅을 벗어나는 신호를 고려하여 PEFT의 성능을 크게 향상시킵니다. 경험적 평가에서는 다양한 NLU 작업 세트에서 LoRA 및 제어되지 않은 희소성 기준에 비해 상당한 개선이 있음을 보여줍니다.
RoSA는 개념적으로 단순하지만 고성능이며 매개변수 효율성, 적응형 표현 및 지속적인 학습의 교차점을 더욱 발전시켜 언어 지능을 확장할 수 있습니다.
위 내용은 RoSA: 대규모 모델 매개변수를 효율적으로 미세 조정하기 위한 새로운 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
관련 기사
더보기- 매개 변수가 약간 개선되고 성능 지수가 폭발합니다! 구글: 대규모 언어 모델은 '신비한 기술'을 숨긴다
- GPT-3의 수학 문제 해결 정확도가 92.5%로 향상되었습니다! Microsoft는 미세 조정 없이 '과학' 언어 모델을 만들 수 있는 MathPrompter를 제안합니다.
- AI 분야에 또 다른 '강자' 추가, 메타, 새로운 대규모 언어 모델 LLaMA 출시
- 사이버 보안을 강화하기 위해 AI 챗봇과 대규모 언어 모델을 구축하는 6가지 방법
- 국내 최초 기업인 360 Intelligent Brain이 중국정보통신기술학원의 신뢰받는 AIGC 대형 언어 모델 기능 평가를 통과했습니다.