
RoboFlamingo 프레임워크를 통해 오픈 소스 VLM의 잠재력이 극대화됩니다.

- PHPz앞으로
- 2024-01-17 14:12:24964검색
최근에는 대형 모델에 대한 연구가 가속화되고 있으며 다양한 작업에서 다중 모드 이해와 시공간 추론 능력이 점차 입증되고 있습니다. 로봇의 다양한 구현 작업은 당연히 언어 명령 이해, 장면 인식, 시공간 계획에 대한 요구 사항이 높습니다. 이는 자연스럽게 대형 모델의 기능을 최대한 활용하여 로봇 분야로 마이그레이션할 수 있는지에 대한 질문으로 이어집니다. 기본 작업 순서를 직접 계획합니까?
ByteDance Research는 오픈 소스 다중 모달 언어 비전 대형 모델 OpenFlamingo를 사용하여 단일 기계 훈련만 필요한 사용하기 쉬운 RoboFlamingo 로봇 작동 모델을 개발합니다. VLM은 간단한 미세 조정을 통해 Robotics VLM으로 전환될 수 있으며, 이는 언어 상호 작용 로봇 작동 작업에 적합합니다.
로봇 작업 데이터세트 CALVIN에 대해 OpenFlamingo에서 검증했습니다. 실험 결과 RoboFlamingo는 언어 주석이 포함된 데이터의 1%만 사용하고 일련의 로봇 작업 작업에서 SOTA 성능을 달성하는 것으로 나타났습니다. RT-X 데이터 세트가 공개되면서 오픈 소스 데이터를 기반으로 사전 훈련되고 다양한 로봇 플랫폼에 맞게 미세 조정된 RoboFlamingo가 간단하고 효과적인 대규모 로봇 모델 프로세스가 될 것으로 기대됩니다. 또한 이 논문은 로봇 작업에 대한 다양한 전략 헤드, 다양한 훈련 패러다임 및 다양한 Flamingo 구조를 사용하여 VLM의 미세 조정 성능을 테스트하고 몇 가지 흥미로운 결론에 도달했습니다.

- 프로젝트 홈페이지: https://roboflamingo.github.io
- 코드 주소: https://github.com/RoboFlamingo/RoboFlamingo
- 주소: https://arxiv.org/abs/2311.01378
연구배경
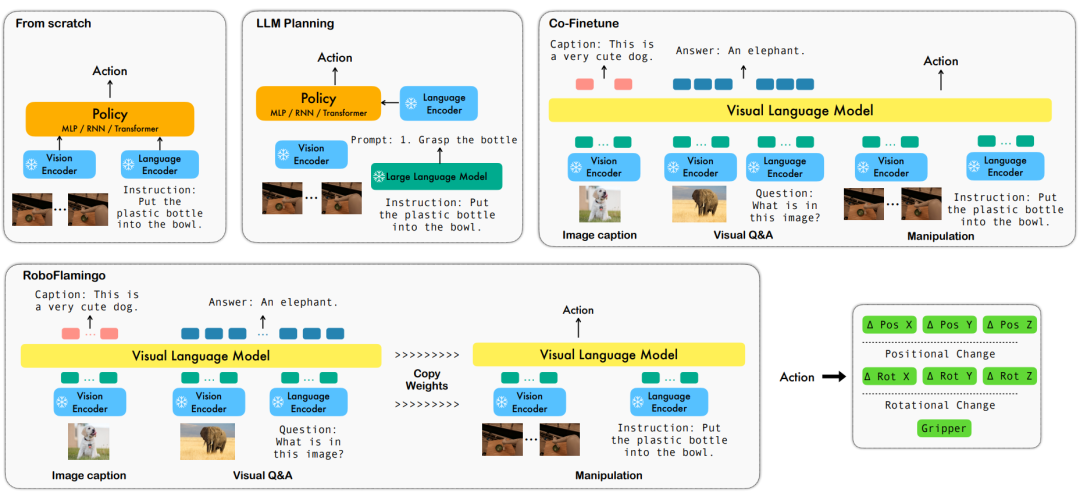
언어 기반 로봇 작동은 다중 모드 데이터를 포함하는 구현 지능 분야에서 중요한 응용 분야입니다. 이해 시각, 언어 및 제어를 포함한 처리. 최근 몇 년 동안 시각적 언어 기반 모델(VLM)은 이미지 설명, 시각적 질문 응답, 이미지 생성과 같은 영역에서 상당한 발전을 이루었습니다. 그러나 이러한 모델을 로봇 작업에 적용하는 것은 시각적 및 언어 정보를 통합하는 방법, 로봇 작업의 시간 순서를 처리하는 방법과 같은 과제에 여전히 직면해 있습니다. 이러한 문제를 해결하려면 모델의 다중 모드 표현 기능 개선, 보다 효과적인 모델 융합 메커니즘 설계, 로봇 작업의 순차적 특성에 적응하는 모델 구조 및 알고리즘 도입과 같은 여러 측면의 개선이 필요합니다. 또한 이러한 모델을 훈련하고 평가하기 위해 더욱 풍부한 로봇 공학 데이터 세트를 개발할 필요가 있습니다. 지속적인 연구와 혁신을 통해 언어 기반 로봇 운영은 실제 응용 분야에서 더 큰 역할을 하고 인간에게 더욱 지능적이고 편리한 서비스를 제공할 것으로 기대됩니다.
이러한 문제를 해결하기 위해 ByteDance Research의 로봇공학 연구팀은 기존 오픈 소스 VLM(Visual Language Model)인 OpenFlamingo를 미세 조정하고 RoboFlamingo라는 새로운 시각적 언어 조작 프레임워크를 설계했습니다. 이 프레임워크의 특징은 VLM을 사용하여 단일 단계의 시각적 언어 이해를 달성하고 추가 정책 헤드 모듈을 통해 기록 정보를 처리한다는 것입니다. 간단한 미세 조정 방법을 통해 RoboFlamingo를 언어 기반 로봇 작동 작업에 적용할 수 있습니다. 이 프레임워크의 도입은 현재 로봇 운영에 존재하는 일련의 문제를 해결할 것으로 기대됩니다.
RoboFlamingo는 언어 기반 로봇 작업 데이터 세트 CALVIN에서 검증되었습니다. 실험 결과 RoboFlamingo는 언어 주석 데이터의 1%만 활용하고 일련의 로봇 작업에서 SOTA 성능(10% 이상)을 달성하는 것으로 나타났습니다. 작업 학습의 작업 순서 성공률은 66%, 평균 작업 완료 횟수는 4.09, 기본 방법은 38%, 평균 작업 완료 횟수는 3.06입니다. %, 평균 작업 완료 횟수는 2.48, 기준 방법은 1%, 평균 작업 완료 횟수는 0.67)이며 개방 루프 제어를 통해 실시간 응답을 달성할 수 있으며 하위 환경에 유연하게 배포할 수 있습니다. 퍼포먼스 플랫폼. 이러한 결과는 RoboFlamingo가 효과적인 로봇 조작 방법이며 향후 로봇 응용 분야에 유용한 참고 자료를 제공할 수 있음을 보여줍니다.
방법
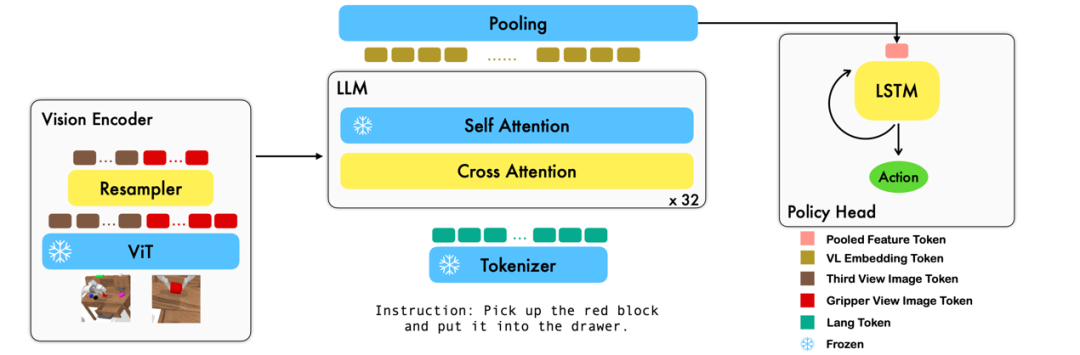
이 작업은 이미지-텍스트 쌍을 기반으로 하는 기존의 시각적 언어 기본 모델을 사용하여 엔드투엔드 방식으로 학습을 통해 로봇의 각 단계의 상대적 동작을 생성합니다. 이 모델은 비전 인코더, 기능 융합 디코더 및 정책 헤드의 세 가지 주요 모듈로 구성됩니다. Vision 인코더 모듈에서는 현재 시각적 관찰이 먼저 ViT에 입력된 다음 ViT에서 출력된 토큰이 리샘플러를 통해 다운샘플링됩니다. 이 단계는 모델의 입력 차원을 줄여 훈련 효율성을 높이는 데 도움이 됩니다. 기능 융합 디코더 모듈은 텍스트 토큰을 입력으로 사용하고 교차 주의 메커니즘을 통해 시각적 인코더의 출력을 쿼리로 사용하여 시각적 기능과 언어 기능의 융합을 달성합니다. 각 계층에서 Feature Fusion Decoder는 먼저 Cross-Attention 연산을 수행한 후 Self-Attention 연산을 수행합니다. 이러한 작업은 언어와 시각적 특징 간의 상관관계를 추출하여 로봇 동작을 더 잘 생성하는 데 도움이 됩니다. 기능 융합 디코더의 현재 및 과거 토큰 시퀀스 출력을 기반으로 정책 헤드는 6차원 로봇 팔 끝 포즈 및 1차원 그리퍼 열기/닫기를 포함하여 현재 7 DoF 관련 동작을 직접 출력합니다. 마지막으로 기능 융합 디코더에서 최대 풀링을 수행하고 이를 정책 헤드로 보내 관련 작업을 생성합니다. 이러한 방식으로 우리 모델은 시각적 정보와 언어적 정보를 효과적으로 융합하여 정확한 로봇 움직임을 생성할 수 있습니다. 이는 로봇 제어 및 자율 항법과 같은 분야에서 광범위한 응용 가능성을 가지고 있습니다.
훈련 과정에서 RoboFlamingo는 사전 훈련된 ViT, LLM 및 Cross Attention 매개변수를 활용하고 리샘플러, 교차 관심 및 정책 헤드의 매개변수만 미세 조정합니다.
실험 결과
데이터 세트:
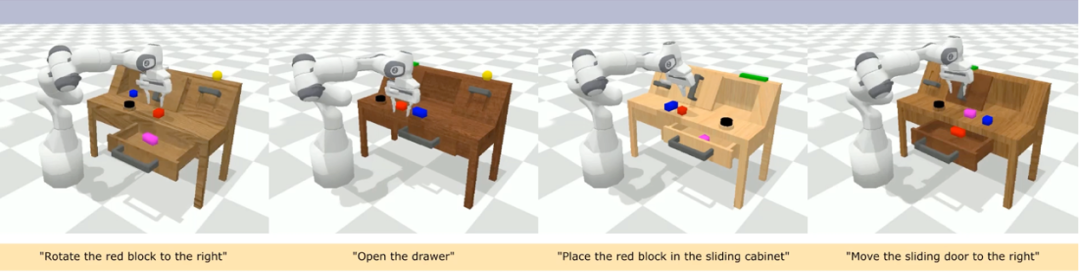
CALVIN(Composing Actions from Language and Vision)은 언어 기반 장거리 작업 작업을 학습하기 위한 오픈 소스 시뮬레이션 벤치마크입니다. 기존의 시각-언어 작업 데이터 세트와 비교하여 CALVIN의 작업은 시퀀스 길이, 동작 공간 및 언어 측면에서 더 복잡하며 센서 입력의 유연한 사양을 지원합니다. CALVIN은 ABCD 4개의 분할로 나누어지며, 각 분할은 서로 다른 컨텍스트와 레이아웃에 해당합니다.
정량 분석:
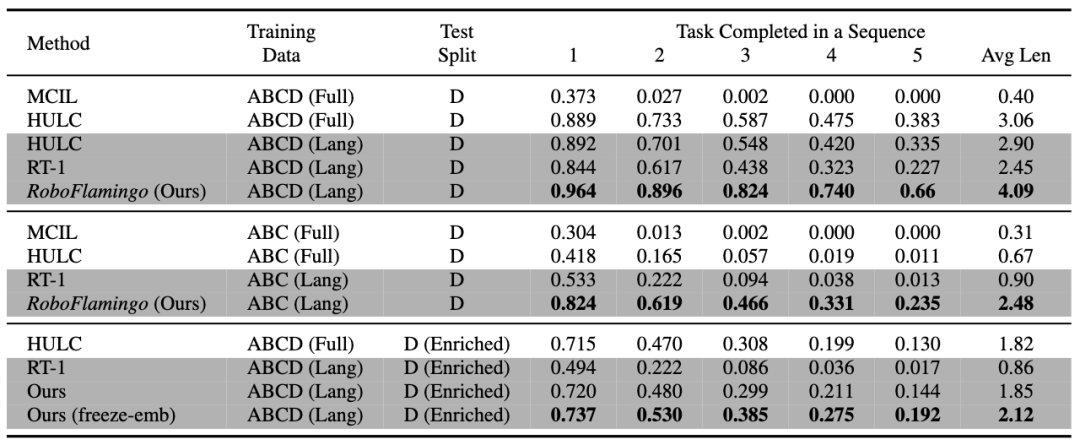
RoboFlamingo는 모든 설정 및 지표에서 최고의 성능을 보여 강력한 모방 능력, 시각적 일반화 능력 및 언어 일반화 능력을 갖추고 있음을 보여줍니다. Full 및 Lang은 모델이 페어링되지 않은 시각적 데이터(즉, 언어 페어링이 없는 시각적 데이터)를 사용하여 훈련되었는지 여부를 나타냅니다.
절제 실험:
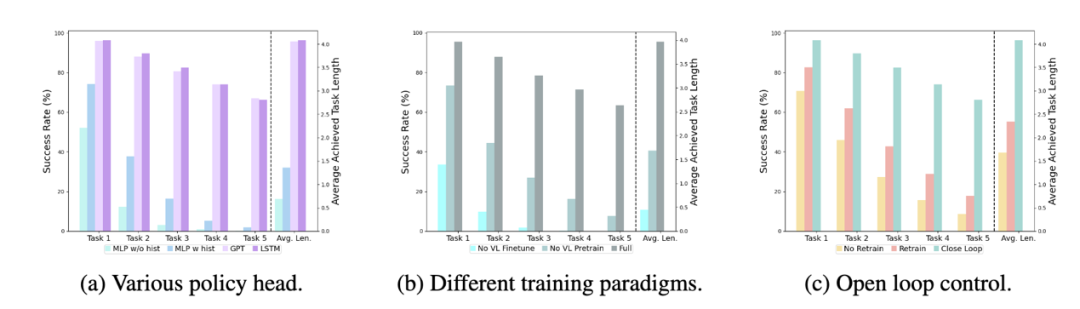
다양한 정책 헤드:
실험에서는 히스트가 없는 MLP, 히스트가 있는 MLP, GPT 및 LSTM의 네 가지 정책 헤드를 조사했습니다. 그 중 히스트가 없는 MLP는 현재 관찰을 기반으로 이력을 직접 예측하며 성능이 가장 나쁩니다. MLP는 비전 인코더 끝에서 이력 관측을 융합하고 동작을 예측하며 성능이 향상됩니다. GPT 및 LSTM 정책수장에서는 각각 역사적 정보를 암묵적으로 유지하고 있으며 그 성과가 가장 좋은 것으로 보아 정책수장을 통한 역사정보 융합의 효율성이 잘 나타나고 있다.
시각 언어 사전 훈련의 영향:
사전 훈련은 RoboFlamingo의 성능을 향상시키는 데 중요한 역할을 합니다. 실험에 따르면 RoboFlamingo는 대규모 시각적 언어 데이터 세트에 대한 사전 교육을 통해 로봇 작업에서 더 나은 성능을 발휘하는 것으로 나타났습니다.
모델 크기 및 성능:
일반적으로 더 큰 모델이 더 나은 성능을 제공하지만, 실험 결과에 따르면 더 작은 모델이라도 일부 작업에서는 큰 모델과 경쟁할 수 있는 것으로 나타났습니다.
명령 미세 조정의 영향:
명령 미세 조정은 강력한 기술이며, 실험 결과에 따르면 모델의 성능을 더욱 향상시킬 수 있는 것으로 나타났습니다.
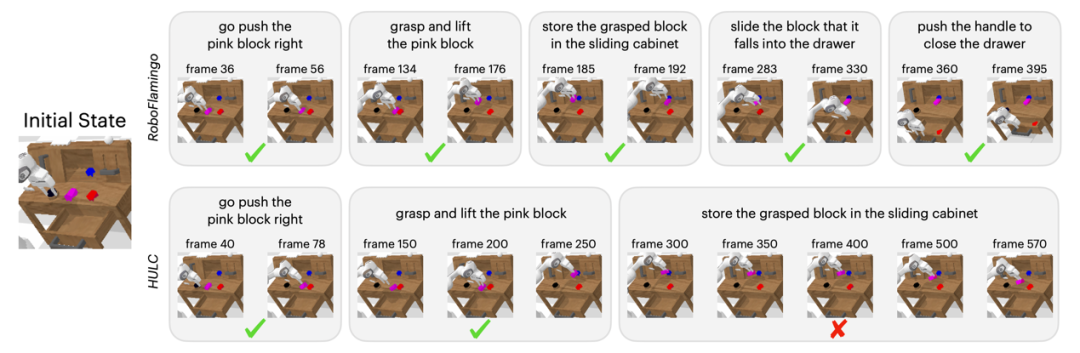
정성적 결과
기본 방법과 비교하여 RoboFlamingo는 5개의 연속 하위 작업을 완전히 실행했을 뿐만 아니라 기준 페이지를 성공적으로 실행한 처음 두 하위 작업에 대해 훨씬 적은 단계를 수행했습니다.
요약
이 작업은 언어 대화형 로봇 운영 전략을 위한 기존 오픈 소스 VLM을 기반으로 하는 새로운 프레임워크를 제공하며, 이는 간단한 미세 조정으로 우수한 결과를 얻을 수 있습니다. RoboFlamingo는 로봇 공학 연구자들에게 오픈 소스 VLM의 잠재력을 더 쉽게 실현할 수 있는 강력한 오픈 소스 프레임워크를 제공합니다. 본 연구에서 얻은 풍부한 실험 결과는 로봇 공학의 실제 적용을 위한 귀중한 경험과 데이터를 제공하고 향후 연구 및 기술 개발에 기여할 수 있습니다.
위 내용은 RoboFlamingo 프레임워크를 통해 오픈 소스 VLM의 잠재력이 극대화됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!