
상업적 이용이 무조건 무료인 세계 최장 오픈소스 모델 XVERSE-Long-256K

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-01-16 21:54:15809검색
Yuanxiang은 컨텍스트 창 길이가 256K인 세계 최초의 오픈 소스 대형 모델 XVERSE-Long-256K를 출시했습니다. 이 모델은 한자 25만자 입력을 지원해 대형 모델 애플리케이션이 '장문 시대'로 진입할 수 있게 해준다. 이 모델은 완전한 오픈 소스이며 아무런 조건 없이 무료로 상업적으로 사용할 수 있습니다. 또한 많은 중소기업, 연구원 및 개발자가 "대규모"를 실현할 수 있도록 하는 자세한 단계별 교육 튜토리얼도 함께 제공됩니다. 모델의 자유'를 앞서 소개했습니다.
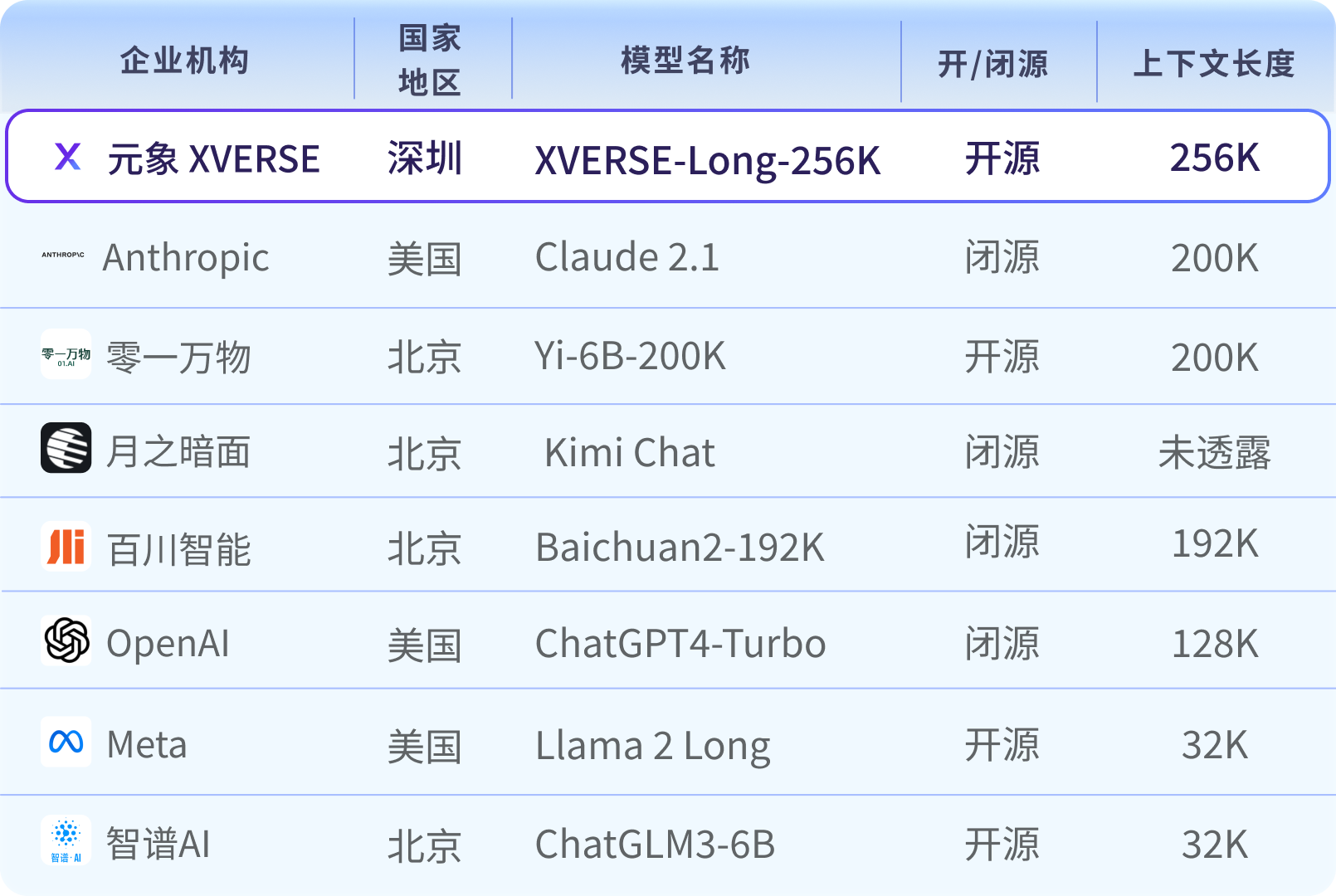 글로벌 주류 긴 텍스트 대형 모델 맵
글로벌 주류 긴 텍스트 대형 모델 맵
매개변수의 양과 고품질 데이터의 양이 대형 모델의 계산 복잡성을 결정하며, 긴 텍스트 기술(Long Context)이 개발의 "킬러"입니다. 신기술로 인해 R&D가 어려운데, 현재 대부분이 유료 비공개 소스를 통해 제공되고 있습니다.
XVERSE-Long-256K는 매우 긴 텍스트 입력을 지원하며 대규모 데이터 분석, 다중 문서 독해 및 도메인 간 지식 통합에 사용할 수 있어 대규모 모델 애플리케이션의 깊이와 폭을 효과적으로 향상시킵니다. 변호사, 재무 분석가 또는 컨설턴트의 경우 교사, 신속한 엔지니어, 과학 연구원 등이 긴 텍스트를 분석하고 처리하는 작업을 해결할 수 있습니다. 2. 롤플레잉 또는 채팅 애플리케이션에서 모델의 "망각" 문제를 완화할 수 있습니다. 이전 대화 또는 넌센스의 "환각" 문제 3. 과거 정보를 기반으로 한 계획 및 의사 결정에서 AI 에이전트를 더 효과적으로 지원합니다. 4. AI 기본 애플리케이션이 일관되고 개인화된 사용자 경험을 유지하도록 지원합니다.
지금까지 XVERSE-Long-256K는 오픈 소스 생태계의 공백을 메웠으며 Yuanxiang의 이전 70억, 130억, 650억 매개변수 대형 모델과 함께 "고성능 패밀리 버킷"을 형성하여 국내 오픈소스를 세계 최고 수준으로 끌어올렸습니다. 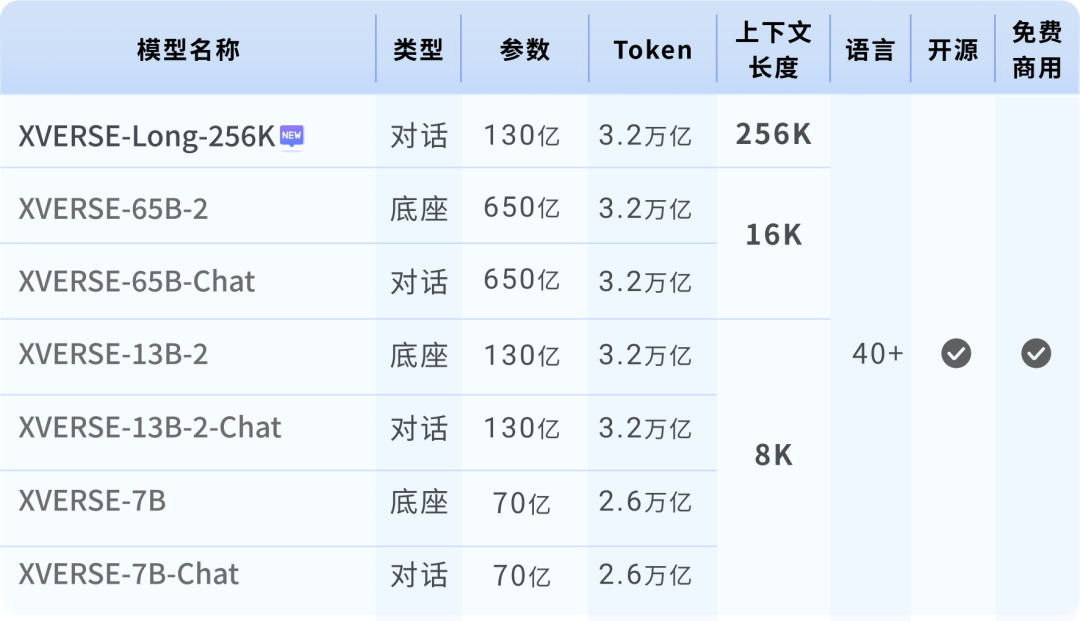 Yuanxiang 대형 모델 시리즈
Yuanxiang 대형 모델 시리즈
Yuanxiang 대형 모델 무료 다운로드
- GitHub: https://github.com/xverse-ai/XVERSE-13B
- 껴안는 얼굴: https://huggingface.co/ xverse / chat.xverse.cn) 또는 미니프로그램으로 XVERSE-Long-256K를 바로 체험해 보실 수 있습니다.
- 고성능 포지셔닝
- 우수한 평가 성과
업계가 Yuanxiang 대형 모델에 대해 포괄적이고 객관적이며 장기적인 이해를 갖출 수 있도록 연구진은 권위 있는 업계 평가를 참고하여 9개 항목의 종합 보고서를 개발했습니다. 6차원 평가 시스템. XVERSE-Long-256K는 모두 잘 수행되어 다른 긴 텍스트 모델보다 성능이 뛰어납니다.
글로벌 주류 긴 텍스트 오픈 소스 대형 모델 평가 결과 XVERSE-Long-256K는 일반적인 긴 텍스트 대형 모델 성능 스트레스 테스트인 "건초 더미에서 바늘 찾기"를 통과했습니다. 이 테스트는 내용과 관련이 없는 긴 텍스트 코퍼스에 문장을 숨기고, 자연어 질문을 사용하여 대형 모델이 문장을 정확하게 추출할 수 있도록 합니다.
Novel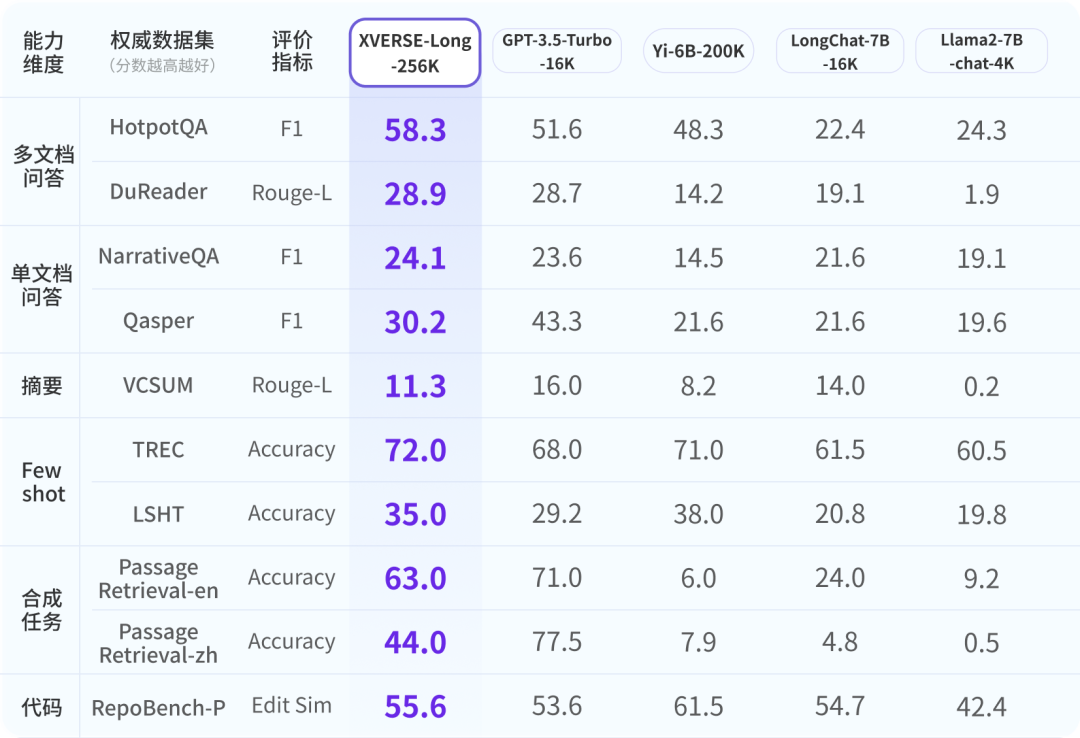
독해
현재 중국의 대부분의 대규모 모델은 중국어와 영어 이중 언어만 지원하지만 Yuanxiang은 40개 이상의 언어를 지원합니다. 16만 자의 러시아 고전소설 『강철은 어떻게 단련되었나』와 41만 자의 독일 역사전기 『인류의 별이 빛날 때』를 테스트했다. "How Steel Was Tempered(러시아어 버전)" 테스트
"When Human Stars Shine(독일어 버전)" 테스트법률 및 규정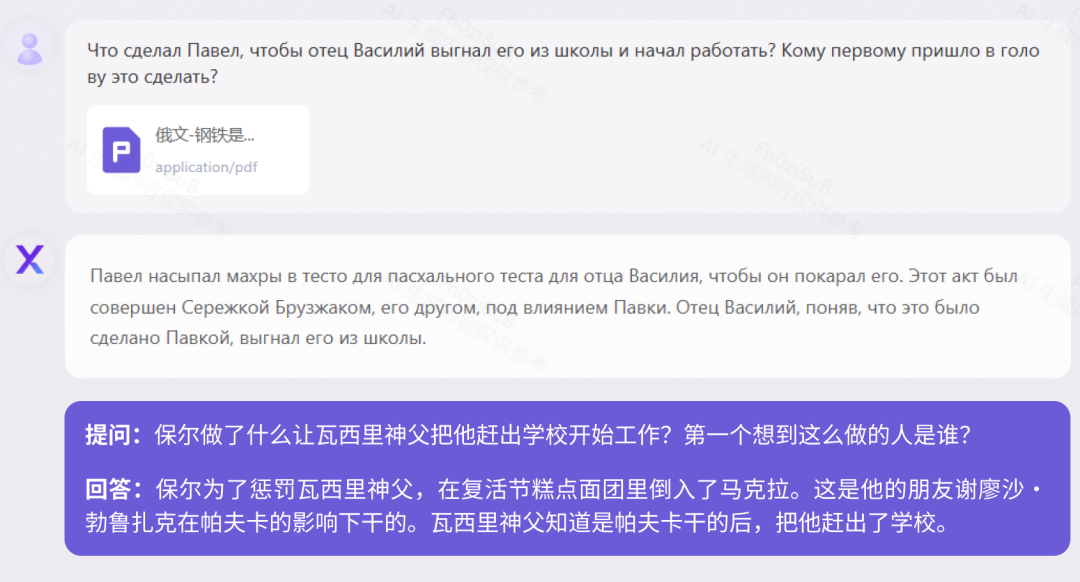
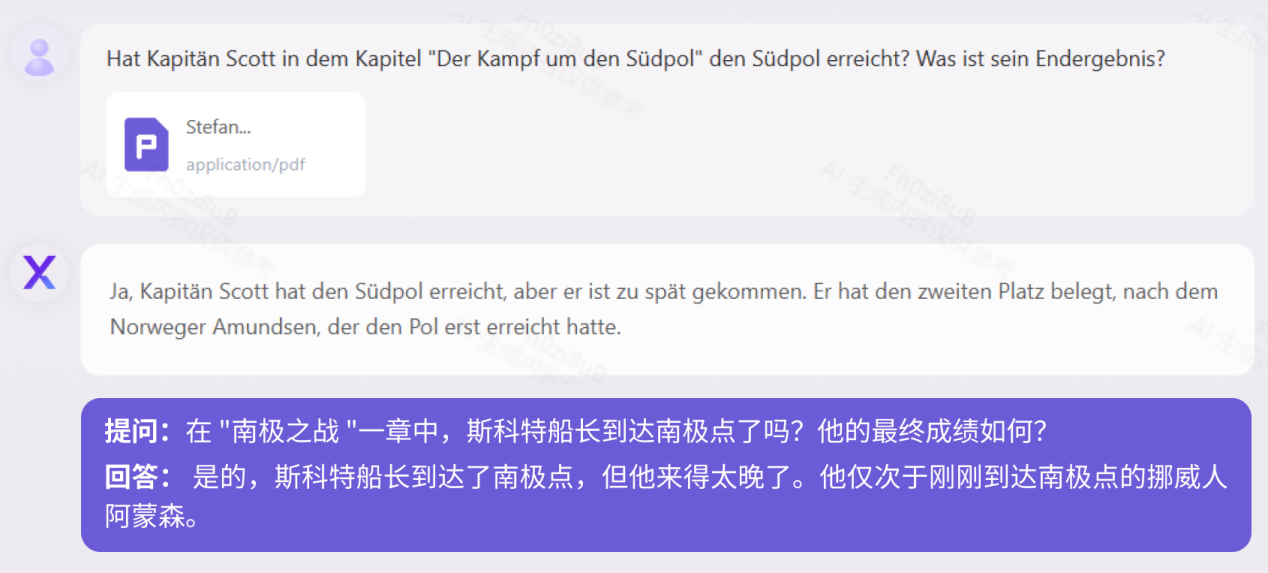
정확한 적용
중화인민공화국 법전을 예로 들어 법률 용어 설명, 사건의 논리적 분석, 현실과 결합된 유연한 적용을 보여줍니다. "민법" 테스트
단계적으로 가르쳐주세요. 긴 텍스트 대형 모델 훈련 방법 


기술적 과제
- 모델 훈련: GPU 메모리 사용량은 시퀀스 길이의 제곱에 비례하므로 훈련량이 급격히 증가합니다.
- 모델 구조: 시퀀스가 길어질수록 모델의 주의가 더 분산되고 모델이 이전 내용을 잊어버리기 쉬워집니다.
- 추론 속도: 모델 시퀀스가 길어질수록 모델 추론 속도가 느려집니다.
2. Yuanxiang 기술 경로
긴 텍스트 대형 모델 기술은 작년에 개발된 새로운 기술입니다. 주요 기술 솔루션은 다음과 같습니다.
- 긴 시퀀스를 직접 사전 훈련하지만 이로 인해 훈련이 발생합니다. 부피는 2차적으로 증가합니다.
- 위치 인코딩의 보간 또는 외삽을 통해 시퀀스 길이를 확장합니다. 이 방법은 위치 인코딩의 해상도를 줄여 대형 모델의 출력 효과를 줄입니다.
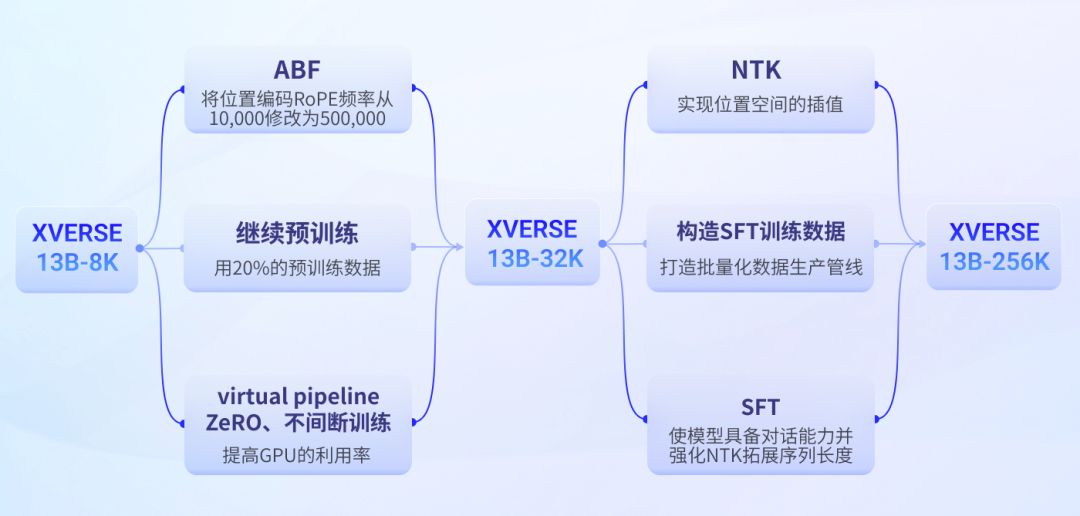
Yuanxiang 긴 텍스트 대형 모델 훈련 과정
첫 번째 단계: ABF+사전 훈련 계속하기
- GitHub: https://github.com/xverse-ai/XVERSE-13B
- 껴안는 얼굴: https://huggingface.co/xverse/XVERSE-13B-256K
- 매직 매치: https://modelscope.cn/models/xverse/XVERSE-13B-256K
- 문의는 오픈소스로 보내주세요. @xverse.cn
위 내용은 상업적 이용이 무조건 무료인 세계 최장 오픈소스 모델 XVERSE-Long-256K의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!