
Meta는 캐릭터 대화 장면의 더빙을 생성하기 위한 오디오-이미지 AI 프레임워크를 출시합니다.

- PHPz앞으로
- 2024-01-13 11:39:061058검색
IT House News 1월 9일 Meta는 최근 audio2photoreal이라는 AI 프레임워크를 발표했습니다. 이 프레임워크는 일련의 현실적인 NPC 캐릭터 모델을 생성하고 기존 더빙 파일의 도움으로 캐릭터 모델을 자동으로 "립싱크"할 수 있습니다.


▲ 이미지 출처 메타리서치 리포트 (아래동일)
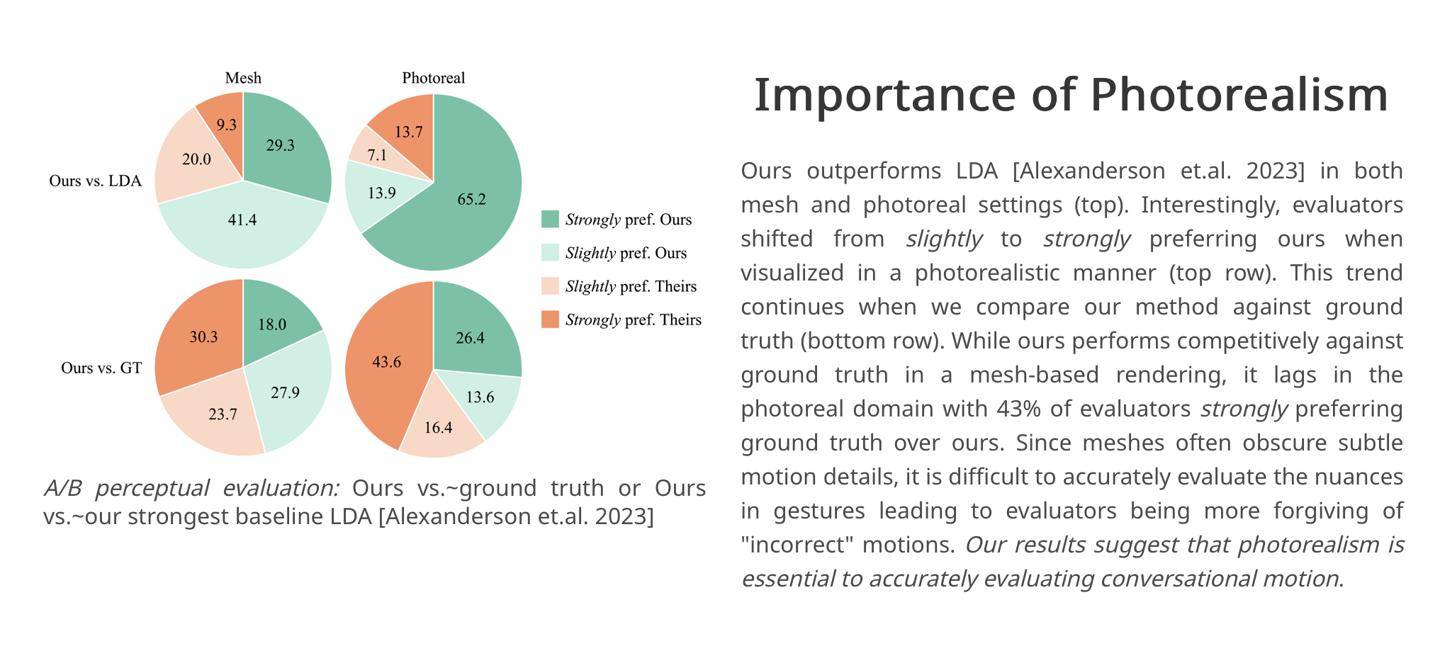
IT House는 공식 연구 보고서를 통해 Audio2photoreal 프레임워크가 먼저 일련의 NPC 모델을 생성한 다음 양자화 기술과 확산 알고리즘을 사용하여 모델 동작을 생성한다는 사실을 알게 되었습니다. 프레임에 의해 생성된 캐릭터 모션 효과를 향상시키기 위해 확산 알고리즘이 사용됩니다.
연구원들은 이 프레임워크가 30FPS에서 "고품질 동작 샘플"을 생성할 수 있으며 대화 중에 "손가락 가리키기", "손목 돌리기" 또는 "어깨를 으쓱하기"와 같은 인간의 비자발적인 "습관적인 동작"을 시뮬레이션할 수도 있다고 언급했습니다.


연구원들은 통제된 실험에서 평가자의 43%가 프레임워크에 의해 생성된 캐릭터 대화 장면에 "매우 만족"했습니다. 따라서 연구원들은 Audio2photoreal 프레임워크가 "더 역동적이고 표현력이 풍부한" 결과를 생성할 수 있다고 믿습니다. "업계 경쟁 제품과 비교. 포스" 액션.
이제 연구팀이 GitHub에 관련 코드와 데이터 세트를 공개한 것으로 알려졌습니다. 관심 있는 파트너는 여기를 클릭하여 액세스할 수 있습니다.
위 내용은 Meta는 캐릭터 대화 장면의 더빙을 생성하기 위한 오디오-이미지 AI 프레임워크를 출시합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!