최근에는 Transformer의 수학적 원리에 대한 새로운 해석을 제공하는 논문이 arxiv에 발표되었습니다. 내용이 매우 길고, 원문을 읽어 보시기를 적극 권장합니다.
2017년 Vaswani 등이 출판한 "Attention is all you need"는 신경망 아키텍처 개발에 중요한 이정표가 되었습니다. 본 논문의 핵심 기여는 Transformers를 기존 아키텍처와 구별하는 혁신이며 우수한 실제 성능에 중요한 역할을 하는 self-attention 메커니즘입니다. 실제로 이러한 혁신은 컴퓨터 비전, 자연어 처리 등의 분야에서 인공 지능 발전의 핵심 촉매제가 되었으며, 대규모 언어 모델의 출현에도 핵심적인 역할을 했습니다. 따라서 Transformers, 특히 self-attention이 데이터를 처리하는 메커니즘을 이해하는 것은 중요하지만 대체로 충분히 연구되지 않은 영역입니다. 
문서 주소: https://arxiv.org/pdf/2312.10794.pdf심층 신경망(DNN)에는 공통 기능이 있습니다. 즉, 입력 데이터가 순서대로 계층별로 처리되어 시간 이산 동적 시스템(구체적인 내용은 MIT에서 출판한 "Deep Learning"(중국에서는 "Flower Book"이라고도 함)을 참조하십시오.) 이 관점은 신경 상미분 방정식(신경 ODE)이라고 불리는 시간 연속 동적 시스템에 잔차 네트워크를 모델링하는 데 성공적으로 사용되었습니다. 신 상수 미분 방정식에서 입력 이미지 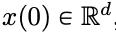 는 시간 간격(0, T)에 걸쳐 주어진 시변 속도 장
는 시간 간격(0, T)에 걸쳐 주어진 시변 속도 장 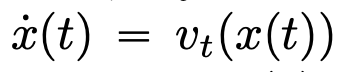 에 따라 진화합니다. 따라서 DNN은 하나의
에 따라 진화합니다. 따라서 DNN은 하나의 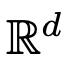 에서 다른
에서 다른  으로의 흐름 맵
으로의 흐름 맵 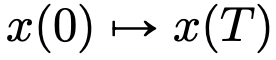 으로 볼 수 있습니다. 고전적인 DNN 아키텍처의 제약에 따라 속도 필드
으로 볼 수 있습니다. 고전적인 DNN 아키텍처의 제약에 따라 속도 필드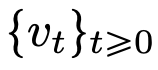 에서도 흐름 맵 간에는 강한 유사성이 있습니다. 연구원들은 Transformer가 실제로
에서도 흐름 맵 간에는 강한 유사성이 있습니다. 연구원들은 Transformer가 실제로 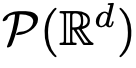 의 흐름 매핑, 즉 d차원 확률 측정 공간(확률 측정 공간) 간의 매핑임을 발견했습니다. 미터법 공간 간을 변환하는 흐름 매핑을 구현하려면 변환기는 평균 필드 상호 작용 입자 시스템을 설정해야 합니다. 구체적으로 각 입자(딥러닝의 맥락에서 토큰으로 이해될 수 있음)는 벡터장의 흐름을 따르며 흐름은 모든 입자의 경험적 척도에 따라 달라집니다. 결과적으로 방정식은 오랫동안 지속될 수 있고 지속적인 주의가 필요한 프로세스인 입자의 경험적 측정의 진화를 결정합니다. 연구원들의 주요 관찰은 입자가 결국 서로 뭉치는 경향이 있다는 것입니다. 이 현상은 단방향 파생(즉, 시퀀스의 다음 단어 예측)과 같은 학습 작업에서 특히 두드러집니다. 출력 메트릭은 다음 토큰의 확률 분포를 인코딩하며, 클러스터링 결과를 기반으로 소수의 가능한 결과를 필터링할 수 있습니다. 이 기사의 연구 결과는 극한 분포가 실제로 점 질량이며 다양성이나 임의성이 없음을 보여 주지만 이는 실제 관찰 결과와 일치하지 않습니다. 이 명백한 역설은 입자가 오랜 기간 동안 다양한 상태로 존재한다는 사실로 해결됩니다. 그림 2와 그림 4에서 볼 수 있듯이 Transformer에는 두 가지 다른 시간 척도가 있습니다. 첫 번째 단계에서는 모든 토큰이 여러 클러스터를 빠르게 형성하는 반면, 두 번째 단계(첫 번째 단계보다 훨씬 느림)에서는 쌍 단위 병합 프로세스가 진행됩니다. 클러스터의 모든 토큰은 결국 한 지점으로 축소됩니다.
의 흐름 매핑, 즉 d차원 확률 측정 공간(확률 측정 공간) 간의 매핑임을 발견했습니다. 미터법 공간 간을 변환하는 흐름 매핑을 구현하려면 변환기는 평균 필드 상호 작용 입자 시스템을 설정해야 합니다. 구체적으로 각 입자(딥러닝의 맥락에서 토큰으로 이해될 수 있음)는 벡터장의 흐름을 따르며 흐름은 모든 입자의 경험적 척도에 따라 달라집니다. 결과적으로 방정식은 오랫동안 지속될 수 있고 지속적인 주의가 필요한 프로세스인 입자의 경험적 측정의 진화를 결정합니다. 연구원들의 주요 관찰은 입자가 결국 서로 뭉치는 경향이 있다는 것입니다. 이 현상은 단방향 파생(즉, 시퀀스의 다음 단어 예측)과 같은 학습 작업에서 특히 두드러집니다. 출력 메트릭은 다음 토큰의 확률 분포를 인코딩하며, 클러스터링 결과를 기반으로 소수의 가능한 결과를 필터링할 수 있습니다. 이 기사의 연구 결과는 극한 분포가 실제로 점 질량이며 다양성이나 임의성이 없음을 보여 주지만 이는 실제 관찰 결과와 일치하지 않습니다. 이 명백한 역설은 입자가 오랜 기간 동안 다양한 상태로 존재한다는 사실로 해결됩니다. 그림 2와 그림 4에서 볼 수 있듯이 Transformer에는 두 가지 다른 시간 척도가 있습니다. 첫 번째 단계에서는 모든 토큰이 여러 클러스터를 빠르게 형성하는 반면, 두 번째 단계(첫 번째 단계보다 훨씬 느림)에서는 쌍 단위 병합 프로세스가 진행됩니다. 클러스터의 모든 토큰은 결국 한 지점으로 축소됩니다. 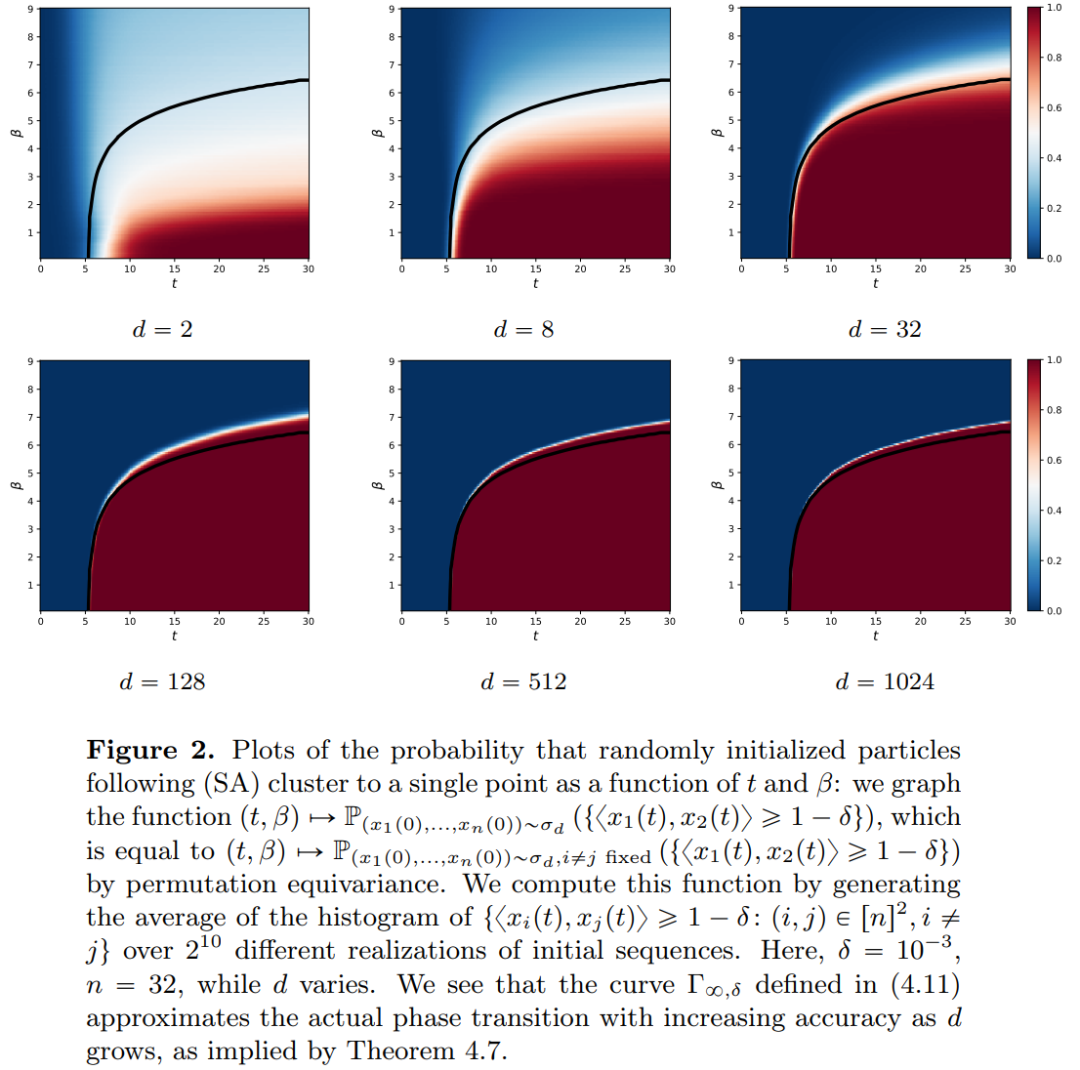
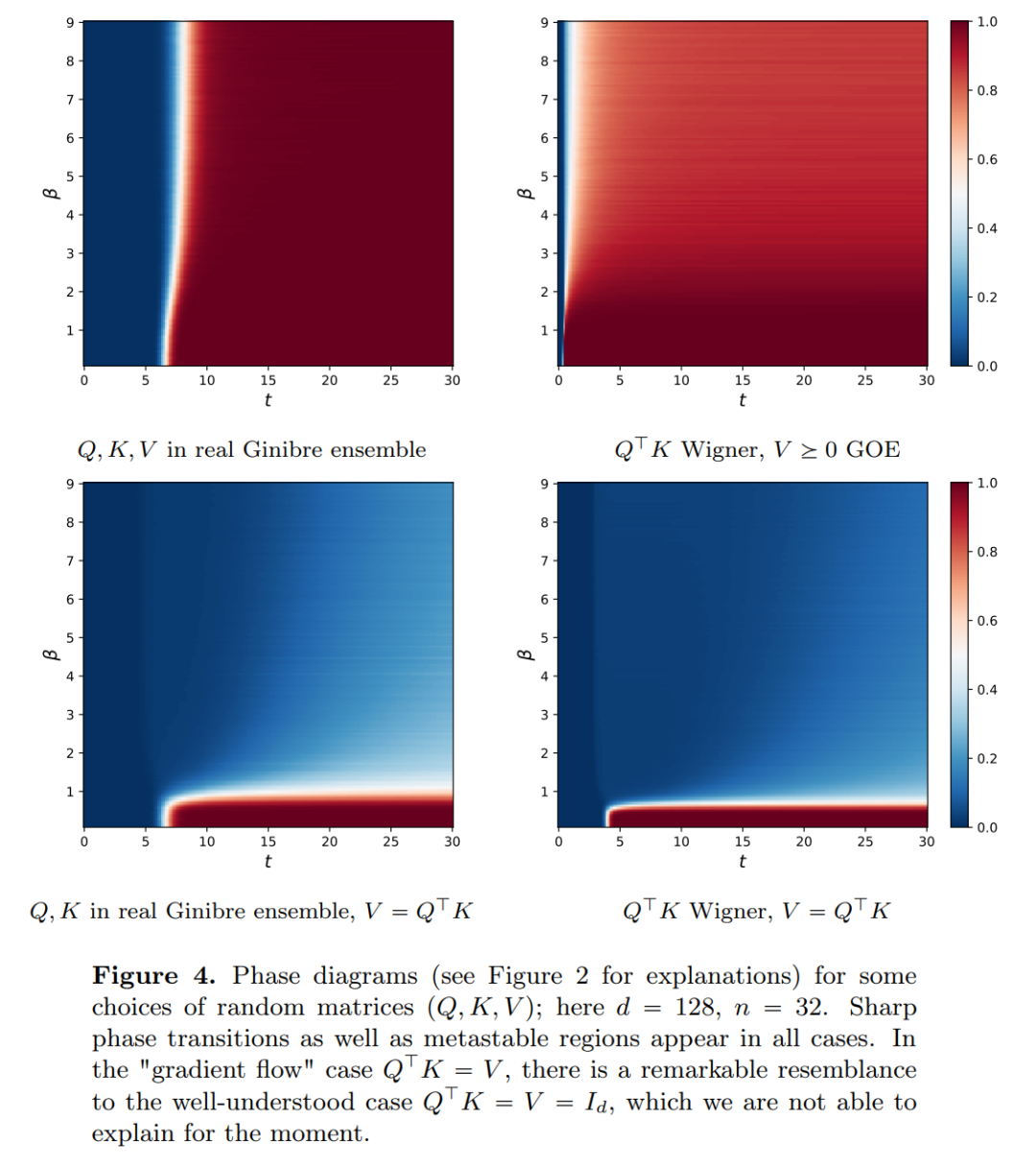
이 글의 목적은 두 가지입니다. 한편으로, 이 글은 수학적 관점에서 트랜스포머를 연구하기 위한 일반적이고 이해하기 쉬운 프레임워크를 제공하는 것을 목표로 합니다. 특히, 이러한 상호 작용하는 입자 시스템의 구조를 통해 연구자들은 비선형 전송 방정식, Wasserstein 경사 흐름, 집단 행동 모델 및 구 위 점의 최적 구성을 포함하여 수학에서 확립된 주제에 구체적으로 연결할 수 있습니다. 한편, 이 논문에서는 장기간에 걸쳐 현상을 클러스터링하는 데 특별히 초점을 맞춘 몇 가지 유망한 연구 방향을 설명합니다. 연구자들이 제안한 주요 결과 측정은 새로운 것이며, 논문 전체에서 흥미롭다고 생각되는 공개 질문을 제기하기도 합니다. 이 기사의 주요 내용은 세 부분으로 나뉩니다. 
1부: 모델링. 이 기사에서는 레이어 수를 연속시간 변수로 처리하는 Transformer 아키텍처의 이상적인 모델을 정의합니다. 추상화에 대한 이러한 접근 방식은 새로운 것이 아니며 ResNets와 같은 클래식 아키텍처에서 사용하는 접근 방식과 유사합니다. 이 기사의 모델은 Transformer 아키텍처의 두 가지 주요 구성 요소인 self-attention 메커니즘과 레이어 정규화에만 중점을 둡니다. 레이어 정규화는 입자를 단위 구의 공간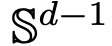 에 효과적으로 제한하는 반면, Self-Attention 메커니즘은 경험적 측정을 통해 입자 간의 비선형 결합을 달성합니다. 결과적으로, 경험적 측정은 연속성 편미분 방정식에 따라 전개됩니다. 이 기사에서는 또한 self-attention을 위한 더 간단하고 사용하기 쉬운 대체 모델인 에너지 함수의 Wasserstein 경사 흐름을 소개하며, 에너지 함수 영역에서 점의 최적 구성을 위한 성숙한 연구 방법이 이미 있습니다. 2부: 클러스터링. 이 부분에서 연구원들은 장기간에 걸쳐 토큰 클러스터링에 대한 새로운 수학적 결과를 제안합니다. 정리 4.1에서 볼 수 있듯이 고차원 공간에서는 단위 공에 무작위로 초기화된 n개의 입자 그룹이
에 효과적으로 제한하는 반면, Self-Attention 메커니즘은 경험적 측정을 통해 입자 간의 비선형 결합을 달성합니다. 결과적으로, 경험적 측정은 연속성 편미분 방정식에 따라 전개됩니다. 이 기사에서는 또한 self-attention을 위한 더 간단하고 사용하기 쉬운 대체 모델인 에너지 함수의 Wasserstein 경사 흐름을 소개하며, 에너지 함수 영역에서 점의 최적 구성을 위한 성숙한 연구 방법이 이미 있습니다. 2부: 클러스터링. 이 부분에서 연구원들은 장기간에 걸쳐 토큰 클러스터링에 대한 새로운 수학적 결과를 제안합니다. 정리 4.1에서 볼 수 있듯이 고차원 공간에서는 단위 공에 무작위로 초기화된 n개의 입자 그룹이  의 한 점으로 모일 것입니다. 입자 클러스터의 수축률에 대한 연구원의 정확한 설명은 이 결과를 보완합니다. 구체적으로 연구자들은 모든 입자 사이의 거리와 모든 입자가 클러스터링을 완료하려고 하는 시점에 대한 히스토그램을 그렸습니다(원본 기사의 섹션 4 참조). 연구자들은 또한 큰 차원 d를 가정하지 않고 클러스터링 결과를 얻었습니다(원본 기사의 섹션 5 참조). 3부: 앞을 내다봅니다. 본 논문은 주로 개방형 질문 형태로 질문을 제기하고 수치적 관찰을 통해 이를 입증함으로써 향후 연구의 잠재적인 노선을 제안합니다. 연구자들은 먼저 차원 d = 2의 경우에 초점을 맞추고(원문 기사의 섹션 6 참조) Kuramoto 발진기와의 연관성을 끌어냈습니다. 그런 다음 모델을 간단하고 자연스럽게 수정하여 구면 최적화와 관련된 어려운 문제를 어떻게 해결할 수 있는지 간략하게 보여줍니다(원본 기사의 섹션 7 참조). 다음 장에서는 Transformer 아키텍처의 매개변수를 조정하여 나중에 실제 응용할 수 있도록 하는 상호 작용 입자 시스템을 살펴봅니다.
의 한 점으로 모일 것입니다. 입자 클러스터의 수축률에 대한 연구원의 정확한 설명은 이 결과를 보완합니다. 구체적으로 연구자들은 모든 입자 사이의 거리와 모든 입자가 클러스터링을 완료하려고 하는 시점에 대한 히스토그램을 그렸습니다(원본 기사의 섹션 4 참조). 연구자들은 또한 큰 차원 d를 가정하지 않고 클러스터링 결과를 얻었습니다(원본 기사의 섹션 5 참조). 3부: 앞을 내다봅니다. 본 논문은 주로 개방형 질문 형태로 질문을 제기하고 수치적 관찰을 통해 이를 입증함으로써 향후 연구의 잠재적인 노선을 제안합니다. 연구자들은 먼저 차원 d = 2의 경우에 초점을 맞추고(원문 기사의 섹션 6 참조) Kuramoto 발진기와의 연관성을 끌어냈습니다. 그런 다음 모델을 간단하고 자연스럽게 수정하여 구면 최적화와 관련된 어려운 문제를 어떻게 해결할 수 있는지 간략하게 보여줍니다(원본 기사의 섹션 7 참조). 다음 장에서는 Transformer 아키텍처의 매개변수를 조정하여 나중에 실제 응용할 수 있도록 하는 상호 작용 입자 시스템을 살펴봅니다. 위 내용은 새로운 버전 공개: 지금까지 본 적 없는 Transformer의 수학적 원리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


 으로의 흐름 맵
으로의 흐름 맵