지난해 DreamFusion은 3D 정적 개체 및 장면 생성이라는 새로운 트렌드를 주도하여 생성 기술 분야에서 광범위한 관심을 끌었습니다. 지난 한 해를 되돌아보면 우리는 3D 정적 생성 기술의 품질 및 제어 측면에서 상당한 발전을 목격했습니다. 기술 개발은 텍스트 기반 생성에서 시작되어 점차 싱글 뷰 이미지로 통합되고, 이후 여러 제어 신호를 통합하는 방향으로 발전했습니다. 이에 비해 3D 다이나믹 장면 생성은 아직 초기 단계입니다. 2023년 초 Meta는 MAV3D를 출시하여 텍스트 기반 3D 동영상 생성을 최초로 시도했습니다. 그러나 오픈 소스 비디오 생성 모델의 부족으로 인해 이 분야의 발전은 상대적으로 느렸습니다. 그런데 이제 그래픽과 텍스트의 결합을 기반으로 한 3D 영상 생성 기술이 공개됐습니다! 텍스트 기반 3D 영상 생성은 다양한 콘텐츠 제작이 가능하지만, 사물의 디테일과 포즈를 제어하는 데에는 여전히 한계가 있습니다. 3D 정적 생성 분야에서는 단일 이미지를 입력으로 사용하여 3D 객체를 효과적으로 재구성할 수 있습니다. 이에 영감을 받아 싱가포르국립대학교(NUS)와 Huawei 연구팀이 Animate124 모델을 제안했습니다. 이 모델은 단일 이미지와 해당 동작 설명을 결합하여 3D 비디오 생성을 정밀하게 제어할 수 있습니다. 
- 프로젝트 홈페이지: https://animate124.github.io/
- 논문 주소: https://arxiv.org/abs/2311.14603
- 코드: https://github. com/HeliosZhao/Animate124

에 따라 이 문서는 다음과 같이 나뉩니다. 3D 영상 생성을 3단계로 나누어 : 1) 정적 생성 단계: Vincentian 그래프 및 3D 그래프 그래프 확산 모델을 사용하여 단일 이미지에서 3D 개체를 생성합니다. 2) 동적 대략 생성 단계: Vincentian 비디오 모델을 사용하여 언어 설명에 따라 동작을 최적화합니다. 또한, 외모에 대한 2단계 언어 설명으로 인한 편차를 최적화하고 개선하기 위해 개인화된 미세 조정 ControlNet을 사용합니다. ㅋㅋㅋ 0-1 대 3 ) 그림을 기반으로 정적 개체 생성:
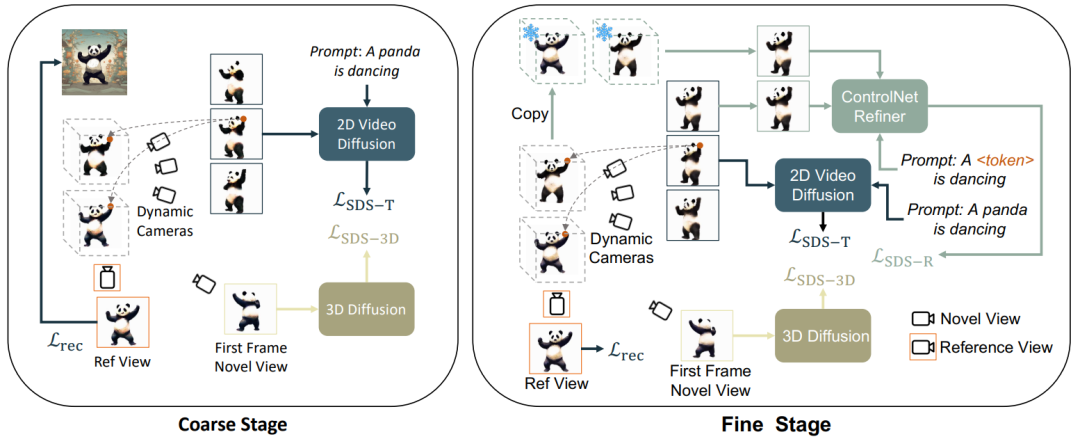
조건부 그림에 해당하는 관점의 경우 최적화를 위해 손실 함수를 추가로 사용합니다. 위의 두 가지 최적화 목표를 통해 여러 관점을 얻습니다. 3D 일관된 정적 객체(이 단계는 프레임 다이어그램에서 생략됨)
동적 러프 생성
이 단계에서는 정적 3D를 초기 프레임으로 처리하고 언어 설명을 기반으로 액션을 생성하는 Vinson 비디오 확산 모델
을 주로 사용합니다. 특히 동적 3D 모델(동적 NeRF)은 연속 타임스탬프가 있는 다중 프레임 비디오를 렌더링하고 이 비디오를 Vincent 비디오 확산 모델에 입력하며 SDS 증류 손실을 사용하여 동적 3D 모델을 최적화합니다. 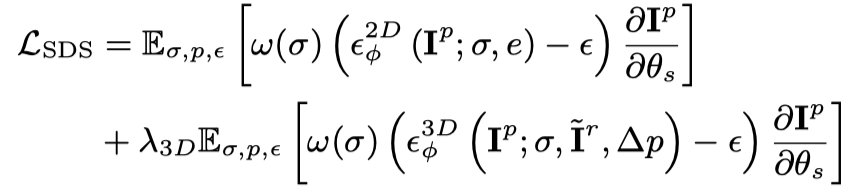
Vincent만 사용 video 증류 손실로 인해 3D 모델이 사진의 내용을 잊어버리게 되며, 무작위 샘플링으로 인해 동영상의 초기 및 최종 단계에서 훈련이 충분하지 않게 됩니다. 따라서 이 문서의 연구자들은 시작 및 종료 타임스탬프를 오버샘플링했습니다. 그리고 초기 프레임을 샘플링할 때 최적화를 위해 추가 정적 함수가 사용됩니다(3D 그래프의 SDS 증류 손실): 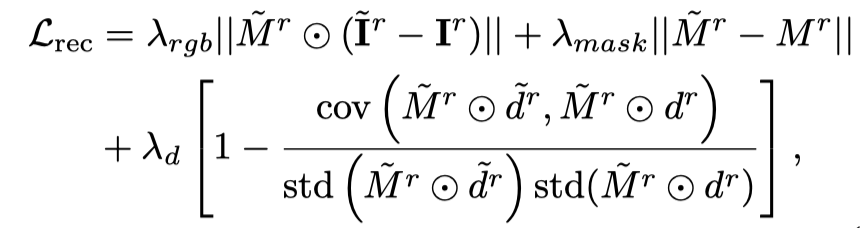
따라서 이 단계의 손실 함수는 다음과 같습니다. 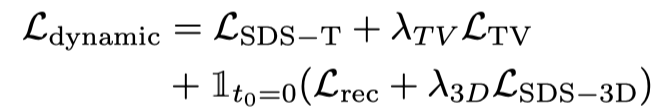
초기 프레임 오버샘플링 및 추가 감독이 있어도 Vincent 비디오 확산 모델을 사용한 최적화 프로세스 중에 객체의 모양은 여전히 참조 이미지를 오프셋하는 텍스트의 영향을 받습니다. 따라서 본 논문에서는 개인화 모델을 통해 의미 오프셋을 개선하기 위한 의미 최적화 단계를 제안한다. 사진이 한 장뿐이므로 Vincent 비디오 모델은 개인화될 수 없습니다. 이 기사에서는 이미지와 텍스트를 기반으로 한 확산 모델을 소개하고 이 확산 모델에 대해 개인화된 미세 조정을 수행합니다. 이 확산 모델은 원본 비디오의 내용과 동작을 변경해서는 안 되며, 모양만 조정해야 합니다. 따라서 본 논문에서는 ControlNet-Tile 그래픽 모델을 채택하고, 이전 단계에서 생성된 비디오 프레임을 조건으로 사용하여 언어에 따라 최적화한다. ControlNet은 Stable Diffusion 모델을 기반으로 하며 참조 이미지에서 의미 정보를 추출하려면 Stable Diffusion에 대해 개인화된 미세 조정(Textual Inversion)만 수행하면 됩니다. 개인화된 미세 조정 후 비디오를 다중 프레임 이미지로 처리하고 ControlNet을 사용하여 단일 이미지를 감독합니다. 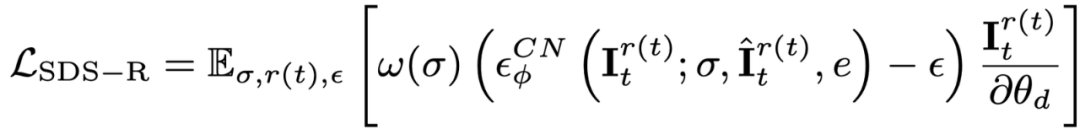
또한 ControlNet은 거친 이미지를 조건으로 사용하기 때문에 CFG(분류 없는 안내)를 사용할 수 있습니다. Vincentian 그래프 및 Vincentian 비디오 모델과 같이 매우 큰 값(보통 100)을 사용하는 대신 정상 범위(왼쪽 및 오른쪽 10)를 사용합니다. 지나치게 큰 CFG는 이미지 과포화를 유발하므로 ControlNet 확산 모델을 사용하면 과포화 현상을 완화하고 더 나은 생성 결과를 얻을 수 있습니다. 이 단계의 감독은 동적 스테이지 손실과 ControlNet 감독으로 결합됩니다. 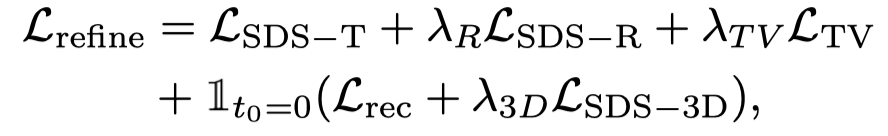
최초의 이미지 텍스트 기반 3D 비디오 생성 모델로서 이 기사는 두 가지 기준과 비교됩니다. 모델과 MAV3D를 비교했습니다. Animate124는 다른 방법에 비해 더 나은 결과를 제공합니다. 
그림 2. 두 기준선과 비교한 Animate124

그림 3.1. Animate124와 MAV3D 그래픽 3D 비디오 비교 이 기사에서는 CLIP 및 수동 평가를 사용하여 품질을 생성합니다. 평가 정확성, 이미지와의 유사성, 시간적 일관성. 수동 평가 지표에는 텍스트 유사성, 그림 유사성, 비디오 품질, 움직임의 사실성 및 움직임 진폭이 포함됩니다. 수동 평가는 해당 측정 항목에 대한 Animate124의 선택에 대한 단일 모델의 비율로 표시됩니다. 두 가지 기본 모델과 비교하여 Animate124는 CLIP 및 수동 평가 모두에서 더 나은 결과를 얻습니다. 
표 1. Animate124와 두 기준선의 정량적 비교Animate124는 최초로 모든 이미지를 텍스트 설명 영상 방식을 기반으로 한 3D. 감독 및 안내를 위해 다중 확산 모델을 사용하여 4D 동적 표현 네트워크를 최적화하여 고품질 3D 비디오를 생성합니다. 위 내용은 사진과 동작 명령만으로 Animate124는 쉽게 3D 비디오를 생성할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

