


대형 모델의 뛰어난 성능은 누구나 다 아는 사실이며, 이를 로봇에 접목하게 된다면 로봇은 더욱 지능적인 두뇌를 가지게 되어 자율주행, 홈로봇, 산업용 로봇 등 로봇공학 분야에 새로운 가능성을 가져올 것으로 기대됩니다. 로봇, 보조 로봇, 의료 로봇, 필드 로봇 및 멀티 로봇 시스템.
사전 훈련된 LLM(대형 언어 모델), VLM(대형 시각 언어 모델), ALM(대형 오디오 언어 모델) 및 VNM(대형 시각적 탐색 모델)을 사용하여 로봇 공학 분야의 다양한 문제를 더 잘 처리할 수 있습니다. 일. 기본 모델을 로봇공학에 통합하는 것은 빠르게 성장하는 분야이며, 로봇공학 커뮤니티는 최근 다시 작성해야 하는 로봇공학 분야(인식, 예측, 계획 및 제어)에서 이러한 대형 모델의 사용을 탐색하기 시작했습니다.
최근 스탠포드대, 프린스턴대, 엔비디아, 구글 딥마인드 등으로 구성된 공동 연구팀은 로봇 연구 분야 기본 모델의 개발과 향후 과제를 요약한 리뷰 보고서를 발표했습니다

Paper 주소: https://arxiv.org/pdf/2312.07843.pdf
재작성된 내용은 다음과 같습니다. 종이 라이브러리: https://github.com/robotics-survey/Awesome-Robotics-Foundation -Models
팀원 중에는 Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu 등 우리가 잘 아는 중국 학자가 많이 있습니다.
대규모 데이터를 활용하여 광범위하게 사전 학습된 기본 모델은 미세 조정 후 다양한 다운스트림 작업에 적용할 수 있습니다. 이러한 기본 모델은 BERT, GPT-3, GPT-4, CLIP, DALL-E 및 PaLM-E와 같은 관련 모델을 포함하여 시각 및 언어 처리 분야에서 획기적인 발전을 이루었습니다
기본 모델이 등장하기 전에는 로봇용 기존 딥 러닝 모델은 다양한 작업을 위해 수집된 제한된 데이터 세트를 사용하여 학습됩니다. 이와 대조적으로 기본 모델은 광범위하고 다양한 데이터를 사용하여 사전 훈련되었으며 자연어 처리, 컴퓨터 비전 및 의료와 같은 다른 영역에서 적응성, 일반화 및 전반적인 성능을 입증했습니다. 결국 기본 모델은 로봇 분야에서도 그 잠재력을 발휘할 것으로 기대된다. 그림 1은 로봇공학 분야의 기본 모델의 개요를 보여줍니다.
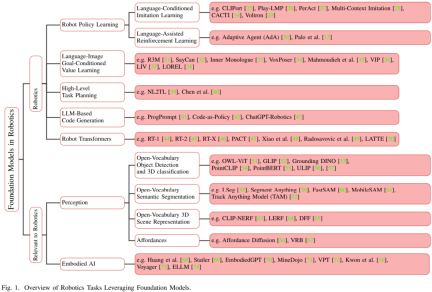
작업별 모델에 비해 기본 모델에서 지식을 이전하면 교육 시간과 컴퓨팅 리소스를 줄일 수 있는 잠재력이 있습니다. 특히 로봇 관련 분야에서 다중 모드 기본 모델은 다양한 센서에서 수집된 다중 모드 이질적 데이터를 로봇 이해 및 추론에 필요한 컴팩트한 동종 표현으로 융합하고 정렬할 수 있습니다. 학습한 표현은 인식, 의사결정, 제어 등 다시 작성해야 하는 표현을 포함하여 자동화 기술 스택의 모든 부분에서 사용할 수 있습니다.
그뿐만 아니라 기본 모델은 제로샷 학습 기능도 제공할 수 있어 AI 시스템이 예제나 목표 교육 없이 작업을 수행할 수 있습니다. 이를 통해 로봇은 학습한 지식을 새로운 사용 사례에 일반화하여 구조화되지 않은 환경에서 로봇의 적응성과 유연성을 향상시킬 수 있습니다.
기본 모델을 로봇 시스템에 통합하면 로봇의 환경 인식 능력과 환경과의 상호 작용 능력이 향상될 수 있습니다. 다시 작성해야 할 맥락인 지각 로봇 시스템을 실현할 수 있습니다.
예를 들어, 다시 작성해야 할 사항은 다음과 같습니다. 지각 분야에서 대규모 시각 언어 모델(VLM)은 시각 데이터와 텍스트 데이터 간의 연관성을 학습하여 모달 간 이해 기능을 갖추고 이를 통해 도움을 줄 수 있습니다. 제로샷 이미지 분류, 제로 샘플 객체 감지 및 3D 분류와 같은 작업. 또 다른 예로, 3D 세계에서 언어 기반(즉, VLM의 상황별 이해를 3D 실제 세계와 정렬)은 발화를 3D 환경의 특정 개체, 위치 또는 동작과 연결하여 로봇의 공간 요구 사항을 향상시킬 수 있습니다. : 인지하는 능력.
의사결정 또는 계획 분야에서 연구에 따르면 LLM과 VLM은 로봇이 상위 수준 계획과 관련된 작업을 지정하는 데 도움을 줄 수 있는 것으로 나타났습니다.
작업, 탐색 및 상호 작용과 관련된 언어 신호를 활용하여 로봇은 더 복잡한 작업을 수행할 수 있습니다. 예를 들어, 모방학습, 강화학습 등의 로봇 정책학습 기술의 경우 기본 모델은 데이터 효율성과 맥락 이해를 향상시키는 능력을 갖춘 것으로 보인다. 특히, 언어 기반 보상은 형성된 보상을 제공하여 강화 학습 에이전트를 안내할 수 있습니다.
또한 연구자들은 이미 언어 모델을 사용하여 정책 학습 기술에 대한 피드백을 제공하고 있습니다. 일부 연구에 따르면 VLM 모델의 시각적 질문 응답(VQA) 기능이 로봇 사용 사례에 사용될 수 있는 것으로 나타났습니다. 예를 들어, 연구자들은 VLM을 사용하여 로봇이 작업을 완료하는 데 도움이 되는 시각적 콘텐츠와 관련된 질문에 답했습니다. 또한 일부 연구자들은 VLM을 사용하여 데이터 주석을 지원하고 시각적 콘텐츠에 대한 설명 레이블을 생성합니다.
기본 모델은 비전 및 언어 처리 분야에서 혁신적인 기능을 갖추고 있지만 실제 로봇 작업을 위한 기본 모델의 일반화 및 미세 조정은 여전히 매우 어렵습니다.
이러한 과제는 다음과 같습니다.
1) 데이터 부족: 로봇 작동, 위치 지정 및 탐색과 같은 작업을 지원하기 위해 인터넷 규모의 데이터를 얻는 방법과 이러한 데이터를 자기 감독 교육에 사용하는 방법
2) 큰 차이점: 기본 모델에 필요한 일반성을 유지하면서 다양한 물리적 환경, 물리적 로봇 플랫폼 및 잠재적인 로봇 작업을 처리하는 방법
3) 불확실성 정량화 문제: 인스턴스 수준 불확실성을 해결하는 방법 (예: 언어 모호성 또는 LLM 환상), 배포 수준 불확실성 및 배포 변경 문제, 특히 폐쇄 루프 로봇 배포로 인한 배포 변경 문제.
4) 안전성 평가: 기본 모델을 기반으로 로봇 시스템을 배포 전, 업데이트 과정, 작업 과정에서 엄격하게 테스트하는 방법입니다.
5) 실시간 성능: 로봇의 기본 모델 배포를 방해하는 일부 기본 모델의 긴 추론 시간을 처리하는 방법과 온라인 의사 결정에 필요한 기본 모델의 추론을 가속화하는 방법- 만들기.
이 리뷰 논문은 로봇 공학 분야의 기본 모델의 현재 사용을 요약합니다. 연구자들은 현재의 방법, 적용 및 과제를 조사하고 이러한 과제를 해결하기 위한 향후 연구 방향을 제안합니다. 또한 로봇 자율성을 달성하기 위해 기본 모델을 사용하는 데 존재할 수 있는 잠재적인 위험을 지적했습니다.
기본 모델 배경 지식
기본 모델은 수십억 개의 매개변수를 가지며 인터넷 수준의 대규모 데이터를 사용하여 사전 훈련됩니다. 이렇게 크고 복잡한 모델을 훈련하는 데는 비용이 매우 많이 듭니다. 데이터 획득, 처리, 관리 비용도 높을 수 있습니다. 훈련 과정에는 많은 양의 컴퓨팅 리소스가 필요하고, GPU나 TPU와 같은 전용 하드웨어를 사용해야 하며, 모델 훈련을 위한 소프트웨어와 인프라도 필요하므로 모두 재정적 투자가 필요합니다. 또한 기본 모델의 학습 시간도 매우 길어서 비용도 많이 듭니다. 따라서 이러한 모델은 종종 플러그형 모듈로 사용됩니다. 즉, 광범위한 사용자 정의 작업 없이 기본 모델을 다양한 애플리케이션에 통합합니다.
표 1에는 일반적으로 사용되는 기본 모델의 세부 정보가 나와 있습니다.
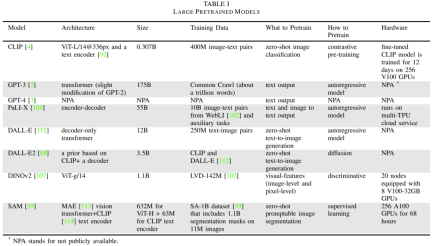
이 섹션에서는 LLM, 시각적 변환기, VLM, 구현된 다중 모달 언어 모델 및 시각적 생성 모델에 중점을 둡니다. 또한 기본 모델을 훈련하는 데 사용되는 다양한 훈련 방법도 소개됩니다
먼저 토큰화, 생성 모델, 판별 모델, 트랜스포머 아키텍처, 자동 회귀 모델, 마스크 자동 인코딩, 대조 학습을 포함하는 몇 가지 관련 용어와 수학적 지식을 소개합니다. 및 확산 모델.
그런 다음 LLM(Large Language Models)의 예와 역사적 배경을 소개합니다. 이후에는 시각적 변환기(Visual Transformer), 다중 모드 비전 언어 모델(VLM), 구체화된 다중 모드 언어 모델, 시각적 생성 모델이 강조되었습니다.
로봇 연구
이 섹션에서는 로봇 의사 결정, 계획 및 제어에 중점을 둡니다. 이 영역에서는 LLM(대형 언어 모델)과 VLM(시각 언어 모델) 모두 로봇의 기능을 향상시키는 데 사용될 수 있는 잠재력을 가지고 있습니다. 예를 들어, LLM은 로봇이 인간으로부터 높은 수준의 지시를 받고 해석할 수 있도록 작업 지정 프로세스를 용이하게 할 수 있습니다.
VLM도 이 분야에 기여할 것으로 기대됩니다. VLM은 시각적 데이터 분석에 탁월합니다. 로봇이 정보에 입각한 결정을 내리고 복잡한 작업을 수행하려면 시각적 이해가 중요합니다. 이제 로봇은 자연어 신호를 사용하여 조작, 탐색 및 상호 작용과 관련된 작업을 수행하는 능력을 향상시킬 수 있습니다.
목표 기반의 시각적 언어 정책 학습(모방 학습이든 강화 학습이든)이 기본 모델을 통해 향상될 것으로 예상됩니다. 언어 모델은 정책 학습 기술에 대한 피드백도 제공할 수 있습니다. 이 피드백 루프는 로봇이 LLM에서 받은 피드백을 기반으로 작업을 최적화할 수 있으므로 로봇의 의사 결정 능력을 지속적으로 향상시키는 데 도움이 됩니다.
이 섹션에서는 로봇 의사 결정 분야에서 LLM 및 VLM의 적용에 중점을 둡니다.
이 섹션은 6개 부분으로 나누어져 있습니다. 첫 번째 부분에서는 언어 기반 모방 학습, 언어 기반 강화 학습 등 의사 결정 및 제어와 로봇을 위한 정책 학습을 소개합니다.
두 번째 부분은 목표 기반 언어-이미지 가치 학습입니다.
세 번째 부분에서는 언어 지침을 통해 작업을 설명하고 언어 모델을 사용하여 작업 계획을 위한 코드를 생성하는 등 로봇 작업을 계획하기 위해 대규모 언어 모델을 사용하는 방법을 소개합니다.
네 번째 부분은 의사결정을 위한 상황별 학습(ICL)입니다.
다음으로 소개할 것은 로봇트랜스포머
여섯번째는 로봇 내비게이션과 개방형 어휘도서관 운영입니다.
표 2는 모델 크기 및 아키텍처, 사전 훈련 작업, 추론 시간 및 하드웨어 설정을 보고하는 몇 가지 기본 로봇별 모델을 제공합니다.
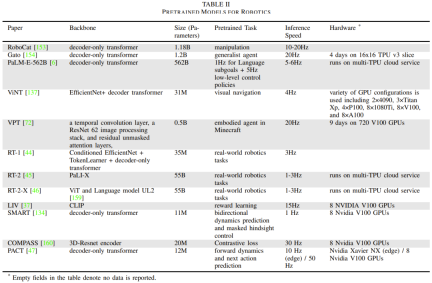
다시 작성해야 할 것은 인식
입니다.주변 환경과 상호 작용하는 로봇은 이미지, 비디오, 오디오, 언어 등 다양한 양식으로 감각 정보를 수신합니다. 이 고차원 데이터는 로봇이 환경을 이해하고, 추론하고, 상호 작용하는 데 중요합니다. 기본 모델은 이러한 고차원 입력을 해석하고 조작하기 쉬운 추상 구조 표현으로 변환할 수 있습니다. 특히 다중 모드 기본 모델을 사용하면 로봇은 다양한 감각의 입력을 의미, 공간, 시간 및 어포던스 정보가 포함된 통합 표현으로 통합할 수 있습니다. 이러한 다중 모드 모델에는 교차 모드 상호 작용이 필요하며 일관성과 상호 대응을 보장하기 위해 다양한 양식의 요소를 정렬해야 하는 경우가 많습니다. 예를 들어, 이미지 설명 작업에는 텍스트와 이미지 데이터의 정렬이 필요합니다.
이 섹션에서는 로봇이 다시 작성해야 하는 사항, 즉 인식과 관련된 일련의 작업에 중점을 둘 것입니다. 이는 양식을 정렬하기 위해 기본 모델을 사용하여 개선할 수 있습니다. 비전과 언어에 중점을 두고 있습니다.
이 섹션은 다섯 부분으로 나누어져 있는데, 먼저 개방형 어휘의 표적 검출 및 3차원 분류, 개방형 어휘의 의미적 분할, 개방형 어휘의 3차원 장면 및 표적 표현, 그 다음으로 학습된 어포던스, 최종적으로 예측 모델.
Embodied AI
최근 일부 연구에 따르면 LLM은 구체화된 AI 분야에서 성공적으로 사용될 수 있는 것으로 나타났습니다. 여기서 "embodied"는 일반적으로 실제 로봇 몸체를 갖는 것이 아니라 월드 시뮬레이터의 가상 구현을 의미합니다.
이 분야에서 몇 가지 흥미로운 프레임워크, 데이터 세트 및 모델이 등장했습니다. 특히 주목할 점은 구체화된 에이전트를 훈련하기 위한 플랫폼으로 Minecraft 게임을 사용한다는 것입니다. 예를 들어 Voyager는 GPT-4를 사용하여 Minecraft 환경을 탐색하는 에이전트를 안내합니다. GPT-4의 모델 매개변수를 미세 조정할 필요 없이 상황별 프롬프트 설계를 통해 GPT-4와 상호 작용할 수 있습니다.
강화 학습은 로봇 학습 분야에서 중요한 연구 방향입니다. 연구자들은 강화 학습을 최적화하기 위해 기본 모델을 사용하여 보상 기능을 설계하려고 합니다.
로봇이 높은 수준의 계획을 수행하기 위해 연구자들은 기본 모델의 사용을 탐구해 왔습니다. 도움을 주는 모델. 또한 일부 연구자들은 체화된 지능에 사고 사슬 기반 추론 및 행동 생성 방법을 적용하려고 노력하고 있습니다.
도전 과제 및 향후 방향
이 섹션에서는 로봇의 기본 모델 사용과 관련된 과제를 제공합니다. 또한 팀은 이러한 과제를 해결할 수 있는 향후 연구 방향을 탐색할 것입니다.
첫 번째 과제는 다음을 포함하는 로봇용 기본 모델을 훈련할 때 데이터 부족 문제를 극복하는 것입니다.
1. 구조화되지 않은 게임 데이터와 레이블이 지정되지 않은 인간 비디오를 사용하여 로봇 학습 확장
2. 이미지 인페인팅(인페인팅)을 사용하여 데이터 향상
3. 3D 기본 모델 학습 시 3D 데이터 부족 문제 극복
4. 고충실도 시뮬레이션을 통해 합성 데이터 생성
5. VLM을 사용하여 데이터 향상 데이터 증강을 위해 VLM을 사용하는 것은 효과적인 방법입니다
6. 로봇의 물리적 능력은 기술의 분포에 의해 제한됩니다
두 번째 과제는 실시간 성능과 관련이 있으며 여기서 핵심은 기본 모델의 추론 시간입니다. .
세 번째 과제는 다중 모드 표현의 한계와 관련이 있습니다.
네 번째 과제는 인스턴스 수준 및 배포 수준과 같은 다양한 수준에서 불확실성을 정량화하는 방법이며 배포 변화를 보정하고 처리하는 방법에 대한 문제도 포함됩니다.
다섯 번째 과제는 배포 전 보안 테스트, 런타임 모니터링, 배포 중단 상황 감지 등을 포함한 보안 평가입니다.
여섯 번째 챌린지는 선택 방법에 관한 것입니다. 기존 기본 모델을 사용할 것인가 아니면 로봇을 위한 새로운 기본 모델을 구축할 것인가입니다.
일곱 번째 과제는 로봇 설정의 높은 가변성과 관련이 있습니다.
여덟 번째 과제는 로봇 설정에서 어떻게 벤치마킹하고 재현성을 보장할 것인가입니다.
자세한 연구 내용은 원문을 참고해주세요.
위 내용은 대형모델+로봇, 중국학자 다수 참여로 상세한 리뷰 리포트 공개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 机器人学我表情的样子,让人感到一丝恐惧Apr 09, 2023 am 10:11 AM
机器人学我表情的样子,让人感到一丝恐惧Apr 09, 2023 am 10:11 AM通常,机器人的主要功能是完成一些简单的操作任务,我们希望机器人可以模仿人,让能力尽可能接近人类水平。不论是小米的 CyberOne 还是特斯拉的 Optimus,人们关心的主要是其机械关节数量,控制算法和行走速度。不过在这个领域,有些人探索的方向更加脑洞大开:现在,有一种机器人把模仿真人表情做到了极致:先尝试一下自拍。从「嫌弃」到「惊讶」,都可以做到完全同步:这个机器人名叫 Ameca,是个表情怪。除了模仿,它自己也能照镜子做很多小表情,看起来非常像真人。Ameca「假装」第一次见到镜子,首
 拿破仑、孔子在线陪聊!AI聊天机器人「复活」历史名人,网友:真上头!Apr 08, 2023 pm 12:11 PM
拿破仑、孔子在线陪聊!AI聊天机器人「复活」历史名人,网友:真上头!Apr 08, 2023 pm 12:11 PM和活生生的已故历史名人聊天是个什么感觉?近日,就有一群开发者利用语言模型,把千百年来各行各业的历史名人全部「复活」成了聊天机器人,做进了一款手机app里,起名叫「你好,历史」!开发者声称,这个与古代名人聊天的app涉及的内容几乎无所不包。比如可以:与玛丽莲·梦露聊好莱坞八卦与弗里达·卡洛讨论现代艺术问问圣诞老人他有多少只驯鹿问问科特·科本为什么自杀向穴居人学习如何生火与宇宙意识辩论生命的意义不过他们也没忘记提醒用户,这些对话是由人工智能生成的,所以不要太认真。而且每个对话都是独一无二的,你永远不
 女王登基70周年,世上首个超逼真人形机器艺术家献上肖像画作,被锐评“缺少信念”Apr 08, 2023 pm 08:11 PM
女王登基70周年,世上首个超逼真人形机器艺术家献上肖像画作,被锐评“缺少信念”Apr 08, 2023 pm 08:11 PM大数据文摘出品作者:Caleb为庆祝英国女王伊丽莎白二世登基70周年,英国也是早早就洋溢出了庆典的味道。据了解,英国将于6月2日至5日连放4天公众假期,并在期间举行多项庆祝活动。英国皇家铸币厂也在精心打造有史以来最大的硬币,直径220毫米,重15公斤,面值15000英镑,耗时近400小时打造,是该厂1100年来生产的最大硬币。这枚金币一面雕刻着代表英国女王伊丽莎白二世的符号EⅡR,周围环绕着代表英国的玫瑰、水仙、蓟和三叶草。另一面有女王骑在马背上的图案。在这么热闹的日子里,AI当然也必须来凑一凑
 人类与人工智能如何建立关系Apr 09, 2023 pm 07:41 PM
人类与人工智能如何建立关系Apr 09, 2023 pm 07:41 PM人类与人工智能相比,哪个更擅长建立关系?事实上,这项革命性的技术已经存在了很长一段时间。然而,直到最近人们才意识到人工智能对人类的重要性。人工智能利用算法模拟人类,并随着时间的推移从经验中学习的能力,为这项技术与人类建立关系开辟道路。人类如何建立人际关系作为人类,我们倾向于只与少数人建立关系。我们试图确保不需要的和不相干的人从我们的生活中消失。在将我们的关系限制在少数人的同时,我们确保与那些对我们真正重要的人建立高质量的关系。然而,同样的方法在商业用语中可能不是理想的,并可能适得其反。尽管知道这
 盘点全球不错的七所机器人工程专业学校Apr 08, 2023 pm 01:31 PM
盘点全球不错的七所机器人工程专业学校Apr 08, 2023 pm 01:31 PM有抱负的工程师应该了解世界各地著名的机器人工程学院。现在是从事机器人和工程事业的最佳时机——从人工智能到太空探索,这一领域充满了令人兴奋的创新和进步。美国劳工统计局估计,未来10年,机械工程领域的职业总体上将保持7%的稳定增长率,确保毕业生将有大量的就业机会。机器人工程专业的学生平均工资超过9万美元,无需担心还助学贷款的问题。对于那些考虑投身机器人工程领域的人来说,选择一所合适的大学是非常重要的。世界上许多顶尖的机器人工程学院都在美国,尽管国外也有一些很棒的项目。这是7所世界上最好的机器人工程学
 让机器人学会咖啡拉花,得从流体力学搞起!CMU&MIT推出流体模拟平台Apr 07, 2023 pm 04:46 PM
让机器人学会咖啡拉花,得从流体力学搞起!CMU&MIT推出流体模拟平台Apr 07, 2023 pm 04:46 PM机器人也能干咖啡师的活了!比如让它把奶泡和咖啡搅拌均匀,效果是这样的:然后上点难度,做杯拿铁,再用搅拌棒做个图案,也是轻松拿下:这些是在已被ICLR 2023接收为Spotlight的一项研究基础上做到的,他们推出了提出流体操控新基准FluidLab以及多材料可微物理引擎FluidEngine。研究团队成员分别来自CMU、达特茅斯学院、哥伦比亚大学、MIT、MIT-IBM Watson AI Lab、马萨诸塞大学阿默斯特分校。在FluidLab的加持下,未来机器人处理更多复杂场景下的流体工作也都
 四足机器人学会“双腿站立下楼梯”!效率比腿式系统高83%Apr 09, 2023 am 11:21 AM
四足机器人学会“双腿站立下楼梯”!效率比腿式系统高83%Apr 09, 2023 am 11:21 AM还记得那个和特斯拉飙车的机器人吗?这是瑞士苏黎世联邦理工学院衍生公司研发的与公司同名的四足轮腿式机器人——Swiss-Mile,前身是ANYmal四足机器人。距离它和特斯拉飙车还不到半年的时间,它又实现了重大升级。这次升级改进了机器人的算法,运动能力直接UP UP UP ! 可以双腿站立下楼梯:(小编内心OS:如果是我穿轮滑鞋下楼梯可能会摔个狗吃屎)楼梯爬累了,坐个电梯吧,用前脚按开电梯门:面对障碍物应对自如:它还能知道什么时候该站起来,什么时候该“趴下”,双腿直立与四足运动之间的切换更丝滑:
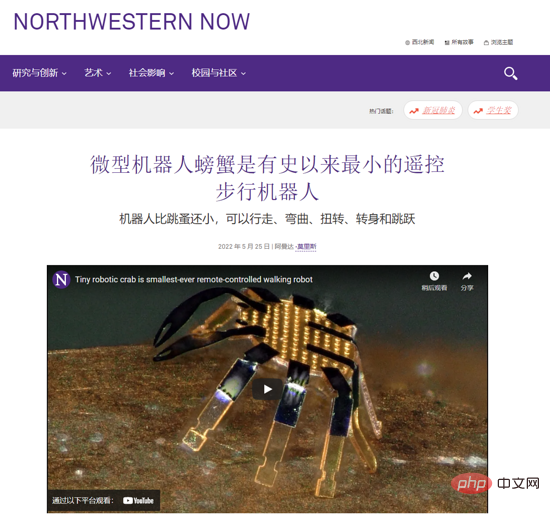 科学家展示世界上有史以来超小的“螃蟹”遥控步行机器人,体积比跳蚤还小Apr 09, 2023 pm 10:41 PM
科学家展示世界上有史以来超小的“螃蟹”遥控步行机器人,体积比跳蚤还小Apr 09, 2023 pm 10:41 PM日前,美国西北大学工程师开发出有史以来最小的遥控步行机器人,它以一种小巧可爱的螃蟹形式出现。这种微小的“螃蟹”机器人宽度只有半毫米,可以弯曲、扭曲、爬行、行走、转弯甚至跳跃,无需液压或电力。IT之家了解到,相关研究成果发表在《科学・机器人》上。据介绍,这种机器人是用形状记忆合金材料所制造的,然后可以变成所需的形状,当你加热后又会变回原来的形状,而热量消失时可以再次弹回变形时的样子。据介绍,其热量是由激光所带来的。激光通过“螃蟹”加热合金,但因为它们非常小,所以热量传播非常快,这使得它们的响应速度


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

드림위버 CS6
시각적 웹 개발 도구

WebStorm Mac 버전
유용한 JavaScript 개발 도구

