



앞서 작성 및 작성자 개인 요약
BEV(Bird Eye's View) 감지는 여러 개의 서라운드 뷰 카메라를 융합하여 감지하는 방법입니다. 현재 알고리즘의 대부분은 동일한 데이터 세트에서 훈련되고 평가되므로 이러한 알고리즘은 변경되지 않은 카메라 내부 매개변수(카메라 유형) 및 외부 매개변수(카메라 배치)에 과적합됩니다. 본 논문에서는 알 수 없는 도메인에서 객체 감지 문제를 해결할 수 있는 암시적 렌더링 기반 BEV 감지 프레임워크를 제안합니다. 프레임워크는 암시적 렌더링을 사용하여 개체의 3D 위치와 단일 뷰의 원근 위치 간의 관계를 설정하며, 이는 원근 편향을 수정하는 데 사용할 수 있습니다. 이 방법은 DG(도메인 일반화) 및 UDA(무감독 도메인 적응)에서 상당한 성능 향상을 달성합니다. 이 방법은 실제 시나리오에서 BEV 감지의 훈련 및 평가를 위해 가상 데이터 세트만 사용하려는 첫 번째 시도로, 가상과 실제 사이의 장벽을 허물고 폐쇄 루프 테스트를 완료할 수 있습니다.
- 문서 링크: https://arxiv.org/pdf/2310.11346.pdf
- 코드 링크: https://github.com/EnVision-Research/Generalised-BEV

BEV 탐지 도메인 일반 문제 배경
다중 카메라 감지는 여러 대의 카메라를 사용하여 3차원 공간에서 물체를 감지하고 찾는 작업을 말합니다. 다중 카메라 3D 객체 감지는 서로 다른 시점의 정보를 결합함으로써 특히 특정 시점의 대상이 가려지거나 부분적으로 보일 수 있는 상황에서 더욱 정확하고 강력한 객체 감지 결과를 제공할 수 있습니다. 최근에는 BEV(Bird Eye's View) 방식이 다중 카메라 감지 작업에서 큰 주목을 받고 있습니다. 이러한 방법은 다중 카메라 정보 융합에 장점이 있지만, 테스트 환경이 훈련 환경과 크게 다를 경우 이러한 방법의 성능이 크게 저하될 수 있습니다.
현재 대부분의 BEV 감지 알고리즘은 동일한 데이터 세트에서 훈련 및 평가되므로 이러한 알고리즘은 내부 및 외부 카메라 매개변수와 도시 도로 조건의 변화에 너무 민감하여 심각한 과잉 맞춤 문제를 초래합니다. 그러나 실제 응용 분야에서는 BEV 감지 알고리즘이 다양한 새 모델과 새 카메라에 적응해야 하는 경우가 많으며 이로 인해 이러한 알고리즘이 실패하게 됩니다. 따라서 BEV 감지의 일반화 가능성을 연구하는 것이 중요합니다. 또한, 폐쇄 루프 시뮬레이션도 자율 주행에 매우 중요하지만 현재는 Carla와 같은 가상 엔진에서만 평가할 수 있습니다. 따라서 가상 엔진과 실제 장면 간의 도메인 차이 문제를 해결해야 합니다.
도메인 일반화(DG)와 비지도 도메인 적응(UDA)은 배포 전환 방향을 완화하기 위한 두 가지 유망한 방법입니다. DG 방법은 도메인별 기능을 분리하고 제거하여 보이지 않는 도메인의 일반화 성능을 향상시키는 경우가 많습니다. UDA의 경우 최근 방법은 의사 레이블 또는 잠재 기능 분포 정렬을 생성하여 도메인 이동을 완화합니다. 그러나 순수한 시각적 인식을 위한 시점 및 환경 독립적인 기능을 학습하는 것은 다양한 시점, 카메라 매개변수 및 환경의 데이터를 사용하지 않고는 매우 어렵습니다.
관찰 결과에 따르면 그림에 표시된 것처럼 단일 관점(카메라 평면)에서 2D 감지가 여러 관점에서 3D 개체 감지보다 일반화 기능이 더 강한 경향이 있습니다. 일부 연구에서는 2D 정보를 3D 감지기에 융합하거나 2D-3D 일관성을 설정하는 등 2D 감지를 BEV 감지에 통합하는 방법을 모색했습니다. 2차원 정보융합은 메커니즘 모델링 방식이 아닌 학습 기반 방식으로, 여전히 도메인 마이그레이션으로 인해 심각한 영향을 받고 있다. 기존 2D-3D 일관성 방법은 3D 결과를 2차원 평면에 투영하고 일관성을 설정합니다. 이러한 제약은 대상 도메인의 기하학적 정보를 수정하는 대신 대상 도메인의 의미 정보에 해를 끼칠 수 있습니다. 또한 이 2D-3D 일관성 접근 방식은 모든 감지 헤드에 대한 통합 접근 방식을 어렵게 만듭니다.
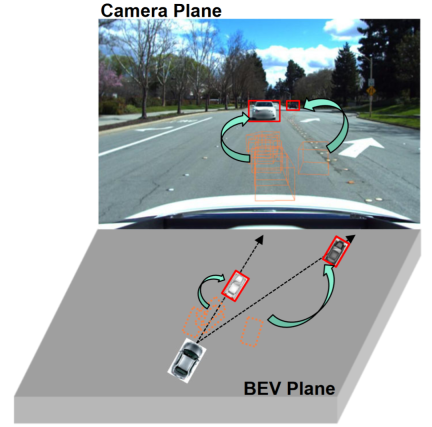
이 백서의 기여 요약
- 이 백서는 관점 편향 제거를 기반으로 하는 일반화된 BEV 감지 프레임워크를 제안합니다. 이 프레임워크는 모델이 소스 도메인에서 관점과 컨텍스트 불변 기능을 학습하는 데 도움이 될 수 있습니다. 2차원 검출기는 대상 도메인의 허위 기하학적 특징을 추가로 수정하는 데에도 활용될 수 있습니다.
- 이 논문은 BEV 감지에 대한 비지도 도메인 적응을 연구하고 벤치마크를 설정하려는 첫 번째 시도입니다. UDA 및 DG 프로토콜 모두에서 최첨단 결과를 얻을 수 있습니다.
- 이 문서는 실제 BEV 감지 작업을 달성하기 위해 실제 장면 주석 없이 가상 엔진에 대한 교육을 탐구한 최초의 문서입니다.
BEV 감지 영역 일반화 문제 정의
문제 정의
연구는 주로 BEV 감지의 일반화 향상에 중점을 둡니다. 이 목표를 달성하기 위해 이 백서에서는 DG(도메인 일반화) 및 UDA(무감독 도메인 적응)라는 널리 실용적으로 적용되는 두 가지 프로토콜을 탐색합니다.
BEV 일반화(DG)에 의해 감지된 도메인: 기존 알 수 없는 데이터 세트(대상 도메인)에 대한 탐지 성능을 향상시키기 위해 데이터 세트(원본 도메인)를 사용합니다. 예를 들어, 특정 차량이나 시나리오에서 BEV 감지 모델을 교육하면 다양한 차량과 시나리오로 직접 일반화될 수 있습니다.
BEV 감지를 위한 UDA(Unsupervised Domain Adaptation): 기존 데이터 세트(소스 도메인)에서 BEV 감지 알고리즘을 교육하고 대상 도메인에서 레이블이 지정되지 않은 데이터를 사용하여 감지 성능을 향상시킵니다. 예를 들어, 새로운 차량이나 도시에서는 감독되지 않은 데이터를 수집하는 것만으로도 새로운 차량과 새로운 환경에서 모델의 성능을 향상시킬 수 있습니다. DG와 UDA의 유일한 차이점은 대상 도메인의 라벨이 지정되지 않은 데이터를 활용할 수 있는지 여부입니다.
보기 각도 편차 정의
물체의 알 수 없는 L=[x,y,z]를 감지하기 위해 대부분의 BEV 감지에는 두 가지 핵심 부분이 있습니다. (1) 다양한 보기 각도에서 이미지 특징을 얻습니다. 2) 이러한 이미지의 융합 특징은 BEV 공간으로 전달되고 최종 예측 결과가 얻어집니다.
위 수식은 도메인 편차가 특징 추출 단계 또는 BEV 융합 단계에서 발생할 수 있음을 설명합니다. 그런 다음 이 기사는 부록으로 진행하여 2D 결과에 투영된 최종 3D 예측 결과의 시야각 편차를 다음과 같이 얻었습니다.
여기서 k_u, b_u, k_v 및 b_v는 BEV 인코더의 도메인 오프셋 d와 관련이 있습니다. (u, v)는 모델의 최종 예측 깊이 정보입니다. c_u 및 c_v는 uv 이미지 평면에서 카메라 광학 중심의 좌표를 나타냅니다. 위 방정식은 몇 가지 중요한 추론을 제공합니다. (1) 최종 위치 오프셋이 있으면 관점 편향이 발생합니다. 이는 관점 편향을 최적화하면 도메인 오프셋을 완화하는 데 도움이 될 수 있음을 보여줍니다. (2) 단일 뷰 이미징 평면에서 카메라 광학 중심 광선의 지점 위치도 이동합니다.
직관적으로 도메인 이동은 BEV 기능의 위치를 변경하는데, 이는 제한된 훈련 데이터 관점 및 카메라 매개변수로 인한 과적합 때문입니다. 이 문제를 완화하려면 BEV 기능에서 새로운 뷰 이미지를 다시 렌더링하여 네트워크가 뷰 및 환경에 독립적인 기능을 학습할 수 있도록 하는 것이 중요합니다. 이를 고려하여 본 연구에서는 렌더링 시점에 따른 관점 편차를 해결하여 모델의 일반화 능력을 향상시키는 것을 목표로 합니다
PD-BEV 알고리즘에 대한 자세한 설명
PD-BEV는 의미론적 세 부분으로 나뉩니다. 렌더링, 소스 도메인 제거 바이어스 및 대상 도메인 디바이어스는 그림 1에 나와 있습니다. 의미론적 렌더링은 BEV 기능을 통해 2D 및 3D 관점 관계를 설정하는 방법을 설명합니다. 소스 도메인 편향성 제거는 소스 도메인에서 의미론적 렌더링을 통해 모델 일반화 기능을 향상시키는 방법을 설명합니다. 대상 도메인 편향성 제거는 의미론적 렌더링을 통해 모델 일반화 기능을 향상시키기 위해 대상 도메인에서 레이블이 지정되지 않은 데이터를 사용하는 것을 설명합니다.
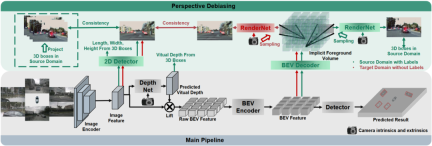
의미론적 렌더링
많은 알고리즘이 BEV 볼륨을 2차원 특징으로 압축하므로 먼저 BEV 디코더를 사용하여 BEV 특징을 볼륨으로 변환합니다.
위 공식은 실제로 BEV 평면입니다. 개선을 위해 높이 치수가 추가되었습니다. 그런 다음 카메라의 내부 및 외부 매개변수를 이 볼륨에서 샘플링하여 2D 기능 맵이 될 수 있습니다. 그런 다음 2D 기능 맵과 카메라의 내부 및 외부 매개변수를 RenderNet으로 전송하여 히트맵과 개체 속성을 예측합니다. 해당 관점. Nerf와 유사한 작업을 통해 2D와 3D 간의 브리지를 설정할 수 있습니다.
소스 도메인 디바이어스
모델의 일반화 성능을 향상하려면 소스 도메인에서 개선해야 할 몇 가지 핵심 사항이 있습니다. 첫째, 원근 편향을 줄이기 위해 소스 도메인의 3D 상자를 사용하여 새로 렌더링된 뷰의 히트맵과 속성을 모니터링할 수 있습니다. 둘째, 정규화된 깊이 정보를 사용하여 이미지 인코더가 기하학적 정보를 더 잘 학습할 수 있습니다. 이러한 개선 사항은 모델의 일반화 성능을 향상시키는 데 도움이 됩니다.
관점 의미 체계 감독: 의미 체계 렌더링을 기반으로 히트맵과 속성이 다양한 관점(RenderNet의 출력)에서 렌더링됩니다. 동시에 카메라의 내부 및 외부 매개변수는 무작위로 샘플링되고 이러한 내부 및 외부 매개변수를 사용하여 개체의 상자가 3D 좌표에서 2차원 카메라 평면으로 투영됩니다. 그런 다음 초점 손실과 L1 손실을 사용하여 투영된 2Dbox 및 렌더링 결과를 제한합니다.
이 작업을 통해 카메라의 내부 및 외부 매개변수의 과적합을 줄이고 새로운 관점에 대한 견고성을 향상할 수 있습니다. 이 논문은 무인 운전 분야에서 새로운 관점의 RGB 감독이 부족하다는 단점을 피하기 위해 RGB 이미지의 지도 학습을 객체 중심의 히트 맵으로 변환한다는 점을 언급할 가치가 있습니다.
기하학적 감독: 명시적인 깊이 정보 제공은 효과적으로 다중 카메라 3D 객체 감지 성능을 향상시킵니다. 그러나 네트워크 예측의 깊이는 고유 매개변수에 과적합되는 경향이 있습니다. 따라서 이 문서에서는 가상 깊이 접근 방식을 사용합니다.
여기서 BCE()는 이진 교차 엔트로피 손실을 나타내고 D_{pre}는 DepthNet의 예측 깊이를 나타냅니다. f_u와 f_v는 각각 이미지 평면의 u와 v 초점 거리이고 U는 상수입니다. 여기서의 깊이는 포인트 클라우드가 아닌 3D 박스를 이용하여 제공되는 전경 깊이 정보라는 점에 주목할 필요가 있습니다. 이렇게 하면 DepthNet은 전경 개체의 깊이에 더 집중할 가능성이 높습니다. 마지막으로, 실제 깊이 정보를 이용하여 의미적 특징이 BEV 평면으로 상승되면 가상 깊이가 다시 실제 깊이로 변환됩니다.
대상 도메인 디바이어스
대상 도메인에 레이블이 없으므로 3D 상자 감독을 사용하여 모델의 일반화 능력을 향상시킬 수 없습니다. 그래서 본 논문에서는 2D 검출 결과가 3D 결과보다 더 강력하다고 설명합니다. 따라서 이 논문에서는 렌더링된 관점의 감독으로 소스 도메인에서 사전 훈련된 2D 감지기를 사용하고 의사 라벨 메커니즘도 사용합니다.
이 작업은 정확한 2D 감지를 효과적으로 활용하여 BEV 공간에서 전경 대상 위치를 수정할 수 있습니다. 이는 대상 도메인의 감독되지 않은 정규화입니다. 2차원 예측의 수정 능력을 더욱 높이기 위해 의사(pseudo) 방법을 사용하여 예측된 히트 맵의 신뢰도를 높였습니다. 본 논문에서는 3D 결과에서 2D 투영 오류가 발생하는 원인을 설명하기 위해 3.2의 수학적 증명과 보충 자료를 제공합니다. 또한 이러한 방식으로 편향을 제거할 수 있는 이유에 대해서도 설명합니다. 자세한 내용은 원본 논문을 참조하세요.
전체 감독
훈련을 돕기 위해 이 문서에 일부 네트워크가 추가되었지만 추론 중에는 이러한 네트워크가 필요하지 않습니다. 즉, 우리의 방법은 대부분의 BEV 검출 방법이 관점 불변 특징을 학습하는 상황에 적용 가능합니다. 프레임워크의 효율성을 테스트하기 위해 평가에 BEVDepth를 사용하기로 선택했습니다. BEVDepth의 원래 손실은 소스 도메인에서 주요 3D 감지 감시로 사용됩니다. 요약하면 알고리즘의 최종 손실은 다음과 같습니다.
교차 도메인 실험 결과
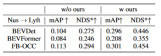
표 1은 도메인 일반화(DG) 및 비지도 도메인 적응(UDA) 프로토콜에서 다양한 방법의 효과를 비교한 것입니다. 그 중 Target-Free는 DG 프로토콜을 나타내며 Pseudo Label, Coral 및 AD는 일반적인 UDA 방법입니다. 그래프에서 볼 수 있듯이 이러한 방법은 모두 대상 도메인에서 상당한 개선을 달성합니다. 이는 의미론적 렌더링이 도메인 이동에 대한 관점 불변 기능을 학습하는 데 도움이 되는 다리 역할을 한다는 것을 의미합니다. 또한 이러한 방법은 소스 도메인의 성능을 저하시키지 않으며 대부분의 경우 일부 개선을 제공합니다. 특히 DeepAccident는 Carla 가상 엔진을 기반으로 개발되었으며 DeepAccident에 대한 교육을 마친 후 알고리즘이 만족스러운 일반화 기능을 달성했습니다. 또한 다른 BEV 감지 방법도 테스트되었지만 특별한 설계가 없으면 일반화 성능이 매우 나쁩니다. 대상 도메인에서 비지도 데이터 세트를 활용할 수 있는 능력을 추가로 검증하기 위해 UDA 벤치마크도 설정하고 UDA 방법(Pseudo Label, Coral 및 AD 포함)을 DG-BEV에 적용했습니다. 실험에 따르면 이러한 방법은 성능이 크게 향상되는 것으로 나타났습니다. 암시적 렌더링은 더 나은 일반화 성능을 갖춘 2D 감지기를 최대한 활용하여 3D 감지기의 잘못된 기하학적 정보를 수정합니다. 또한 대부분의 알고리즘은 소스 도메인의 성능을 저하시키는 경향이 있는 반면, 우리의 방법은 상대적으로 온화합니다. AD와 Coral은 가상 데이터세트에서 실제 데이터세트로 이동할 때 상당한 개선을 보였지만 실제 테스트에서는 성능 저하를 보였다는 점은 언급할 가치가 있습니다. 이는 이 두 알고리즘이 스타일 변경을 처리하도록 설계되었지만 작은 스타일 변경으로 장면의 의미 정보를 파괴할 수 있기 때문입니다. Pseudo Label 알고리즘의 경우 상대적으로 좋은 일부 대상 도메인에 대한 신뢰도를 높여 모델의 일반화 성능을 향상시킬 수 있지만, 대상 도메인에 대한 신뢰도를 맹목적으로 높이면 실제로 모델이 악화됩니다. 실험 결과는 이 알고리즘이 DG 및 UDA에서 상당한 성능 향상을 달성했음을 입증합니다. 세 가지 주요 구성 요소인 2D 검출기 사전 훈련(DPT), 소스 도메인 제거 바이어스(SDB) 및 대상 도메인에 대한 절제 실험 결과가 표 2에 나와 있습니다. 편향성 제거(TDB). 실험 결과는 각 구성 요소가 개선되었음을 보여주며, 그 중 SDB와 TDB는 상대적으로 유의미한 효과를 나타냅니다
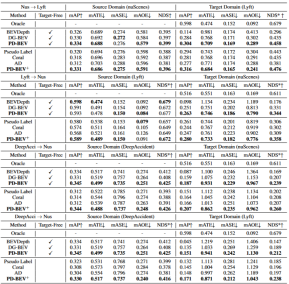
표 3은 알고리즘 알고리즘을 BEVFormer 및 FB-OCC 알고리즘으로 마이그레이션할 수 있음을 보여줍니다. 이 알고리즘은 이미지 기능과 BEV 기능에 대한 추가 작업만 필요하므로 BEV 기능으로 알고리즘을 향상시킬 수 있습니다.
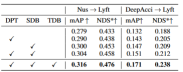
그림 5는 감지된 레이블이 없는 개체를 보여줍니다. 첫 번째 행은 라벨의 3D 상자이고, 두 번째 행은 알고리즘의 감지 결과입니다. 파란색 상자는 알고리즘이 레이블이 지정되지 않은 일부 상자를 감지할 수 있음을 나타냅니다. 이는 이 방법이 너무 멀리 떨어져 있는 차량이나 거리 양쪽에 있는 건물과 같이 대상 도메인에서 라벨이 지정되지 않은 샘플도 감지할 수 있음을 보여줍니다.
요약
본 논문에서는 미지 분야의 객체 검출 문제를 해결할 수 있는 원근감소화 기반의 범용 다중 카메라 3D 객체 검출 프레임워크를 제안합니다. 프레임워크는 3D 감지 결과를 2D 카메라 평면에 투영하고 원근 편향을 수정하여 일관되고 정확한 감지를 달성합니다. 또한 프레임워크는 다양한 관점에서 이미지를 렌더링하여 모델의 견고성을 향상시키는 관점 편향 제거 전략도 도입합니다. 실험 결과는 이 방법이 도메인 일반화 및 비지도 도메인 적응에서 상당한 성능 향상을 달성한다는 것을 보여줍니다. 또한 이 방법은 실제 장면 주석 없이도 가상 데이터 세트에 대해 학습할 수 있어 실시간 애플리케이션 및 대규모 배포에 편리함을 제공합니다. 이러한 하이라이트는 다중 카메라 3D 물체 감지를 해결하는 방법의 과제와 잠재력을 보여줍니다. 본 논문에서는 BEV의 일반화 능력을 향상시키기 위해 Nerf의 아이디어를 활용하려고 시도했으며, 레이블이 있는 소스 도메인 데이터와 레이블이 없는 대상 도메인 데이터를 사용할 수도 있습니다. 또한 자율주행 폐루프에 잠재적인 가치를 지닌 Sim2Real의 실험적 패러다임을 시도하였다. 정성적, 정량적 결과 모두 좋은 결과가 있으며, 오픈소스 코드도 살펴볼 가치가 있습니다

원본링크: https://mp.weixin.qq.com/s/GRLu_JW6qZ_nQ9sLiE0p2g
위 내용은 NeRF의 BEV 일반화 성능 혁신: 최초의 도메인 간 오픈 소스 코드가 Sim2Real을 성공적으로 구현했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM
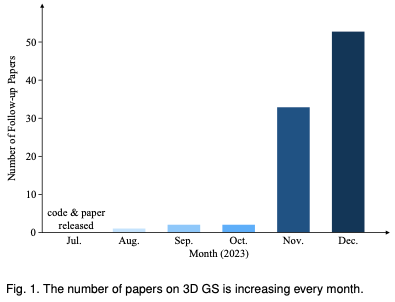
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM您一定记得,尤其是如果您是Teams用户,Microsoft在其以工作为重点的视频会议应用程序中添加了一批新的3DFluent表情符号。在微软去年宣布为Teams和Windows提供3D表情符号之后,该过程实际上已经为该平台更新了1800多个现有表情符号。这个宏伟的想法和为Teams推出的3DFluent表情符号更新首先是通过官方博客文章进行宣传的。最新的Teams更新为应用程序带来了FluentEmojis微软表示,更新后的1800表情符号将为我们每天
 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM
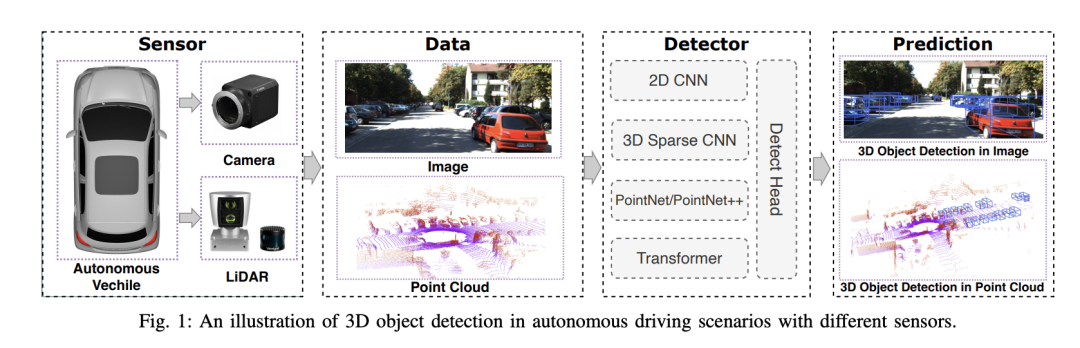
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM当八卦开始传播新的Windows11正在开发中时,每个微软用户都对新操作系统的外观以及它将带来什么感到好奇。经过猜测,Windows11就在这里。操作系统带有新的设计和功能更改。除了一些添加之外,它还带有功能弃用和删除。Windows11中不存在的功能之一是Paint3D。虽然它仍然提供经典的Paint,它对抽屉,涂鸦者和涂鸦者有好处,但它放弃了Paint3D,它提供了额外的功能,非常适合3D创作者。如果您正在寻找一些额外的功能,我们建议AutodeskMaya作为最好的3D设计软件。如
 单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PM
单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PMChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spacesoftheweek)。△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Imageto3D技术,受到了广泛关注现行beta版本生成的3D模型,
 自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM
自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM对于自动驾驶应用来说,最终还是需要对3D场景进行感知。道理很简单,车辆不能靠着一张图像上得到感知结果来行驶,就算是人类司机也不能对着一张图像来开车。因为物体的距离和场景的和深度信息在2D感知结果上是体现不出来的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(PerspectiveView)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景
 《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM
《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM一些原神“奇怪”的关键词,在这两天很有关注度,明明搜索指数没啥变化,却不断有热议话题蹦窜。例如了龙王、钟离等“转变”立绘激增,虽在网络上疯传了一阵子,但是经过追溯发现这些是合理、常规的二创同人。如果单是这些,倒也翻不起多大的热度。按照一部分网友的说法,除了原神自身就有热度外,发现了一件格外醒目的事情:原神3d同人作者shirakami已经被捕。这引发了不小的热议。为什么被捕?关键词,原神3D动画。还是越过了线(就是你想的那种),再多就不能明说了。经过多方求证,以及新闻报道,确实有此事。自从去年发


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

Dreamweaver Mac版
시각적 웹 개발 도구
뜨거운 주제
 1371
1371 523819
523819