
중국과학원 팀, 효소 동역학 매개변수의 예측 정확도 향상을 위한 통합 프레임워크 구축

- 王林앞으로
- 2024-01-10 14:50:28880검색
Editor | Radish Skin
효소 역학 매개변수의 예측은 생명공학 및 산업 응용 분야에서 효소를 설계하고 최적화하는 데 중요하지만, 다양한 작업에 대한 현재 예측 도구의 제한된 성능으로 인해 실제 적용이 제한됩니다.
중국과학원 연구원들은 최근 효소 회전율(kcat), 미카엘리스-멘텐 상수(Km) 및 촉매를 포함한 효소 동역학 매개변수를 예측하는 데 사용할 수 있는 사전 훈련된 언어 모델을 기반으로 하는 통합 프레임워크인 UniKP를 제안했습니다. 효율(kcat/Km), 이러한 매개변수는 단백질 서열과 기질 구조로부터 얻어집니다.
pH, 온도 등 환경 요인을 고려하여 kcat 값을 안정적으로 예측할 수 있는 UniKP(EF-UniKP) 기반의 2계층 프레임워크도 제안되었습니다. 동시에 연구팀은 네 가지 대표적인 재가중화 방법을 체계적으로 탐색하여 고가치 예측 작업에서 예측 오류를 줄이는 데 성공했습니다.
이 연구의 제목은 "UniKP: 효소 동역학 매개변수 예측을 위한 통합 프레임워크"이며 2023년 12월 11일 "Nature Communications" 저널에 게재되었습니다.

특정 기질에서 효소의 촉매 효율을 연구하는 것은 생물학에서 중요한 문제이며 효소 진화, 대사 공학 및 합성 생물학에 지대한 영향을 미칩니다. kcat 및 Km뿐만 아니라 최대 회전율 및 Michaelis-Menten 상수를 측정하는 시험관 내 실험 데이터는 특정 반응을 촉매하는 효소의 효율성을 측정하고 다양한 효소의 상대적인 촉매 활성을 비교하는 지표로 사용될 수 있습니다.
현재 효소 동역학 매개변수의 측정은 주로 실험적 측정에 의존하는데, 이는 시간이 많이 걸리고 비용이 많이 들고 노동 집약적이므로 실험적으로 측정된 동역학 매개변수 값에 대한 작은 데이터베이스가 생성됩니다. 예를 들어 서열 데이터베이스 UniProt에는 2억 3천만 개 이상의 효소 서열이 포함되어 있는 반면, 효소 데이터베이스 BRENDA 및 SABIO-RK에는 실험적으로 측정된 수만 개의 kcat 값이 포함되어 있습니다. 이러한 효소 데이터베이스에 Uniprot 식별자를 통합하면 측정된 매개변수와 단백질 서열 간의 연결이 용이해집니다. 그러나 이러한 연결의 규모는 효소 서열의 수에 비해 여전히 훨씬 작아서 방향성 진화 및 대사 공학과 같은 다운스트림 응용 분야의 진행이 제한됩니다.
효소 동역학 매개변수 예측 프레임워크
이 연구에서 중국과학원의 연구원들은 사전 훈련된 언어 모델을 기반으로 하며 효소 동역학 매개변수의 예측을 향상시키는 것을 목표로 하는 UniKP라는 새로운 프레임워크를 제안했습니다. . 이러한 매개변수에는 kcat, Km 및 kcat/Km이 포함되며, 이는 효소 서열 및 기질 구조를 고려하여 예측할 수 있습니다. 연구원들은 16개의 서로 다른 머신러닝 모델과 2개의 딥러닝 모델을 종합적으로 비교한 결과 UniKP가 예측 정확도 측면에서 우수한 성능을 보이는 것으로 나타났습니다. 이 연구는 효소 역학 분야의 연구 및 응용을 위한 새로운 도구와 방법을 제공할 것으로 기대됩니다.
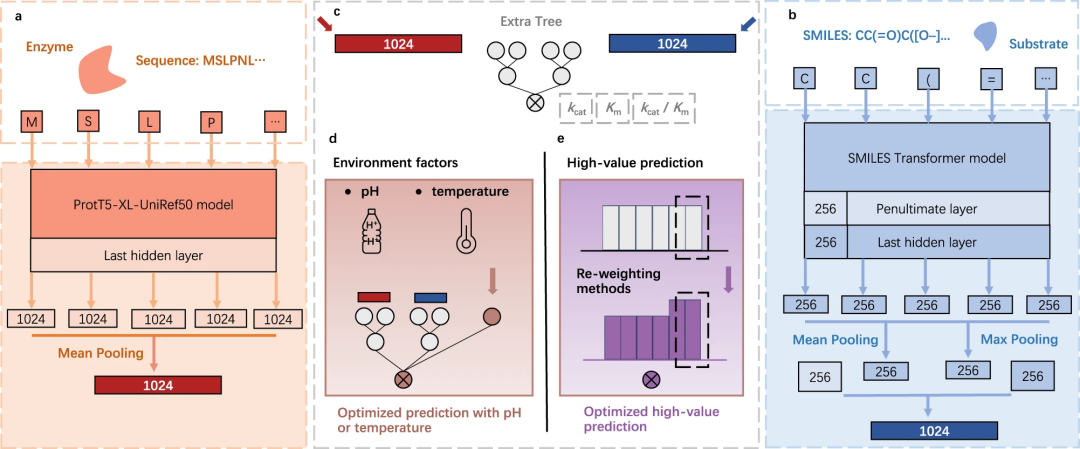
그림: UniKP 개요. (출처: 논문)
UniKP는 이전 최첨단 모델인 DLKcat과 비교하여 kcat 예측 작업에서 평균 결정계수가 0.68로 20% 향상된 우수한 성능을 보여줍니다. 연구자들은 사전 훈련된 모델이 전체 데이터베이스의 감독되지 않은 정보를 사용하여 효소 서열과 기질 구조에 대한 배우기 쉬운 표현을 생성함으로써 UniKP의 성능에 크게 기여했다고 추측합니다.
모델 학습 분석에 따르면 단백질 정보가 지배적인 역할을 하는 것으로 나타났습니다. 이는 아마도 기질 구조에 비해 효소 구조가 복잡하기 때문일 것입니다. 또한 UniKP는 실험적으로 측정된 경우를 포함하여 효소와 그 돌연변이 사이의 kcat 값의 작은 차이를 효과적으로 포착할 수 있으며 이는 효소 설계 및 변형에 중요합니다. UniKP 예측의 R^2와 높은 ID 및 낮은 ID 영역에 대한 gmean 방법의 R^2 차이는 UniKP가 더 깊게 상호 연결된 정보를 추출하여 이러한 작업에서 더 높은 성능을 발휘할 수 있음을 보여줍니다.
2계층 프레임워크 EF-UniKP
대부분의 최신 모델은 환경 요인을 고려하지 않습니다. 이는 실제 실험 조건을 시뮬레이션하는 데 주요 제한 사항입니다. 이 문제를 해결하기 위해 연구진은 환경 요인을 고려한 2계층 프레임워크 EF-UniKP를 제안했습니다. pH 및 온도 정보가 각각 포함된 두 개의 새로 구성된 데이터 세트를 기반으로 EF-UniKP는 초기 UniKP에 비해 향상된 성능을 보여줍니다. 이는 정확하고 처리량이 많으며 유기체에 독립적이고 상황에 따라 달라지는 kcat 예측입니다. 또한, 이 접근법은 공동 기판 및 NaCl 농도와 같은 다른 요소를 포함하도록 확장될 가능성이 있습니다.
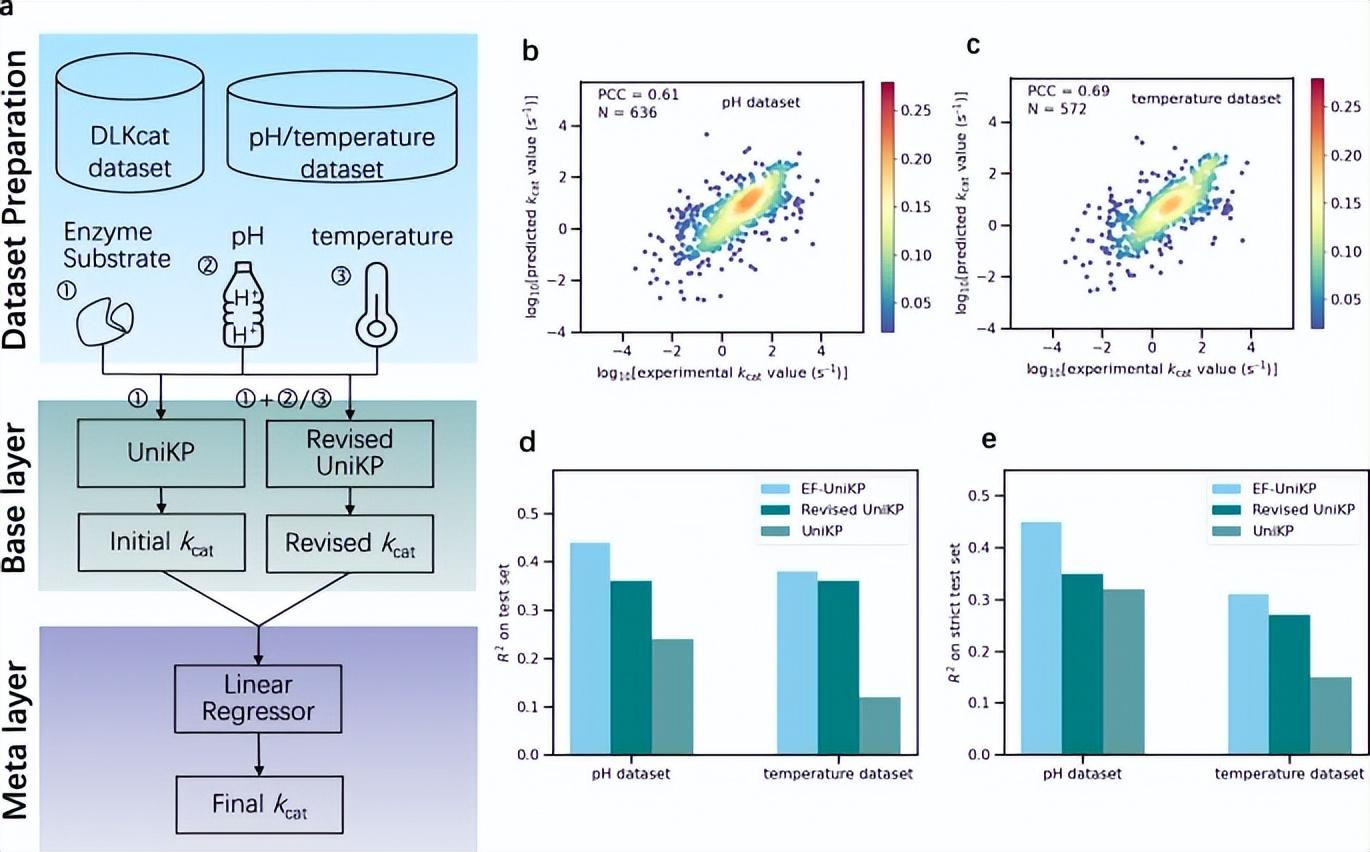
그림: 환경 요인을 고려한 2계층 프레임워크. (출처: 논문)
그러나 기존 모델은 포괄적인 데이터가 부족하여 이러한 요소 간의 상호 작용을 고려하지 않습니다. 바이오캐스트 실험실 자동화 및 지속적인 진화 방법을 포함한 실험 기술이 발전함에 따라 연구자들은 효소 역학 데이터의 확산을 예상합니다. 이러한 유입으로 인해 분야가 풍부해졌을 뿐만 아니라 예측 모델의 정확도도 향상되었습니다.
kcat 데이터 세트의 높은 불균형으로 인해 높은 kcat 값 예측에서 오류가 높아짐에 따라 팀에서는 이 문제를 완화하기 위해 네 가지 대표적인 재가중 방법을 체계적으로 탐색했습니다. 결과는 각 방법의 하이퍼파라미터 설정이 높은 kcat 값 예측을 개선하는 데 중요하다는 것을 보여줍니다.
팀은 Michaelis 상수(Km) 예측과 kcat/Km 예측 모두에서 현재 프레임워크의 강력한 일반성을 확인했습니다. UniKP는 Km 값을 예측하는 데 있어 최첨단 성능을 달성하고, 더욱 인상적으로 kcat/Km 값을 예측하는 데 있어 현재 최첨단 모델의 결합 결과를 능가합니다. 또한 연구진은 kcat/Km 데이터세트에서 kcat 및 Km 예측 모델을 사용하여 계산된 kcat/Km 값과 실험적으로 측정된 kcat/Km 값을 기반으로 UniKP 프레임워크를 검증했습니다.
UniKP kcat/UniKP Km에서 파생된 값과 실험적 kcat/Km 사이에 관찰된 상관관계가 상대적으로 낮다는 점은 주목할 가치가 있습니다(PCC = −0.01). 이러한 차이는 각 모델을 구축하는 데 사용된 서로 다른 데이터 세트로 인해 발생할 수 있으므로 kcat/Km 값을 예측하려면 서로 다른 모델을 개발해야 합니다. 앞으로 kcat 및 Km 값을 포함하는 통합 데이터 세트의 출현으로 kcat 및 Km 모델의 계산 출력은 kcat/Km 전용 모델에서 생성된 출력과 밀접하게 일치할 것으로 예상됩니다.
효소 채굴 및 진화에 대한 구체적인 응용
UniKP의 티로신 암모니아 분해효소(TAL) 효소 채굴 및 유도 진화에 대한 응용은 합성 생물학 및 생화학 연구에 혁명을 일으킬 수 있는 잠재력을 보여줍니다. 이 연구는 UniKP가 고활성 TAL을 효과적으로 인식하고 기존 TAL의 촉매 효율을 빠르게 향상시키는 것으로 나타났습니다. RgTAL-489T는 야생형 효소보다 kcat/Km 값이 3.5배 더 높습니다.
또한 파생된 프레임워크 EF-UniKP는 Tephrocybe rancida의 TrTAL kcat/Km 값이 야생형 효소의 kcat/Km 값보다 2.6배 더 높아 매우 높은 정확도로 활성이 높은 TAL 효소를 항상 식별할 수 있었습니다. 그 결과, 5개 서열의 kcat 및 kcat/Km 값이 야생형 효소의 값을 초과하는 것으로 나타났다.
효소 발견 및 최적화 프로세스를 가속화함으로써 UniKP는 생체촉매, 약물 발견, 대사 공학 및 효소 촉매 프로세스에 의존하는 기타 분야를 발전시키는 강력한 도구가 될 것으로 예상됩니다.
제한 사항 및 Outlook
그러나 현재 UniKP 버전에는 여전히 몇 가지 제한 사항이 있습니다. 예를 들어 UniKP는 실험적으로 측정된 효소의 kcat 값과 그 변이체를 구별할 수 있지만 예측된 kcat 값은 충분히 정확하지 않습니다. 이는 알려진 단백질 서열 및 기질 구조의 수에 비해 데이터 세트가 충분하지 않기 때문일 수 있습니다.
재가중치 방법은 불균형 kcat 데이터 세트로 인한 예측 편향을 어느 정도 완화할 수 있지만(~6.5% 개선), 합성 소수 오버샘플링 기술 및 기타 샘플 합성 방법을 통해 더 중요한 개선을 달성할 수 있습니다.
합성 생물학의 중심 목표는 과학자들이 생물학을 연구하는 방식에 혁명을 일으킬 디지털 세포의 개발입니다. 이 연구의 주요 전제 조건은 경로 내의 모든 효소에 대한 효소 매개변수를 신중하게 결정하는 것입니다. 인공 지능 지원 도구는 효소 동역학을 예측하기 위한 높은 처리량 방법을 제공하여 이러한 문제를 해결합니다.
UniKP 예측기의 오류는 이전 모델에 비해 줄어들었지만 부정확성은 정확한 대사 모델을 구축하는 데 여전히 중요한 장애물로 남아 있습니다. 실험적으로 결정된 kcat 및 Km 값의 증가하는 수를 통합하면 모델 정확도가 향상될 수 있습니다.
다음으로 연구원들은 전이 학습, 강화 학습 및 기타 소규모 학습 알고리즘과 같은 최첨단 알고리즘을 결합하여 불균형 데이터 세트를 효과적으로 처리할 계획입니다. 그리고 팀은 효소 진화와 유기체의 전체 분석을 포함한 추가 응용 프로그램을 탐색하는 것을 목표로 합니다.
논문 링크: https://www.nature.com/articles/s41467-023-44113-1
위 내용은 중국과학원 팀, 효소 동역학 매개변수의 예측 정확도 향상을 위한 통합 프레임워크 구축의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!